
Rumah >pangkalan data >Redis >Analisis terperinci tentang atomicity arahan dalam Redis
Analisis terperinci tentang atomicity arahan dalam Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-06-01 11:58:044037semak imbas
Artikel ini membawa anda pengetahuan yang berkaitan tentang Redis, yang terutamanya memperkenalkan isu yang berkaitan dengan atomicity perintah dalam operasi atom, termasuk penyelesaian pengendalian konkurensi, model pengaturcaraan dan multi-IO Mari kita lihat kandungan berkaitan benang dan arahan tunggal saya harap ia akan membantu semua orang.

Pembelajaran yang disyorkan: Tutorial video Redis
Cara Redis mengatasi akses serentak
Penyelesaian pengendalian concurrency dalam Redis
Dalam perniagaan, kadangkala kami menggunakan Redis untuk mengendalikan beberapa senario perniagaan serentak tinggi, seperti perniagaan jualan kilat dan operasi inventori. . .
Mari kita analisis dahulu masalah apa yang akan berlaku dalam senario konkurensi
Masalah konkurensi terutamanya berlaku dalam pengubahsuaian data Untuk pelanggan mengubah suai data, ia biasanya dibahagikan kepada dua langkah berikut:
1 Pelanggan membaca data secara setempat dan mengubah suainya secara setempat;
2.
Kami memanggil proses ini 读取-修改-写回 operasi (Read-Modify-Write, dirujuk sebagai operasi RMW). Jika pelanggan melakukan operasi RMW secara serentak, ia perlu memastikan bahawa 读取-修改-写回 ialah operasi atom Apabila melakukan operasi arahan, pelanggan lain tidak boleh beroperasi pada data semasa.
Berangan salah:
Kira bilangan lawatan ke halaman Setiap kali halaman dimuat semula, bilangan lawatan ialah 1. Di sini, Redis digunakan untuk merekodkan bilangan lawatan.
Jika setiap operasi 读取-修改-写回 bukan operasi atom, maka mungkin terdapat masalah seperti yang ditunjukkan dalam rajah di bawah Client 2 juga memperoleh nilai Redis di tengah-tengah operasi klien 1, dan juga melakukan 1 pada nilai , operasi, yang membawa kepada ralat dalam data akhir.
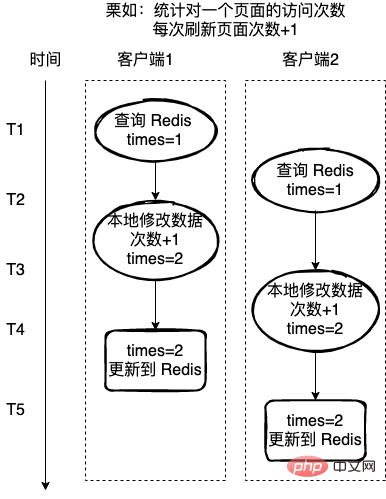
Untuk situasi di atas, biasanya terdapat dua cara untuk menyelesaikannya:
1 Gunakan Redis untuk melaksanakan kunci teragih dan gunakan kunci untuk Lindungi bahawa hanya satu utas yang mengendalikan sumber kritikal pada satu masa;
Li Ru, untuk contoh ralat di atas, jika- ialah arahan atom, maka tiada benang lain akan membaca data operasi pada masa yang sama semasa operasi arahan ini, supaya Ia dapat mengelakkan masalah yang disebabkan oleh buah berangan di atas.
读取-修改-写回Berikut ialah analisis terperinci pengendalian isu akses serentak daripada dua aspek atomicity dan locking
Dalam perintah untuk Untuk melaksanakan pelaksanaan kod bahagian kritikal yang saling eksklusif yang diperlukan untuk kawalan serentak, jika anda menggunakan atomicity perintah dalam Redis, anda boleh mempunyai dua kaedah pemprosesan berikut:
1 dalam Redis;
2 Tulis berbilang operasi ke dalam skrip Lua dan laksanakan satu skrip Lua secara atom.
Apabila membincangkan atomicity Redis, mari kita bincangkan model pengaturcaraan yang digunakan dalam Redis
Model pengaturcaraan RedisDigunakan dalam Redis Coming to model Reaktor, Reaktor ialah model I/O yang tidak menyekat Mari kita lihat model I/O dalam Unix.
Model I/O dalam UnixI/O pada sistem pengendalian ialah interaksi data antara ruang pengguna dan ruang kernel, jadi operasi I/O biasanya termasuk berikut Dua langkah:
1 Tunggu data rangkaian tiba di kad rangkaian (baca sedia)/tunggu kad rangkaian boleh ditulis (tulis sedia) –>
2 , Salin data daripada penimbal kernel –> Ruang pengguna (baca)/Salin data dari ruang pengguna –> dalam Unix
Menghalang I/O; /O O; I/O tak segerak;- Untuk menentukan sama ada model I/O adalah segerak atau tak segerak, terutamanya bergantung pada langkah kedua: data Adakah penyalinan antara ruang pengguna dan kernel menyekat proses semasa Jika ya, ia adalah I/O segerak, jika tidak, ia adalah I/O tak segerak.
- Di sini terutamanya dibahagikan kepada tiga model I/O berikut:
- Menyekat I/O;
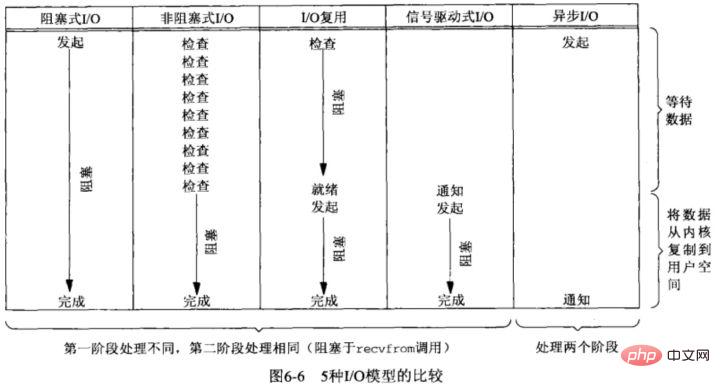 Apabila program pengguna melaksanakan bacaan, benang akan Sekat, tunggu sehingga data kernel sedia, dan salin data dari penimbal kernel ke penimbal aplikasi Apabila proses penyalinan selesai, baca akan kembali.
Apabila program pengguna melaksanakan bacaan, benang akan Sekat, tunggu sehingga data kernel sedia, dan salin data dari penimbal kernel ke penimbal aplikasi Apabila proses penyalinan selesai, baca akan kembali.
- I/O segerak yang tidak menyekat;
- I/O tak segerak yang tidak menyekat;
- Kurangkan gandingan;
- Pelaksanaan tak segerak;
- Skalabiliti;
- Model reaktor dibahagikan kepada 3 kategori:
- Mod Reaktor benang tunggal;
- Mod Reaktor berbilang benang; mod, menambahkan kumpulan benang pekerja dan memindahkan operasi bukan daripada benang Reaktor ke kumpulan benang pekerja (Kolam Benang) untuk dilaksanakan.
- Untuk mesin dengan berbilang CPU, untuk menggunakan sepenuhnya sumber sistem, belah Reaktor kepada Dua bahagian: mainReactor dan subReactor.
- Apabila memulakan permintaan baca dan tulis tak segerak, anda perlu menghantar alamat penimbal data (digunakan untuk menyimpan data hasil) dan maklumat lain, supaya kernel sistem boleh membantu kami secara automatik melengkapkan pembacaan dan penulisan data , keseluruhan kerja membaca dan menulis di sini dilakukan oleh sistem pengendalian Ia tidak memerlukan proses aplikasi untuk memulakan secara aktif untuk membaca dan menulis data seperti Reaktor kerja membaca dan menulis, ia akan memberitahu proses permohonan untuk memproses data secara langsung.
- Pemulaan acara;
- Tangkapan acara;
- Gelung utama pengedaran dan pemprosesan.
Permintaan baca tanpa menyekat kembali serta-merta apabila data belum sedia, dan boleh terus dilaksanakan pada masa ini tidak meneruskan kitaran Pertanyaan kernel sehingga data sedia, kernel menyalin data ke penimbal aplikasi, dan panggilan baca boleh memperoleh hasilnya.
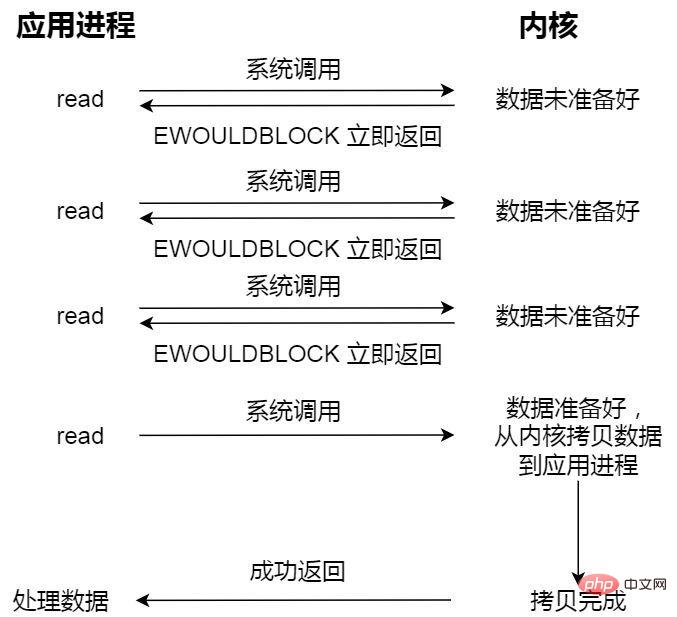
Panggilan baca terakhir di sini, proses mendapatkan data, adalah proses segerak dan memerlukan menunggu. Penyegerakan di sini merujuk kepada proses menyalin data keadaan kernel ke kawasan cache program pengguna.
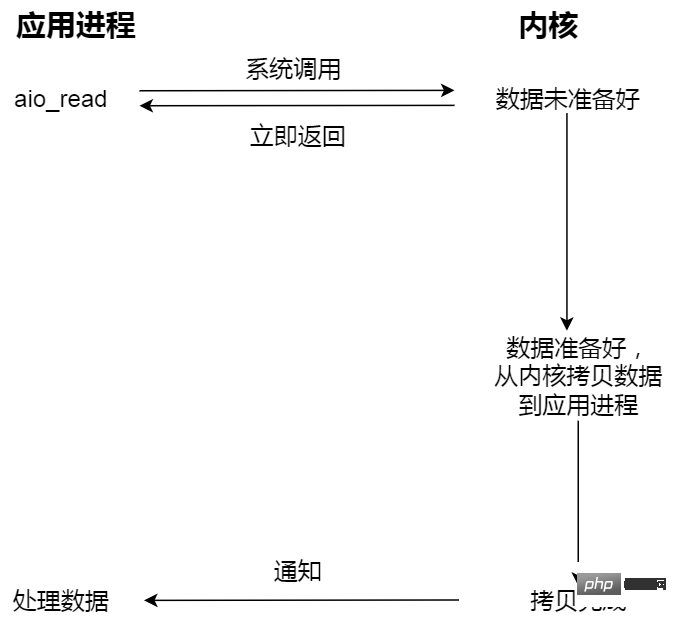
Mulakan I/O tak segerak dan kembalikan kernel secara automatik menyalin data dari ruang kernel ke ruang pengguna proses Ia juga tidak segerak dan dilengkapkan secara automatik oleh kernel Tidak seperti operasi segerak sebelumnya, aplikasi tidak perlu secara aktif memulakan tindakan salin.
Contohnya, kalau ke kantin untuk makan, anda seperti aplikasi, dan kantin pula seperti sistem operasi.
Menyekat I/O Contohnya, anda pergi ke kantin untuk makan, tetapi makanan di kantin belum siap, dan kemudian anda terus menunggu di sana dan menunggu setelah lama menunggu, akhirnya anda tunggu sampai makcik kantin Makanan dibawa keluar (proses penyediaan data), tetapi anda masih perlu menunggu makcik memasukkan makanan (ruang kernel) ke dalam kotak makan tengah hari anda (ruang pengguna selepas dua proses ini, anda boleh keluar). .
I/O yang tidak menghalang Contohnya, anda pergi ke kantin dan bertanya kepada ibu saudara anda sama ada makanan sudah siap, jadi anda pergi selepas beberapa dozen minit datang ke kantin sekali lagi dan bertanya kepadanya. Makcik berkata sudah siap, jadi Makcik membantu anda memasukkan makanan ke dalam kotak makan tengah hari anda. Anda perlu menunggu proses ini.
Asynchronous I/O ni macam, lepas awak suruh makcik kantin sediakan hidangan dan letak pinggan ke dalam kotak makan tengahari, kemudian hantar kotak makan tengah hari kepada awak, tak perlu tunggu lagi. keseluruhan proses.
Dalam perkhidmatan web, biasanya terdapat dua seni bina untuk memproses permintaan web, iaitu: thread-based architecture (seni bina berasaskan benang), event-driven architecture (model dipacu peristiwa)
seni bina berasaskan benang (seni bina berasaskan benang)
seni bina berasaskan benang (seni bina berasaskan benang): Ini lebih mudah difahami, ia ialah mod serentak berbilang benang, pelayan sedang memproses request , permintaan diperuntukkan kepada urutan bebas untuk diproses.
Oleh kerana setiap permintaan diberikan urutan bebas, penyekatan satu utas tidak akan menjejaskan urutan lain, yang boleh meningkatkan kelajuan tindak balas program.
Kelemahannya ialah sentiasa ada hubungan satu dengan satu antara sambungan dan utas Jika sambungan panjang yang sentiasa dalam keadaan Keep-Alive, ia akan menyebabkan sejumlah besar benang pekerja untuk menunggu dalam keadaan terbiar, contohnya, akses sistem fail, rangkaian, dsb. Di samping itu, beratus-ratus atau beribu-ribu sambungan boleh menyebabkan benang serentak membazirkan sejumlah besar ruang tindanan memori.
seni bina dipacu acara (model dipacu acara)
Seni bina dipacu acara terdiri daripada pengeluar acara dan pengguna acara, dan merupakan seni bina Pemacu yang diedarkan secara longgar , pengeluar mengumpul peristiwa yang dijana oleh aplikasi dan melakukan pemprosesan yang diperlukan pada acara dalam masa nyata sebelum menghalakannya ke sistem hiliran tanpa menunggu respons sistem Kumpulan pengguna acara hiliran menerima mesej acara dan memprosesnya secara tak segerak.
Seni bina dipacu acara mempunyai kelebihan berikut:
Kurangkan gandingan pengeluar dan pelanggan acara. Penerbit acara hanya perlu memberi perhatian kepada kejadian acara, dan tidak perlu memberi perhatian kepada cara acara itu diproses dan pelanggan mana ia diedarkan. Jika mana-mana pautan gagal, ia tidak akan menjejaskan operasi biasa perniagaan lain.
Seni bina dipacu peristiwa sesuai untuk senario tak segerak, walaupun semasa tempoh permintaan puncak Dikumpul dan disimpan dalam bas acara , dan kemudian secara beransur-ansur Edarkan acara penghantaran tanpa menyebabkan kesesakan sistem atau sumber berlebihan.
Keupayaan penghalaan dan penapisan dalam seni bina dipacu peristiwa menyokong pembahagian perkhidmatan untuk memudahkan pengembangan dan pengedaran laluan.
Mod reaktor dan mod Proaktor adalah kedua-dua kaedah pelaksanaan event-driven architecture (model dipacu peristiwa Berikut ialah analisis terperinci
Mod reaktor
Corak Reaktor merujuk kepada corak pemprosesan permintaan perkhidmatan dipacu peristiwa yang dihantar serentak kepada pemproses perkhidmatan melalui satu atau lebih input. Memproses acara sambungan IO rangkaian, membaca acara dan menulis acara. Tiga jenis peranan diperkenalkan dalam Reaktor- reaktor: memantau dan mengedarkan acara, menyambungkan acara kepada penerima, dan membaca dan menulis acara kepada pengendali: menerima permintaan sambungan, Selepas menerima sambungan, pengendali akan dibuat untuk mengendalikan acara baca dan tulis berikutnya pada sambungan rangkaian;
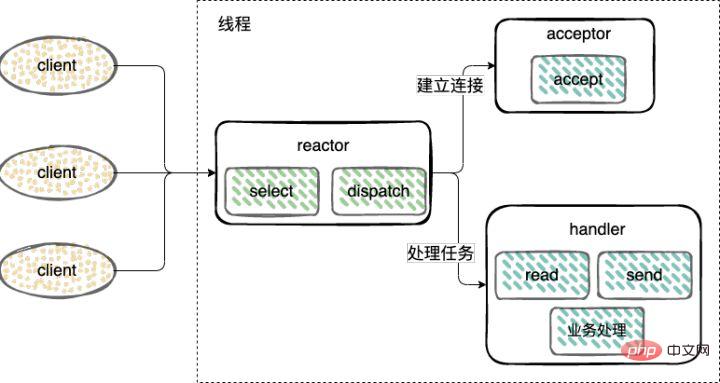
Mewujudkan sambungan (Penerima), mendengar untuk menerima, membaca, menulis acara (Reaktor), mengendalikan acara (Pengendali) ) kedua-duanya hanya menggunakan satu utas;
Tetapkan sambungan (Penerima) dan dengar untuk menerima, membaca, menulis acara (Reaktor) dan menggunakan semula urutan. 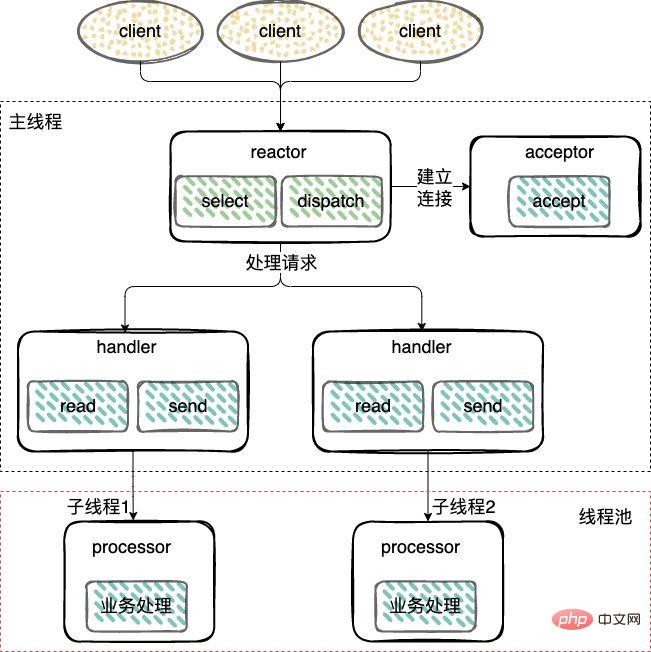
I/O
, digunakan untuk mengendalikan penubuhan sambungan rangkaian baharu, dan mendaftarkan socketChannel kepada subReactor, biasanya satu thread boleh mengendalikannya; 🎜 >Acara (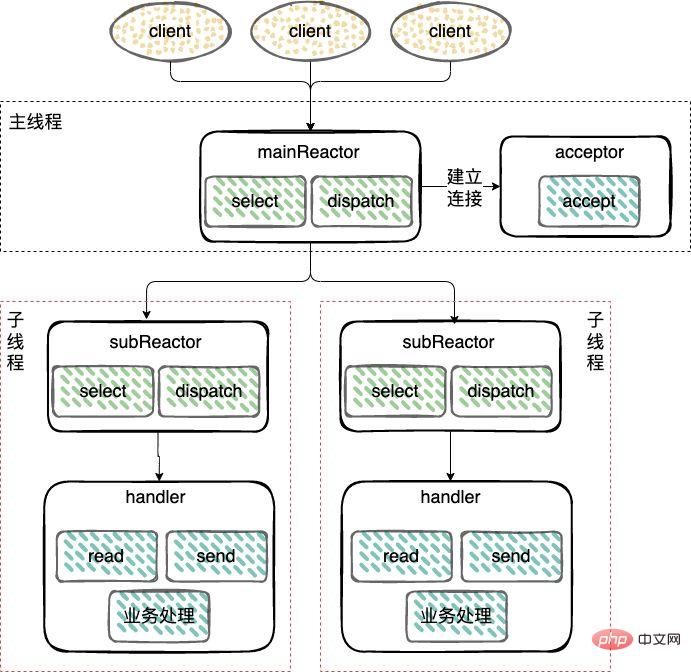 ), termasuk membaca dan menulis data dalam mod kernel semasa menunggu data siap, biasanya menggunakan multi-threading.
), termasuk membaca dan menulis data dalam mod kernel semasa menunggu data siap, biasanya menggunakan multi-threading.
Benang pekerja: Pemprosesan acara (Pengendali) boleh menggunakan benang yang sama seperti subReaktor, atau ia boleh dijadikan kumpulan benang, serupa dengan kaedah pemprosesan kumpulan benang pekerja dalam Reaktor berbilang benang mod di atas.
server socketMod Proaktor
accept、read、writeproses reaktor adalah serupa dengan mod ReaktorReactor
Reaktor ialah bukan -menyekat mod rangkaian segerak, apa yang dilihat ialah acara baca dan tulis sedia.
Setiap kali ia merasakan sesuatu peristiwa berlaku (seperti peristiwa sedia boleh dibaca), proses permohonan perlu secara aktif memanggil kaedah baca untuk melengkapkan bacaan data, iaitu proses permohonan perlu menerima soket secara aktif Data dalam cache dibaca ke dalam memori proses aplikasi Proses ini adalah segerak Proses aplikasi boleh memproses data hanya selepas membaca data.Proactor ialah mod rangkaian tak segerak yang merasakan peristiwa baca dan tulis selesai.
Oleh itu, Reaktor boleh difahami sebagai "apabila peristiwa datang, sistem pengendalian memberitahu proses permohonan, dan biarkan proses permohonan mengendalikannya", manakala Proactor boleh difahami sebagai "apabila peristiwa datang, operasi sistem memprosesnya, dan kemudian memberitahu proses permohonan selepas pemprosesan" .
- Untuk memberi contoh dalam kehidupan sebenar, model Reaktor bermaksud bahawa kurier berada di tingkat bawah dan menghubungi anda untuk memberitahu anda bahawa kurier telah tiba di komuniti anda. Anda perlu turun ke bawah untuk mengambil kurier itu sendiri. Dalam mod Proactor, kurier menghantar bungkusan terus ke pintu anda dan kemudian memberitahu anda.
read/write
Redis Sebelum versi v6.0, model rangkaian teras Redis sentiasa menjadi model Reaktor tunggal yang tipikal: menggunakan teknologi pemultipleksan seperti untuk memproses acara secara berterusan dalam gelung acara berbenang tunggal (Permintaan pelanggan ), dan akhirnya tulis semula data tindak balas kepada pelanggan:
Berikut ialah lihat cara Redis menggunakan satu utas untuk memproses tugasan
Rangka kerja dipacu peristiwa menangkap dan mengedarkan peristiwa
Rangka kerja rangkaian Redis melaksanakan model Reaktor, dan rangka kerja dipacu peristiwa dibangunkan dan dilaksanakan dengan sendirinya.epoll/select/kqueueRingkasnya, logik rangka kerja dipacu peristiwa ialah

Mari kita lihat beberapa fungsi utama yang dilaksanakan oleh rangka kerja dipacu peristiwa dalam Redis
// 执行事件捕获,分发和处理循环 void aeMain(aeEventLoop *eventLoop); // 用来注册监听的事件和事件对应的处理函数。只有对事件和处理函数进行了注册,才能在事件发生时调用相应的函数进行处理。 int aeCreateFileEvent(aeEventLoop *eventLoop, int fd, int mask, aeFileProc *proc, void *clientData); // aeProcessEvents 函数实现的主要功能,包括捕获事件、判断事件类型和调用具体的事件处理函数,从而实现事件的处理 int aeProcessEvents(aeEventLoop *eventLoop, int flags);
Gunakan aeMain sebagai gelung utama untuk memproses peristiwa Pantau dan tangkap secara berterusan, di mana fungsi aeProcessEvents akan dipanggil untuk merealisasikan tangkapan peristiwa, menentukan jenis acara dan memanggil fungsi pemprosesan acara tertentu untuk mencapai pemprosesan acara.
// https://github.com/redis/redis/blob/5.0/src/ae.c#L496
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}
// https://github.com/redis/redis/blob/5.0/src/ae.c#L358
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
...
if (eventLoop->maxfd != -1 || ((flags & AE_TIME_EVENTS) && !(flags & AE_DONT_WAIT))) {
...
//调用aeApiPoll函数捕获事件
numevents = aeApiPoll(eventLoop, tvp);
...
}
...
}
Anda boleh melihat bahawa penangkapan acara IO dalam aeProcessEvents diselesaikan dengan memanggil aeApiPoll.
aeApiPoll ialah API pemultipleksan I/O Ia berdasarkan pengkapsulan panggilan sistem seperti epoll_wait/select/kevent Ia mendengar dan menunggu acara baca dan tulis dicetuskan, dan kemudiannya fungsi teras dalam gelung peristiwa (Gelung Acara) , adalah asas untuk operasi dipacu peristiwa.
Redis bergantung pada mekanisme pemultipleksan IO yang disediakan oleh sistem pengendalian asas untuk melaksanakan tangkapan peristiwa dan menyemak sama ada sambungan baharu, peristiwa baca dan tulis berlaku. Untuk menyesuaikan diri dengan sistem pengendalian yang berbeza, Redis merangkum secara seragam fungsi pemultipleksan IO rangkaian yang dilaksanakan oleh sistem pengendalian yang berbeza.
// https://github.com/redis/redis/blob/5.0/src/ae.c#L49 #ifdef HAVE_EVPORT #include "ae_evport.c" // Solaris #else #ifdef HAVE_EPOLL #include "ae_epoll.c" // Linux #else #ifdef HAVE_KQUEUE #include "ae_kqueue.c" // MacOS #else #include "ae_select.c" // Windows #endif #endif #endif
ae_epoll.c: sepadan dengan epoll fungsi pemultipleksan IO pada Linux
ae_evport.c: sepadan dengan evport fungsi pemultipleksan IO pada Solaris; .c: Sepadan dengan fungsi pemultipleksan IO kqueue pada macOS atau FreeBSD;
ae_select.c: Sepadan dengan fungsi pemultipleksan IO pilih pada Linux (atau Windows).
Respon sambungan pelangganDengar acara baca soket apabila permintaan sambungan pelanggan datang, gunakan fungsi acceptTcpHandler untuk mewujudkan sambungan dengan klien
Apabila Redis dimulakan, fungsi utama program pelayan akan memanggil fungsi initSever untuk permulaan Semasa proses pemulaan, aeCreateFileEvent akan dipanggil oleh fungsi initServer untuk mendaftarkan acara yang akan dipantau dan fungsi pemprosesan acara yang sepadan. .Anda boleh melihat bahawa initServer akan memanggil aeCreateFileEvent untuk acara rangkaian pada setiap port IP berdasarkan bilangan port IP yang didayakan, mencipta pendengar untuk acara AE_READABLE dan mendaftarkan pengendali untuk acara AE_READABLE , yang merupakan fungsi acceptTcpHandler.
// https://github.com/redis/redis/blob/5.0/src/server.c#L2036
void initServer(void) {
...
// 创建一个事件处理程序以接受 TCP 和 Unix 中的新连接
for (j = 0; j < server.ipfd_count; j++) {
if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,
acceptTcpHandler,NULL) == AE_ERR)
{
serverPanic(
"Unrecoverable error creating server.ipfd file event.");
}
}
...
}Kemudian lihat pada pelaksanaan acceptTcpHandler 1 acceptTcpHandler digunakan terutamanya untuk mengendalikan perhubungan dengan klien
// https://github.com/redis/redis/blob/5.0/src/networking.c#L734
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) {
int cport, cfd, max = MAX_ACCEPTS_PER_CALL;
char cip[NET_IP_STR_LEN];
UNUSED(el);
UNUSED(mask);
UNUSED(privdata);
while(max--) {
// 用于accept客户端的连接,其返回值是客户端对应的socket
cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport);
if (cfd == ANET_ERR) {
if (errno != EWOULDBLOCK)
serverLog(LL_WARNING,
"Accepting client connection: %s", server.neterr);
return;
}
serverLog(LL_VERBOSE,"Accepted %s:%d", cip, cport);
// 会调用acceptCommonHandler对连接以及客户端进行初始化
acceptCommonHandler(cfd,0,cip);
}
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L664
static void acceptCommonHandler(int fd, int flags, char *ip) {
client *c;
// 分配并初始化新客户端
if ((c = createClient(fd)) == NULL) {
serverLog(LL_WARNING,
"Error registering fd event for the new client: %s (fd=%d)",
strerror(errno),fd);
close(fd); /* May be already closed, just ignore errors */
return;
}
// 判断当前连接的客户端是否超过最大值,如果超过的话,会拒绝这次连接。否则,更新客户端连接数的计数
if (listLength(server.clients) > server.maxclients) {
char *err = "-ERR max number of clients reached\r\n";
/* That's a best effort error message, don't check write errors */
if (write(c->fd,err,strlen(err)) == -1) {
/* Nothing to do, Just to avoid the warning... */
}
server.stat_rejected_conn++;
freeClient(c);
return;
}
...
}
// 使用多路复用,需要记录每个客户端的状态,client 之前通过链表保存
typedef struct client {
int fd; // 字段是客户端套接字文件描述符
sds querybuf; // 保存客户端发来命令请求的输入缓冲区。以Redis通信协议的方式保存
int argc; // 当前命令的参数数量
robj **argv; // 当前命令的参数
redisDb *db; // 当前选择的数据库指针
int flags;
list *reply; // 保存命令回复的链表。因为静态缓冲区大小固定,主要保存固定长度的命令回复,当处理一些返回大量回复的命令,则会将命令回复以链表的形式连接起来。
// ... many other fields ...
char buf[PROTO_REPLY_CHUNK_BYTES];
} client;
client *createClient(int fd) {
client *c = zmalloc(sizeof(client));
// 如果fd为-1,表示创建的是一个无网络连接的伪客户端,用于执行lua脚本的时候。
// 如果fd不等于-1,表示创建一个有网络连接的客户端
if (fd != -1) {
// 设置fd为非阻塞模式
anetNonBlock(NULL,fd);
// 禁止使用 Nagle 算法,client向内核递交的每个数据包都会立即发送给server出去,TCP_NODELAY
anetEnableTcpNoDelay(NULL,fd);
// 如果开启了tcpkeepalive,则设置 SO_KEEPALIVE
if (server.tcpkeepalive)
anetKeepAlive(NULL,fd,server.tcpkeepalive);
// 创建一个文件事件状态el,且监听读事件,开始接受命令的输入
if (aeCreateFileEvent(server.el,fd,AE_READABLE,
readQueryFromClient, c) == AE_ERR)
{
close(fd);
zfree(c);
return NULL;
}
}
...
// 初始化client 中的参数
return c;
}2 fungsi anetTcpAccept dipanggil untuk Terima sambungan klien, dan nilai pulangannya ialah soket yang sepadan dengan klien 3 Kemudian panggil acceptCommonHandler untuk memulakan sambungan dan klien; memulakan klien, gunakan aeCreateFileEvent pada masa yang sama Digunakan untuk mendaftarkan acara yang dipantau dan fungsi pemprosesan yang sepadan dengan peristiwa, dan mengikat pemproses baca perintah readQueryFromClient kepada deskriptor fail yang sepadan dengan sambungan baharu; Pelayan akan memantau acara baca deskriptor fail , apabila klien menghantar arahan dan mencetuskan acara AE_READABLE, fungsi panggil balik readQueryFromClient() akan dipanggil untuk membaca arahan daripada deskriptor fail fd dan menyimpannya dalam input buffer querybuf .
Penerimaan arahan
readQueryFromClient ialah titik permulaan pemprosesan permintaan, penghuraian dan pelaksanaan arahan permintaan pelanggan.1. readQueryFromClient(), membaca data daripada deskriptor fail fd ke dalam input buffer querybuf;2 Gunakan processInlineBuffer atau processMultibulkBuffer untuk menghuraikan arahan mengikut protokol Redis; , dan akhirnya keluarga fungsi addReply dipanggil Satu siri data tindak balas tulis fungsi kepada penimbal tulis yang sepadan dengan klien: klien->buf atau klien->balas klien->buf ialah penimbal tulis pilihan, dengan a saiz tetap 16KB Secara umumnya, klien->buf ialah penimbal tulis pilihan Ia boleh menampan data tindak balas yang mencukupi, tetapi jika data yang perlu dijawab oleh pelanggan dalam tetingkap masa adalah sangat besar, ia akan bertukar secara automatik. klien->menjawab senarai terpaut Penggunaan senarai terpaut secara teorinya boleh menyimpan data yang tidak terhingga besar (terhad (pada memori fizikal mesin), dan akhirnya menambah klien pada baris gilir LIFO clients_pending_write;
Balas arahan// https://github.com/redis/redis/blob/5.0/src/networking.c#L1522
// 读取client的输入缓冲区的内容
void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) {
client *c = (client*) privdata;
int nread, readlen;
size_t qblen;
UNUSED(el);
UNUSED(mask);
...
// 输入缓冲区的长度
qblen = sdslen(c->querybuf);
// 更新缓冲区的峰值
if (c->querybuf_peak < qblen) c->querybuf_peak = qblen;
// 扩展缓冲区的大小
c->querybuf = sdsMakeRoomFor(c->querybuf, readlen);
// 调用read从描述符为fd的客户端socket中读取数据
nread = read(fd, c->querybuf+qblen, readlen);
...
// 处理读取的内容
processInputBufferAndReplicate(c);
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1507
void processInputBufferAndReplicate(client *c) {
// 当前客户端不属于主从复制中的Master
// 直接调用 processInputBuffer,对客户端输入缓冲区中的命令和参数进行解析
if (!(c->flags & CLIENT_MASTER)) {
processInputBuffer(c);
// 客户端属于主从复制中的Master
// 调用processInputBuffer函数,解析客户端命令,
// 调用replicationFeedSlavesFromMasterStream 函数,将主节点接收到的命令同步给从节点
} else {
size_t prev_offset = c->reploff;
processInputBuffer(c);
size_t applied = c->reploff - prev_offset;
if (applied) {
replicationFeedSlavesFromMasterStream(server.slaves,
c->pending_querybuf, applied);
sdsrange(c->pending_querybuf,applied,-1);
}
}
}
// https://github.com/redis/redis/blob/5.0/src/networking.c#L1428
void processInputBuffer(client *c) {
server.current_client = c;
/* Keep processing while there is something in the input buffer */
// 持续读取缓冲区的内容
while(c->qb_pos < sdslen(c->querybuf)) {
...
/* Multibulk processing could see a <= 0 length. */
// 如果参数为0,则重置client
if (c->argc == 0) {
resetClient(c);
} else {
/* Only reset the client when the command was executed. */
// 执行命令成功后重置client
if (processCommand(c) == C_OK) {
if (c->flags & CLIENT_MASTER && !(c->flags & CLIENT_MULTI)) {
/* Update the applied replication offset of our master. */
c->reploff = c->read_reploff - sdslen(c->querybuf) + c->qb_pos;
}
// 命令处于阻塞状态中的客户端,不需要进行重置
if (!(c->flags & CLIENT_BLOCKED) || c->btype != BLOCKED_MODULE)
resetClient(c);
}
/* freeMemoryIfNeeded may flush slave output buffers. This may
* result into a slave, that may be the active client, to be
* freed. */
if (server.current_client == NULL) break;
}
}
/* Trim to pos */
if (server.current_client != NULL && c->qb_pos) {
sdsrange(c->querybuf,c->qb_pos,-1);
c->qb_pos = 0;
}
server.current_client = NULL;
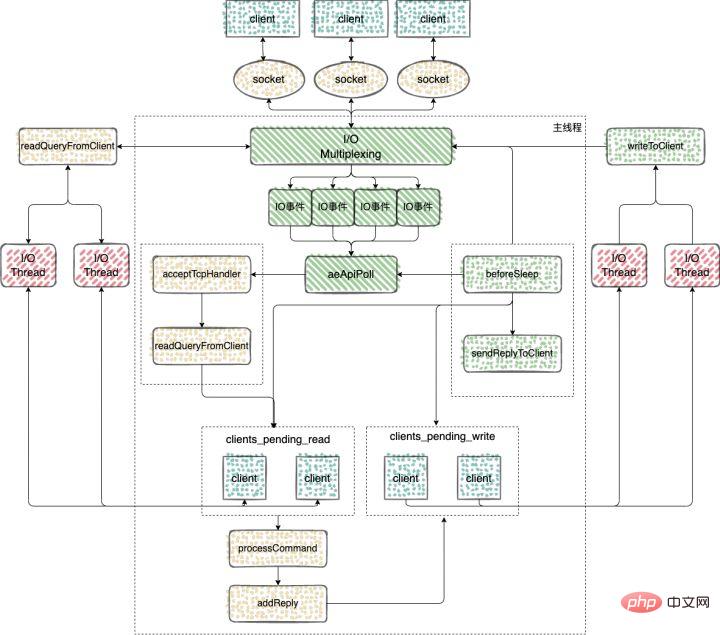
}Dalam rangka kerja dipacu peristiwa Redis, masukkan fungsi pemprosesan acara setiap kali ia gelung Sebelum memproses peristiwa tercetus yang dipantau atau acara bermasa, fungsi beforeSleep akan dipanggil untuk melaksanakan beberapa pemprosesan tugas, termasuk memanggil fungsi handleClientsWithPendingWrites, yang akan dalam penimbal klien Data ditulis kembali kepada klien.
1. Fungsi handleClientsWithPendingWrites yang dipanggil oleh fungsi beforeSleep akan melintasi baris gilir clients_pending_write (klien untuk ditulis balik), panggil writeToClient untuk menulis data dalam penimbal tulis klien kembali kepada klien panggil fungsi writeToClient untuk menghantar data dalam penimbal keluaran klien kepada klien2、如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites 函数就会调用 aeCreateFileEvent 函数,注册 sendReplyToClient 到该连接的写就绪事件,等待将后续将数据写回给客户端。
上面的执行流程总结下来就是
1、Redis Server 启动后,主线程会启动一个时间循环(Event Loop),持续监听事件;
2、client 到 server 的新连接,会调用 acceptTcpHandler 函数,之后会注册读事件 readQueryFromClient 函数,client 发给 server 的数据,都会在这个函数处理,这个函数会解析 client 的数据,找到对应的 cmd 函数执行;
3、cmd 逻辑执行完成后,server 需要写回数据给 client,调用 addReply 函数族的一系列函数将响应数据写入到对应 client 的写出缓冲区:client->buf 或者 client->reply ,client->buf 是首选的写出缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到 client->reply 链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把 client 添加进一个 LIFO 队列 clients_pending_write;
4、在 Redis 事件驱动框架每次循环进入事件处理函数前,来处理监听到的已触发事件或是到时的时间事件之前,都会调用 beforeSleep 函数,进行一些任务处理,这其中就包括了调用 handleClientsWithPendingWrites 函数,它会将 Redis sever 客户端缓冲区中的数据写回客户端;
- beforeSleep 函数调用的 handleClientsWithPendingWrites 函数,会遍历 clients_pending_write(待写回数据的客户端) 队列,调用 writeToClient 把 client 的写出缓冲区里的数据回写到客户端,然后调用 writeToClient 函数,将客户端输出缓冲区中的数据发送给客户端;
- 如果输出缓冲区的数据还没有写完,此时,handleClientsWithPendingWrites 函数就会调用 aeCreateFileEvent 函数,注册 sendReplyToClient 到该连接的写就绪事件,等待将后续将数据写回给客户端。
Redis 多IO线程
在 Redis6.0 的版本中,引入了多线程来处理 IO 任务,多线程的引入,充分利用了当前服务器多核特性,使用多核运行多线程,让多线程帮助加速数据读取、命令解析以及数据写回的速度,提升 Redis 整体性能。
Redis6.0 之前的版本用的是单线程 Reactor 模式,所有的操作都在一个线程中完成,6.0 之后的版本使用了主从 Reactor 模式。
由一个 mainReactor 线程接收连接,然后发送给多个 subReactor 线程处理,subReactor 负责处理具体的业务。
来看下 Redis 多IO线程的具体实现过程
多 IO 线程的初始化
使用 initThreadedIO 函数来初始化多 IO 线程。
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3573
void initThreadedIO(void) {
server.io_threads_active = 0; /* We start with threads not active. */
/* Don't spawn any thread if the user selected a single thread:
* we'll handle I/O directly from the main thread. */
// 如果用户只配置了一个 I/O 线程,不需要创建新线程了,直接在主线程中处理
if (server.io_threads_num == 1) return;
if (server.io_threads_num > IO_THREADS_MAX_NUM) {
serverLog(LL_WARNING,"Fatal: too many I/O threads configured. "
"The maximum number is %d.", IO_THREADS_MAX_NUM);
exit(1);
}
/* Spawn and initialize the I/O threads. */
// 初始化线程
for (int i = 0; i < server.io_threads_num; i++) {
/* Things we do for all the threads including the main thread. */
io_threads_list[i] = listCreate();
// 编号为0是主线程
if (i == 0) continue; /* Thread 0 is the main thread. */
/* Things we do only for the additional threads. */
pthread_t tid;
// 初始化io_threads_mutex数组
pthread_mutex_init(&io_threads_mutex[i],NULL);
// 初始化io_threads_pending数组
setIOPendingCount(i, 0);
// 主线程在启动 I/O 线程的时候会默认先锁住它,直到有 I/O 任务才唤醒它。
pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */
// 调用pthread_create函数创建IO线程,线程运行函数为IOThreadMain
if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) {
serverLog(LL_WARNING,"Fatal: Can't initialize IO thread.");
exit(1);
}
io_threads[i] = tid;
}
}可以看到在 initThreadedIO 中完成了对下面四个数组的初始化工作
io_threads_list 数组:保存了每个 IO 线程要处理的客户端,将数组每个元素初始化为一个 List 类型的列表;
io_threads_pending 数组:保存等待每个 IO 线程处理的客户端个数;
io_threads_mutex 数组:保存线程互斥锁;
io_threads 数组:保存每个 IO 线程的描述符。
命令的接收
Redis server 在和一个客户端建立连接后,就开始了监听客户端的可读事件,处理可读事件的回调函数就是 readQueryFromClient
// https://github.com/redis/redis/blob/6.2/src/networking.c#L2219
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
/* Check if we want to read from the client later when exiting from
* the event loop. This is the case if threaded I/O is enabled. */
// 判断是否从客户端延迟读取数据
if (postponeClientRead(c)) return;
...
}
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3746
int postponeClientRead(client *c) {
// 当多线程 I/O 模式开启、主线程没有在处理阻塞任务时,将 client 加入异步队列。
if (server.io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ|CLIENT_BLOCKED)))
{
// 给客户端的flag添加CLIENT_PENDING_READ标记,表示推迟该客户端的读操作
c->flags |= CLIENT_PENDING_READ;
// 将可获得加入clients_pending_write列表
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}
使用 clients_pending_read 保存了需要进行延迟读操作的客户端之后,这些客户端又是如何分配给多 IO 线程执行的呢?
handleClientsWithPendingWritesUsingThreads 函数:该函数主要负责将 clients_pending_write 列表中的客户端分配给 IO 线程进行处理。
看下如何实现
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3766
int handleClientsWithPendingReadsUsingThreads(void) {
// 当多线程 I/O 模式开启,才能执行下面的流程
if (!server.io_threads_active || !server.io_threads_do_reads) return 0;
int processed = listLength(server.clients_pending_read);
if (processed == 0) return 0;
// 遍历待读取的 client 队列 clients_pending_read,
// 根据IO线程的数量,让clients_pending_read中客户端数量对IO线程进行取模运算
// 取模的结果就是客户端分配给对应IO线程的编号
listIter li;
listNode *ln;
listRewind(server.clients_pending_read,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置当前 I/O 操作为读取操作,给每个 I/O 线程的计数器设置分配的任务数量,
// 让 I/O 线程可以开始工作:只读取和解析命令,不执行
io_threads_op = IO_THREADS_OP_READ;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
// 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
readQueryFromClient(c->conn);
}
listEmpty(io_threads_list[0]);
// 忙轮询,等待所有 IO 线程完成待读客户端的处理
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
// 遍历待读取的 client 队列,清除 CLIENT_PENDING_READ标记,
// 然后解析并执行所有 client 的命令。
while(listLength(server.clients_pending_read)) {
ln = listFirst(server.clients_pending_read);
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_READ;
listDelNode(server.clients_pending_read,ln);
serverAssert(!(c->flags & CLIENT_BLOCKED));
// client 的第一条命令已经被解析好了,直接尝试执行。
if (processPendingCommandsAndResetClient(c) == C_ERR) {
/* If the client is no longer valid, we avoid
* processing the client later. So we just go
* to the next. */
continue;
}
// 解析并执行 client 命令
processInputBuffer(c);
// 命令执行完成之后,如果 client 中有响应数据需要回写到客户端,则将 client 加入到待写出队列 clients_pending_write
if (!(c->flags & CLIENT_PENDING_WRITE) && clientHasPendingReplies(c))
clientInstallWriteHandler(c);
}
/* Update processed count on server */
server.stat_io_reads_processed += processed;
return processed;
}
1、当客户端发送命令请求之后,会触发 Redis 主线程的事件循环,命令处理器 readQueryFromClient 被回调,多线程模式下,则会把 client 加入到 clients_pending_read 任务队列中去,后面主线程再分配到 I/O 线程去读取客户端请求命令;
2、主线程会根据 clients_pending_read 中客户端数量对IO线程进行取模运算,取模的结果就是客户端分配给对应IO线程的编号;
3、忙轮询,等待所有的线程完成读取客户端命令的操作,这一步用到了多线程的请求;
4、遍历 clients_pending_read,执行所有 client 的命令,这里就是在主线程中执行的,命令的执行是单线程的操作。
命令的回复
完成命令的读取、解析以及执行之后,客户端命令的响应数据已经存入 client->buf 或者 client->reply 中。
主循环在捕获 IO 事件的时候,beforeSleep 函数会被调用,进而调用 handleClientsWithPendingWritesUsingThreads ,写回响应数据给客户端。
// https://github.com/redis/redis/blob/6.2/src/networking.c#L3662
int handleClientsWithPendingWritesUsingThreads(void) {
int processed = listLength(server.clients_pending_write);
if (processed == 0) return 0; /* Return ASAP if there are no clients. */
// 如果用户设置的 I/O 线程数等于 1 或者当前 clients_pending_write 队列中待写出的 client
// 数量不足 I/O 线程数的两倍,则不用多线程的逻辑,让所有 I/O 线程进入休眠,
// 直接在主线程把所有 client 的相应数据回写到客户端。
if (server.io_threads_num == 1 || stopThreadedIOIfNeeded()) {
return handleClientsWithPendingWrites();
}
// 唤醒正在休眠的 I/O 线程(如果有的话)。
if (!server.io_threads_active) startThreadedIO();
/* Distribute the clients across N different lists. */
// 和上面的handleClientsWithPendingReadsUsingThreads中的操作一样分配客户端给IO线程
listIter li;
listNode *ln;
listRewind(server.clients_pending_write,&li);
int item_id = 0;
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
c->flags &= ~CLIENT_PENDING_WRITE;
/* Remove clients from the list of pending writes since
* they are going to be closed ASAP. */
if (c->flags & CLIENT_CLOSE_ASAP) {
listDelNode(server.clients_pending_write, ln);
continue;
}
int target_id = item_id % server.io_threads_num;
listAddNodeTail(io_threads_list[target_id],c);
item_id++;
}
// 设置当前 I/O 操作为写出操作,给每个 I/O 线程的计数器设置分配的任务数量,
// 让 I/O 线程可以开始工作,把写出缓冲区(client->buf 或 c->reply)中的响应数据回写到客户端。
// 可以看到写回操作也是多线程执行的
io_threads_op = IO_THREADS_OP_WRITE;
for (int j = 1; j < server.io_threads_num; j++) {
int count = listLength(io_threads_list[j]);
setIOPendingCount(j, count);
}
// 主线程自己也会去执行读取客户端请求命令的任务,以达到最大限度利用 CPU。
listRewind(io_threads_list[0],&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
writeToClient(c,0);
}
listEmpty(io_threads_list[0]);
/* Wait for all the other threads to end their work. */
// 等待所有的线程完成对应的工作
while(1) {
unsigned long pending = 0;
for (int j = 1; j < server.io_threads_num; j++)
pending += getIOPendingCount(j);
if (pending == 0) break;
}
// 最后再遍历一次 clients_pending_write 队列,检查是否还有 client 的写出缓冲区中有残留数据,
// 如果有,那就为 client 注册一个命令回复器 sendReplyToClient,等待客户端写就绪再继续把数据回写。
listRewind(server.clients_pending_write,&li);
while((ln = listNext(&li))) {
client *c = listNodeValue(ln);
// 检查 client 的写出缓冲区是否还有遗留数据。
if (clientHasPendingReplies(c) &&
connSetWriteHandler(c->conn, sendReplyToClient) == AE_ERR)
{
freeClientAsync(c);
}
}
listEmpty(server.clients_pending_write);
/* Update processed count on server */
server.stat_io_writes_processed += processed;
return processed;
}
1、也是会将 client 分配给所有的 IO 线程;
2、忙轮询,等待所有的线程将缓存中的数据写回给客户端,这里写回操作使用的多线程;
3、最后再遍历 clients_pending_write,为那些还残留有响应数据的 client 注册命令回复处理器 sendReplyToClient,等待客户端可写之后在事件循环中继续回写残余的响应数据。
通过上面的分析可以得出结论,Redis 多IO线程中多线程的应用
1、解析客户端的命令的时候用到了多线程,但是对于客户端命令的执行,使用的还是单线程;
2、给客户端回复数据的时候,使用到了多线程。
来总结下 Redis 中多线程的执行过程
1、Redis Server 启动后,主线程会启动一个时间循环(Event Loop),持续监听事件;
2、client 到 server 的新连接,会调用 acceptTcpHandler 函数,之后会注册读事件 readQueryFromClient 函数,client 发给 server 的数据,都会在这个函数处理;
3、客户端发送给服务端的数据,不会类似 6.0 之前的版本使用 socket 直接去读,而是会将 client 放入到 clients_pending_read 中,里面保存了需要进行延迟读操作的客户端;
4、处理 clients_pending_read 的函数 handleClientsWithPendingReadsUsingThreads,在每次事件循环的时候都会调用;
- 1、主线程会根据 clients_pending_read 中客户端数量对IO线程进行取模运算,取模的结果就是客户端分配给对应IO线程的编号;
- 2、忙轮询,等待所有的线程完成读取客户端命令的操作,这一步用到了多线程的请求;
- 3、遍历 clients_pending_read,执行所有 client 的命令,这里就是在主线程中执行的,命令的执行是单线程的操作。
5、命令执行完成以后,回复的内容还是会被写入到 client 的缓存区中,这些 client 和6.0之前的版本处理方式一样,也是会被放入到 clients_pending_write(待写回数据的客户端);
6、6.0 对于clients_pending_write 的处理使用到了多线程;
- 1、也是会将 client 分配给所有的 IO 线程;
- 2、忙轮询,等待所有的线程将缓存中的数据写回给客户端,这里写回操作使用的多线程;
- 3、最后再遍历 clients_pending_write,为那些还残留有响应数据的 client 注册命令回复处理器 sendReplyToClient,等待客户端可写之后在事件循环中继续回写残余的响应数据。
原子性的单命令
通过上面的分析,我们知道,Redis 的主线程是单线程执行的,所有 Redis 中的单命令,都是原子性的。
所以对于一些场景的操作尽量去使用 Redis 中单命令去完成,就能保证命令执行的原子性。
比如对于上面的读取-修改-写回操作可以使用 Redis 中的原子计数器, INCRBY(自增)、DECRBR(自减)、INCR(加1) 和 DECR(减1) 等命令。
这些命令可以直接帮助我们处理并发控制
127.0.0.1:6379> incr test-1 (integer) 1 127.0.0.1:6379> incr test-1 (integer) 2 127.0.0.1:6379> incr test-1 (integer) 3
分析下源码,看看这个命令是如何实现的
// https://github.com/redis/redis/blob/6.2/src/t_string.c#L617
void incrCommand(client *c) {
incrDecrCommand(c,1);
}
void decrCommand(client *c) {
incrDecrCommand(c,-1);
}
void incrbyCommand(client *c) {
long long incr;
if (getLongLongFromObjectOrReply(c, c->argv[2], &incr, NULL) != C_OK) return;
incrDecrCommand(c,incr);
}
void decrbyCommand(client *c) {
long long incr;
if (getLongLongFromObjectOrReply(c, c->argv[2], &incr, NULL) != C_OK) return;
incrDecrCommand(c,-incr);
}
可以看到 INCRBY(自增)、DECRBR(自减)、INCR(加1) 和 DECR(减1)这几个命令最终都是调用的 incrDecrCommand
// https://github.com/redis/redis/blob/6.2/src/t_string.c#L579
void incrDecrCommand(client *c, long long incr) {
long long value, oldvalue;
robj *o, *new;
// 查找有没有对应的键值
o = lookupKeyWrite(c->db,c->argv[1]);
// 判断类型,如果value对象不是字符串类型,直接返回
if (checkType(c,o,OBJ_STRING)) return;
// 将字符串类型的value转换为longlong类型保存在value中
if (getLongLongFromObjectOrReply(c,o,&value,NULL) != C_OK) return;
// 备份旧的value
oldvalue = value;
// 判断 incr 的值是否超过longlong类型所能表示的范围
// 长度的范围,十进制 64 位有符号整数
if ((incr < 0 && oldvalue < 0 && incr < (LLONG_MIN-oldvalue)) ||
(incr > 0 && oldvalue > 0 && incr > (LLONG_MAX-oldvalue))) {
addReplyError(c,"increment or decrement would overflow");
return;
}
// 计算新的 value值
value += incr;
if (o && o->refcount == 1 && o->encoding == OBJ_ENCODING_INT &&
(value < 0 || value >= OBJ_SHARED_INTEGERS) &&
value >= LONG_MIN && value <= LONG_MAX)
{
new = o;
o->ptr = (void*)((long)value);
} else {
new = createStringObjectFromLongLongForValue(value);
// 如果之前的 value 对象存在
if (o) {
// 重写为 new 的值
dbOverwrite(c->db,c->argv[1],new);
} else {
// 如果之前没有对应的 value,新设置 value 的值
dbAdd(c->db,c->argv[1],new);
}
}
// 进行通知
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"incrby",c->argv[1],c->db->id);
server.dirty++;
addReply(c,shared.colon);
addReply(c,new);
addReply(c,shared.crlf);
}
总结
1、Redis 中的命令执行都是单线程的,所以单命令的执行都是原子性的;
2、虽然 Redis6.0 版本引入了多线程,但是仅是在接收客户端的命令和回复客户端的数据用到了多线程,实际命令的执行还是单线程在处理;
推荐学习:Redis视频教程
Atas ialah kandungan terperinci Analisis terperinci tentang atomicity arahan dalam Redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!