
Rumah >pangkalan data >Redis >Ringkasan 20 soalan dan jawapan temu bual klasik Redis (kongsi)
Ringkasan 20 soalan dan jawapan temu bual klasik Redis (kongsi)

- 青灯夜游ke hadapan
- 2023-03-07 18:53:414768semak imbas
Artikel ini telah menyusun 20 soalan wawancara klasik Redis untuk anda.

1. Untuk apa ia digunakan terutamanya?
Redis, nama penuh bahasa Inggeris ialah Pelayan Kamus Jauh (perkhidmatan kamus jauh), ialah jenis log sumber terbuka yang ditulis dalam bahasa ANSI C, menyokong rangkaian dan boleh berdasarkan memori atau pangkalan data Nilai Kunci dan menyediakan API dalam berbilang bahasa.
Tidak seperti pangkalan data MySQL, data Redis disimpan dalam ingatan. Kelajuan baca dan tulisnya sangat pantas dan boleh mengendalikan lebih daripada 100,000 operasi baca dan tulis sesaat. Oleh itu, redis digunakan secara meluas dalam cache Selain itu, Redis juga sering digunakan untuk kunci yang diedarkan. Di samping itu, Redis menyokong transaksi, ketekunan, skrip LUA, acara didorong LRU dan pelbagai penyelesaian kluster.
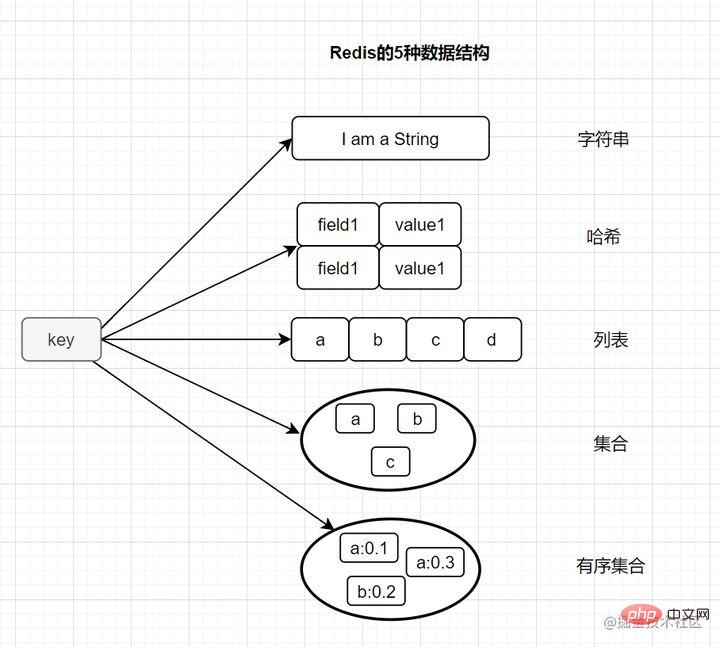
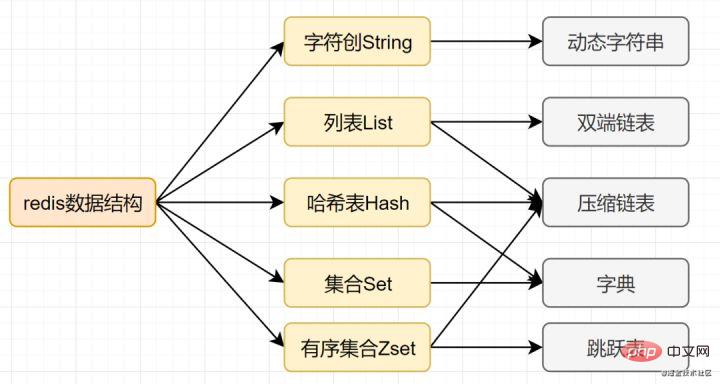
2 Mari kita bincangkan tentang jenis struktur data asas Redis
Kebanyakan rakan tahu bahawa Redis mempunyai lima jenis asas berikut:
- String (Rentetan Aksara)
- Hash (Hash)
- Senarai (senarai)
- Set (set)
- zset (set dipesan)
Ia juga mempunyai tiga jenis struktur data khas
- Geospatial
- Hyperloglog
- Bitmap
2.1 Lima jenis data asas daripada Redis
String (rentetan)
- Pengenalan: String ialah jenis struktur data paling asas bagi Redis , ia selamat binari dan boleh menyimpan gambar atau objek bersiri Nilai maksimum yang disimpan ialah 512M
- Contoh penggunaan mudah:
set key value,get key, dsb. - Senario aplikasi: sesi kongsi , kunci diedarkan, pembilang. , had semasa.
- Terdapat tiga pengekodan dalaman,
int(8字节长整型)/embstr(小于等于39字节字符串)/raw(大于39个字节字符串)
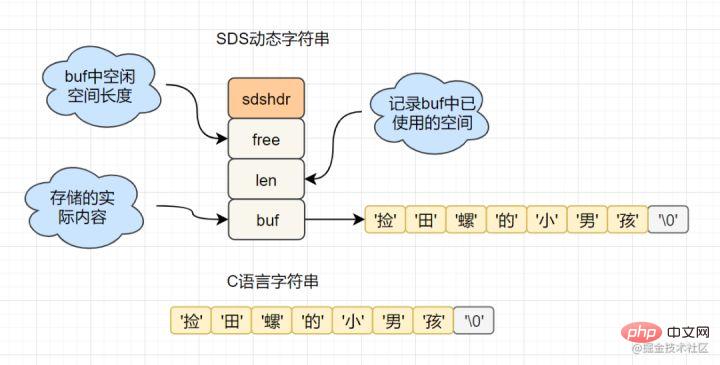
Rentetan bahasa C dilaksanakan oleh char[] dan Redis menggunakan SDS (rentetan dinamik ringkas) Pakej , kod sumber sds adalah seperti berikut:
struct sdshdr{
unsigned int len; // 标记buf的长度
unsigned int free; //标记buf中未使用的元素个数
char buf[]; // 存放元素的坑
}Rajah struktur SDS adalah seperti berikut:
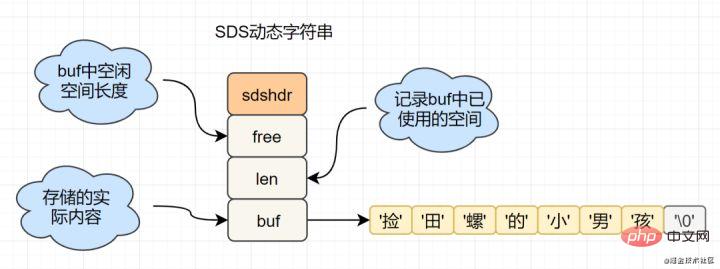
Mengapa Redis memilih SDS struktur, manakala C Bukankah bahasa ibunda char[] sedap?
Sebagai contoh, dalam SDS, anda boleh mendapatkan panjang rentetan dengan kerumitan masa O(1) manakala untuk rentetan C, anda perlu melintasi keseluruhan rentetan dan kerumitan masa ialah O(n )
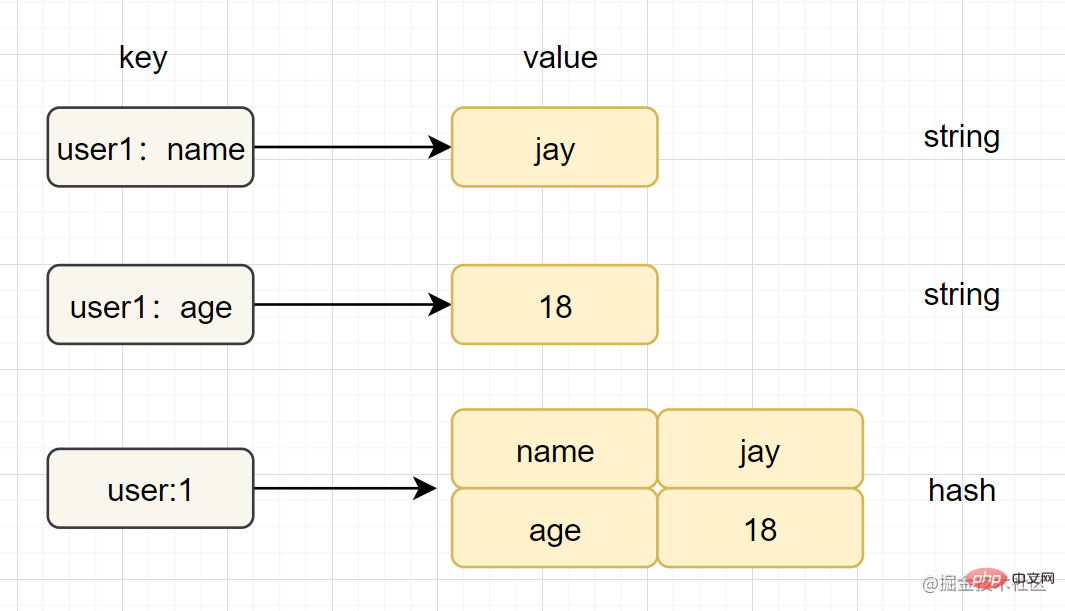
Hash (Hash)
- Pengenalan: Dalam Redis, jenis hash merujuk kepada v (nilai) itu sendiri yang merupakan struktur pasangan nilai kunci (k-v)
- Contoh penggunaan mudah:
hset key field value,hget key field - Pengekodan dalaman:
ziplist(压缩列表),hashtable(哈希表) - Senario aplikasi: menyimpan cache maklumat pengguna, dsb.
- Nota: Jika hgetall digunakan dalam pembangunan dan terdapat banyak elemen cincang, ia boleh menyebabkan Redis menyekat. Jika anda hanya ingin mendapatkan beberapa bidang, adalah disyorkan untuk menggunakan hmget.
Perbandingan antara jenis rentetan dan cincang adalah seperti berikut:
Senarai (senarai)
- Pengenalan: Senarai Jenis (senarai) digunakan untuk menyimpan berbilang rentetan tertib Satu senarai boleh menyimpan sehingga 2^32-1 elemen.
- Contoh mudah dan praktikal:
lpush key value [value ...],lrange key start end - Pengekodan dalaman: senarai zip (senarai termampat), senarai terpaut (senarai terpaut)
- Senario aplikasi: baris gilir mesej, senarai artikel ,
Anda boleh memahami sisipan dan pop timbul jenis senarai dalam satu gambar:
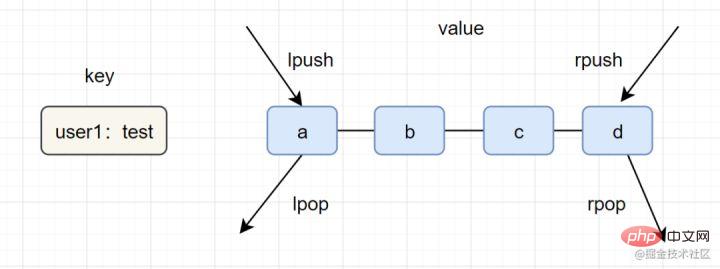
Senario aplikasi senarai rujuk perkara berikut :
- lpush+lpop=Timbunan (tindan)
- lpush+rpop=Barisan (baris)
- lpsh+ltrim=Koleksi Terhad (koleksi terhad )
- lpush+ brpop=Baris Gilir Mesej (Baris Gilir Mesej)
Set (Koleksi)
- Pengenalan: Jenis set juga Digunakan untuk menyimpan berbilang elemen rentetan, tetapi elemen pendua tidak dibenarkan
- Contoh penggunaan mudah:
sadd key element [element ...],smembers key - Pengekodan dalaman:
intset(整数集合),hashtable(哈希表) - Nota: smembers, lrange, dan hgetall adalah arahan yang agak berat Jika terdapat terlalu banyak elemen dan terdapat kemungkinan menyekat Redis, anda boleh menggunakan sscan untuk melengkapkannya. .
- Senario aplikasi: tag pengguna, penjanaan loteri nombor rawak, keperluan sosial.
Set dipesan (zset)
- Pengenalan: Koleksi rentetan yang diisih dan elemen tidak boleh diulang
- Contoh format mudah:
zadd key score member [score member ...],zrank key member - Pengekodan dalaman yang mendasari:
ziplist(压缩列表),skiplist(跳跃表) - Senario aplikasi: kedudukan, keperluan sosial (seperti kesukaan pengguna).
2.2 Tiga jenis data khas Redis
- Geo: Kedudukan geografi yang dilancarkan oleh Redis3.2, digunakan untuk menyimpan maklumat lokasi geografi dan beroperasi pada maklumat yang disimpan.
- HyperLogLog: Struktur data yang digunakan untuk algoritma statistik kardinaliti, seperti UV untuk tapak web statistik.
- Bitmaps: Gunakan satu bit untuk memetakan status elemen Dalam Redis, lapisan bawahnya adalah berdasarkan jenis rentetan Anda boleh menukar peta bit menjadi tatasusunan dalam bit
3. Mengapa Redis begitu pantas?
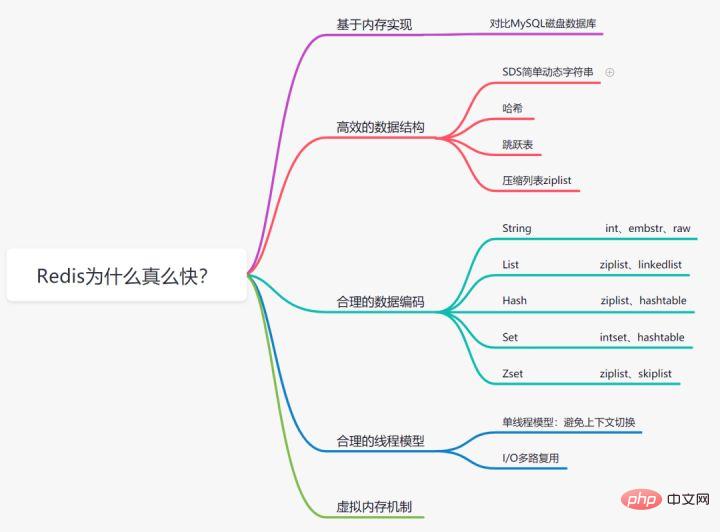
Mengapa Redis begitu pantas
3.1 Pelaksanaan berdasarkan storan memori
Kita semua tahu bahawa bacaan memori dan menulis lebih cepat daripada Berbanding dengan pangkalan data MySQL di mana data disimpan pada cakera, pangkalan data Redis dilaksanakan berdasarkan storan memori, yang jauh lebih pantas daripada cakera, menjimatkan penggunaan cakera I/O.
3.2 Struktur data yang cekap
Kami tahu bahawa untuk meningkatkan kecekapan, indeks Mysql memilih struktur data pepohon B+. Malah, struktur data yang munasabah boleh menjadikan aplikasi/program anda lebih pantas. Mari kita lihat struktur data & gambar rajah pengekodan dalaman Redis:
rentetan dinamik ringkas SDS
- Pemprosesan panjang rentetan: Redis memperoleh panjang rentetan, kerumitan masa ialah O(1), manakala dalam bahasa C, ia perlu dilalui dari awal, kerumitannya ialah O(n);
- Pra-peruntukan ruang : Lebih kerap rentetan diubah suai, lebih kerap peruntukan memori akan digunakan, yang akan menggunakan prestasi pengubahsuaian SDS dan pengembangan ruang akan memperuntukkan ruang yang tidak digunakan tambahan, mengurangkan kehilangan prestasi.
- Lazy space release: Apabila SDS dipendekkan, bukannya mengitar semula lebihan ruang memori, lebihan ruang direkodkan secara percuma Jika terdapat perubahan seterusnya, ruang yang direkodkan secara percuma akan digunakan terus untuk mengurangkan peruntukan.
- Keselamatan binari: Redis boleh menyimpan beberapa data binari, rentetan yang ditemui dalam bahasa C '
- I/O: Rangkaian I/O
- Berbilang: Berbilang sambungan rangkaian
- Guna Semula: Guna semula urutan yang sama.
- Pemultipleksan IO sebenarnya ialah model IO segerak, yang melaksanakan urutan yang boleh memantau berbilang pemegang fail apabila pemegang fail sedia, ia boleh memberitahu aplikasi untuk melaksanakan operasi baca dan tulis yang sepadan; sudah siap, aplikasi akan disekat dan CPU akan diserahkan.
Model benang tunggal
- Redis ialah model benang tunggal dan benang tunggal mengelakkan penukaran konteks dan persaingan yang tidak perlu untuk penggunaan Kunci CPU. Tepat kerana ia adalah satu utas, jika arahan tertentu dilaksanakan terlalu lama (seperti arahan hgetall), ia akan menyebabkan penyekatan. Redis ialah pangkalan data untuk senario pelaksanaan pantas. , jadi arahan seperti smembers, lrange, hgetall, dsb. hendaklah digunakan dengan berhati-hati.
- Redis 6.0 memperkenalkan multi-threading untuk mempercepatkan, dan pelaksanaan perintah dan operasi memorinya masih dalam satu utas.
3.5 Mekanisme Memori Maya
Redis membina mekanisme VM sendiri secara langsung, ia tidak memanggil fungsi sistem seperti sistem biasa, yang akan membazirkan sejumlah tertentu masa. Pergi bergerak dan minta.
Apakah mekanisme ingatan maya Redis?
Mekanisme memori maya menukar sementara data yang jarang diakses (data sejuk) dari memori ke cakera, dengan itu membebaskan ruang memori yang berharga untuk data lain yang perlu diakses (data panas). ). Fungsi VM boleh merealisasikan pemisahan data panas dan sejuk, supaya data panas masih dalam ingatan dan data sejuk disimpan ke cakera. Ini boleh mengelakkan masalah kelajuan capaian perlahan yang disebabkan oleh memori yang tidak mencukupi.
4. Apakah pecahan cache, penembusan cache, avalanche cache?
4.1 Masalah Penembusan Cache
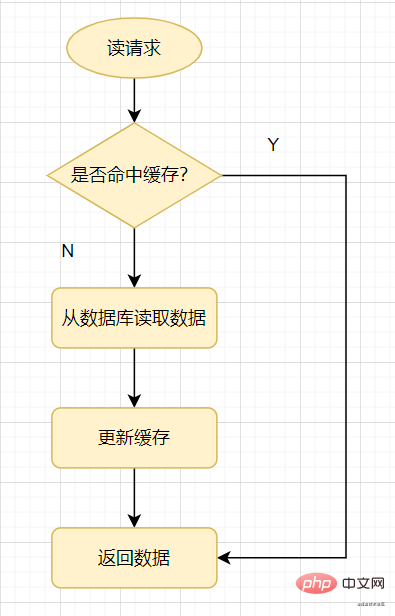
Mari kita lihat dahulu kaedah penggunaan cache biasa: apabila permintaan baca datang, semak cache dahulu, dan akan ada cache hit , hanya kembali terus jika cache terlepas, semak pangkalan data, kemudian kemas kini nilai pangkalan data ke cache, dan kemudian kembali.
Baca cache
Penembusan cache: merujuk kepada pertanyaan data yang mesti tidak wujud, kerana ia diperlukan apabila cache terlepas Jika data ditanya daripada pangkalan data, ia tidak akan ditulis ke cache Ini akan menyebabkan data yang tidak wujud akan ditanya dalam pangkalan data setiap kali ia diminta, yang akan memberi tekanan kepada pangkalan data.
Ringkasnya, apabila permintaan baca diakses, baik cache mahupun pangkalan data tidak mempunyai nilai tertentu, yang akan menyebabkan setiap permintaan pertanyaan untuk nilai ini menembusi ke dalam pangkalan data penembusan.
Penembusan cache secara amnya disebabkan oleh situasi berikut:
- Reka bentuk perniagaan yang tidak munasabah, contohnya, kebanyakan pengguna tidak mendayakan Guard, tetapi setiap permintaan yang anda buat pergi ke cache dan menyemak sama ada id pengguna tertentu dikawal.
- Ralat perniagaan/operasi dan penyelenggaraan/pembangunan, seperti cache dan data pangkalan data dipadamkan secara tidak sengaja.
- Serangan permintaan tidak sah oleh penggodam, sebagai contoh, penggodam sengaja mereka-reka sebilangan besar permintaan haram untuk membaca data perniagaan yang tidak wujud.
Bagaimana untuk mengelakkan penembusan cache? Secara amnya terdapat tiga kaedah.
- 1 Jika ia adalah permintaan yang tidak sah, kami akan mengesahkan parameter di pintu masuk API dan menapis nilai yang tidak sah.
- 2 Jika pangkalan data pertanyaan kosong, kami boleh menetapkan nilai nol atau nilai lalai untuk cache. Walau bagaimanapun, jika permintaan tulis masuk, cache perlu dikemas kini untuk memastikan konsistensi cache Pada masa yang sama, masa tamat tempoh yang sesuai akhirnya ditetapkan untuk cache. (Biasa digunakan dalam perniagaan, mudah dan berkesan)
- 3 Gunakan penapis Bloom untuk menentukan dengan cepat sama ada data wujud. Iaitu, apabila permintaan pertanyaan masuk, ia terlebih dahulu menilai sama ada nilai itu wujud melalui penapis Bloom, dan kemudian terus menyemak sama ada nilai itu wujud.
Prinsip penapis Bloom: Ia terdiri daripada tatasusunan peta bit dengan nilai awal 0 dan fungsi cincang N. Lakukan algoritma cincang N pada kunci untuk mendapatkan nilai N Hash nilai N ini dalam tatasusunan bit dan tetapkannya kepada 1. Kemudian apabila menyemak, jika kedudukan khusus ini semuanya 1, maka Penapisan Bloom Pelayan menentukan bahawa kunci itu wujud. .
4.2 Masalah larian salji cache
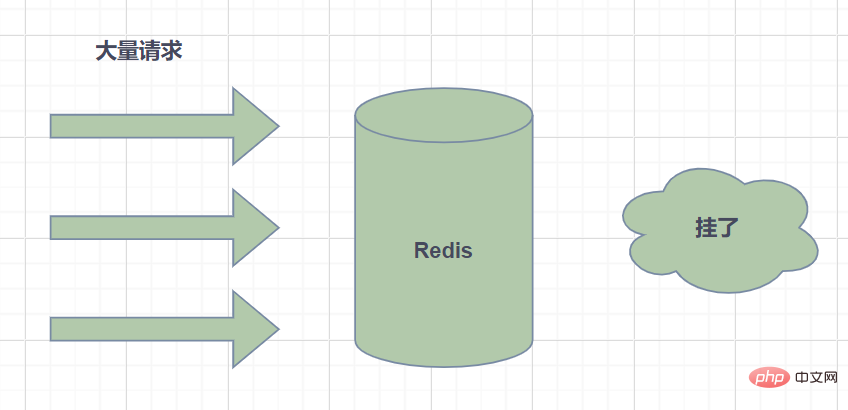
Larian salji cache: merujuk kepada masa tamat tempoh kumpulan besar data dalam cache, dan jumlah data pertanyaan Besar, semua permintaan terus mengakses pangkalan data, menyebabkan tekanan yang berlebihan pada pangkalan data dan juga masa henti.
- Cache snowfall secara amnya disebabkan oleh sejumlah besar data yang luput pada masa yang sama Atas sebab ini, ia boleh diselesaikan dengan menetapkan masa tamat tempoh secara sama rata, iaitu, menjadikan masa tamat tempoh agak diskret. . Jika anda menggunakan nilai tetap yang lebih besar + nilai rawak yang lebih kecil, 5 jam + 0 hingga 1800 saat.
- Kegagalan redis juga boleh menyebabkan salji cache. Ini memerlukan pembinaan kluster ketersediaan tinggi Redis.
4.3 Masalah pecahan cache
Pecahan cache: merujuk kepada apabila kunci tempat liputan tamat tempoh pada masa tertentu, dan ia kebetulan Pada ketika ini, terdapat sejumlah besar permintaan serentak untuk Kunci ini, dan sejumlah besar permintaan dipukul ke db.
Pecahan cache kelihatan agak serupa Malah, perbezaan di antara mereka ialah salji cache bermakna bahawa pangkalan data berada di bawah tekanan yang berlebihan atau malah pecahan cache hanyalah sejumlah besar permintaan serentak ke peringkat pangkalan data DB. Ia boleh dianggap bahawa pecahan ialah subset cache salji. Sesetengah artikel percaya bahawa perbezaan antara kedua-duanya ialah pecahan ditujukan kepada cache kunci panas tertentu, manakala Xuebeng disasarkan pada banyak kunci.
Terdapat dua penyelesaian:
- 1 Gunakan skema kunci mutex . Apabila cache gagal, daripada memuatkan data db serta-merta, anda mula-mula menggunakan beberapa perintah operasi atom dengan pulangan yang berjaya, seperti (Redis's setnx) untuk beroperasi Apabila berjaya, muatkan data pangkalan data db dan sediakan cache. Jika tidak, cuba dapatkan cache sekali lagi.
- 2. "Tidak pernah tamat tempoh" bermakna masa tamat tempoh tidak ditetapkan, tetapi apabila data tempat liputan hampir tamat tempoh, urutan tak segerak mengemas kini dan menetapkan masa tamat tempoh.
5. Apakah masalah kunci panas dan cara menyelesaikan masalah kunci panas
Apakah kunci panas? Di Redis, kami memanggil kunci dengan kekerapan akses tinggi sebagai kunci tempat liputan.
Jika permintaan kunci tempat liputan dihantar kepada hos pelayan, disebabkan volum permintaan yang sangat besar, ia mungkin menyebabkan sumber hos tidak mencukupi atau bahkan masa henti, sekali gus menjejaskan perkhidmatan biasa.
Bagaimanakah Kunci tempat liputan dijana? Terdapat dua sebab utama:
- Data yang digunakan oleh pengguna jauh lebih besar daripada data yang dihasilkan, seperti jualan kilat, berita hangat dan senario lain di mana terdapat lebih banyak bacaan dan kurang penulisan.
- Pembahagian permintaan adalah tertumpu, yang melebihi prestasi pelayan Redi tunggal Contohnya, jika kunci nama tetap dan Hash jatuh ke dalam pelayan yang sama, jumlah akses segera adalah besar, melebihi kesesakan mesin. , dan menyebabkan masalah kunci panas.
Jadi bagaimana untuk mengenal pasti kunci panas dalam pembangunan harian?
Peluasan gugusan Redis: tambah salinan serpihan untuk mengimbangi trafik baca; , cache tempatan JVM, mengurangkan permintaan baca Redis.
- Tentukan kekunci panas yang berdasarkan pengalaman;
- Pelaporan statistik pelanggan;
Bagaimana untuk menyelesaikan masalah kunci panas?
- 6. Dasar tamat tempoh Redis dan dasar penghapusan ingatan
Apabila kita berada di , kita boleh menetapkan masa tamat tempoh untuknya, seperti
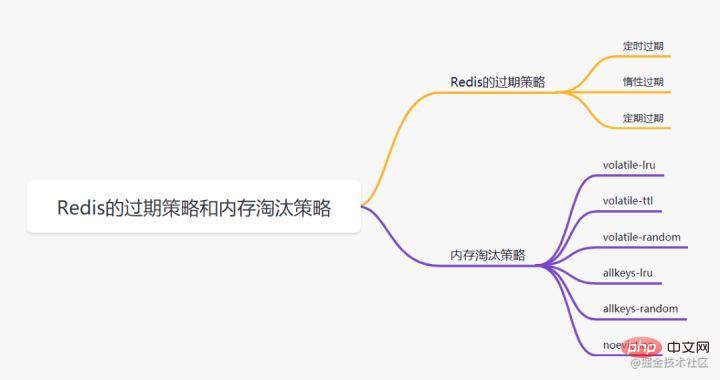
. Tentukan bahawa kunci ini akan tamat tempoh selepas 60 saat Bagaimana redis mengendalikannya selepas 60 saat? Mari kita perkenalkan beberapa strategi tamat tempoh dahulu:
Tamat tempoh masa
Setiap kunci dengan masa tamat tempoh perlu mencipta pemasa dan kunci akan dikosongkan serta-merta selepas masa tamat tempoh . Strategi ini boleh mengosongkan data yang telah tamat tempoh serta-merta dan sangat mesra memori walau bagaimanapun, ia akan menduduki sejumlah besar sumber CPU untuk memproses data yang telah tamat tempoh, sekali gus menjejaskan masa tindak balas cache dan pemprosesan.
Malas tamat tempoh
Hanya apabila kunci diakses, ia akan dinilai sama ada kunci telah tamat tempoh, dan ia akan dikosongkan apabila ia tamat tempoh. Strategi ini boleh menjimatkan sumber CPU ke tahap maksimum, tetapi ia sangat tidak mesra memori. Dalam kes yang melampau, sebilangan besar kunci yang telah tamat tempoh mungkin tidak dapat diakses semula, oleh itu tidak dibersihkan dan menduduki sejumlah besar memori.set keyexpire key 60Tamat tempoh secara tetapSetiap masa tertentu, bilangan kunci tertentu dalam kamus tamat tempoh bilangan pangkalan data tertentu akan diimbas dan kunci tamat tempoh akan dikosongkan. Strategi ini adalah kompromi antara dua yang pertama. Dengan melaraskan selang masa imbasan berjadual dan penggunaan masa terhad bagi setiap imbasan, keseimbangan optimum antara CPU dan sumber memori boleh dicapai dalam keadaan yang berbeza. Kamus tamat tempoh akan menyimpan data masa tamat tempoh semua kunci dengan masa tamat tempoh ditetapkan, dengan kunci ialah penunjuk kepada kunci dalam ruang kunci dan nilai ialah cap masa UNIX bagi kunci dengan ketepatan milisaat masa. Ruang kekunci merujuk kepada semua kekunci yang disimpan dalam kelompok Redis.Redis menggunakan kedua-duatamat tempoh malas dan tamat tempoh berkaladua strategi tamat tempoh.
- 假设Redis当前存放30万个key,并且都设置了过期时间,如果你每隔100ms就去检查这全部的key,CPU负载会特别高,最后可能会挂掉。
- 因此,redis采取的是定期过期,每隔100ms就随机抽取一定数量的key来检查和删除的。
- 但是呢,最后可能会有很多已经过期的key没被删除。这时候,redis采用惰性删除。在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间并且已经过期了,此时就会删除。
但是呀,如果定期删除漏掉了很多过期的key,然后也没走惰性删除。就会有很多过期key积在内存内存,直接会导致内存爆的。或者有些时候,业务量大起来了,redis的key被大量使用,内存直接不够了,运维小哥哥也忘记加大内存了。难道redis直接这样挂掉?不会的!Redis用8种内存淘汰策略保护自己~
6.2 Redis 内存淘汰策略
- volatile-lru:当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰;
- allkeys-lru:当内存不足以容纳新写入数据时,从所有key中使用LRU(最近最少使用)算法进行淘汰。
- volatile-lfu:4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使用LFU算法进行删除key。
- allkeys-lfu:4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使用LFU算法进行淘汰;
- volatile-random:当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据;。
- allkeys-random:当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰;
- noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
7.说说Redis的常用应用场景
- 缓存
- 排行榜
- 计数器应用
- 共享Session
- 分布式锁
- 社交网络
- 消息队列
- 位操作
7.1 缓存
我们一提到redis,自然而然就想到缓存,国内外中大型的网站都离不开缓存。合理的利用缓存,比如缓存热点数据,不仅可以提升网站的访问速度,还可以降低数据库DB的压力。并且,Redis相比于memcached,还提供了丰富的数据结构,并且提供RDB和AOF等持久化机制,强的一批。
7.2 排行榜
当今互联网应用,有各种各样的排行榜,如电商网站的月度销量排行榜、社交APP的礼物排行榜、小程序的投票排行榜等等。Redis提供的
zset数据类型能够实现这些复杂的排行榜。比如,用户每天上传视频,获得点赞的排行榜可以这样设计:
- 1.用户Jay上传一个视频,获得6个赞,可以酱紫:
zadd user:ranking:2021-03-03 Jay 3
- 2.过了一段时间,再获得一个赞,可以这样:
zincrby user:ranking:2021-03-03 Jay 1
- 3.如果某个用户John作弊,需要删除该用户:
zrem user:ranking:2021-03-03 John
- 4.展示获取赞数最多的3个用户
zrevrangebyrank user:ranking:2021-03-03 0 27.3 计数器应用
各大网站、APP应用经常需要计数器的功能,如短视频的播放数、电商网站的浏览数。这些播放数、浏览数一般要求实时的,每一次播放和浏览都要做加1的操作,如果并发量很大对于传统关系型数据的性能是一种挑战。Redis天然支持计数功能而且计数的性能也非常好,可以说是计数器系统的重要选择。
7.4 共享Session
如果一个分布式Web服务将用户的Session信息保存在各自服务器,用户刷新一次可能就需要重新登录了,这样显然有问题。实际上,可以使用Redis将用户的Session进行集中管理,每次用户更新或者查询登录信息都直接从Redis中集中获取。
7.5 分布式锁
几乎每个互联网公司中都使用了分布式部署,分布式服务下,就会遇到对同一个资源的并发访问的技术难题,如秒杀、下单减库存等场景。
- Menggunakan kunci setempat segerak atau reentrantlock pasti tidak akan berfungsi.
- Jika jumlah concurrency tidak besar, tiada masalah untuk menggunakan kunci pesimis dan kunci optimistik pangkalan data.
- Walau bagaimanapun, dalam situasi dengan konkurensi yang tinggi, menggunakan kunci pangkalan data untuk mengawal akses serentak kepada sumber akan menjejaskan prestasi pangkalan data.
- Malah, setnx Redis boleh digunakan untuk melaksanakan kunci teragih.
7.6 Rangkaian Sosial
Suka/tidak suka, peminat, rakan/kegemaran bersama, tolak, tarik-turun muat semula, dsb. adalah fungsi penting rangkaian sosial Disebabkan oleh rangkaian sosial Lawatan laman web biasanya besar, dan data perhubungan tradisional tidak sesuai untuk menyimpan data jenis ini. Struktur data yang disediakan oleh Redis boleh merealisasikan fungsi ini dengan mudah.
7.7 Baris Gilir Mesej
Baris gilir mesej ialah perisian tengah yang mesti ada untuk tapak web yang besar, seperti ActiveMQ, RabbitMQ, Kafka dan perisian tengah gilir mesej popular yang lain, terutamanya digunakan untuk penyahgandingan perniagaan, pencukuran puncak trafik dan pemprosesan perkhidmatan tak segerak dengan prestasi masa nyata yang rendah. Redis menyediakan fungsi penerbitan/langgan dan menyekat baris gilir, yang boleh melaksanakan sistem baris gilir mesej ringkas. Di samping itu, ini tidak boleh dibandingkan dengan perisian tengah mesej profesional.
Operasi 7.8-bit
Digunakan dalam senario dengan ratusan juta data, seperti log masuk sistem untuk ratusan juta pengguna, statistik bilangan log masuk nyahduplikasi, dan sama ada pengguna berada dalam talian dsb. Tencent mempunyai 1 bilion pengguna Bagaimana kita boleh menyemak sama ada pengguna tertentu berada dalam talian dalam beberapa milisaat? Jangan sekali-kali mengatakan untuk mencipta kunci untuk setiap pengguna dan kemudian merekodkannya satu demi satu (anda boleh mengira memori yang diperlukan, yang akan menjadi sangat menakutkan, dan terdapat banyak keperluan yang serupa. Operasi yang betul mesti digunakan di sini - gunakan setbit, getbit, dan perintah bitcount Prinsipnya ialah: bina tatasusunan yang cukup panjang dalam redis, setiap elemen tatasusunan hanya boleh mempunyai dua nilai 0 dan 1, dan kemudian indeks subskrip tatasusunan ini digunakan untuk mewakili ID pengguna (mestilah nombor), maka jelas sekali, susunan yang besar ratusan juta ini boleh membina sistem memori melalui subskrip dan nilai elemen (0 dan 1)
8 Apakah kelebihan dan kekurangannya Redis? >
Redis ialah pangkalan data K-V bukan hubungan berasaskan memori, jika pelayan Redis menutup telefon, data akan hilang, Redis menyediakanketekunan , iaitu menyimpan data ke cakera
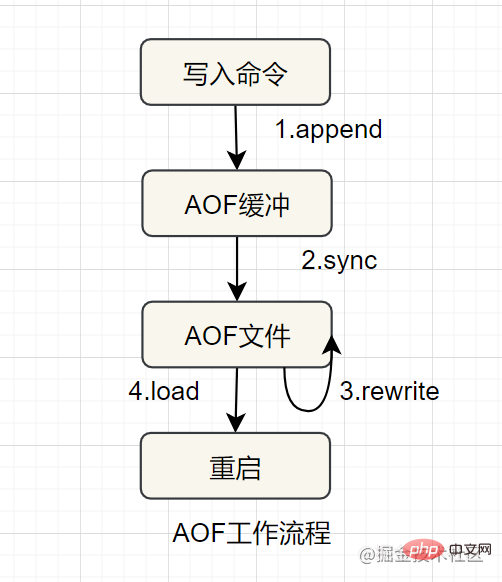
Redis menyediakan dua mekanisme kegigihan:RDB dan AOF Proses pemuatan fail yang berterusan adalah seperti berikut:
8.1 RDB
RDB menyimpan data memori ke cakera dalam bentuk syot kilat 🎜 >Apakah syot kilat? Anda boleh memahaminya dengan cara ini, mengambil gambar data pada masa semasa, dan kemudian menyimpannya
Kegigihan RDB merujuk kepada melaksanakan bilangan kali yang ditetapkan. selang masa tertentu Operasi tulis menulis syot kilat set data ke dalam cakera Ia adalah kaedah kegigihan lalai Redis Selepas operasi selesai, failakan dihasilkan dalam direktori yang ditentukan dimulakan semula, ia akan dimuatkan oleh <.>Kelemahan RDB
dump.rdbdump.rdbTiada cara untuk mencapai kegigihan masa nyata/kegigihan peringkat keduaVersi lama dan baharu mempunyai isu keserasian format RDB
AOF
- AOF (tambah fail sahaja)
Kegigihan merekodkan setiap operasi tulis dalam bentuk log, tambahkannya pada fail dan kemudian melaksanakan semula arahan dalam fail AOF untuk memulihkan data terutamanya menyelesaikan masalah masa nyata kegigihan data dan tidak didayakan secara lalaiAliran kerja AOF adalah seperti berikut: <.>
Ketekalan data dan integriti yang lebih tinggi
- Kelebihan AOF
Kelemahan AOF
Semakin banyak kandungan rekod AOF, semakin besar fail dan semakin perlahan pemulihan data
9.
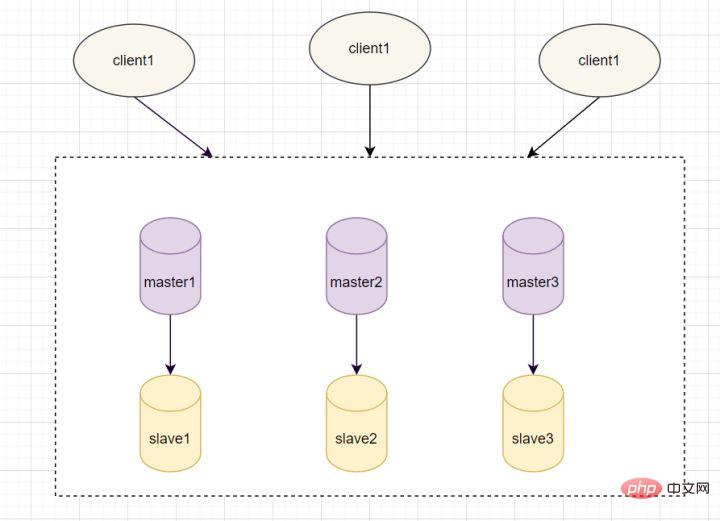
Apabila kami menggunakan Redis dalam projek, kami pasti tidak akan menggunakan perkhidmatan Redis sebagai satu titik. Kerana apabila penggunaan satu titik menurun, ia tidak lagi tersedia. Untuk mencapai ketersediaan tinggi, amalan biasa ialah menyalin berbilang salinan pangkalan data dan menggunakannya pada pelayan yang berbeza Jika salah satu daripadanya gagal, ia boleh terus menyediakan perkhidmatan. Terdapat tiga mod penggunaan untuk Redis mencapai ketersediaan tinggi: mod master-slave, mod sentinel dan mod cluster.
- 9.1 Mod Master-slave
Dalam mod master-slave, Redis menggunakan berbilang mesin, dengan nod induk yang bertanggungjawab untuk operasi membaca dan menulis, dan nod hamba bertanggungjawab hanya untuk operasi membaca. Data nod hamba datang daripada nod induk, dan prinsip pelaksanaannya ialah mekanisme replikasi induk-hamba
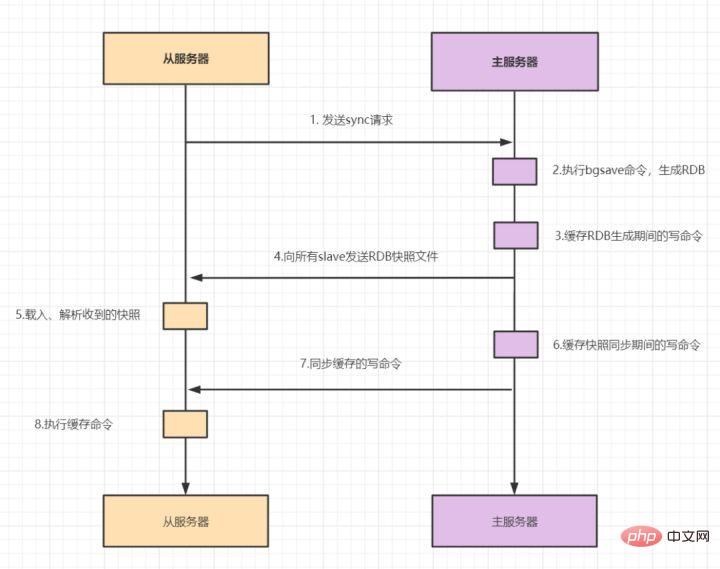
Replikasi tuan-hamba termasuk replikasi penuh dan replikasi tambahan. Secara amnya, apabila hamba mula menyambung kepada tuan buat kali pertama, atau ia dianggap sebagai kali pertama menyambung, salinan penuh digunakan proses salinan penuh adalah seperti berikut:
- 1.hamba menghantar arahan penyegerakan kepada tuan.
- 2. Selepas induk menerima arahan SYNC, ia melaksanakan perintah bgsave untuk menjana fail RDB penuh.
- 3. Induk menggunakan penimbal untuk merekod semua arahan tulis semasa penjanaan syot kilat RDB.
- 4. Selepas master melaksanakan bgsave, ia menghantar fail snapshot RDB kepada semua hamba.
- 5. Selepas menerima fail petikan RDB, hamba memuatkan dan menghuraikan petikan yang diterima.
- 6. Induk menggunakan penimbal untuk merekod semua arahan bertulis yang dijana semasa penyegerakan RDB.
- 7 Selepas syot kilat induk dihantar, ia mula menghantar arahan tulis dalam penimbal kepada hamba
- 8 penimbal
Selepas redis versi 2.8, psync telah digunakan untuk menggantikan penyegerakan, kerana arahan penyegerakan menggunakan sumber sistem dan psync lebih cekap.
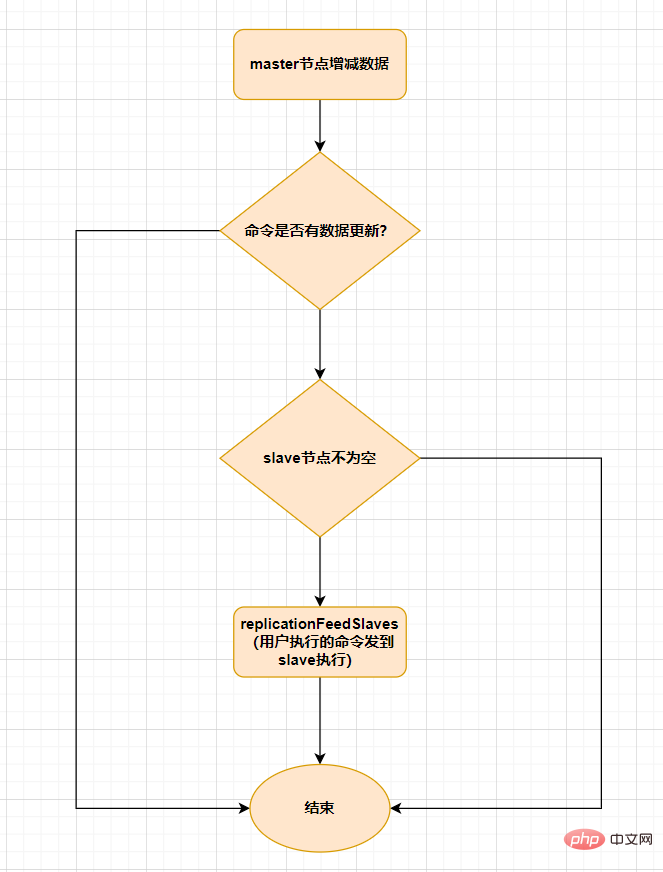
Selepas hamba disegerakkan sepenuhnya dengan tuan, jika data pada tuan dikemas kini semula, replikasi tambahan akan dicetuskan.
Apabila data bertambah atau berkurang pada nod induk, fungsi
replicationFeedSalves()akan dicetuskan. Setiap arahan yang kemudiannya dipanggil pada nod Induk akan menggunakanreplicationFeedSlaves()untuk menyegerakkan ke nod Hamba. Sebelum melaksanakan fungsi ini, nod induk akan menentukan sama ada arahan yang dilaksanakan oleh pengguna mempunyai kemas kini data Jika terdapat kemas kini data dan nod hamba tidak kosong, fungsi ini akan dilaksanakan. Fungsi fungsi ini adalah untuk: menghantar arahan yang dilaksanakan oleh pengguna kepada semua nod hamba dan biarkan nod hamba melaksanakannya. Prosesnya adalah seperti berikut:
9.2 Mod Sentinel
Dalam mod master-slave, sebaik sahaja nod induk tidak dapat menyediakan perkhidmatan yang perlu dibayar untuk kegagalan, ia perlu diganti secara manual Nod hamba dinaikkan ke nod induk dan aplikasi dimaklumkan untuk mengemas kini alamat nod induk. Jelas sekali, kaedah pengendalian kerosakan ini tidak boleh diterima dalam kebanyakan senario perniagaan. Redis telah secara rasmi menyediakan seni bina Redis Sentinel sejak 2.8 untuk menyelesaikan masalah ini.
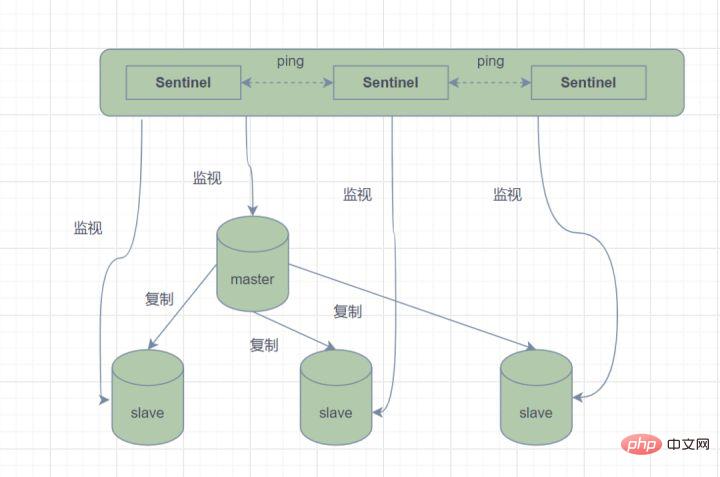
Mod Sentinel, sistem Sentinel yang terdiri daripada satu atau lebih tika Sentinel, yang boleh memantau semua nod induk dan nod hamba Redis, dan memasuki keadaan luar talian apabila nod induk dipantau , secara automatik meningkatkan nod hamba di bawah pelayan induk luar talian kepada nod induk baharu . Walau bagaimanapun, apabila proses sentinel memantau nod Redis, masalah mungkin berlaku (Masalah titik tunggal Oleh itu, berbilang sentinel boleh digunakan untuk memantau nod Redis, dan akan ada komunikasi berterusan antara setiap monitor.
Mod Sentinel
Ringkasnya, Mod Sentinel mempunyai tiga fungsi:
Apakah proses failover?
- Hantar arahan dan tunggu pelayan Redis ( Termasuk pelayan induk dan pelayan hamba) Kembali untuk memantau status berjalannya; terbitkan dan langgan mod, dan ubah suai fail Konfigurasi untuk membolehkan mereka menukar hos;
- Pengawal juga akan memantau satu sama lain untuk mencapai ketersediaan yang tinggi.
Andaikan pelayan utama tidak berfungsi dan Sentinel 1 mengesan keputusan ini terlebih dahulu, sistem tidak akan proses failover dijalankan serta-merta. Sentinel 1 hanya secara subjektif percaya bahawa pelayan utama tidak tersedia, dan fenomena ini menjadi luar talian subjektif. Apabila pengawal berikutnya juga mengesan bahawa pelayan utama tidak tersedia dan bilangannya mencapai nilai tertentu, undian akan diadakan antara pengawal Keputusan undian akan dimulakan oleh seorang pengawal untuk melakukan operasi failover. Selepas suis berjaya, setiap pengawal akan menggunakan mod terbitkan-langganan untuk menukar pelayan hamba yang dipantaunya kepada hos Proses ini dipanggil objektif luar talian. Dengan cara ini semuanya telus kepada pelanggan.
Mod kerja Sentinel adalah seperti berikut:Setiap Sentinel menghantar mesej kepada Master, Slave dan contoh Sentinel lain yang diketahuinya sekali sesaat Perintah PING.
- Jika masa sejak balasan terakhir yang sah kepada arahan PING melebihi nilai yang ditentukan oleh pilihan turun-selepas milisaat, kejadian itu akan ditandakan secara subjektif di luar talian oleh Sentinel.
- Jika Master ditandakan sebagai subjektif luar talian, semua Sentinel yang memantau Master mesti mengesahkan sekali sesaat bahawa Master memang telah memasuki keadaan luar talian subjektif.
- Apabila bilangan Sentinel yang mencukupi (lebih daripada atau sama dengan nilai yang dinyatakan dalam fail konfigurasi) mengesahkan bahawa Master memang telah memasuki keadaan luar talian subjektif dalam julat masa yang ditentukan, Sarjana akan ditanda sebagai objektif luar talian.
Dalam keadaan biasa, setiap Sentinel akan menghantar arahan INFO kepada semua Master dan Slaves yang dikenalinya sekali setiap 10 saat.
Apabila Guru ditandakan sebagai luar talian secara objektif oleh Sentinel, kekerapan Sentinel menghantar arahan INFO kepada semua Hamba Guru luar talian akan ditukar daripada sekali setiap 10 saat kepada sekali sesaat
Jika tidak cukup Sentinel untuk bersetuju bahawa Master berada di luar talian, status luar talian objektif Master akan dialih keluar jika Master mengembalikan jawapan yang sah kepada arahan PING Sentinel, subjektif Master status luar talian akan dialih keluar Status akan dialih keluar.
9.3 Mod Kluster
Mod sentinel adalah berdasarkan mod tuan-hamba, yang merealisasikan pemisahan membaca dan menulis juga bertukar secara automatik dan sistem mempunyai ketersediaan yang lebih tinggi. Walau bagaimanapun, data yang disimpan dalam setiap nod adalah sama, yang membazirkan memori dan tidak mudah untuk dikembangkan dalam talian. Oleh itu, kluster Kluster wujud. Ia telah ditambahkan dalam Redis 3.0 dan melaksanakan storan teragih Redis. Bahagikan data, yang bermaksud simpan kandungan berbeza pada setiap nod Redis untuk menyelesaikan masalah pengembangan dalam talian. Selain itu, ia juga menyediakan keupayaan replikasi dan failover.
Komunikasi nod kelompok KlusterKluster Redis terdiri daripada berbilang nodBagaimanakah setiap nod berkomunikasi antara satu sama lain? Melalui protokol Gosip!
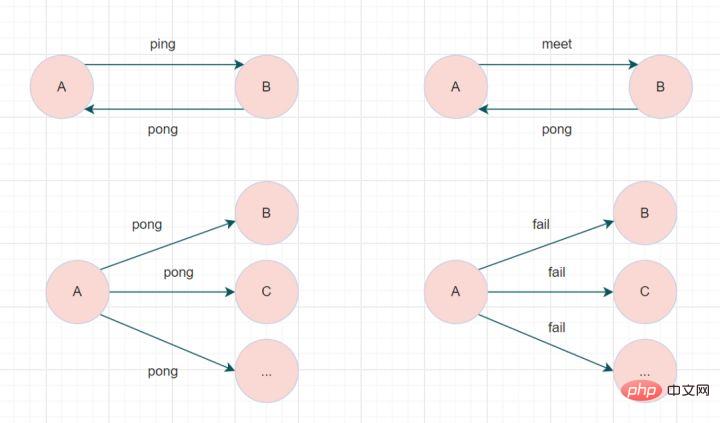
Kluster Redis berkomunikasi melalui protokol Gossip Nod bertukar maklumat secara berterusan termasuk kegagalan nod, sambungan nod baharu, maklumat pertukaran nod induk, maklumat slot, dsb. Mesej gosip yang biasa digunakan terbahagi kepada empat jenis: ping, pong, meet, dan fail.
Khususnya, setiap nod berkomunikasi dengan nod lain melaluimesej jumpa: Maklumkan nod baharu untuk menyertai. Pengirim mesej memberitahu penerima untuk menyertai kluster semasa Selepas komunikasi mesej bertemu selesai seperti biasa, nod penerima akan menyertai kluster dan melakukan pertukaran mesej ping dan pong secara berkala.
- Mesej ping: Mesej yang paling kerap ditukar dalam kluster Setiap nod dalam kluster menghantar mesej ping ke berbilang nod lain setiap saat, yang digunakan untuk mengesan sama ada nod berada dalam talian dan bertukar maklumat status antara satu sama lain. .
- mesej pong: Apabila menerima mesej ping atau meet, ia akan membalas kepada penghantar sebagai mesej respons untuk mengesahkan komunikasi biasa mesej itu. Mesej pong secara dalaman merangkum data statusnya sendiri. Nod juga boleh menyiarkan mesej pongnya sendiri kepada kluster untuk memberitahu seluruh kluster untuk mengemas kini statusnya sendiri.
- mesej gagal: Apabila nod menentukan bahawa nod lain dalam kluster berada di luar talian, ia akan menyiarkan mesej gagal ke kluster Selepas menerima mesej gagal, nod lain akan mengemas kini nod yang sepadan kepada keadaan luar talian.
bas kluster (bas kluster). Semasa berkomunikasi, gunakan nombor port khas, iaitu nombor port perkhidmatan luaran ditambah 10000. Sebagai contoh, jika nombor port nod ialah 6379, maka nombor port yang digunakan untuk berkomunikasi dengan nod lain ialah 16379. Komunikasi antara nod menggunakan protokol binari khas.
Algoritma Slot CincangMemandangkan ia adalah storan teragih, adakah algoritma teragih digunakan oleh gugusan KlusterCencang Konsisten? Tidak, tetapi Algoritma slot Hash Slot.
Algoritma slotSeluruh pangkalan data dibahagikan kepada 16384 slot (slot) Setiap pasangan nilai kunci yang memasuki Redis dicincang mengikut kunci dan diperuntukkan kepada 16384 slot ini. Peta hash yang digunakan juga agak mudah Ia menggunakan algoritma CRC16 untuk mengira nilai 16-bit, dan kemudian modulo 16384. Setiap kunci dalam pangkalan data adalah milik salah satu daripada 16384 slot ini dan setiap nod dalam kelompok boleh mengendalikan 16384 slot ini.
Setiap nod dalam gugusan bertanggungjawab untuk sebahagian daripada slot cincang Contohnya, gugusan semasa mempunyai nod A, B dan C, dan bilangan slot cincang pada setiap nod = 16384/3, maka terdapat:Nod A bertanggungjawab untuk slot cincang 0~5460
Kluster Kluster RedisDalam kluster Kluster Redis, adalah perlu untuk memastikan bahawa nod yang sepadan dengan slot 16384 berfungsi seperti biasa , slot yang dipertanggungjawabkan juga akan gagal, dan keseluruhan kluster tidak akan berfungsi. Oleh itu, untuk memastikan ketersediaan tinggi, kluster Kluster memperkenalkan replikasi induk-hamba, dan satu nod induk sepadan dengan satu atau lebih nod hamba. Apabila nod induk lain ping nod induk A, jika lebih separuh daripada nod induk berkomunikasi dengan A tamat masa, maka nod induk A dianggap turun. Jika nod induk turun, nod hamba akan didayakan. Pada setiap nod Redis, terdapat dua perkara, satu ialah slot dan julat nilainya ialah 0~16383. Yang satu lagi ialah kluster, yang boleh difahami sebagai pemalam pengurusan kluster. Apabila kunci yang kami akses tiba, Redis akan memperoleh nilai 16-bit berdasarkan algoritma CRC16, dan kemudian mengambil hasil modulo 16384. Setiap kekunci dalam Jiangzi sepadan dengan slot cincang bernombor antara 0 dan 16383. Gunakan nilai ini untuk mencari nod yang sepadan dengan slot yang sepadan, dan kemudian secara automatik melompat ke nod yang sepadan untuk operasi akses.- Nod B bertanggungjawab untuk slot cincang 5461~10922
- Nod C bertanggungjawab untuk slot cincang 10923~16383
虽然数据是分开存储在不同节点上的,但是对客户端来说,整个集群Cluster,被看做一个整体。客户端端连接任意一个node,看起来跟操作单实例的Redis一样。当客户端操作的key没有被分配到正确的node节点时,Redis会返回转向指令,最后指向正确的node,这就有点像浏览器页面的302 重定向跳转。
故障转移
Redis集群实现了高可用,当集群内节点出现故障时,通过故障转移,以保证集群正常对外提供服务。
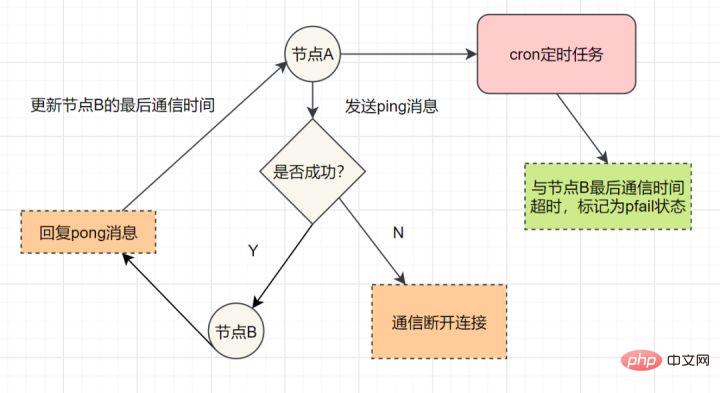
redis集群通过ping/pong消息,实现故障发现。这个环境包括主观下线和客观下线。
主观下线: 某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况。
主观下线
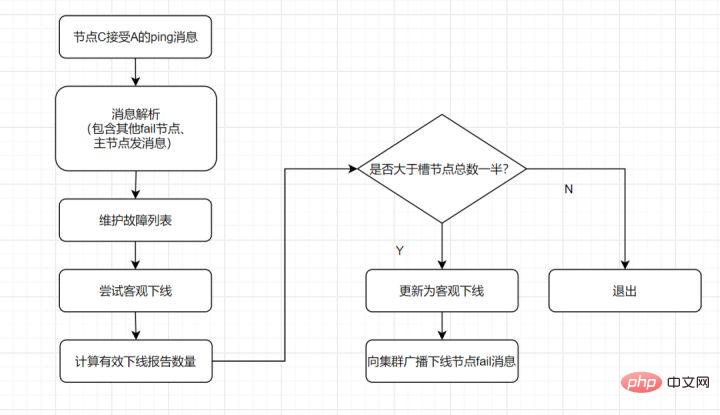
客观下线: 指标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果。如果是持有槽的主节点故障,需要为该节点进行故障转移。
- 假如节点A标记节点B为主观下线,一段时间后,节点A通过消息把节点B的状态发到其它节点,当节点C接受到消息并解析出消息体时,如果发现节点B的pfail状态时,会触发客观下线流程;
- 当下线为主节点时,此时Redis Cluster集群为统计持有槽的主节点投票,看投票数是否达到一半,当下线报告统计数大于一半时,被标记为客观下线状态。
流程如下:
客观下线
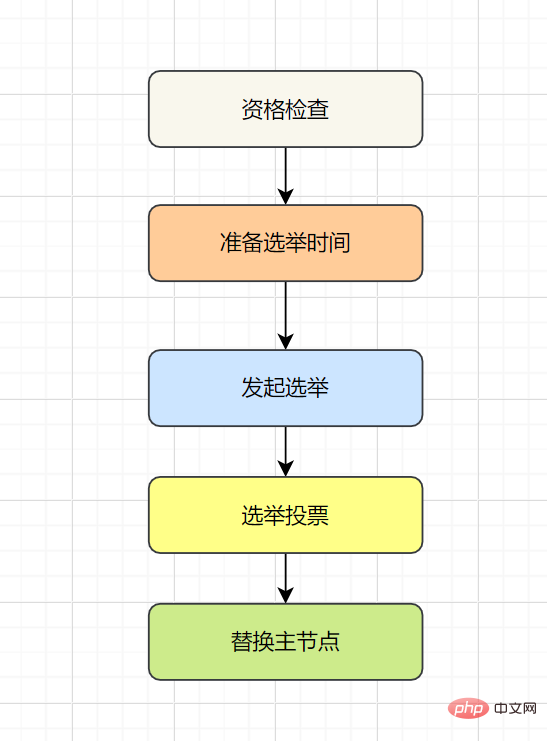
故障恢复:故障发现后,如果下线节点的是主节点,则需要在它的从节点中选一个替换它,以保证集群的高可用。流程如下:
- 资格检查:检查从节点是否具备替换故障主节点的条件。
- 准备选举时间:资格检查通过后,更新触发故障选举时间。
- 发起选举:到了故障选举时间,进行选举。
- 选举投票:只有持有槽的主节点才有票,从节点收集到足够的选票(大于一半),触发替换主节点操作
10. 使用过Redis分布式锁嘛?有哪些注意点呢?
分布式锁,是控制分布式系统不同进程共同访问共享资源的一种锁的实现。秒杀下单、抢红包等等业务场景,都需要用到分布式锁,我们项目中经常使用Redis作为分布式锁。
选了Redis分布式锁的几种实现方法,大家来讨论下,看有没有啥问题哈。
- 命令setnx + expire分开写
- setnx + value值是过期时间
- set的扩展命令(set ex px nx)
- set ex px nx + 校验唯一随机值,再删除
10.1 命令setnx + expire分开写
if(jedis.setnx(key,lock_value) == 1){ //加锁 expire(key,100); //设置过期时间 try { do something //业务请求 }catch(){ } finally { jedis.del(key); //释放锁 } }如果执行完
setnx加锁,正要执行expire设置过期时间时,进程crash掉或者要重启维护了,那这个锁就“长生不老”了,别的线程永远获取不到锁啦,所以分布式锁不能这么实现。10.2 setnx + value值是过期时间
long expires = System.currentTimeMillis() + expireTime; //系统时间+设置的过期时间 String expiresStr = String.valueOf(expires); // 如果当前锁不存在,返回加锁成功 if (jedis.setnx(key, expiresStr) == 1) { return true; } // 如果锁已经存在,获取锁的过期时间 String currentValueStr = jedis.get(key); // 如果获取到的过期时间,小于系统当前时间,表示已经过期 if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) { // 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间(不了解redis的getSet命令的小伙伴,可以去官网看下哈) String oldValueStr = jedis.getSet(key_resource_id, expiresStr); if (oldValueStr != null && oldValueStr.equals(currentValueStr)) { // 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才可以加锁 return true; } } //其他情况,均返回加锁失败 return false; }笔者看过有开发小伙伴是这么实现分布式锁的,但是这种方案也有这些缺点:
- 过期时间是客户端自己生成的,分布式环境下,每个客户端的时间必须同步。
- 没有保存持有者的唯一标识,可能被别的客户端释放/解锁。
- 锁过期的时候,并发多个客户端同时请求过来,都执行了
jedis.getSet(),最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被别的客户端覆盖。10.3:set的扩展命令(set ex px nx)(注意可能存在的问题)
if(jedis.set(key, lock_value, "NX", "EX", 100s) == 1){ //加锁 try { do something //业务处理 }catch(){ } finally { jedis.del(key); //释放锁 } }这个方案可能存在这样的问题:
- 锁过期释放了,业务还没执行完。
- 锁被别的线程误删。
10.4 set ex px nx + 校验唯一随机值,再删除
if(jedis.set(key, uni_request_id, "NX", "EX", 100s) == 1){ //加锁 try { do something //业务处理 }catch(){ } finally { //判断是不是当前线程加的锁,是才释放 if (uni_request_id.equals(jedis.get(key))) { jedis.del(key); //释放锁 } } }在这里,判断当前线程加的锁和释放锁是不是一个原子操作。如果调用jedis.del()释放锁的时候,可能这把锁已经不属于当前客户端,会解除他人加的锁。
一般也是用lua脚本代替。lua脚本如下:
if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end;这种方式比较不错了,一般情况下,已经可以使用这种实现方式。但是存在锁过期释放了,业务还没执行完的问题(实际上,估算个业务处理的时间,一般没啥问题了)。
11. 使用过Redisson嘛?说说它的原理
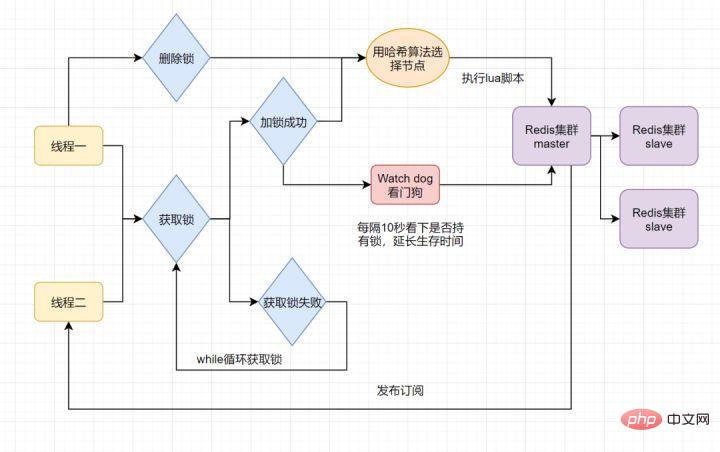
分布式锁可能存在锁过期释放,业务没执行完的问题。有些小伙伴认为,稍微把锁过期时间设置长一些就可以啦。其实我们设想一下,是否可以给获得锁的线程,开启一个定时守护线程,每隔一段时间检查锁是否还存在,存在则对锁的过期时间延长,防止锁过期提前释放。
当前开源框架Redisson就解决了这个分布式锁问题。我们一起来看下Redisson底层原理是怎样的吧:
只要线程一加锁成功,就会启动一个
watch dog看门狗,它是一个后台线程,会每隔10秒检查一下,如果线程1还持有锁,那么就会不断的延长锁key的生存时间。因此,Redisson就是使用Redisson解决了锁过期释放,业务没执行完问题。12. 什么是Redlock算法
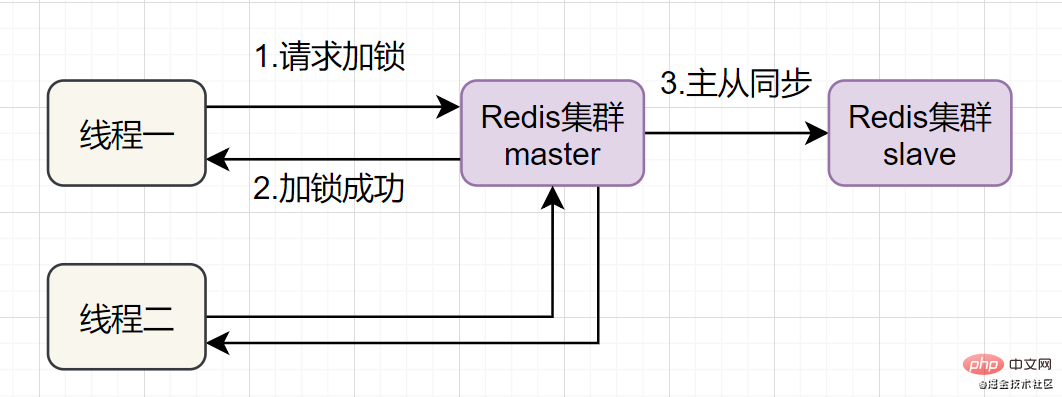
Redis一般都是集群部署的,假设数据在主从同步过程,主节点挂了,Redis分布式锁可能会有哪些问题呢?一起来看些这个流程图:
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
为了解决这个问题,Redis作者 antirez提出一种高级的分布式锁算法:Redlock。Redlock核心思想是这样的:
搞多个Redis master部署,以保证它们不会同时宕掉。并且这些master节点是完全相互独立的,相互之间不存在数据同步。同时,需要确保在这多个master实例上,是与在Redis单实例,使用相同方法来获取和释放锁。
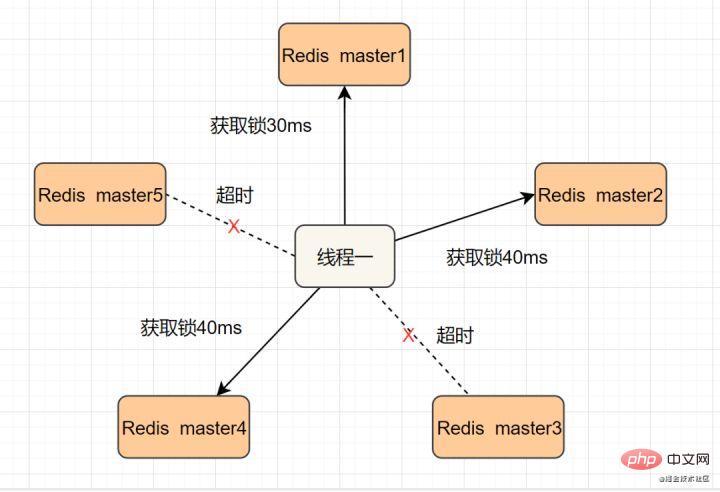
我们假设当前有5个Redis master节点,在5台服务器上面运行这些Redis实例。
RedLock的实现步骤:如下
- 1.获取当前时间,以毫秒为单位。
- 2.按顺序向5个master节点请求加锁。客户端设置网络连接和响应超时时间,并且超时时间要小于锁的失效时间。(假设锁自动失效时间为10秒,则超时时间一般在5-50毫秒之间,我们就假设超时时间是50ms吧)。如果超时,跳过该master节点,尽快去尝试下一个master节点。
- 3.客户端使用当前时间减去开始获取锁时间(即步骤1记录的时间),得到获取锁使用的时间。当且仅当超过一半(N/2+1,这里是5/2+1=3个节点)的Redis master节点都获得锁,并且使用的时间小于锁失效时间时,锁才算获取成功。(如上图,10s> 30ms+40ms+50ms+4m0s+50ms)
- 如果取到了锁,key的真正有效时间就变啦,需要减去获取锁所使用的时间。
- 如果获取锁失败(没有在至少N/2+1个master实例取到锁,有或者获取锁时间已经超过了有效时间),客户端要在所有的master节点上解锁(即便有些master节点根本就没有加锁成功,也需要解锁,以防止有些漏网之鱼)。
简化下步骤就是:
- 按顺序向5个master节点请求加锁
- 根据设置的超时时间来判断,是不是要跳过该master节点。
- 如果大于等于三个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦。
- 如果获取锁失败,解锁!
13. Redis的跳跃表
跳跃表
- Jadual langkau ialah salah satu pelaksanaan asas bagi set zset tertib
- Jadual langkau menyokong purata O(logN) dan kerumitan O(N) kes terburuk nod lookup , nod juga boleh diproses dalam kelompok melalui operasi berurutan.
- Pelaksanaan jadual langkau terdiri daripada dua struktur: zskiplist dan zskiplistNode, di mana zskiplist digunakan untuk menyimpan maklumat jadual langkau (seperti nod pengepala, nod ekor, panjang) dan zskiplistNode digunakan untuk Mewakili nod jadual langkau.
- Senarai langkau adalah berdasarkan senarai terpaut, menambah indeks berbilang peringkat untuk meningkatkan kecekapan carian.
14 Bagaimana MySQL dan Redis memastikan konsistensi penulisan dua kali
- Cache tertunda pemadaman dua kali
- Padam mekanisme percubaan semula cache
- Baca biglog dan padam cache secara tak segerak
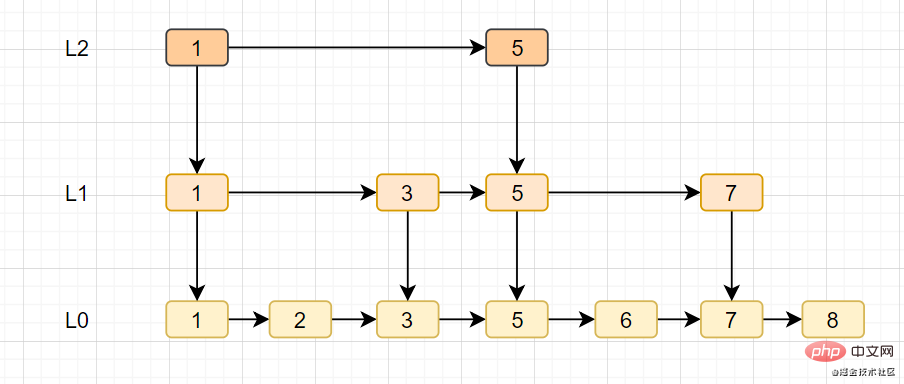
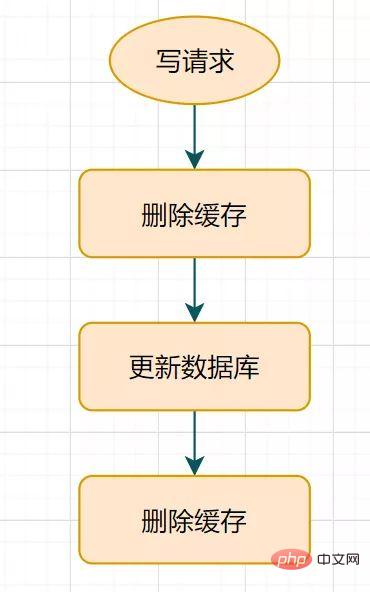
14.1 Menangguhkan pemadaman dua kali?
Apakah pemadaman berganda tertunda? Carta alir adalah seperti berikut:
Proses pemadaman berganda tertunda
- Padam cache dahulu
- kemudian kemas kini pangkalan data
- Tidur sebentar (contohnya, 1 saat) dan padamkan cache sekali lagi.
Berapa lama biasanya masa yang diambil untuk tidur seketika? Adakah mereka semua 1 saat?
Masa tidur ini = masa yang diperlukan untuk membaca data logik perniagaan + beberapa ratus milisaat. Untuk memastikan permintaan baca tamat, permintaan tulis boleh memadamkan data kotor cache yang mungkin dibawa oleh permintaan baca.
Penyelesaian ini tidak buruk Hanya semasa tempoh tidur (contohnya, hanya 1 saat), mungkin terdapat data yang kotor dan perniagaan umum akan menerimanya. Tetapi bagaimana jika Memadamkan cache gagal untuk kali kedua? Data cache dan pangkalan data mungkin masih tidak konsisten, bukan? Bagaimana pula dengan menetapkan masa tamat tempoh semula jadi untuk Kunci dan membiarkannya tamat tempoh secara automatik? Adakah perniagaan perlu menerima ketidakkonsistenan data dalam tempoh tamat tempoh? Atau adakah penyelesaian lain yang lebih baik?
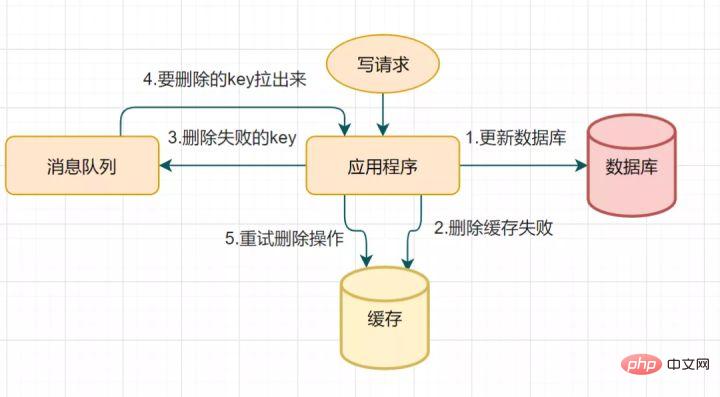
14.2 Mekanisme percubaan semula pemadaman cache
Disebabkan oleh pemadaman dua kali tertunda, langkah kedua memadam cache mungkin gagal, mengakibatkan ketidakkonsistenan data. Anda boleh menggunakan penyelesaian ini untuk mengoptimumkan: Jika pemadaman gagal, padamkannya beberapa kali lagi untuk memastikan pemadaman cache berjaya~ Jadi anda boleh memperkenalkan mekanisme percubaan semula cache pemadaman
Padam cache cuba semula proses Percubaan
- Tulis permintaan untuk mengemas kini pangkalan data
- Cache gagal dipadam atas sebab tertentu
- Letakkan kunci yang gagal pada baris gilir mesej
- Gunakan mesej daripada baris gilir mesej dan dapatkan kunci untuk dipadamkan
- Cuba semula operasi cache pemadaman
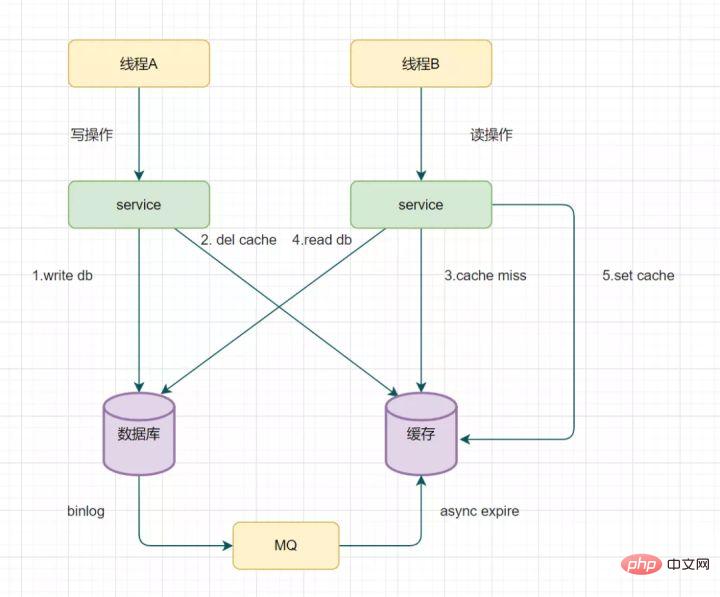
14.3 Baca biglog dan padam cache secara tak segerak
Cuba semula mekanisme cache pemadaman juga Ya, tetapi ia akan menyebabkan banyak pencerobohan kod perniagaan. Malah, ia juga boleh dioptimumkan seperti ini: menghapuskan kunci secara tidak segerak melalui binlog pangkalan data.
Ambil mysql sebagai contoh
- Anda boleh menggunakan saluran Alibaba untuk mengumpul log binlog dan menghantarnya ke baris gilir MQ
- Kemudian Sahkan dan proses mesej kemas kini ini melalui mekanisme ACK, padamkan cache dan pastikan ketekalan cache data
15. Mengapakah Redis bertukar kepada multi-threading selepas 6.0?
- Sebelum Redis 6.0, apabila Redis memproses permintaan pelanggan, termasuk soket membaca, menghurai, melaksanakan, menulis soket, dsb., semuanya diproses oleh urutan utama bersiri. dipanggil "benang tunggal".
- Mengapa anda tidak menggunakan multi-threading sebelum Redis 6.0? Apabila menggunakan Redis, hampir tiada situasi di mana CPU menjadi hambatan terutamanya oleh memori dan rangkaian. Sebagai contoh, pada sistem Linux biasa, Redis boleh mengendalikan 1 juta permintaan sesaat dengan menggunakan saluran paip, jadi jika aplikasi terutamanya menggunakan arahan O(N) atau O(log(N)), ia tidak akan mengambil banyak CPU.
Penggunaan redis berbilang benang tidak bermakna ia meninggalkan sepenuhnya benang tunggal Redis masih menggunakan model berbenang tunggal untuk memproses permintaan pelanggan Ia hanya menggunakan berbilang benang untuk mengendalikan pembacaan data dan penulisan dan penghuraian protokol Untuk melaksanakan arahan, ia masih menggunakan berulir Tunggal.
Tujuan ini adalah kerana kesesakan prestasi redis adalah IO rangkaian dan bukannya CPU Menggunakan multi-threading boleh meningkatkan kecekapan membaca dan menulis IO, dengan itu meningkatkan prestasi keseluruhan redis.
16 Mari kita bincangkan tentang mekanisme transaksi Redis
Redis melaksanakan mekanisme transaksi melalui satu set perintah seperti MULTI, EXEC dan WATCH. Urus niaga menyokong pelaksanaan berbilang arahan pada satu masa, dan semua arahan dalam urus niaga akan bersiri. Semasa proses pelaksanaan transaksi, arahan dalam baris gilir akan disiri dan dilaksanakan mengikut tertib, dan permintaan arahan yang dikemukakan oleh pelanggan lain tidak akan dimasukkan ke dalam urutan perintah pelaksanaan transaksi.
Ringkasnya, transaksi Redis ialah pelaksanaan berurutan, sekali dan eksklusif bagi siri perintah dalam baris gilir.
Proses pelaksanaan transaksi Redis adalah seperti berikut:Mulakan transaksi (MULTI)
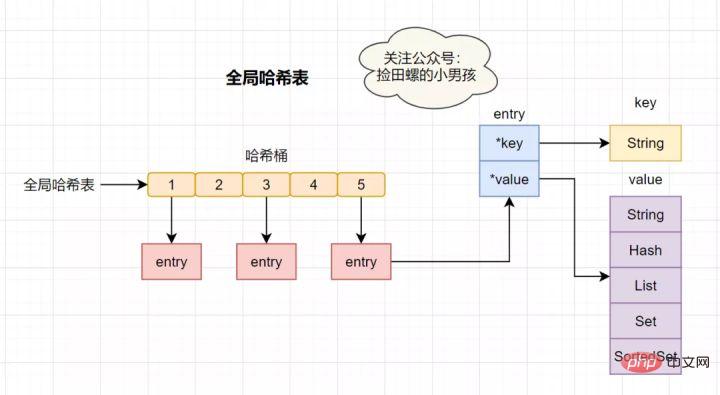
17 Perkara yang perlu dilakukan jika konflik Hash Redis Redis ialah pangkalan data dalam memori K-V, yang menggunakan cincang global untuk menyimpan semua pasangan nilai kunci. . Jadual cincang ini terdiri daripada berbilang baldi cincang Elemen entri dalam baldi cincang menyimpan- Arahan perintah
- Laksanakan transaksi (EXEC), batalkan urus niaga (DISCARD)
kunci dan penunjuk nilai, di mana *kunci menunjuk ke kunci sebenar dan *nilai menunjuk kepada nilai sebenar .
Kelajuan carian jadual cincang sangat pantas, agak serupa dengan HashMap dalam Java, yang membolehkan kami mencari pasangan nilai kunci dengan cepat dalam kerumitan masa O(1). Mula-mula, hitung nilai cincang melalui kunci, cari lokasi baldi cincang yang sepadan, kemudian cari entri dan cari data yang sepadan dalam entri.
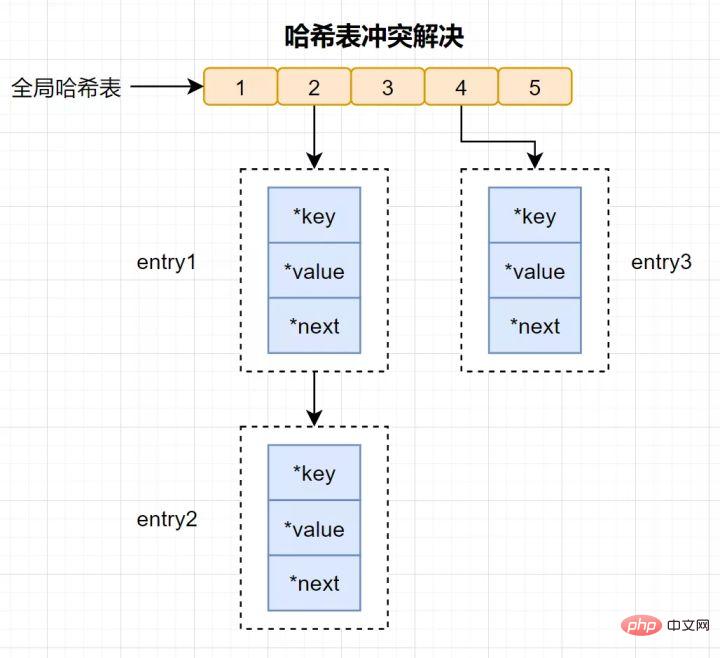
Apakah perlanggaran cincang?
Konflik cincang: Nilai cincang yang sama dikira melalui kunci yang berbeza, menghasilkan baldi cincang yang sama.
Untuk menyelesaikan konflik cincang, Redis menggunakan pencincangan rantai. Pencincangan berantai bermakna berbilang elemen dalam baldi cincang yang sama disimpan dalam senarai terpaut dan ia disambungkan secara bergilir menggunakan penunjuk.
Sesetengah pembaca mungkin masih mempunyai soalan: elemen pada rantaian konflik cincang hanya boleh dicari satu demi satu melalui penunjuk dan kemudian dikendalikan. Apabila banyak data dimasukkan ke dalam jadual cincang, lebih banyak konflik akan berlaku, lebih lama senarai pautan konflik dan kecekapan pertanyaan akan dikurangkan.
Untuk mengekalkan kecekapan, Redis akan melakukan operasi rehash pada jadual cincang, yang bermaksud menambah baldi cincang dan mengurangkan konflik. Untuk menjadikan rehash lebih cekap, Redis juga menggunakan dua jadual cincang global secara lalai, satu untuk kegunaan semasa, dipanggil jadual cincang utama, dan satu untuk pengembangan, dipanggil jadual cincang sandaran .
18 Semasa penjanaan RDB, bolehkah Redis mengendalikan permintaan tulis pada masa yang sama?
Ya, Redis menyediakan dua arahan untuk menjana RDB iaitu simpan dan bgsave.
- Jika ia adalah arahan simpan, ia akan menyekat kerana ia dilaksanakan oleh utas utama.
- Jika ia adalah arahan bgsave, ia menghentikan proses kanak-kanak untuk menulis fail RDB Kegigihan syot kilat dikendalikan sepenuhnya oleh proses anak, dan proses induk boleh terus memproses permintaan pelanggan.
19. Apakah protokol yang digunakan di bahagian bawah Redis
RESP, nama penuh bahasa Inggeris ialah Redis Serialization Protocol, iaitu protokol bersiri yang direka khas untuk redis ini sebenarnya Ia telah pun muncul dalam redis versi 1.2, tetapi hanya dalam redis2.0 yang akhirnya menjadi standard protokol komunikasi redis.
RESP terutamanya mempunyai kelebihan pelaksanaan yang mudah, kelajuan penghuraian yang pantas dan kebolehbacaan yang baik .
20. Bloom Filter
Untuk menangani masalah cache penetrasi, kita boleh menggunakan Bloom Filter. Apakah penapis mekar?
Penapis Bloom ialah struktur data yang menggunakan ruang yang sangat sedikit. Ia terdiri daripada vektor perduaan panjang dan satu set fungsi pemetaan Hash Ia digunakan untuk mendapatkan semula sama ada elemen berada dalam satu set, ruang Kecekapan dan masa pertanyaan adalah lebih baik daripada algoritma umum Kelemahannya ialah terdapat kadar salah pengecaman dan kesukaran pemadaman tertentu.
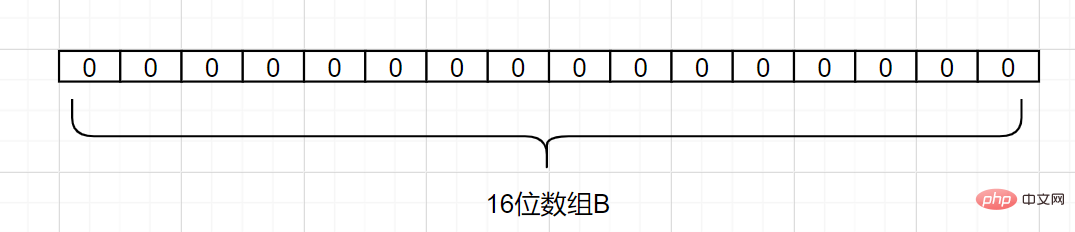
Apakah prinsip penapis Bloom? Andaikan kita mempunyai set A, dan terdapat n elemen dalam A. Menggunakan fungsi k pencincangan , setiap elemen dalam A dipetakan ke kedudukan berbeza dalam tatasusunan B dengan panjang bit, dan nombor perduaan pada kedudukan ini Kedua-duanya ditetapkan kepada 1 . Jika elemen yang hendak disemak dipetakan oleh fungsi cincang k ini dan didapati bahawa nombor perduaan dalam kedudukan knya semuanya 1, elemen ini berkemungkinan tergolong dalam set A. Jika tidak, Mesti tidak tergolong dalam set A.
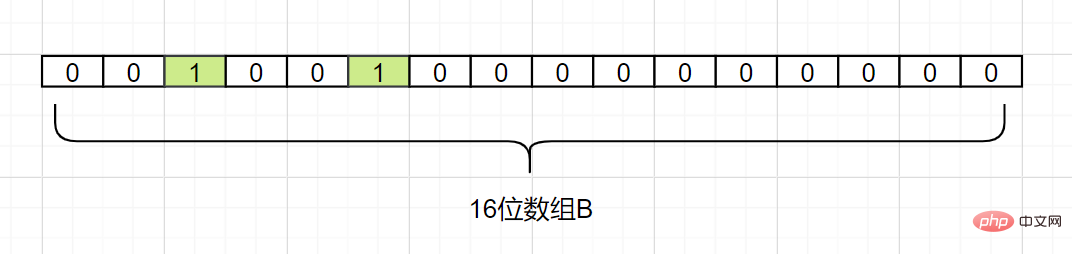
Mari kita ambil contoh mudah. Katakan set A mempunyai 3 elemen, iaitu {d1, d2, d3}. Terdapat 1 fungsi hash iaitu Hash1. Sekarang petakan setiap elemen A kepada tatasusunan B dengan panjang 16 bit.
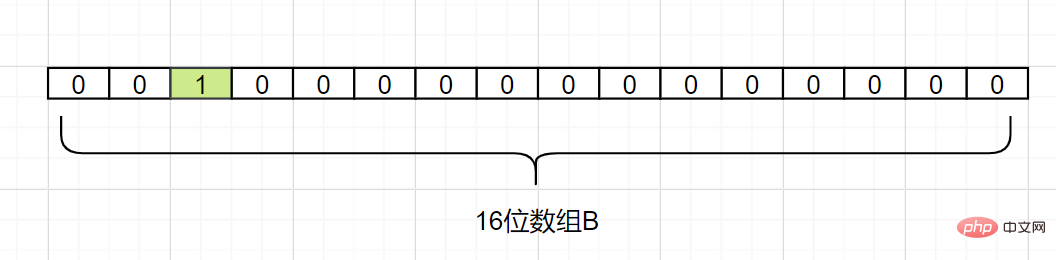
Kami kini memetakan d1. Dengan mengandaikan Hash1 (d1) = 2, kami menukar grid dengan subskrip 2 dalam tatasusunan B kepada 1, seperti berikut:
Kami kini memetakan d2, dengan mengandaikan Hash1(d2) = 5, kami juga menukar grid dengan subskrip 5 dalam tatasusunan B kepada 1, seperti berikut:
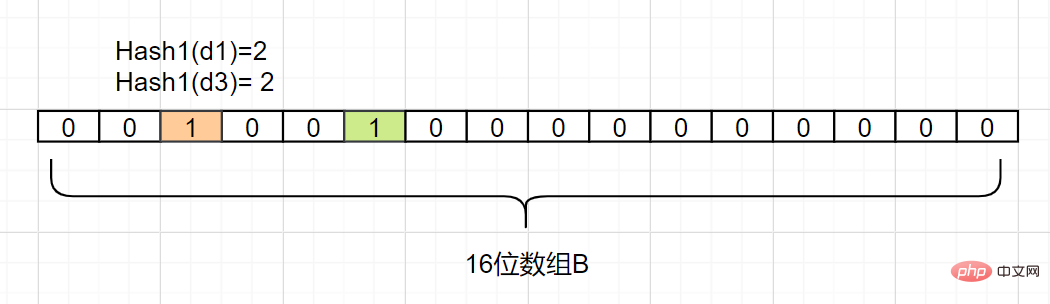
Kemudian kami memetakan d3 juga dengan mengandaikan bahawa Hash1 (d3) juga sama dengan 2, ia juga menetapkan subskrip kepada 2 Grid subskrip 1:
<.>Oleh itu, kami ingin mengesahkan sama ada elemen dn berada dalam set A. Kami hanya perlu mengira subskrip indeks yang diperolehi oleh Hash1 (dn), selagi ia adalah 0, itu bermakna elemen ini
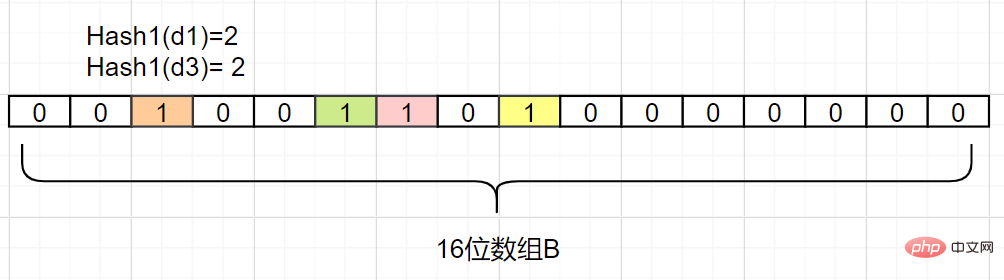
tiada dalam set A Bagaimana jika subskrip indeks ialah 1? Kemudian elemen mungkin menjadi elemen dalam A. Kerana anda lihat, nilai subskrip yang diperoleh oleh d1 dan d3 mungkin kedua-duanya adalah 1, atau ia mungkin dipetakan oleh nombor lain Penapis Bloom mempunyai kelemahan ini: akan terdapat cincang Palsu. positif yang disebabkan oleh perlanggaran , terdapat ralat dalam penghakiman.
Bagaimana untukmengurangkan ralat ini?
- Bina lebih banyak pemetaan fungsi cincang untuk mengurangkan kebarangkalian perlanggaran cincang
- Pada masa yang sama, meningkatkan panjang bit tatasusunan B boleh meningkatkan julat data yang dijana oleh fungsi cincang dan mengurangkan kadar cincangan. jika mereka tidak Baik, seperti berikut:
Walaupun terdapat ralat, kita dapati bahawa penapis Bloom tidak
menyimpan data lengkap, ia hanya menggunakan satu siri Fungsi peta hash mengira kedudukan dan kemudian mengisi vektor binari. Jika bilangan
, penapis Bloom boleh menjimatkan banyak ruang storan melalui kadar ralat yang sangat kecil, yang agak menjimatkan kos.Pada masa ini terdapat perpustakaan sumber terbuka yang melaksanakan penapis Bloom dengan sewajarnya, seperti Pustaka kelas Guava Google, perpustakaan kelas Algebird Twitter, yang boleh diakses dengan mudah, atau berdasarkan perpustakaan Redis sendiri Ia adalah juga mungkin untuk Bitmaps melaksanakan reka bentuknya sendiri.
Untuk lebih banyak pengetahuan berkaitan pengaturcaraan, sila lawati:Video Pengaturcaraan! !
 Tamat tempoh masa
Tamat tempoh masa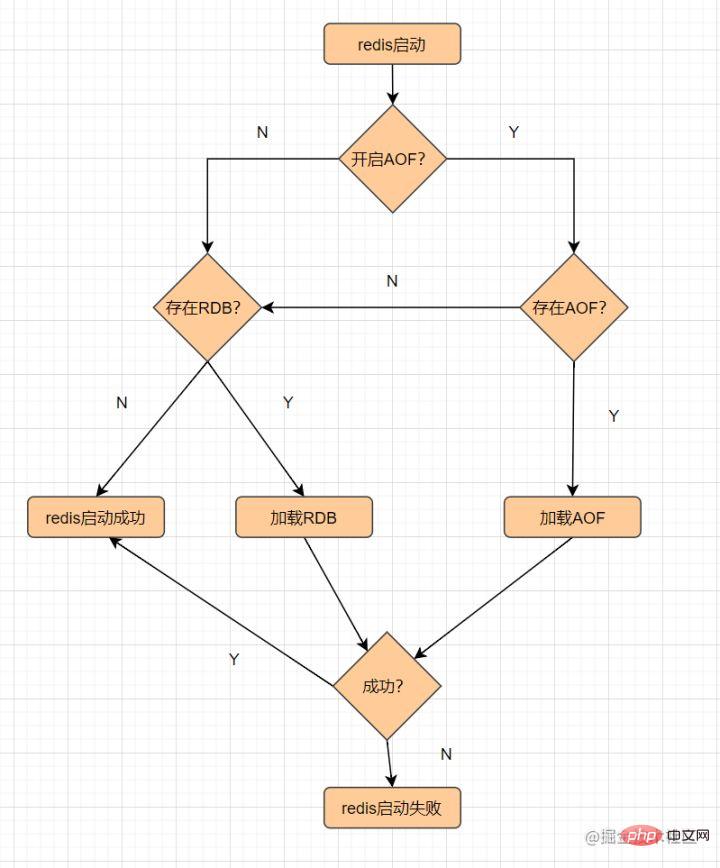


 besar
besarAtas ialah kandungan terperinci Ringkasan 20 soalan dan jawapan temu bual klasik Redis (kongsi). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Bagaimana untuk menggunakan Redis dalam Node.js? Ternyata ia semudah itu!
- Analisis ringkas tentang strategi kegigihan Redis
- Fahami redis cache avalanche, pecahan cache dan penembusan cache dalam satu artikel
- Ringkaskan penggunaan zrangeByScore dalam phpredis
- Pembinaan seni bina ketersediaan tinggi Redis kepada analisis prinsip