
Rumah >pembangunan bahagian belakang >Tutorial Python >Penjelasan yang sangat terperinci tentang perangkak Python
Penjelasan yang sangat terperinci tentang perangkak Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-07-14 16:58:504254semak imbas
Artikel ini membawa anda pengetahuan yang berkaitan tentang Python, yang terutamanya menyelesaikan isu yang berkaitan dengan perangkak web (juga dikenali sebagai labah-labah web, robot web) mensimulasikan pelayar yang menghantar permintaan Rangkaian, menerima respons permintaan, a. program yang menangkap maklumat Internet secara automatik mengikut peraturan tertentu. Mari kita lihat ia akan membantu semua orang.

[Pengesyoran berkaitan: Tutorial video Python3]
Perangkak
Perangkak web (juga dikenali sebagai halaman web Spider, Internet robot) ialah program yang mensimulasikan pelayar untuk menghantar permintaan rangkaian dan menerima respons permintaan, iaitu program yang secara automatik menangkap maklumat Internet mengikut peraturan tertentu.
Pada dasarnya, selagi pelayar (pelanggan) boleh melakukan apa sahaja, crawler boleh melakukannya.
Mengapa kami menggunakan perangkak
Era data besar Internet memberi kami kemudahan hidup dan penampilan data besar-besaran yang meletup dalam rangkaian.
Dahulu, kami menggunakan buku, surat khabar, televisyen, radio atau maklumat Jumlah maklumat adalah terhad dan perlu disaring pada tahap tertentu, tetapi kelemahannya ialah maklumat itu juga sempit. Penghantaran maklumat asimetri mengehadkan penglihatan kita dan menghalang kita daripada mempelajari lebih banyak maklumat dan pengetahuan.
Dalam era data besar Internet, kami tiba-tiba mempunyai akses percuma kepada maklumat Kami telah memperoleh sejumlah besar maklumat, tetapi kebanyakannya adalah maklumat sampah yang tidak sah.
Contohnya, Sina Weibo menjana ratusan juta kemas kini status sehari, manakala dalam enjin carian Baidu, anda boleh mencari hanya satu mesej - 100,000,000 mesej tentang penurunan berat badan.
Dalam jumlah serpihan maklumat yang begitu besar, bagaimanakah kita memperoleh maklumat yang berguna kepada kita?
Jawapannya ialah saringan!
Gunakan teknologi tertentu untuk mengumpul kandungan yang berkaitan, dan hanya selepas analisis dan pemilihan kami boleh mendapatkan maklumat yang kami perlukan.
Kerja pengumpulan, analisis dan penyepaduan maklumat ini boleh digunakan dalam pelbagai bidang, sama ada perkhidmatan hayat, perjalanan, pelaburan kewangan, permintaan pasaran produk pelbagai industri pembuatan, dll... Anda boleh menggunakan teknologi ini untuk memperoleh keputusan yang lebih tepat Gunakan maklumat yang berkesan.
Walaupun teknologi perangkak web mempunyai nama yang pelik, yang menjadikan reaksi pertama Neng adalah seperti makhluk yang lembut dan menggeliat, ia sebenarnya alat berkuasa yang boleh bergerak ke hadapan dalam dunia maya.
Persediaan crawler
Kami biasanya bercakap tentang crawler Python Sebenarnya, mungkin terdapat salah faham di sini. Terdapat banyak bahasa yang boleh digunakan untuk merangkak, seperti: PHP, JAVA, C#, C, Python Saya memilih Python sebagai crawler kerana Python agak mudah dan mempunyai fungsi yang agak lengkap.
Mula-mula kita perlu memuat turun python. Saya memuat turun versi rasmi terkini 3.8.3
Kedua, kita memerlukan persekitaran untuk menjalankan Python Saya menggunakan pychram

. Anda juga boleh memuat turunnya dari tapak web rasmi,
Kami juga memerlukan beberapa perpustakaan untuk menyokong operasi perangkak (sesetengah perpustakaan mungkin disertakan dengan Python)
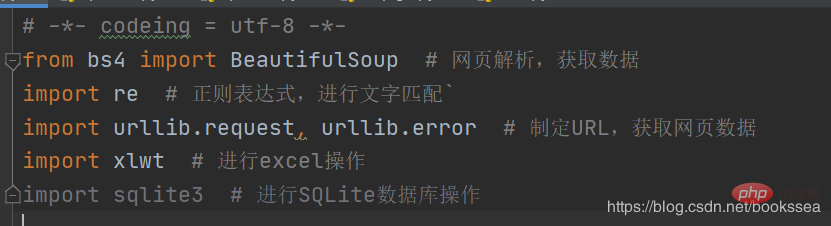
Cantik sekali Perpustakaan, saya telah menulis komen di belakang sejujurnya

(Semasa proses crawler berjalan, anda mungkin tidak hanya memerlukan beberapa perpustakaan di atas, ia bergantung pada perangkak anda yang khusus) Bagaimanapun, jika kami memerlukan perpustakaan, kami boleh memasangnya terus dalam tetapan)
Penjelasan projek perangkak
Apa yang saya lakukan ialah merangkak kod perangkak bagi filem dinilai Top 250 Douban
Kami mahu merangkak Ini ialah tapak web ini: https://movie.douban.com/top250
Saya telah selesai merangkak di sini . Saya menyimpan kandungan yang dirangkak ke dalam xls
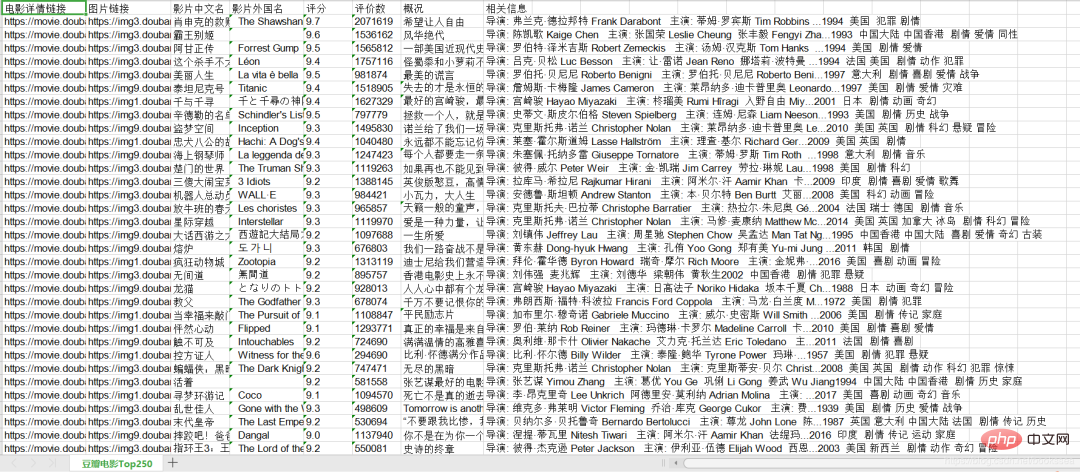
Kandungan yang kami rangkak ialah: Pautan butiran filem, pautan gambar, nama Cina filem, nama asing filem, rating, bilangan ulasan, gambaran keseluruhan, Maklumat berkaitan.
Analisis kod
Mula-mula siarkan kod, dan kemudian saya akan menganalisisnya langkah demi langkah berdasarkan kod
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配`
import urllib.request, urllib.error # 制定URL,获取网页数据
import xlwt # 进行excel操作
#import sqlite3 # 进行SQLite数据库操作
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则
findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S)
findTitle = re.compile(r'<span class="title">(.*)</span>')
findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>')
findJudge = re.compile(r'<span>(\d*)人评价</span>')
findInq = re.compile(r'<span class="inq">(.*)</span>')
findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
def main():
baseurl = "https://movie.douban.com/top250?start=" #要爬取的网页链接
# 1.爬取网页
datalist = getData(baseurl)
savepath = "豆瓣电影Top250.xls" #当前目录新建XLS,存储进去
# dbpath = "movie.db" #当前目录新建数据库,存储进去
# 3.保存数据
saveData(datalist,savepath) #2种存储方式可以只选择一种
# saveData2DB(datalist,dbpath)
# 爬取网页
def getData(baseurl):
datalist = [] #用来存储爬取的网页信息
for i in range(0, 10): # 调用获取页面信息的函数,10次
url = baseurl + str(i * 25)
html = askURL(url) # 保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all('p', class_="item"): # 查找符合要求的字符串
data = [] # 保存一部电影所有信息
item = str(item)
link = re.findall(findLink, item)[0] # 通过正则表达式查找
data.append(link)
imgSrc = re.findall(findImgSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if (len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "") #消除转义字符
data.append(otitle)
else:
data.append(titles[0])
data.append(' ')
rating = re.findall(findRating, item)[0]
data.append(rating)
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum)
inq = re.findall(findInq, item)
if len(inq) != 0:
inq = inq[0].replace("。", "")
data.append(inq)
else:
data.append(" ")
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', "", bd)
bd = re.sub('/', "", bd)
data.append(bd.strip())
datalist.append(data)
return datalist
# 得到指定一个URL的网页内容
def askURL(url):
head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 保存数据到表格
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
# def saveData2DB(datalist,dbpath):
# init_db(dbpath)
# conn = sqlite3.connect(dbpath)
# cur = conn.cursor()
# for data in datalist:
# for index in range(len(data)):
# if index == 4 or index == 5:
# continue
# data[index] = '"'+data[index]+'"'
# sql = '''
# insert into movie250(
# info_link,pic_link,cname,ename,score,rated,instroduction,info)
# values (%s)'''%",".join(data)
# # print(sql) #输出查询语句,用来测试
# cur.execute(sql)
# conn.commit()
# cur.close
# conn.close()
# def init_db(dbpath):
# sql = '''
# create table movie250(
# id integer primary key autoincrement,
# info_link text,
# pic_link text,
# cname varchar,
# ename varchar ,
# score numeric,
# rated numeric,
# instroduction text,
# info text
# )
#
#
# ''' #创建数据表
# conn = sqlite3.connect(dbpath)
# cursor = conn.cursor()
# cursor.execute(sql)
# conn.commit()
# conn.close()
# 保存数据到数据库
if __name__ == "__main__": # 当程序执行时
# 调用函数
main()
# init_db("movietest.db")
print("爬取完毕!")
Kemudian saya akan ikut kod, dari bawah ke bawah Biar saya terangkan dan analisis -- pengekodan = utf-8 -- Yang pertama adalah untuk menetapkan pengekodan kepada utf-8 dan menulisnya pada permulaan untuk mengelakkan kacau watak.
Kemudian import berikut adalah untuk mengimport beberapa perpustakaan dan membuat persediaan (saya tidak menggunakan perpustakaan sqlite3, jadi saya mengulasnya).
Beberapa perkataan berikut bermula dengan find ialah ungkapan biasa, yang digunakan untuk kami menapis maklumat.
(Pustaka semula digunakan untuk ungkapan biasa, dan ungkapan biasa tidak diperlukan.)
Proses umum dibahagikan kepada tiga langkah:
1 Rangka halaman web
2. Parse data satu persatu
3. Simpan halaman web
先分析流程1,爬取网页,baseurl 就是我们要爬虫的网页网址,往下走,调用了 getData(baseurl) ,
我们来看 getData方法
for i in range(0, 10): # 调用获取页面信息的函数,10次 url = baseurl + str(i * 25)
这段大家可能看不懂,其实是这样的:
因为电影评分Top250,每个页面只显示25个,所以我们需要访问页面10次,25*10=250。
baseurl = "https://movie.douban.com/top250?start="
我们只要在baseurl后面加上数字就会跳到相应页面,比如i=1时
https://movie.douban.com/top250?start=25
我放上超链接,大家可以点击看看会跳到哪个页面,毕竟实践出真知。
然后又调用了askURL来请求网页,这个方法是请求网页的主体方法,
怕大家翻页麻烦,我再把代码复制一遍,让大家有个直观感受
def askURL(url):
head = { # 模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
request = urllib.request.Request(url, headers=head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
这个askURL就是用来向网页发送请求用的,那么这里就有老铁问了,为什么这里要写个head呢?
这是因为我们要是不写的话,访问某些网站的时候会被认出来爬虫,显示错误,错误代码
418
这是一个梗大家可以百度下,
418 I’m a teapot
The HTTP 418 I’m a teapot client error response code indicates that
the server refuses to brew coffee because it is a teapot. This error
is a reference to Hyper Text Coffee Pot Control Protocol which was an
April Fools’ joke in 1998.
我是一个茶壶
所以我们需要 “装” ,装成我们就是一个浏览器,这样就不会被认出来,
伪装一个身份。
来,我们继续往下走,
html = response.read().decode("utf-8")
这段就是我们读取网页的内容,设置编码为utf-8,目的就是为了防止乱码。
访问成功后,来到了第二个流程:
2.逐一解析数据
解析数据这里我们用到了 BeautifulSoup(靓汤) 这个库,这个库是几乎是做爬虫必备的库,无论你是什么写法。
下面就开始查找符合我们要求的数据,用BeautifulSoup的方法以及 re 库的
正则表达式去匹配,
findLink = re.compile(r'<a href="(.*?)">') # 创建正则表达式对象,标售规则 影片详情链接的规则 findImgSrc = re.compile(r'<img.*src="(.*?)"', re.S) findTitle = re.compile(r'<span class="title">(.*)</span>') findRating = re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') findJudge = re.compile(r'<span>(\d*)人评价</span>') findInq = re.compile(r'<span class="inq">(.*)</span>') findBd = re.compile(r'<p class="">(.*?)</p>', re.S)
匹配到符合我们要求的数据,然后存进 dataList , 所以 dataList 里就存放着我们需要的数据了。
最后一个流程:
3.保存数据
# 3.保存数据 saveData(datalist,savepath) #2种存储方式可以只选择一种 # saveData2DB(datalist,dbpath)
保存数据可以选择保存到 xls 表, 需要(xlwt库支持)
也可以选择保存数据到 sqlite数据库, 需要(sqlite3库支持)
这里我选择保存到 xls 表 ,这也是为什么我注释了一大堆代码,注释的部分就是保存到 sqlite 数据库的代码,二者选一就行
保存到 xls 的主体方法是 saveData (下面的saveData2DB方法是保存到sqlite数据库):
def saveData(datalist,savepath):
print("save.......")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i]) #列名
for i in range(0,250):
# print("第%d条" %(i+1)) #输出语句,用来测试
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
创建工作表,创列(会在当前目录下创建),
sheet = book.add_sheet('豆瓣电影Top250', cell_overwrite_ok=True) #创建工作表
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
然后把 dataList里的数据一条条存进去就行。
最后运作成功后,会在左侧生成这么一个文件

打开之后看看是不是我们想要的结果
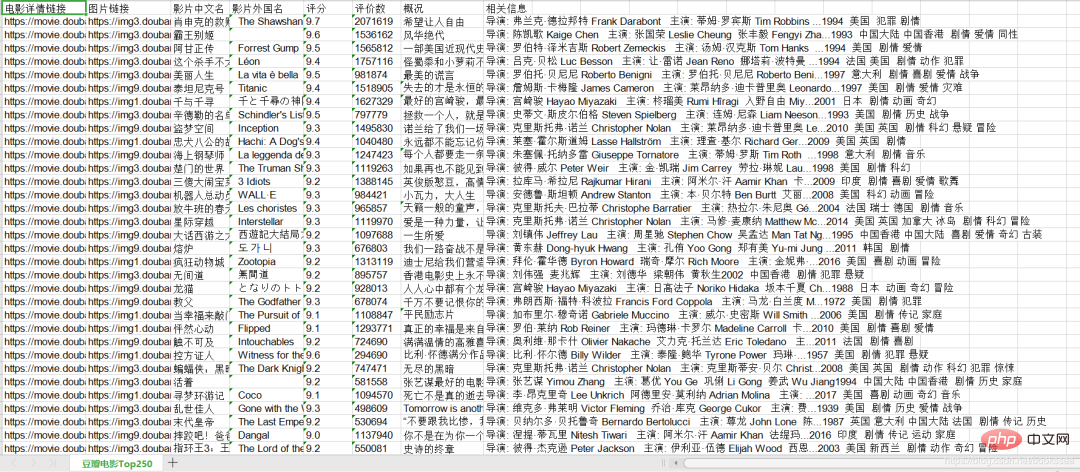
成了,成了!如果我们需要以数据库方式存储,可以先生成 xls 文件,再把 xls 文件导入数据库中,就可以啦!
【相关推荐:Python3视频教程 】
Atas ialah kandungan terperinci Penjelasan yang sangat terperinci tentang perangkak Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!