
Rumah >pangkalan data >tutorial mysql >Memilih dan meringkaskan 15 isu pengoptimuman Mysql
Memilih dan meringkaskan 15 isu pengoptimuman Mysql

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-06-13 18:07:012239semak imbas
Artikel ini membawa anda pengetahuan yang berkaitan tentang mysql terutamanya memperkenalkan isu yang berkaitan dengan pengoptimuman SQL, termasuk cara menyelesaikan masalah penyataan SQL semasa proses pembangunan dan cara menyelesaikan masalah persekitaran pengeluaran Masalah SQL dan sebagainya saya harap ia akan membantu semua orang.

Pembelajaran yang disyorkan: tutorial video mysql
Bagaimana untuk menyelesaikan masalah SQL semasa proses pembangunan?
Idea Penyelesaian Masalah
Bagi kebanyakan pengaturcara, penyelesaian masalah SQL semasa proses pembangunan pada dasarnya kosong. Walau bagaimanapun, dengan involusi industri, semakin banyak perhatian dan profesionalisme diberikan kepada proses pembangunan Salah satu daripadanya adalah untuk menyelesaikan masalah SQL sebanyak mungkin semasa proses pembangunan untuk mengelakkan masalah SQL semasa pengeluaran. Jadi bagaimana untuk menjalankan penyelesaian masalah SQL dengan mudah untuk program semasa proses pembangunan?
Ideanya ialah menggunakan log perlahan Mysql untuk mencapainya:
-
Pertama sekali, semasa proses pembangunan, anda juga perlu mendayakan pertanyaan perlahan pangkalan data Mysql
SET GLOBAL slow_query_log='on';
-
Kedua tetapkan masa minimum untuk SQL perlahan
Nota: Unit masa di sini ialah s saat tetapi ada adalah 6 tempat perpuluhan supaya ia boleh menyatakan intensiti masa yang halus, secara amnya masa pelaksanaan SQL bagi satu jadual adalah dalam 20ms Sebaliknya, pemahamannya ialah semasa proses pembangunan, jika pernyataan SQL yang anda laksanakan melebihi 20ms, anda perlukan. untuk memberi perhatian kepadanya.
SET GLOBAL long_query_time=0.02;
-
Untuk kemudahan, slow SQL boleh direkodkan dalam jadual dan bukannya fail
SET GLOBAL log_output='TABLE';
Akhir sekali, SQL perlahan yang direkodkan boleh disoal melalui jadual mysql.slow_log
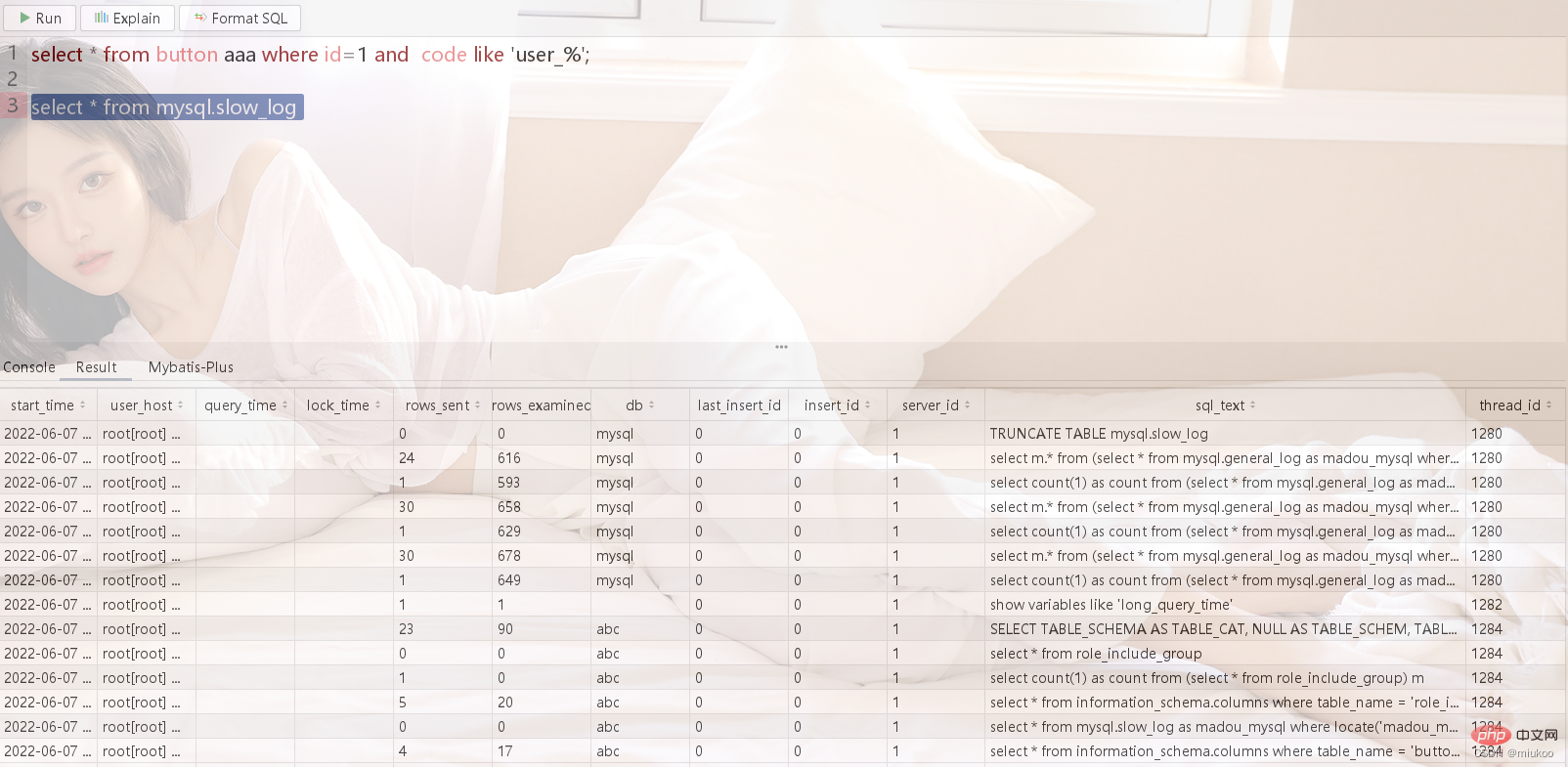
Gunakan alatan
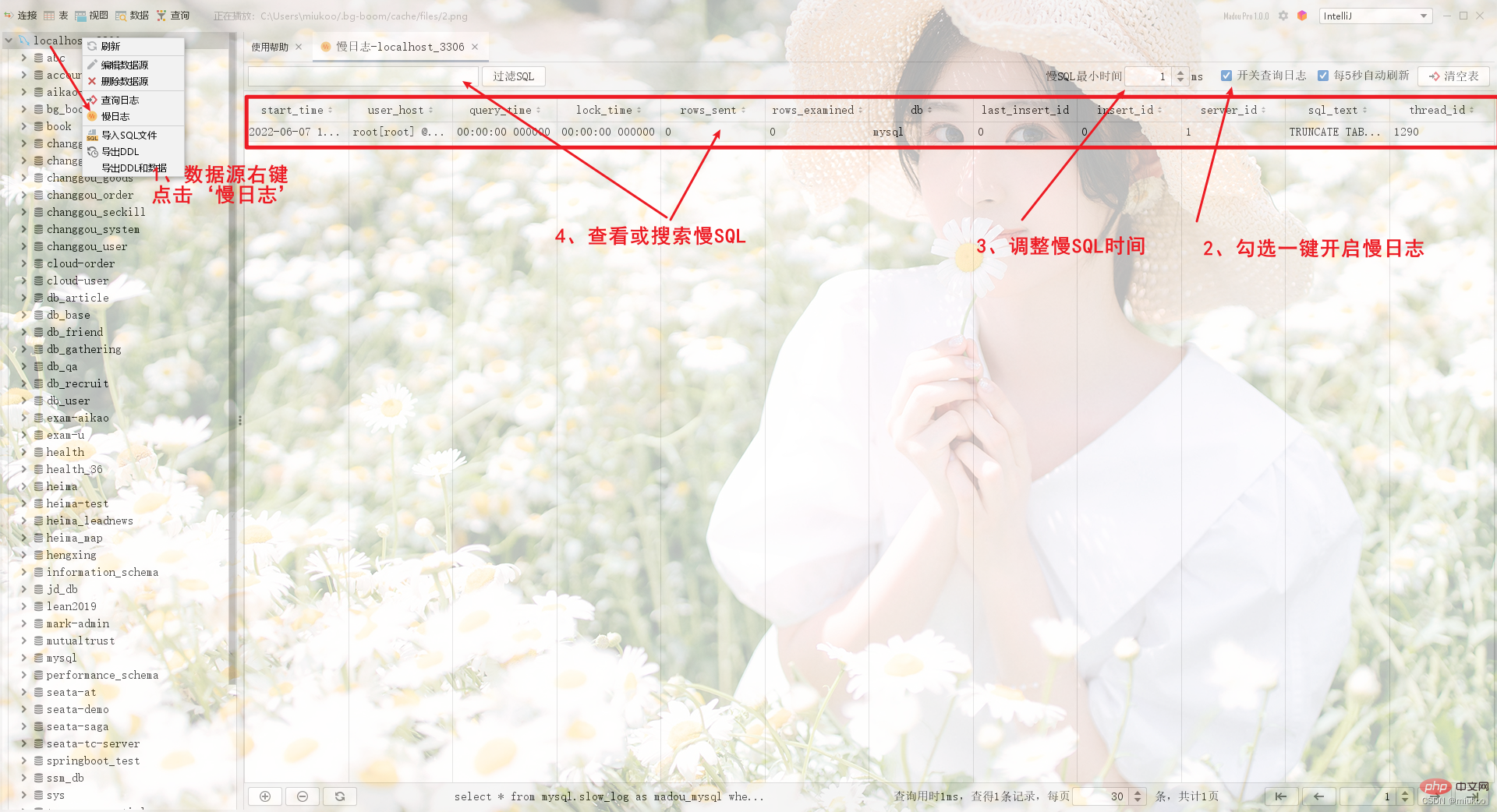
In Brother Yong Perisian yang dibangunkan untuk anda juga menyediakan antara muka grafik untuk membantu anda melaksanakan fungsi di atas dengan cepat dengan satu klik.
Bagaimana untuk menyelesaikan masalah SQL dalam persekitaran pengeluaran?
Idea Menyelesaikan Masalah
Menyelesaikan masalah yang dijanakan masalah SQL sedikit lebih rumit, tetapi idea keseluruhannya adalah untuk menyelesaikan masalah melalui SQL yang perlahan Idea khusus adalah seperti berikut:
-
Mula-mula dayakan pertanyaan perlahan pangkalan data Mysql
SET GLOBAL slow_query_log='on';
-
Kedua tetapkan masa minimum untuk SQL perlahan
SET GLOBAL long_query_time=0.02;
-
Secara amnya apabila menjana Letakkan SQL perlahan ke dalam fail
SET GLOBAL log_output='FILE';
Muat turun fail log SQL perlahan ke tempat setempat
-
Akhirnya tutup pertanyaan lambat bagi pangkalan data Mysql
Adalah penting untuk ambil perhatian: Adalah lebih baik untuk mendayakan SQL perlahan untuk pengeluaran hanya apabila digunakan dan menutupnya selepas digunakan untuk mengelakkan pembalakan daripada menjejaskan prestasi perniagaan
SET GLOBAL slow_query_log='off';
Bagaimana untuk menala SQL?
Penalaan SQL mengintegrasikan pelbagai aspek pengetahuan Secara umumnya, adalah perkara biasa untuk mengoptimumkan daripada dua aspek: struktur jadual dan indeks jadual.
Pengoptimuman struktur jadual
1 Penggunaan kelas dan panjang medan yang munasabah
Contoh untuk difahami: hanya gunakan tinyint(1) untuk menyimpan medan jantina. menduduki 1 bait, dan storan int(1) menduduki 4 bait Jika terdapat 1 juta rekod, maka fail jadual yang disimpan dalam int adalah kira-kira 2.8M lebih besar daripada fail jadual yang disimpan dalam tinyint fail meja adalah besar dan kelajuan membaca lebih perlahan daripada membaca tinyint. Ini sebenarnya intipati mengapa panjang jenis medan harus digunakan secara rasional: untuk mengurangkan saiz fail yang disimpan untuk memberikan prestasi baca .
Sudah tentu, sesetengah rakan mungkin mengatakan bahawa 2.8M tidak menjejaskan keadaan keseluruhan, jadi ia boleh diabaikan. Saudara Yong ingin menambah sesuatu pada idea ini: Katakan jadual mempunyai 10 medan dan sistem anda mempunyai sejumlah 30 jadual. Kemudian mari kita lihat saiz fail tambahan. (2.8Mx10x30=840M, ia akan mengambil masa beberapa saat untuk memuat turun 840M menggunakan Thunder Super. Kali ini dianggap sangat perlahan dalam komputer...)
2 Penggunaan reka bentuk berlebihan yang munasabah
2.1. Latar belakang reka bentuk berlebihan - jadual sementara
Terdapat jadual sementara khas dan ringan di dalam Mysql, yang dicipta dan dipadam secara automatik oleh Mysql. Jadual sementara digunakan terutamanya semasa pelaksanaan SQL untuk menyimpan hasil perantaraan operasi tertentu Proses ini diselesaikan secara automatik oleh MySQL, dan pengguna tidak boleh campur tangan secara manual, dan jadual dalaman ini tidak dapat dilihat oleh pengguna.
Jadual sementara dalaman sangat penting dalam proses pengoptimuman penyata SQL Banyak operasi dalam MySQL bergantung pada jadual sementara dalaman untuk operasi pengoptimuman. Walau bagaimanapun, menggunakan jadual sementara dalaman memerlukan kos untuk mencipta jadual dan mengakses data perantaraan, jadi hendaklah cuba mengelak daripada menggunakan jadual sementara semasa menulis pernyataan SQL.
Jadi dalam senario tersebut, adakah Mysql menggunakan jadual sementara secara dalaman?
Dalam pertanyaan perkaitan berbilang jadual (SERTAI), lajur yang digunakan mengikut susunan oleh atau kumpulan mengikut bukan lajur jadual pertama
Apabila lajur kumpulan oleh bukan lajur indeks
berbeza dan kumpulan mengikut digunakan bersama
urutan mengikut pernyataan menggunakan kata kunci yang berbeza
kumpulan oleh The lajur ialah lajur indeks, tetapi apabila jumlah data terlalu besar
2.2 Bagaimana untuk menyemak sama ada jadual sementara dalaman digunakan?
Gunakan kata kunci Terangkan atau butang fungsi alat untuk melihat proses pelaksanaan SQL Jika kata kunci Menggunakan sementara muncul dalam lajur Tambahan dalam hasil, ini bermakna pernyataan SQL anda menggunakan jadual sementara apabila melaksanakan.
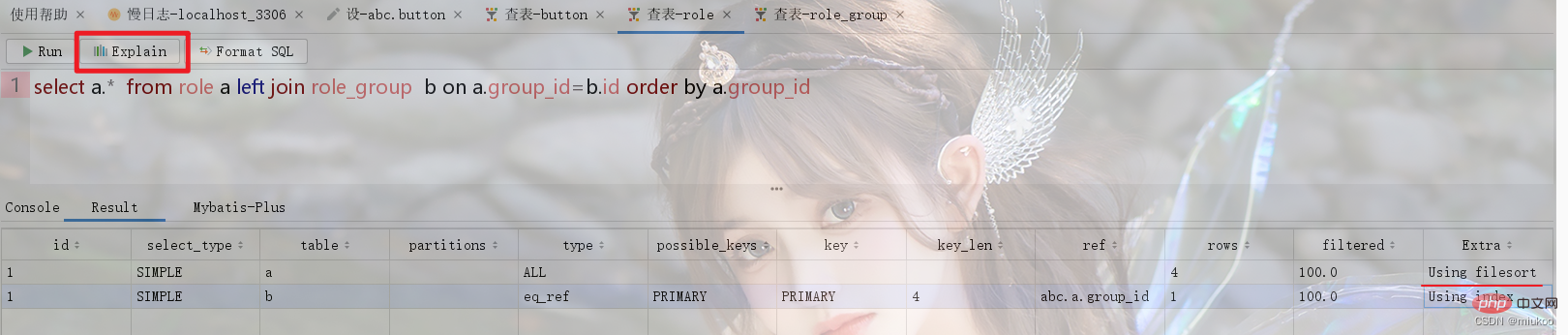
Seperti yang ditunjukkan di bawah, jadual peranan dan kumpulan peranan Role_Group mempunyai hubungan many-to-1 Apabila melakukan pertanyaan berkaitan, jadual sementara akan digunakan untuk mengisih menggunakan id role_group (lihat Rajah 1 di bawah. ). Jika pengisihan menggunakan Id peranan tidak akan menggunakan jadual sementara (lihat Rajah 2).
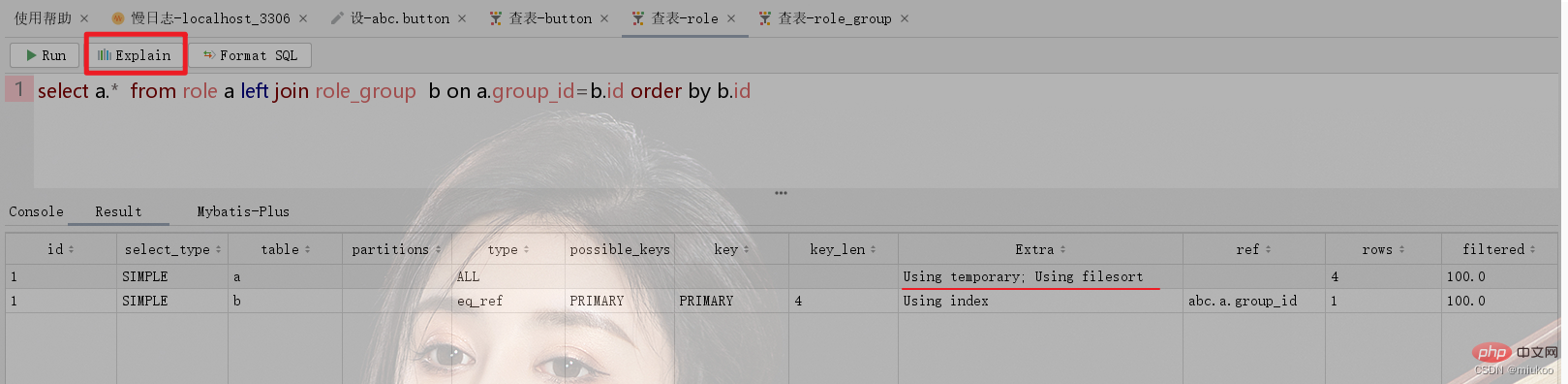
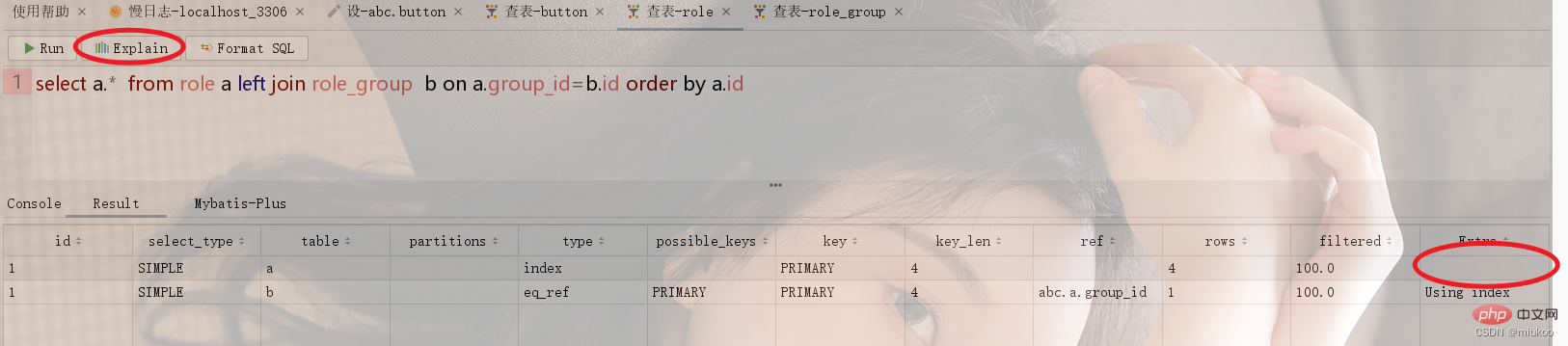
2.3 Bagaimana untuk menyelesaikan masalah tidak menggunakan jadual sementara dalaman?
Terdapat dua penyelesaian untuk masalah ini Satu ialah melaraskan pernyataan SQL untuk mengelak daripada menggunakan jadual sementara, dan satu lagi adalah untuk menyimpan secara berlebihan dalam jadual. Sebagai contoh, dalam contoh dalam Rajah 1 dalam 2.2, jika anda mesti mengisih mengikut id role_group, anda boleh mengisih mengikut group_id dalam jadual peranan dan lajur ini ialah nilai lajur id dalam role_group meja yang disimpan secara berlebihan.
3. Penggunaan sub-pangkalan data dan sub-jadual yang betul
Sub-pangkalan data dan sub-jadual bukan sahaja digunakan untuk pengoptimuman dalam kuantiti yang banyak, tetapi sub-jadual menegak juga boleh digunakan Gunakannya di bawah penalaan SQL. (Saya tidak akan menerangkan sub-jadual menegak dan mendatar di sini. Jika anda berminat, sila hantar mesej peribadi kepada saya)
Contohnya: reka bentuk umum jadual artikel tidak akan termasuk medan besar bagi kandungan artikel.

Bidang besar kandungan artikel diletakkan dalam jadual berasingan

Mengapa jadual artikel gunakan di atas Bagaimana pula dengan mereka bentuk tanpa menggabungkan medan ke dalam satu jadual?
Mari kita hitung masalah matematik dahulu, andaikan satu artikel bersaiz 1M Kandungan artikel ialah 824KB dan ruang yang tinggal ialah 200KB jumlahnya, kemudian:
Pilihan 1, jika meja digunakan untuk penyimpanan, saiz meja ialah 100W*1M=100WM
Pilihan 2, jika storan meja menegak ialah digunakan, asas Saiz jadual ialah 200KBx100W, dan jadual kandungan ialah 824KBx100W
Kami mempunyai dua halaman di hujung hadapan: senarai artikel dan butiran artikel Untuk menanyakan secara terus kandungan yang berkaitan pangkalan data, kemudian:
Pilihan 1, senarai artikel dan butiran artikel akan disoal daripada data 100WM
Pilihan 2, senarai artikel akan disoal dari 200KBx100W, dan butiran artikel akan disoal dari 824KBx100W Pertanyaan dari 200KBx100W (pada masa ini anda juga mungkin perlu bertanya dari 200KBx100W)
Saya percaya semua orang harus mengatakan ini jawapan yang jelas dalam fikiran mereka! Pemisahan jadual menegak membolehkan jumlah data yang berbeza disoal dalam senario perniagaan yang berbeza Selalunya jumlah data ini lebih kecil daripada jumlah jumlah data jadual, yang lebih fleksibel dan cekap daripada membuat pertanyaan daripada jumlah tetap besar atau kecil. .
Pengoptimuman indeks jadual
1 Tambah lajur indeks dengan munasabah
Tahap pemahaman kebanyakan orang tentang indeks ialah "indeks boleh mempercepatkan pertanyaan". Kelajuan", walau bagaimanapun, Abang Yong ingin menambah separuh kedua ayat ini "Indeks boleh mempercepatkan pertanyaan, tetapi juga memperlahankan kelajuan pemasukan atau pengubahsuaian data" .
Jika jadual mempunyai 5 indeks, maka anda boleh menganggap indeks sebagai jadual, maka akan ada 1 jadual dan 6 jadual indeks = bersamaan dengan 6 jadual, maka 6 jadual ini Bilakah ia akan beroperasi? Mari kita mengiranya:
operasi masukkan, selepas memasukkan data, anda perlu memasukkan data indeks ke dalam 5 jadual indeks
operasi padam, data Selepas pemadaman, anda perlu memadamkan indeks dalam 5 jadual indeks
-
operasi kemas kini
Jika data lajur indeks diubah, pertama Untuk mengubah suai data, anda juga perlu mengubah suai indeks dalam jadual indeks
Jika data dalam lajur indeks tidak diubah suai, hanya ubah suai jadual data
-
pilih operasi
Jika indeks pertanyaan dipukul, tanya indeks dahulu, dan kemudian semak jadual data
Jika indeks pertanyaan tidak dipukul, Kemudian semak terus jadual data
Melalui pengiraan di atas, anda secara ajaib akan mendapati bahawa semakin banyak indeks , lebih baik untuk memasukkan dan memadam , operasi kemas kini mempunyai kesan, dan ia mempunyai kesan negatif . Oleh itu, mungkin menilai kesan indeks menjadi kurang daripada manfaat pertanyaan, dan kemudian menambahnya dan bukannya menambah secara membabi buta.
2、合理的调配复合索引列个数和顺序
复合索引指的是包括有多个列的索引,它能有效的减少表的索引个数,平衡了多个字段需要多个索引直接的性能平衡,但是再使用复合索引的时候,需要注意索引列个数和顺序的问题。
先说列个数的问题,指的是一个复合索引中包括的列字段太多影响性能的问题,主要是对update操作的性能影响,如下红字:
如果修改了索引列的数据,则先修改数据,还需要修改索引表中的索引,如果索引列个数越多则修改该索引的概率越大
如果没有修改索引列的数据,则只修改数据表
再说复合索引中列顺序的问题,是指索引的最左匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配,这个比较容易理解,就不多做阐述。
那些情况索引会失效?
索引无法存储null值,当使用is null或is not nulli时会全表扫描
like查询以"%"开头
对于复合索引,查询条件中没有给出索引中第一列的值时
mysql内部评估全表扫描比索引快时
or、!=、<>、in、not in等查询也可能引起索引失效
表设计有那些规范?
建表规约
表达是与否概念的字段,必须使用 is_xxx 的方式命名,数据类型为
unsigned tinyint。 说明:任何字段如果为非负数,则必须是 unsigned。-
字段允许适当冗余,以提高查询性能,但必须考虑数据一致。e.g. 商品类目名称使用频率高,字段长度短,名称基本一成不变,可在相关联的表中冗余存储类目名称,
避免关联查询
。冗余字段遵循:
不是频繁修改的字段;
不是 varchar 超长字段,更不能是 text 字段。
索引规约
在 varchar 字段上建立索引时,必须指定索引长度,没必要对全字段建立索引,根据实际文本区分度决定索引长度即可。
页面搜索严禁左模糊或者全模糊,如果需要请通过搜索引擎来解决。 说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
-
如果有 order by 的场景,请注意利用索引的有序性。order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现 file_sort 的情况,影响查询性能。
正例:where a=? and b=? order by c; 索引: a_b_c。
反例:索引中有范围查找,那么索引有序性无法利用,如 WHERE a>10 ORDER BY b; 索引 a_b 无法排序。
利用延迟关联或者子查询优化超多分页场景。 说明:MySQL 并不是跳过 offset 行,而是取 offset+N 行,然后返回放弃前 offset 的行,返回 N 行。当 offset 特别大的时候,效率会非常的低下,要么控制返回的总页数,要么对超过阈值的页数进行 SQL 改写。
建组合索引的时候,区分度最高的在最左边。
SQL 性能优化的目标,至少要达到 range 级别,要求是 ref 级别,最好是 consts。
SQL 语句
不要使用 count(列名) 或 count(常量) 来替代 count(),count() 是 SQL92 定义的标准统计行数的语句,跟数据库无关,跟 NULL 和非 NULL 无关。 说明:count(*) 会统计值为 NULL 的行,而 count(列名) 不会统计此列为 NULL 值的行。
count(distinct column)计算该列除 NULL 外的不重复行数。注意,count(distinct column1,column2)如果其中一列全为 NULL,那么即使另一列用不同的值,也返回为 0。当某一列的值全为 NULL 时,
count(column)的返回结果为 0,但sum(column)的返回结果为 NULL,因此使用 sum() 时需注意 NPE 问题。 可以使用如下方式来避免 sum 的 NPE 问题。
SELECT IF(ISNULL(SUM(g), 0, SUM(g))) FROM table;
使用
ISNULL()来判断是否为 NULL 值。 说明:NULL 与任何值的直接比较都为 NULL。Kunci asing dan lata tidak dibenarkan Semua konsep kunci asing mesti diselesaikan pada lapisan aplikasi. Nota: Ambil perhubungan antara pelajar dan gred sebagai contoh Id_pelajar bagi jadual pelajar ialah kunci utama, dan id_pelajar bagi jadual gred ialah kunci asing. Jika student_id dalam jadual pelajar dikemas kini dan student_id dalam jadual gred dikemas kini pada masa yang sama, ia adalah kemas kini lata. Kekunci asing dan kemas kini lata sesuai untuk konkurensi rendah pada mesin tunggal, tetapi tidak sesuai untuk kluster teragih dan berkonkurensi tinggi menyekat dengan kuat dan mempunyai risiko ribut kemas kini pangkalan data mempengaruhi kelajuan pemasukan pangkalan data; .
Penggunaan prosedur tersimpan adalah dilarang. Prosedur tersimpan sukar untuk dinyahpepijat dan dilanjutkan, dan ia tidak mudah alih.
inElakkan pembedahan jika boleh. Jika ia tidak dapat dielakkan, anda perlu menilai dengan teliti bilangan elemen koleksi selepas masuk dan mengawalnya dalam 1000.
Pemetaan ORM
Atribut Boolean kelas POJO tidak boleh ditambah dengan is, manakala medan pangkalan data mesti ditambah dengan is_, yang memerlukan medan dan atribut dalam pemetaan resultMap.
sql.xmlParameter konfigurasi menggunakan:#{}, #param#, jangan gunakan ${}, kaedah ini terdedah kepada suntikan SQL.@TransactionalJangan menyalahgunakan urusan. Transaksi menjejaskan QPS pangkalan data. Di samping itu, apabila urus niaga digunakan, pelbagai aspek penyelesaian gulung balik perlu dipertimbangkan, termasuk rollback cache, rollback enjin carian, pampasan mesej, pembetulan statistik, dsb.
Pembelajaran yang disyorkan: tutorial video mysql
Atas ialah kandungan terperinci Memilih dan meringkaskan 15 isu pengoptimuman Mysql. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Bagaimana untuk mengubah suai pengekodan mysql dalam ubuntu
- Penjelasan terperinci tentang asas MySQL: model data dan bahasa SQL
- Mari analisa prinsip aliran kerja transaksi MySQL bersama-sama
- Contoh grafik menganalisis pengurusan pengguna MySQL
- Ringkaskan dan susun spesifikasi reka bentuk pangkalan data MySQL