
Rumah >pembangunan bahagian belakang >Tutorial Python >Satu artikel untuk menguasai kaedah pengekstrakan ciri teks dalam Python
Satu artikel untuk menguasai kaedah pengekstrakan ciri teks dalam Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-08-31 17:35:422716semak imbas

[Cadangan berkaitan: Tutorial video Python3 ]
1. Pengekstrakan ciri teks kamus DictVectorizer()
1.1 pengekodan satu panas
Buat kamus dan perhatikan perubahan dalam borang data berikut:
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
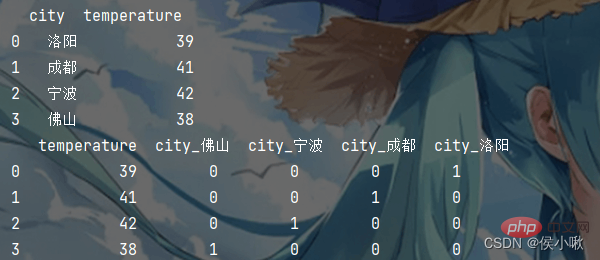
data = [{'city': '洛阳', 'temperature': 39},
{'city': '成都', 'temperature': 41},
{'city': '宁波', 'temperature': 42},
{'city': '佛山', 'temperature': 38}]
df1 = pd.DataFrame(data)
print(df1)
# one-hot编码 因为temperature是数值型的,所以会保留原始值,只有字符串类型的才会生成虚拟变量
df2 = pd.get_dummies(df1)
print(df2)Outputnya adalah seperti berikut:
1.2 Tukar data kamus kepada matriks jarang
Gunakan DictVectorizer() untuk mencipta model pengekstrakan ciri kamus
# 1.创建对象 默认sparse=True 返回的是sparse矩阵; sparse=False 返回的是ndarray矩阵 transfer = DictVectorizer() # 2.转化数据并训练 trans_data = transfer.fit_transform(data) print(transfer.get_feature_names_out()) print(trans_data)

Menggunakan matriks jarang tidak memaparkan 0 Data menjimatkan memori dan lebih ringkas, yang lebih baik daripada matriks ndarray.
2. Pengekstrakan ciri teks bahasa Inggeris
Pengestrakan ciri teks menggunakan model pengekstrakan ciri teks CountVectorizer Berikut ialah teks bahasa Inggeris (saya mempunyai impian). Kira kekerapan perkataan dan dapatkan matriks jarang Kodnya adalah seperti berikut:
CountVectorizer() tidak mempunyai parameter jarang dan menggunakan format matriks jarang secara lalai. Dan kata henti boleh ditentukan melalui kata_henti.
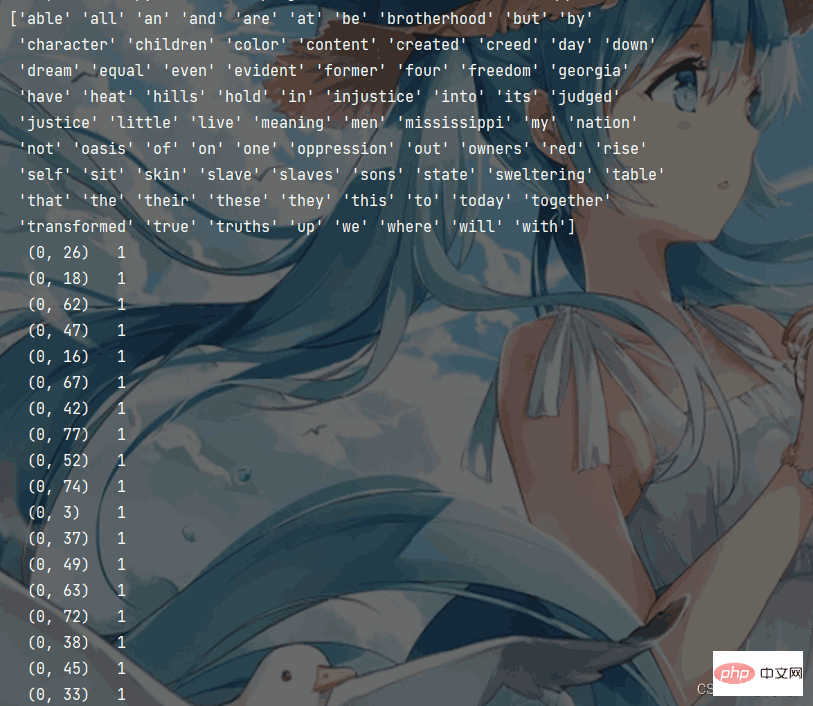
from sklearn.feature_extraction.text import CountVectorizer
data = ["I have a dream that one day this nation will rise up and live out the true meaning of its creed",
"We hold these truths to be self-evident, that all men are created equal",
"I have a dream that one day on the red hills of Georgia, "
"the sons of former slaves and the sons of former slave owners will be able to sit down together at the table of brotherhood",
"I have a dream that one day even the state of Mississippi",
" a state sweltering with the heat of injustice",
"sweltering with the heat of oppression",
"will be transformed into an oasis of freedom and justice",
"I have a dream that my four little children will one day live in a nation where they will not be judged by the color of their skin but by the content of their character",
"I have a dream today"]
# CountVectorizer文本特征提取模型
# 1.实例化 将"is"标记为停用词
c_transfer = CountVectorizer(stop_words=["is"])
# 2.调用fit_transform
c_trans_data = c_transfer.fit_transform(data)
# 打印特征名称
print(c_transfer.get_feature_names_out())
# 打印sparse矩阵
print(c_trans_data)Hasil keluaran adalah seperti yang ditunjukkan di bawah:
3 (data. txt), ambil plot Kuil Snow Mountain di Water Margin sebagai contoh:
Untuk mengekstrak ciri teks daripada bahasa Cina, anda perlu memasang dan menggunakan perpustakaan jieba. Gunakan pustaka ini untuk memproses teks ke dalam format di mana ruang menyambung perkataan, dan kemudian gunakan model pengekstrakan ciri teks CountVectorizer untuk mengekstraknya.大雪下的正紧,林冲和差拨两个在路上又没买酒吃处。早来到草料场外,看时,一周遭有些黄土墙,两扇大门。推开看里面时,七八间草房做着仓廒,四下里都是马草堆,中间两座草厅。到那厅里,只见那老军在里面向火。差拨说道:“管营差这个林冲来替你回天王堂看守,你可即便交割。”老军拿了钥匙,引着林冲,分付道:“仓廒内自有官司封记,这几堆草一堆堆都有数目。”老军都点见了堆数,又引林冲到草厅上。老军收拾行李,临了说道:“火盆、锅子、碗碟,都借与你。”林冲道:“天王堂内我也有在那里,你要便拿了去。”老军指壁上挂一个大葫芦,说道:“你若买酒吃时,只出草场,投东大路去三二里,便有市井。”老军自和差拨回营里来。 只说林冲就床上放了包裹被卧,就坐下生些焰火起来。屋边有一堆柴炭,拿几块来生在地炉里。仰面看那草屋时,四下里崩坏了,又被朔风吹撼,摇振得动。林冲道:“这屋如何过得一冬?待雪晴了,去城中唤个泥水匠来修理。”向了一回火,觉得身上寒冷,寻思:“却才老军所说五里路外有那市井,何不去沽些酒来吃?”便去包里取些碎银子,把花枪挑了酒葫芦,将火炭盖了,取毡笠子戴上,拿了钥匙,出来把草厅门拽上。出到大门首,把两扇草场门反拽上,锁了。带了钥匙,信步投东。雪地里踏着碎琼乱玉,迤逦背着北风而行。那雪正下得紧。 行不上半里多路,看见一所古庙。林冲顶礼道:“神明庇佑,改日来烧钱纸。”又行了一回,望见一簇人家。林冲住脚看时,见篱笆中挑着一个草帚儿在露天里。林冲径到店里,主人道:“客人那里来?”林冲道:“你认得这个葫芦么?”主人看了道:“这葫芦是草料场老军的。”林冲道:“如何便认的?”店主道:“既是草料场看守大哥,且请少坐。天气寒冷,且酌三杯权当接风。”店家切一盘熟牛肉,烫一壶热酒,请林冲吃。又自买了些牛肉,又吃了数杯。就又买了一葫芦酒,包了那两块牛肉,留下碎银子,把花枪挑了酒葫芦,怀内揣了牛肉,叫声相扰,便出篱笆门,依旧迎着朔风回来。看那雪,到晚越下的紧了。古时有个书生,做了一个词,单题那贫苦的恨雪: 广莫严风刮地,这雪儿下的正好。扯絮挦绵,裁几片大如栲栳。见林间竹屋茅茨,争些儿被他压倒。富室豪家,却言道压瘴犹嫌少。向的是兽炭红炉,穿的是绵衣絮袄。手捻梅花,唱道国家祥瑞,不念贫民些小。高卧有幽人,吟咏多诗草。
Contoh kod adalah seperti berikut:
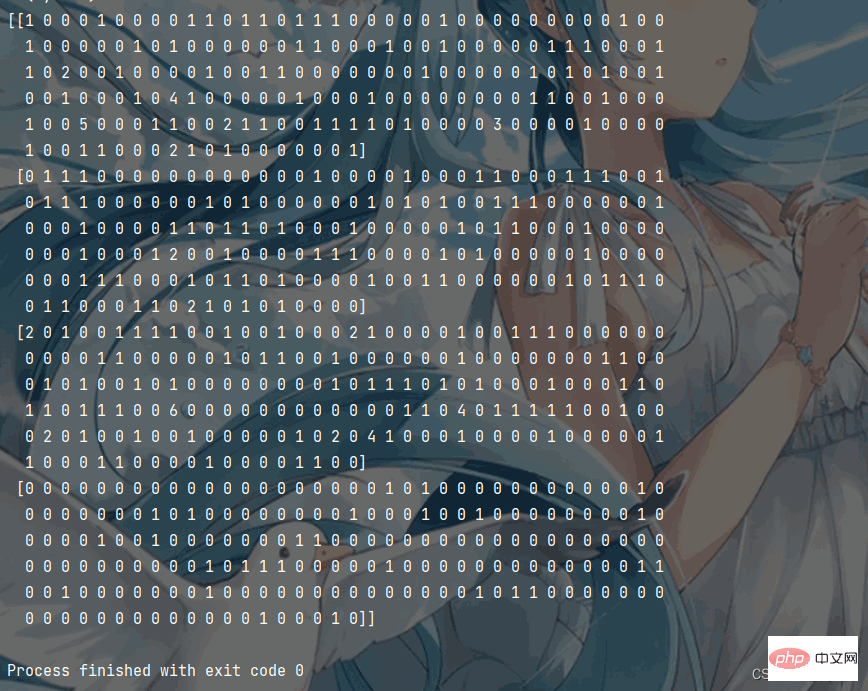
Kesan pelaksanaan program adalah seperti berikut:import jieba
from sklearn.feature_extraction.text import CountVectorizer
# 将文本转为以空格相连的字符串
def cut_word(sent):
return " ".join(list(jieba.cut(sent)))
# 将文本以行为单位,去除空格,并置于列表中。格式形如:["第一行","第二行",..."n"]
with open("./论文.txt", "r") as f:
data = [line.replace("\n", "") for line in f.readlines()]
lis = []
# 将每一行的词汇以空格连接
for temp in data:
lis.append(cut_word(temp))
transfer = CountVectorizer()
trans_data = transfer.fit_transform(lis)
print(transfer.get_feature_names())
# 输出sparse数组
print(trans_data)
# 转为ndarray数组(如果需要)
print(trans_data.toarray())
 Borang tatasusunan ndarray yang ditukar (jika perlu) adalah seperti berikut Seperti yang ditunjukkan dalam rajah:
Borang tatasusunan ndarray yang ditukar (jika perlu) adalah seperti berikut Seperti yang ditunjukkan dalam rajah:
 4 Pengekstrakan ciri teks TF-IDF TfidfVectorizer()
4 Pengekstrakan ciri teks TF-IDF TfidfVectorizer()
Pengekstrak teks TF-IDF. boleh digunakan untuk menilai watak sesuatu perkataan Kepentingan dokumen dalam set dokumen atau korpus.
Kod ditunjukkan seperti berikut:
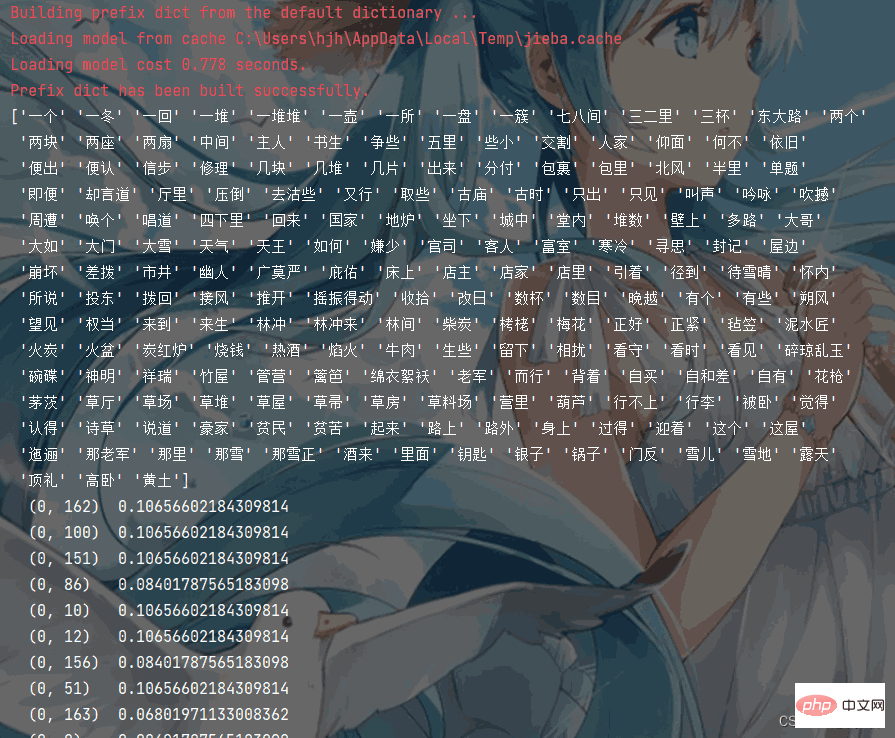
Hasil pelaksanaan program adalah seperti berikut:from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
def cut_word(sent):
return " ".join(list(jieba.cut(sent)))
with open("data.txt", "r") as f:
data = [line.replace("\n", "") for line in f.readlines()]
lis = []
for temp in data:
# print(cut_word(temp))
lis.append(cut_word(temp))
transfer = TfidfVectorizer()
print(transfer.get_feature_names())
print(trans_data)
 [Cadangan berkaitan:
[Cadangan berkaitan:
Atas ialah kandungan terperinci Satu artikel untuk menguasai kaedah pengekstrakan ciri teks dalam Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Membawa anda memahami Penyelia alat pengurusan proses Python
- Cara Python menggunakan contextvars untuk mengurus pembolehubah konteks
- Bangunkan Python dengan VSCode, 14 pemalam ini tidak boleh dilepaskan!
- Cara mengekstrak data csv dalam Python dan menapis data di bawah keadaan tertentu
- Penjelasan terperinci tentang penciptaan tatasusunan dalam tutorial Python NumPy