
Rumah >pangkalan data >Redis >Mari analisa penyelesaian kepada masalah data panas Redis bersama-sama
Mari analisa penyelesaian kepada masalah data panas Redis bersama-sama

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-04-20 13:12:175261semak imbas
Artikel ini membawakan anda pengetahuan yang berkaitan tentang Redis, yang terutamanya memperkenalkan isu berkaitan tentang penyelesaian nilai besar kunci panas Redis Mari kita lihat bersama-sama. .

Pembelajaran yang disyorkan: Tutorial video Redis
Mengenai data panas Redis & soalan kunci besar dan nilai besar juga mudah ditanya tinggi -soalan peringkat Adalah lebih baik untuk mempelajari masalah sekaligus dan membiarkan penemuduga terdiam Dalam pengalaman kerja peribadi saya, masalah data panas lebih berkemungkinan dihadapi di tempat kerja daripada runtuhan salji Namun, kebanyakan masa, titik panas tidak cukup panas dan akan dimaklumkan dan diselesaikan lebih awal Tetapi apabila masalah ini tidak dapat dikawal, masalah dalam talian yang ditimbulkan akan cukup untuk meletakkan prestasi anda pada tahun ini.
Dalam keadaan biasa, data dalam gugusan Redis diagihkan sama rata ke setiap nod, dan permintaan diagihkan sama rata kepada setiap serpihan Walau bagaimanapun, dalam beberapa senario khas, seperti perangkak luaran, serangan dan produk panas Tunggu, contoh yang paling biasa ialah apabila seorang selebriti mengumumkan perceraian mereka di Weibo, dan orang ramai masuk meninggalkan mesej, menyebabkan fungsi ulasan Weibo ranap dalam tempoh yang singkat ini, bilangan lawatan ke kunci tertentu adalah terlalu besar dan permintaan akan dibuat untuk kunci yang sama kepada serpihan data yang sama, mengakibatkan beban yang tinggi pada serpihan dan menjadi halangan, yang membawa kepada satu siri masalah seperti runtuhan salji.
1. Penemuduga: Pernahkah anda menghadapi masalah data panas Redis dalam projek anda?
Analisis masalah: Kali terakhir saya mendengar bos besar dalam temuduga kumpulan Alibaba p7, saya ditanya soalan ini, indeks kesukarannya ialah lima bintang , tunggu saya Menjadi noob sememangnya satu kelebihan.
Jawapan: Saya ada sesuatu untuk diperkatakan tentang isu data panas Saya sedar tentang isu ini sejak mula-mula belajar menggunakan Redis, jadi apabila menggunakan ia Kami sengaja mengelak dan dengan tegas tidak menggali lubang untuk diri kami sendiri Masalah terbesar dengan data hotspot akan menyebabkan kegagalan yang disebabkan oleh beban yang tidak seimbang dalam gugusan Redis (iaitu, data condong.
Mula-mula mari kita bincangkan tentang punca utama kegagalan ketidakseimbangan beban kelompok Reids:
- Kunci diakses tinggi , iaitu kekunci panas, mengikut penyelenggaraan lepas Jika QPS yang diakses oleh kunci melebihi 1,000, anda harus memberi perhatian kepadanya, seperti produk popular, topik hangat, dsb.
- Nilai Besar Walaupun akses QPS bagi sesetengah kekunci tidak tinggi, disebabkan nilai yang besar, beban pada kad rangkaian adalah besar, trafik kad rangkaian penuh dan mesin tunggal mungkin mengalami kegagalan Gigabit/saat, IO.
- Kunci Panas dan Nilai Besar wujud pada masa yang sama , pembunuh pelayan.
Jadi apakah kerosakan yang akan disebabkan oleh kekunci panas atau nilai yang besar:
- Masalah pencongan data: Nilai yang besar akan membawa kepada pengagihan data yang tidak sekata pada nod yang berbeza dalam kelompok, menyebabkan masalah pencongan data , sejumlah besar permintaan dengan nisbah baca-tulis yang sangat tinggi akan jatuh pada pelayan redis yang sama, dan beban redis akan meningkat dengan serius, menjadikannya mudah untuk ranap.
- QPS Skew: QPS tidak sekata merentas serpihan.
- Nilai yang besar akan menyebabkan penimbal pelayan Redis tidak mencukupi, menyebabkan mendapat tamat masa.
- Oleh kerana Nilai terlalu besar, kad rangkaian dalam bilik komputer mempunyai trafik yang tidak mencukupi.
- Kegagalan cache Redis membawa kepada tindak balas berantai pecahan lapisan pangkalan data.
2. Penemubual: Dalam projek sebenar, bagaimanakah anda mengesan isu data hangat dengan tepat?
Jawapan: Penyelesaian masalah ini agak luas Ia bergantung kepada senario perniagaan yang berbeza Contohnya, jika sesebuah syarikat menganjurkan aktiviti promosi, maka mesti ada cara untuk mengira produk yang mengambil bahagian dalam promosi terlebih dahulu , senario ini boleh melepasi kaedah anggaran. Untuk kecemasan dan ketidakpastian, Redis akan memantau data hotspot dengan sendirinya. Untuk meringkaskan:
-
Cara mengetahui lebih awal:
Bergantung pada perniagaan, statistik daging manusia atau statistik sistem mungkin menjadi data hangat, seperti item promosi, topik hangat , Topik percutian, aktiviti ulang tahun, dsb. -
Kaedah pengumpulan pelanggan Redis:
Pemanggil mengira bilangan permintaan kunci dengan mengira, tetapi bilangan kunci tidak boleh diramalkan dan kod itu sangat mengganggu.public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) { //从参数中获取key String key = analysis(args); //计数 counterKey(key); //ignore } -
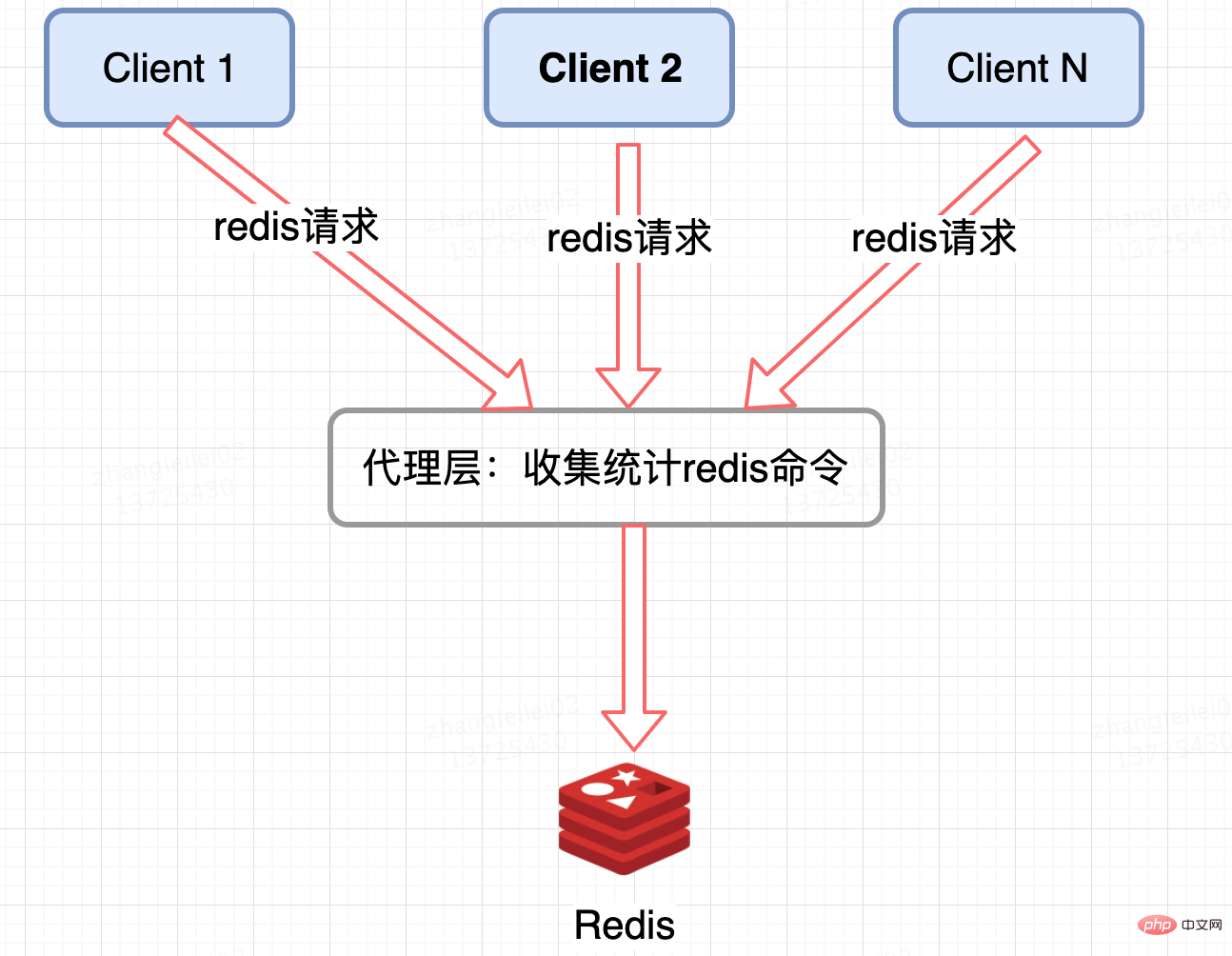
Statistik lapisan proksi kluster Redis:
Seni bina edaran Redis berasaskan ejen seperti Twemproxy dan codis mempunyai pintu masuk bersatu dan boleh dikumpulkan pada lapisan Proksi Dilaporkan , tetapi kelemahannya adalah jelas, tidak semua seni bina kluster Redis mempunyai proksi.
-
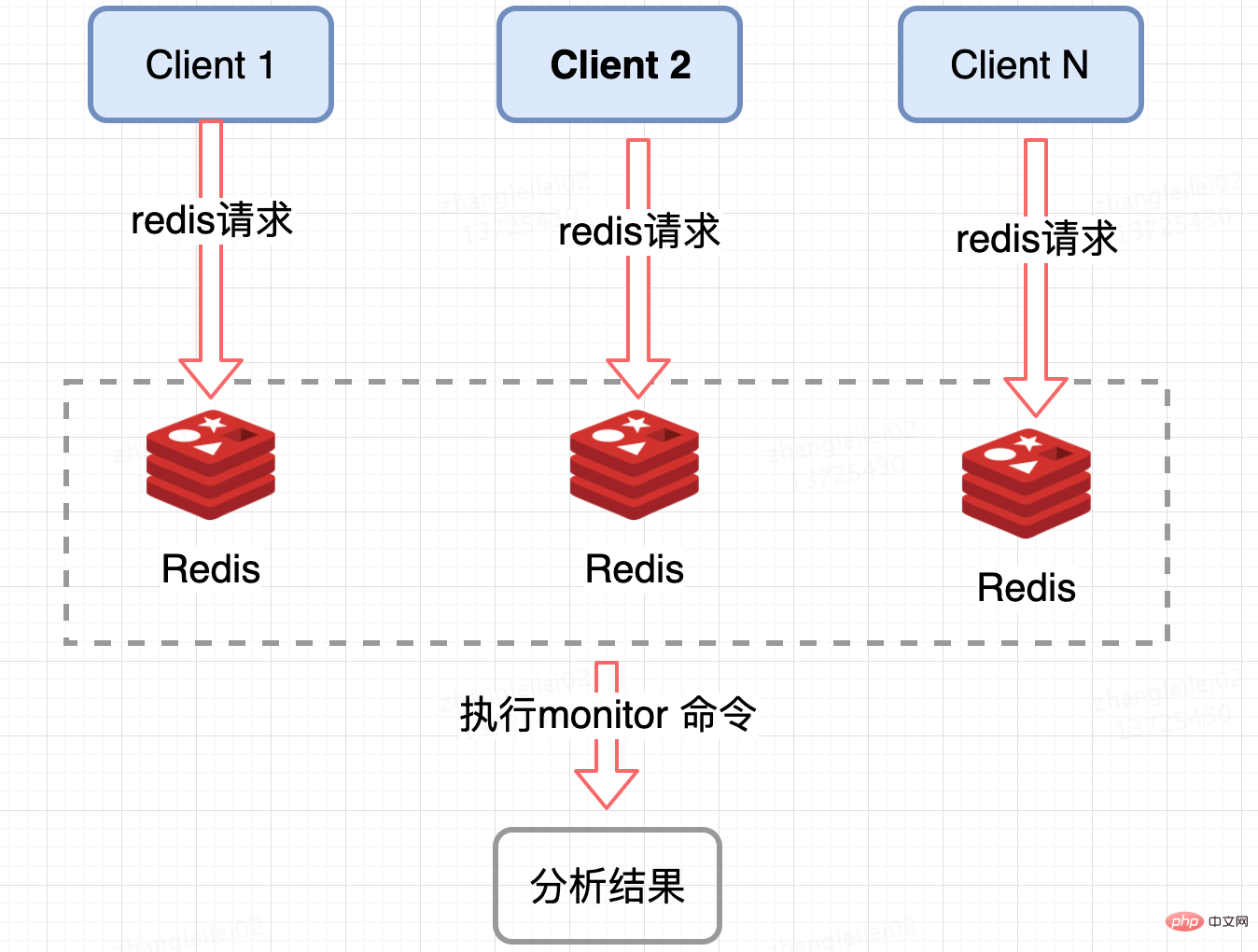
Koleksi pelayan Redis:
Pantau QPS satu serpihan Redis, dan pantau nod di mana QPS dicondongkan ke tahap tertentu untuk mendapatkan kunci tempat liputan. Redis menyediakan arahan monitor, anda boleh mengira semua arahan pada nod Redis tertentu dalam tempoh masa dan menganalisis kekunci panas Di bawah keadaan konkurensi yang tinggi, akan ada bahaya tersembunyi letupan memori dan prestasi Redis, jadi kaedah ini sesuai untuk digunakan dalam tempoh yang singkat; ia juga hanya Ia boleh mengira kekunci hotspot nod Redis Untuk kelompok, statistik ringkasan diperlukan, yang sedikit menyusahkan dari perspektif perniagaan.
Empat kaedah yang dinyatakan di atas semuanya biasa digunakan dalam industri Saya mempunyai idea baharu dengan mengkaji kod sumber Redis. Jenis 5: Ubah suai kod sumber Redis.
-
Ubah suai kod sumber Redis: (Memikirkan idea daripada membaca kod sumber)
Saya mendapati bahawa Redis4.0 telah membawa kepada kita banyak perkara baharu Ciri, termasuk mekanisme penemuan kunci tempat liputan berdasarkan LFU Dengan ciri baharu ini, kami boleh melaksanakan statistik kunci tempat liputan atas dasar ini.
Psikologi penemubual: Pemuda itu agak berfikiran dan berfikiran luas, malah dia memberi perhatian untuk mengubah suai kod sumber Saya tidak mempunyai cita-cita ini. Kami memerlukan orang seperti ini dalam pasukan kami.
(Temui masalah, analisis masalah, selesaikan masalah, dan beritahu terus cara menyelesaikan masalah hot data tanpa menunggu penemuduga bertanya soalan. Ini kandungan teras)
3. Cara menyelesaikan isu hot data
Jawapan: Mengenai cara menguruskan isu hot data, terdapat dua aspek utama yang perlu dipertimbangkan dalam menyelesaikan masalah ini. Yang pertama ialah serpihan data, supaya Tekanan diagihkan secara sama rata kepada berbilang serpihan kluster untuk menghalang satu mesin daripada tergantung.
Ringkasan ringkasan:
-
pemisahan kunci:
Jika jenis kunci semasa ialah struktur data sekunder, seperti sebagai jenis Hash. Jika bilangan elemen cincang adalah besar, anda boleh mempertimbangkan untuk memisahkan cincang semasa, supaya kunci panas boleh dibahagikan kepada beberapa kunci baharu dan diedarkan kepada nod Redis yang berbeza, dengan itu mengurangkan tekanan -
Berhijrah kunci tempat liputan:
Mengambil Redis Cluster sebagai contoh, anda boleh memindahkan slot tempat kunci tempat liputan terletak ke nod Redis baharu secara berasingan, walaupun QPS kunci tempat liputan ini sangat tinggi. ia tidak akan menjejaskan keseluruhan gugusan perniagaan lain juga boleh disesuaikan dan dibangunkan, dan kunci tempat liputan dipindahkan secara automatik ke nod bebas ini juga berbilang salinan. -
Had semasa kunci tempat liputan:
Untuk perintah baca, kita boleh menyelesaikan masalah dengan memindahkan kekunci tempat liputan dan kemudian menambah nod hamba Untuk arahan tulis, kita boleh mengehadkan arus dengan menyasarkan kunci tempat liputan ini secara berasingan . -
Tingkatkan cache setempat:
Untuk perniagaan yang konsistensi datanya tidak begitu tinggi, anda boleh cache kunci tempat liputan dalam cache tempatan mesin perniagaan, kerana ia berada dalam tempatan ingatan akhir perniagaan. Panggilan IO jauh dihapuskan. Walau bagaimanapun, apabila data dikemas kini, ia mungkin menyebabkan ketidakkonsistenan antara perniagaan dan data Redis.
Penemuduga: Anda menjawab dengan sangat baik dan menganggapnya sangat komprehensif.
4. Penemubual: Berkenaan soalan terakhir tentang Redis, Redis menyokong jenis data yang kaya, jadi bagaimana untuk menyelesaikan masalah Nilai besar yang disimpan dalam jenis data ini Pernahkah anda menghadapi situasi ini dalam talian?
Analisis masalah: Berbanding dengan konsep besar hot key, konsep big Value lebih mudah difahami Memandangkan Redis berjalan dalam satu thread, jika nilai an operasi adalah sangat besar, ia akan menjejaskan keseluruhan operasi Masa tindak balas redis mempunyai kesan negatif kerana Redis adalah pangkalan data struktur Nilai-Kekunci bermakna bahawa satu nilai mengambil jumlah yang paling langsung kesan pada gugusan Redis ialah data senget.
Jawapan: (Nak kecutkan saya? Saya bersedia.)
Biar saya bercakap dahulu tentang betapa besarnya Nilai, yang diberikan berdasarkan syarikat infrastruktur Nilai pengalaman boleh dibahagikan seperti berikut:
Nota: (Nilai pengalaman bukan standard, ia diringkaskan berdasarkan pemerhatian jangka panjang kes dalam talian oleh kakitangan operasi dan penyelenggaraan kluster)
- Besar: nilai jenis rentetan > 10K, bilangan elemen dalam set, senarai, cincang, zset dan jenis data koleksi lain > 1000.
- Lebih besar: nilai jenis rentetan > 100K, bilangan elemen dalam set, senarai, cincang, zset dan jenis data koleksi lain > 10000.
Memandangkan Redis berjalan dalam satu utas, jika nilai operasi adalah sangat besar, ia akan memberi kesan negatif pada masa tindak balas keseluruhan redis. Oleh itu, ia boleh dibahagikan jika ia boleh dibahagikan dari segi perniagaan Berikut adalah beberapa contoh biasa: Pelan perobohan:
- 一个较大的 key-value 拆分成几个 key-value ,将操作压力平摊到多个 redis 实例中,降低对单个 redis 的 IO 影响
- 将分拆后的几个 key-value 存储在一个 hash 中,每个 field 代表一个具体的属性,使用 hget,hmget 来获取部分的 value,使用 hset,hmset 来更新部分属性。
- hash、set、zset、list 中存储过多的元素
类似于场景一中的第一个做法,可以将这些元素分拆。
以 hash 为例,原先的正常存取流程是:
hget(hashKey, field); hset(hashKey, field, value)
现在,固定一个桶的数量,比如 10000,每次存取的时候,先在本地计算 field 的 hash 值,模除 10000,确定该 field 落在哪个 key 上,核心思想就是将 value 打散,每次只 get 你需要的。
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value); hget(newHashKey, field)
推荐学习:Redis学习教程
Atas ialah kandungan terperinci Mari analisa penyelesaian kepada masalah data panas Redis bersama-sama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Analisis terperinci Redis tentang replikasi tuan-hamba, sentinel dan kelompok
- Contoh terperinci tentang cara menggunakan kluster redis
- Pemahaman mendalam tentang penyelesaian kluster redis (mod master-slave, mod sentinel, mod Kluster Redis)
- Cache Redis mempelajari slot cincang dan cincang yang konsisten
- Ketahui lebih lanjut tentang cara menggunakan fungsi kelompok redis dalam nod [konfigurasi terperinci]