
Rumah >pangkalan data >Redis >Analisis ringkas tentang strategi kegigihan Redis
Analisis ringkas tentang strategi kegigihan Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-11-09 14:35:411890semak imbas
Artikel ini membawa anda pengetahuan yang berkaitan tentang Redis, yang terutamanya memperkenalkan kandungan yang berkaitan tentang strategi kegigihan RDB merujuk kepada proses menyimpan data dalam ingatan dalam selang masa yang ditetapkan ditulis pada cakera. Mari kita lihat. Saya harap ia akan membantu semua orang.

Pembelajaran yang disyorkan: Tutorial video Redis
Redis (Pelayan Kamus Jauh), perkhidmatan kamus jauh, ialah Perkhidmatan penyimpanan data cache dalam memori sumber terbuka. Ditulis dalam bahasa ANSI C, ia menyokong rangkaian, berasaskan memori dan jenis log berterusan, storan data Nilai Kunci, dan menyediakan API dalam berbilang bahasa
Redis ialah pangkalan data dalam memori, dan data disimpan dalam ingatan, untuk mengelakkan kehilangan data kekal yang disebabkan oleh proses keluar, data dalam Redis perlu disimpan secara berkala dari memori ke cakera keras dalam beberapa bentuk (data atau arahan). Apabila Redis dimulakan semula pada masa akan datang, gunakan fail yang berterusan untuk mencapai pemulihan data. Di samping itu, fail berterusan boleh disalin ke lokasi terpencil untuk tujuan sandaran bencana. Terdapat dua mekanisme kegigihan untuk Redis:
- RDB (Redis Data Base) petikan memori
- AOF (Add Only File) log inkremental
RDB menyimpan data semasa ke cakera keras, dan AOF menyimpan setiap arahan tulis yang dilaksanakan ke cakera keras (serupa dengan Binlog MySQL). Kegigihan AOF mempunyai prestasi masa nyata yang lebih baik, iaitu, kurang data yang hilang apabila proses keluar tanpa dijangka.
RDB Kegigihan
Pengenalan
RDB ( Redis Pangkalan Data) merujuk kepada menulis petikan set data dalam ingatan ke cakera dalam selang masa yang ditetapkan RDB ialah petikan memori (jujukan binari data memori (dalam bentuk kegigihan), setiap kali syot kilat dijana daripada Redis untuk menyandarkan data sepenuhnya.
Kelebihan:
- Storan padat, menjimatkan ruang memori.
- Kelajuan pemulihan sangat pantas.
- Sesuai untuk senario sandaran penuh dan replikasi penuh, dan sering digunakan untuk pemulihan bencana (senario dengan keperluan yang agak rendah untuk integriti dan konsistensi data).
Kelemahan:
- Mudah untuk kehilangan data dan data ditukar dalam pelayan Redis antara dua syot kilat.
- RDB menggunakan sub-proses garpu untuk menyandarkan sepenuhnya petikan memori Ia merupakan operasi berwajaran berat dan mahal untuk dilakukan dengan kerap.
Struktur fail RDB
Secara lalai, Redis menyimpan petikan pangkalan data dalam fail bernama dump.rdb dalam fail binari. Struktur fail RDB terdiri daripada lima bahagian:
(1) REDIS rentetan malar dengan panjang 5 bait.
(2) 4-bait db_version, mengenal pasti versi fail RDB.
(3) pangkalan data: panjang tidak tentu, termasuk sifar atau lebih pangkalan data dan data pasangan nilai kunci dalam setiap pangkalan data.
(4) Pemalar EOF 1-bait, menunjukkan penghujung kandungan fail.
(5) check_sum: 8-bait integer tidak ditandatangani, menyimpan checksum.

Contoh struktur data, berikut ialah kes di mana pangkalan data [0] dan pangkalan data [3] mempunyai data:

Penciptaan fail RDB
Pencetus arahan manual
Untuk mencetuskan kegigihan RDB secara manual, anda boleh menggunakan perintah save dan Perintah bgsave Perbezaan antara kedua-dua arahan ini adalah seperti berikut:
save: Melaksanakan perintah save menyekat operasi lain Redis, yang akan menyebabkan Redis tidak dapat bertindak balas kepada permintaan pelanggan dan tidak disyorkan.
bgsave: Jalankan perintah bgsave, Redis mencipta proses anak di latar belakang dan menyimpan syot kilat secara tidak segerak Pada masa ini, Redis masih boleh membalas permintaan pelanggan.
Penjimatan selang automatik
Secara lalai, Redis menyimpan petikan pangkalan data dalam fail binari bernama dump.rdb. Redis boleh ditetapkan untuk menyimpan set data secara automatik apabila syarat "set data mempunyai sekurang-kurangnya M perubahan dalam N saat" dipenuhi.
Sebagai contoh, tetapan berikut akan menyebabkan Redis menyimpan set data secara automatik apabila syarat "sekurang-kurangnya 10 kekunci telah ditukar dalam masa 60 saat" dipenuhi: save 60 10.
Konfigurasi lalai Redis adalah seperti berikut Penyimpanan automatik boleh dicetuskan jika salah satu daripada tiga tetapan dipenuhi:
save 60 10000 save 300 10 save 900 1
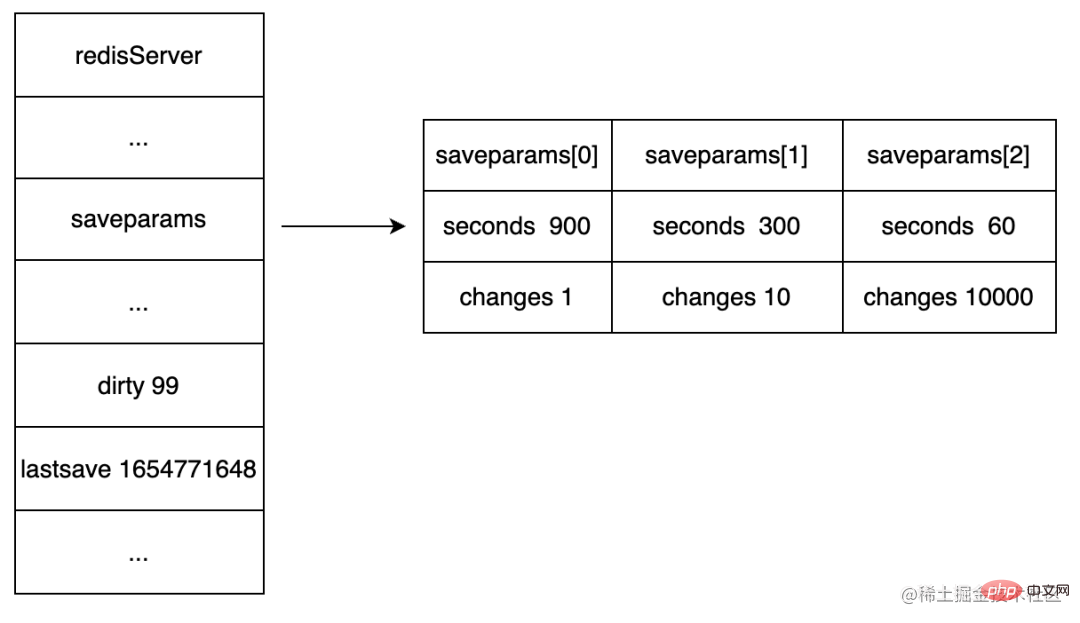
Struktur data konfigurasi simpanan automatik<.>
direkodkan Pelayan mencetuskan atribut bagi keadaan BGSAVE automatik. saveparams
Atribut: Catatkan masa apabila pelayan terakhir dilaksanakan lastsave atau SAVE. BGSAVE
Sifat: dan berapa banyak penulisan yang telah dibuat oleh pelayan sejak kali terakhir fail RDB disimpan. dirty
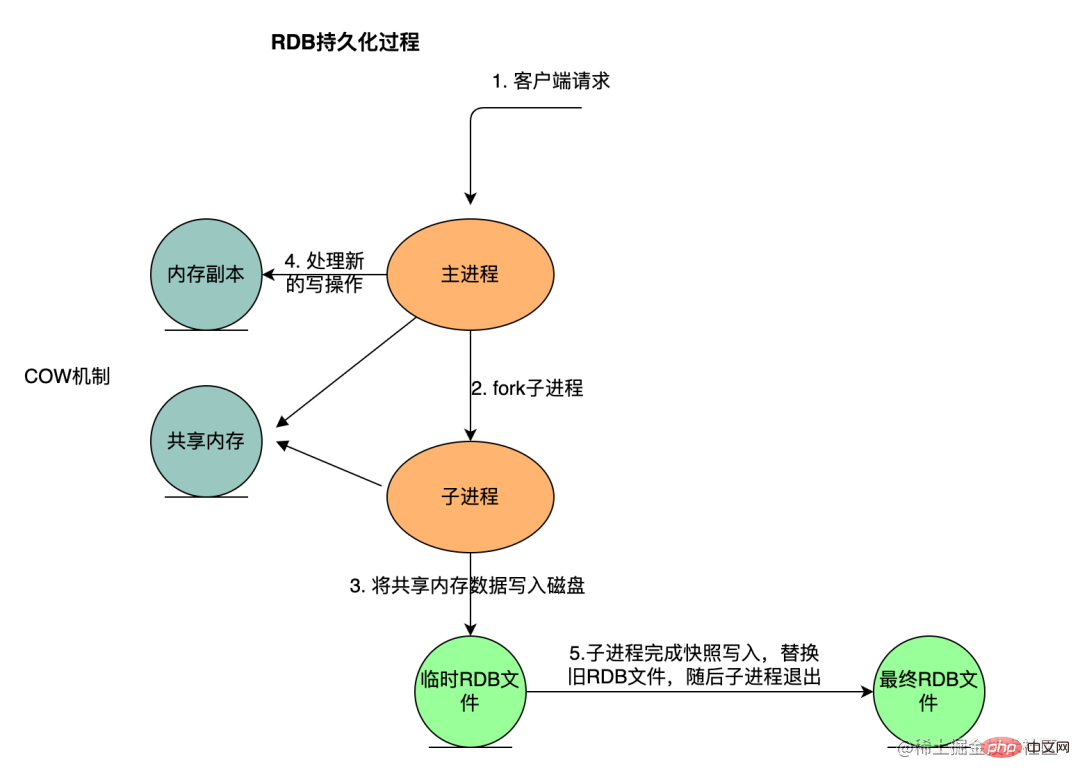
- Proses induk Redis terlebih dahulu menentukan sama ada simpan sedang dilaksanakan atau proses anak bgsave/bgrewriteaof, jika ia sedang dilaksanakan, arahan bgsave akan kembali secara langsung. Proses anak bgsave/bgrewriteaof tidak boleh dilaksanakan pada masa yang sama, terutamanya disebabkan oleh pertimbangan prestasi: dua proses anak serentak melaksanakan sejumlah besar operasi tulis cakera pada masa yang sama, yang mungkin menyebabkan masalah prestasi yang serius. Proses induk menjalankan operasi fork untuk mencipta proses anak Semasa proses ini, proses induk disekat dan Redis tidak boleh melaksanakan sebarang arahan daripada klien. Selepas proses induk bercabang, arahan bgsave mengembalikan mesej "Penyimpanan latar belakang dimulakan" dan tidak lagi menyekat proses induk dan boleh bertindak balas kepada arahan lain.
- Proses kanak-kanak menjana fail syot kilat data memori.
- Operasi tulis baharu yang diterima oleh proses induk dalam tempoh ini ditulis menggunakan mekanisme COW.
- Proses anak melengkapkan penulisan syot kilat, menggantikan fail RDB lama, dan kemudian proses anak itu keluar.
Dalam langkah menjana fail RDB, bagaimana untuk menangani ketidakkonsistenan data semasa proses penyegerakan ke cakera dan penulisan berterusan? Adakah terdapat sebarang kesan perniagaan apabila menjana fail RDB syot kilat?
Peranan sub-proses Fork
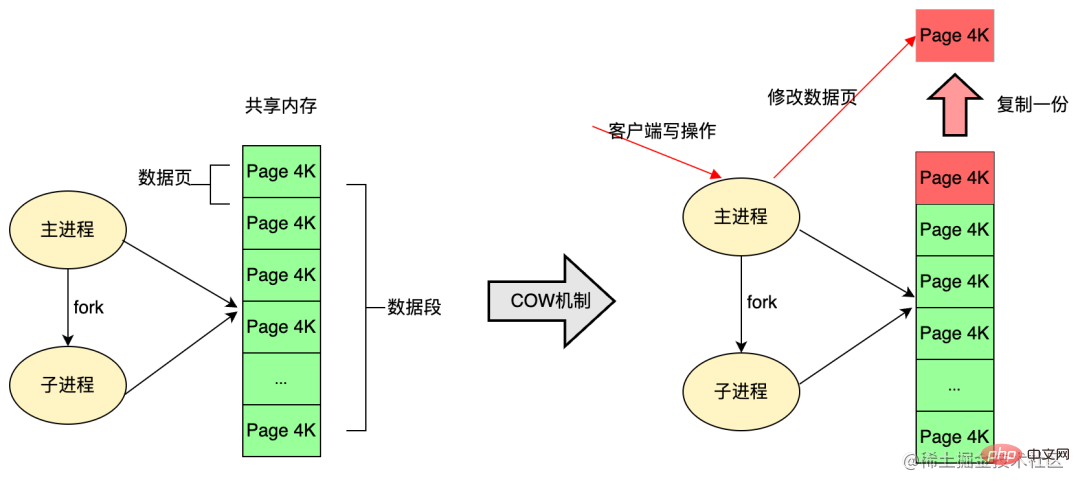
Seperti yang dinyatakan di atas, semasa proses kegigihan RDB, proses utama akan menghentikan sub-proses untuk bertanggungjawab untuk sandaran RDB Ini mudah Biar saya memperkenalkan fork:- Sebuah program dalam sistem pengendalian Linux, fork akan menjana proses anak yang betul-betul sama dengan proses induk. Semua data proses anak adalah konsisten dengan proses induk, tetapi proses anak adalah proses yang benar-benar baru dan mempunyai hubungan proses ibu bapa-anak dengan proses asal.
- Atas sebab kecekapan, sistem pengendalian Linux menggunakan mekanisme copy-on-write COW (Copy On Write) Proses anak fork secara amnya berkongsi bahagian memori fizikal dengan proses induk . Apabila memori dalam ruang proses diubah suai, salinan ruang memori akan disalin.
AOF 持久化
简介
AOF (Append Only File) 是把所有对内存进行修改的指令(写操作)以独立日志文件的方式进行记录,重启时通过执行 AOF 文件中的 Redis 命令来恢复数据。类似MySql bin-log 原理。AOF 能够解决数据持久化实时性问题,是现在 Redis 持久化机制中主流的持久化方案。
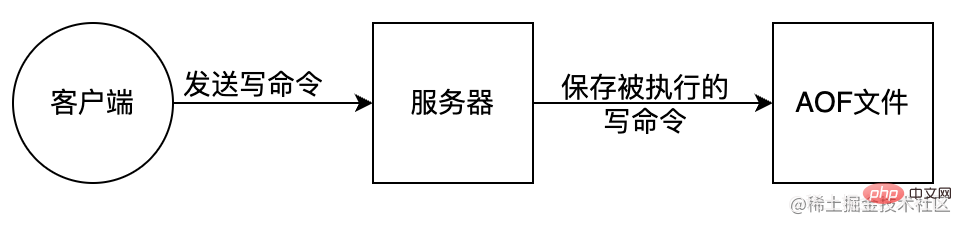
优点:
- 数据的备份更加完整,丢失数据的概率更低,适合对数据完整性要求高的场景
- 日志文件可读,AOF 可操作性更强,可通过操作日志文件进行修复
缺点:
- AOF 日志记录在长期运行中逐渐庞大,恢复起来非常耗时,需要定期对 AOF 日志进行瘦身处理
- 恢复备份速度比较慢
- 同步写操作频繁会带来性能压力
AOF 文件内容
被写入 AOF 文件的所有命令都是以 RESP 格式保存的,是纯文本格式保存在 AOF 文件中。
Redis 客户端和服务端之间使用一种名为
RESP(REdis Serialization Protocol)的二进制安全文本协议进行通信。
下面以一个简单的 SET 命令进行举例:
redis> SET mykey "hello" //客户端命令OK
客户端封装为以下格式(每行用 \r\n分隔)
*3$3SET$5mykey$5hello
AOF 文件中记录的文本内容如下
*2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n //多出一个SELECT 0 命令,用于指定数据库,为系统自动添加 *3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$5\r\nhello\r\n
AOF 持久化实现
AOF 持久化方案进行备份时,客户端所有请求的写命令都会被追加到 AOF 缓冲区中,缓冲区中的数据会根据 Redis 配置文件中配置的同步策略来同步到磁盘上的 AOF 文件中,追加保存每次写的操作到文件末尾。同时当 AOF 的文件达到重写策略配置的阈值时,Redis 会对 AOF 日志文件进行重写,给 AOF 日志文件瘦身。Redis 服务重启的时候,通过加载 AOF 日志文件来恢复数据。
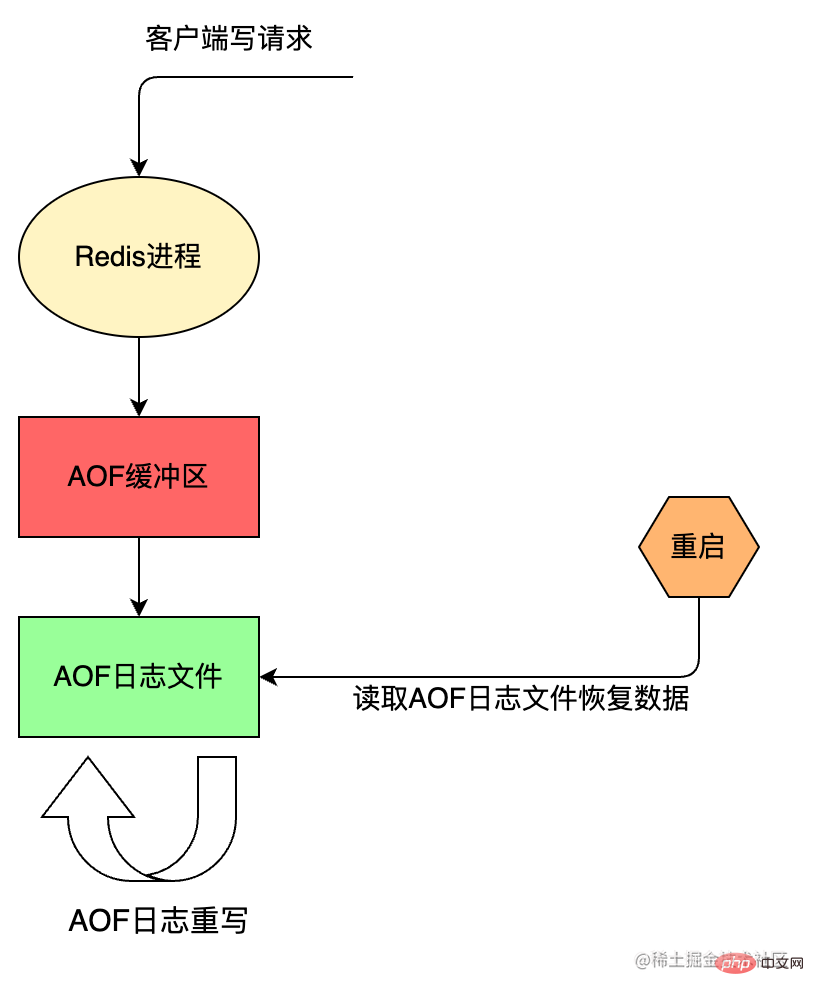
AOF 的执行流程包括:
命令追加(append)
Redis 先将写命令追加到缓冲区 aof_buf,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘 IO 成为 Redis 负载的瓶颈。
struct redisServer {
//其他域... sds aof_buf; // sds类似于Java中的String //其他域...}
文件写入(write)和文件同步(sync)
根据不同的同步策略将 aof_buf 中的内容同步到硬盘;
Linux 操作系统中为了提升性能,使用了页缓存(page cache)。当我们将 aof_buf 的内容写到磁盘上时,此时数据并没有真正的落盘,而是在 page cache 中,为了将 page cache 中的数据真正落盘,需要执行 fsync / fdatasync 命令来强制刷盘。这边的文件同步做的就是刷盘操作,或者叫文件刷盘可能更容易理解一些。
AOF 缓存区的同步文件策略由参数 appendfsync 控制,有三种同步策略,各个值的含义如下:
-
always:命令写入 aof_buf 后立即调用系统 write 操作和系统 fsync 操作同步到 AOF 文件,fsync 完成后线程返回。这种情况下,每次有写命令都要同步到 AOF 文件,硬盘 IO 成为性能瓶颈,Redis 只能支持大约几百TPS写入,严重降低了 Redis 的性能;即便是使用固态硬盘(SSD),每秒大约也只能处理几万个命令,而且会大大降低 SSD 的寿命。可靠性较高,数据基本不丢失。
-
no:命令写入 aof_buf 后调用系统 write 操作,不对 AOF 文件做 fsync 同步;同步由操作系统负责,通常同步周期为30秒。这种情况下,文件同步的时间不可控,且缓冲区中堆积的数据会很多,数据安全性无法保证。
-
everysec:命令写入 aof_buf 后调用系统 write 操作,write 完成后线程返回;fsync 同步文件操作由专门的线程每秒调用一次。everysec 是前述两种策略的折中,是性能和数据安全性的平衡,因此是 Redis 的默认配置,也是我们推荐的配置。
文件重写(rewrite)
定期重写 AOF 文件,达到压缩的目的。
AOF 重写是 AOF 持久化的一个机制,用来压缩 AOF 文件,通过 fork 一个子进程,重新写一个新的 AOF 文件,该次重写不是读取旧的 AOF 文件进行复制,而是读取内存中的Redis数据库,重写一份 AOF 文件,有点类似于 RDB 的快照方式。
文件重写之所以能够压缩 AOF 文件,原因在于:
- 过期的数据不再写入文件
- 无效的命令不再写入文件:如有些数据被重复设值(set mykey v1, set mykey v2)、有些数据被删除了(sadd myset v1, del myset)等等
- 多条命令可以合并为一个:如 sadd myset v1, sadd myset v2, sadd myset v3 可以合并为 sadd myset v1 v2 v3。不过为了防止单条命令过大造成客户端缓冲区溢出,对于 list、set、hash、zset类型的 key,并不一定只使用一条命令;而是以某个常量为界将命令拆分为多条。这个常量在 redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD 中定义,不可更改,2.9版本中值是64。
AOF 重写
前面提到 AOF 的缺点时,说过 AOF 属于日志追加的形式来存储 Redis 的写指令,这会导致大量冗余的指令存储,从而使得 AOF 日志文件非常庞大,比如同一个 key 被写了 10000 次,最后却被删除了,这种情况不仅占内存,也会导致恢复的时候非常缓慢,因此 Redis 提供重写机制来解决这个问题。Redis 的 AOF 持久化机制执行重写后,保存的只是恢复数据的最小指令集,我们如果想手动触发可以使用如下指令:
bgrewriteaof
文件重写时机
相关参数:
- aof_current_size:表示当前 AOF 文件空间
- aof_base_size:表示上一次重写后 AOF 文件空间
- auto-aof-rewrite-min-size: 表示运行 AOF 重写时文件的最小体积,默认为64MB
- auto-aof-rewrite-percentage: 表示当前 AOF 重写时文件空间(aof_current_size)超过上一次重写后 AOF 文件空间(aof_base_size)的比值多少后会重写。
同时满足下面两个条件,则触发 AOF 重写机制:
- aof_current_size 大于 auto-aof-rewrite-min-size
- 当前 AOF 相比上一次 AOF 的增长率:(aof_current_size - aof_base_size)/aof_base_size 大于或等于 auto-aof-rewrite-percentage
AOF 重写流程如下:
bgrewriteaof 触发重写,判断是否存在 bgsave 或者 bgrewriteaof 正在执行,存在则等待其执行结束再执行
- 主进程 fork 子进程,防止主进程阻塞无法提供服务,类似 RDB
子进程遍历 Redis 内存快照中数据写入临时 AOF 文件,同时会将新的写指令写入 aof_buf 和 aof_rewrite_buf 两个重写缓冲区,前者是为了写回旧的 AOF 文件,后者是为了后续刷新到临时 AOF 文件中,防止快照内存遍历时新的写入操作丢失
子进程结束临时 AOF 文件写入后,通知主进程
主进程会将上面 3 中的 aof_rewirte_buf 缓冲区中的数据写入到子进程生成的临时 AOF 文件中
- 主进程使用临时 AOF 文件替换旧 AOF 文件,完成整个重写过程。
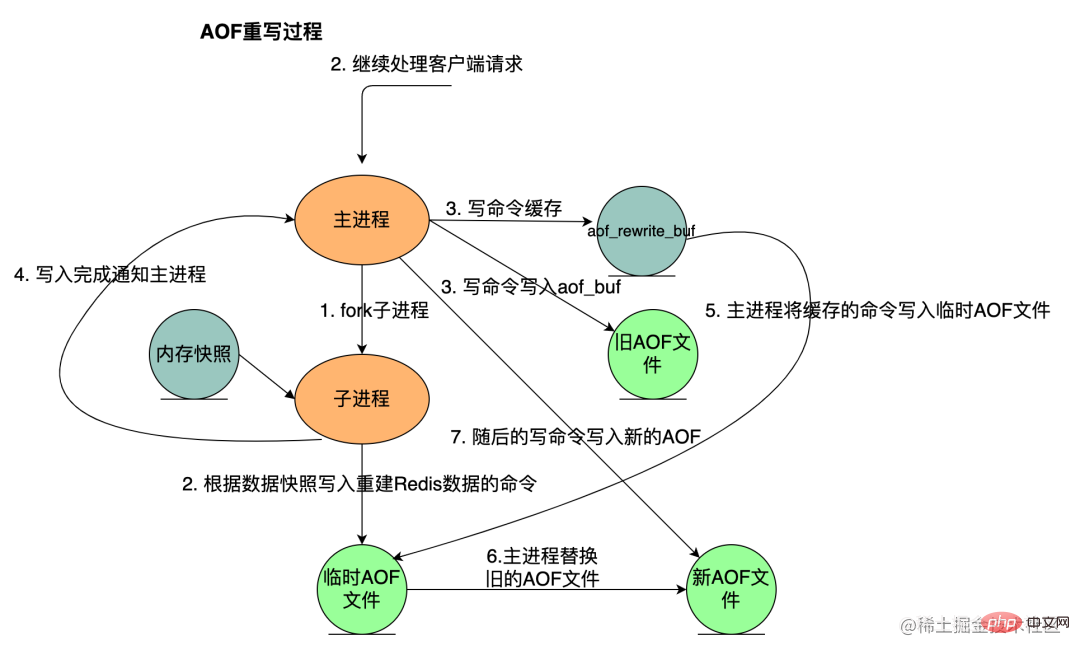
在实际中,为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序会检查集合元素数量是否超过 REDIS_AOF_REWRITE_ITEMS_PER_CMD 常量的值,如果超过了,则会使用多个命令来记录,而不单单使用一条命令。
Redis 2.9版本中该常量为64,如果一个命令的集合键包含超过了64个元素,重写程序会拆成多个命令。

AOF重写是一个有歧义的名字,该功能是通过直接读取数据库的键值对实现的,程序无需对现有AOF文件进行任何读入、分析或者写入操作。
思考
AOF 与 WAL
Redis 为什么考虑使用 AOF 而不是 WAL 呢?
很多数据库都是采用的 Write Ahead Log(WAL)写前日志,其特点就是先把修改的数据记录到日志中,再进行写数据的提交,可以方便通过日志进行数据恢复。
但是 Redis 采用的却是 AOF(Append Only File)写后日志,特点就是先执行写命令,把数据写入内存中,再记录日志。
Jika anda membiarkan sistem melaksanakan arahan terlebih dahulu, hanya arahan itu akan direkodkan dalam log jika ia boleh dilaksanakan dengan jayanya. Oleh itu, Redis menggunakan pengelogan pasca tulis untuk mengelakkan daripada merekod arahan yang salah.
Sebab lain ialah AOF hanya merekodkan log selepas arahan dilaksanakan, jadi ia tidak akan menyekat operasi tulis semasa.
Interaksi antara AOF dan RDB
Dalam Redis dengan nombor versi lebih besar daripada atau sama dengan 2.4, BGREWRITEAOF tidak boleh dilaksanakan semasa pelaksanaan BGSAVE. Sebaliknya, BGSAVE tidak boleh dilaksanakan semasa pelaksanaan BGREWRITEAOF. Ini menghalang dua proses latar belakang Redis daripada melakukan operasi I/O berat pada cakera pada masa yang sama.
Jika BGSAVE sedang melaksanakan dan pengguna secara eksplisit memanggil arahan BGREWRITEAOF, pelayan akan membalas dengan status OK kepada pengguna dan memaklumkan pengguna bahawa BGREWRITEAOF telah dijadualkan untuk pelaksanaan: BGREWRITEAOF secara rasmi akan bermula sebaik sahaja BGSAVE selesai. .
Apabila Redis bermula, jika kedua-dua kegigihan RDB dan kegigihan AOF dihidupkan, program akan memberi keutamaan untuk menggunakan fail AOF untuk memulihkan set data, kerana data yang disimpan dalam fail AOF biasanya yang paling lengkap.
Kegigihan hibrid
Selepas Redis 4.0, kebanyakan senario penggunaan tidak akan menggunakan RDB atau AOF sahaja sebagai mekanisme kegigihan, tetapi akan mengambil kira kelebihan penggunaan campuran . Sebabnya ialah walaupun RDB pantas, ia akan kehilangan banyak data dan tidak dapat menjamin integriti data walaupun AOF boleh memastikan integriti data sebanyak mungkin, prestasinya sememangnya kritikan, seperti memainkan semula dan memulihkan data.
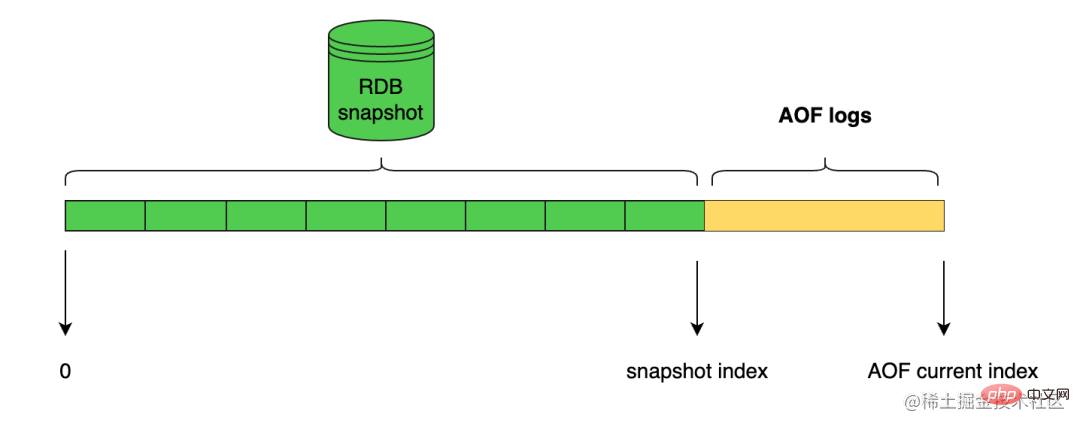
Redis telah memperkenalkan mod kegigihan hibrid RDB-AOF sejak versi 4.0 Mod ini dibina berdasarkan mod kegigihan AOF didayakan melalui aof-use-rdb-preamble yes.
Kemudian apabila pelayan Redis melakukan operasi tulis semula AOF, ia akan menjana data RDB yang sepadan berdasarkan status semasa pangkalan data seperti melaksanakan arahan BGSAVE dan menulis data ini ke dalam fail AOF yang baru dibuat. Bagi arahan Redis yang dilaksanakan selepas penulisan semula AOF bermula akan terus dilampirkan pada penghujung fail AOF baharu dalam bentuk teks protokol, iaitu selepas data RDB sedia ada.
Dengan kata lain, selepas fungsi kegigihan hibrid RDB-AOF dihidupkan, fail AOF yang dijana oleh pelayan akan terdiri daripada dua bahagian Data pada permulaan fail AOF ialah data format RDB , dan data RDB yang mengikuti Apa yang berikut ialah data dalam format AOF.
Apabila pelayan Redis yang menyokong mod kegigihan hibrid RDB-AOF bermula dan memuatkan fail AOF, ia akan menyemak sama ada permulaan fail AOF mengandungi kandungan berformat RDB.
- Jika disertakan, pelayan akan memuatkan data RDB permulaan dahulu, dan kemudian memuatkan data AOF berikutnya.
- Jika fail AOF hanya mengandungi data AOF, pelayan akan memuatkan data AOF secara langsung.
Struktur fail log adalah seperti berikut:
Ringkasan
Akhir sekali Untuk merumuskan kedua-duanya, yang manakah lebih baik?
- Adalah disyorkan untuk membolehkan kedua-duanya.
- Jika data tidak sensitif, anda boleh memilih untuk menggunakan RDB sahaja.
- Jika anda hanya melakukan cache memori tulen, anda tidak perlu menggunakannya sama sekali.
Pembelajaran yang disyorkan: Tutorial video Redis
Atas ialah kandungan terperinci Analisis ringkas tentang strategi kegigihan Redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!