
Rumah >pangkalan data >Redis >Pemahaman mendalam tentang penyelesaian kluster redis (mod master-slave, mod sentinel, mod Kluster Redis)
Pemahaman mendalam tentang penyelesaian kluster redis (mod master-slave, mod sentinel, mod Kluster Redis)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-03-24 19:12:073913semak imbas
Artikel ini membawakan anda pengetahuan yang berkaitan tentang Redis, yang terutamanya memperkenalkan isu berkaitan mod tuan-hamba, mod sentinel dan mod Kluster Redis. Saya harap ia akan membantu semua orang.

Pembelajaran yang disyorkan: Tutorial Redis
Pengenalan kepada penyelesaian kelompok redis (mod tuan-hamba, mod sentinel, mod Kluster Redis )
1. Mod Master-slave
Terdapat dua masalah utama dalam menyimpan data sepenuhnya dalam satu redis:
Sandaran data dan penurunan prestasi yang disebabkan oleh volum data yang besar.
Model tuan-hamba Redis menyediakan penyelesaian yang lebih baik untuk kedua-dua masalah ini. Mod induk-hamba merujuk kepada menggunakan satu contoh redis sebagai hos dan contoh selebihnya sebagai mesin sandaran.
Data hos dan hamba benar-benar konsisten Hos menyokong pelbagai operasi seperti menulis dan membaca data, manakala hamba hanya menyokong penyegerakan dan membaca data dengan hos hos, dan hos secara automatik menyegerakkan operasi penulisan data kepada hamba.
Mod induk-hamba menyelesaikan masalah sandaran data dengan baik, dan memandangkan data perkhidmatan induk-hamba hampir konsisten, arahan untuk menulis data boleh dihantar kepada hos untuk dilaksanakan, manakala perintah untuk membaca data boleh dihantar ke perlaksanaan mesin yang berbeza, dengan itu mencapai tujuan pemisahan membaca dan menulis.
Cara Replikasi Master-Slave berfungsi:
Selepas perkhidmatan nod hamba Slave bermula dan bersambung kepada Master, ia akan menghantar arahan SYNC secara aktif. Selepas menerima arahan penyegerakan, nod induk perkhidmatan Master akan memulakan proses simpan latar belakang dan mengumpul semua arahan yang diterima untuk mengubah suai set data Selepas proses latar belakang selesai, Master akan memindahkan keseluruhan fail pangkalan data kepada Hamba untuk menyelesaikannya penyegerakan. Perkhidmatan nod hamba hamba menyimpan dan memuatkan data fail pangkalan data ke dalam memori selepas menerimanya. Selepas itu, nod Master terus menghantar semua arahan pengubahsuaian yang dikumpul dan arahan pengubahsuaian baharu kepada Hamba dalam urutan The Slaves akan melaksanakan perintah pengubahsuaian data ini kali ini untuk mencapai penyegerakan data akhir.
Jika pautan antara Master dan Slave diputuskan, Slave boleh menyambung semula secara automatik ke Master Selepas sambungan berjaya, penyegerakan penuh akan dilakukan secara automatik. 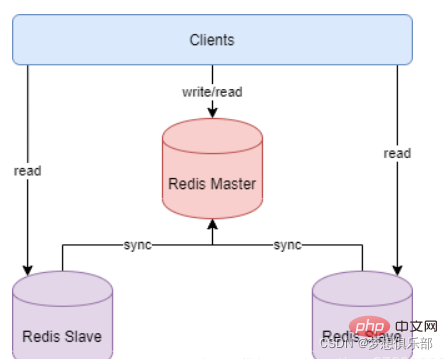
Pengedaran:
versi redis:6.0.9
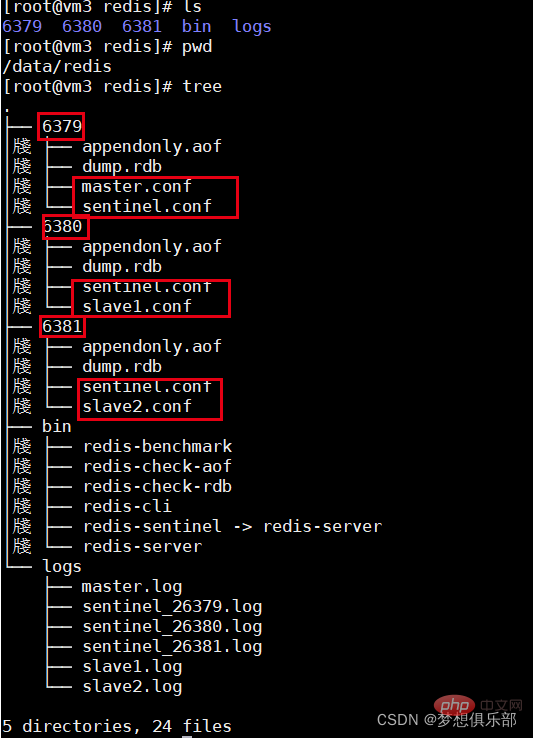
1 Salin 4 salinan fail konfigurasi Redis
dan nama mereka master .conf slave1.conf slave2.conf slave3.conf
2. Konfigurasi ringkas 4 fail konfigurasi
Fail konfigurasi nod Induk umumnya tidak memerlukan tetapan khas Port lalai ialah 6379
Slave1 Node Port Set 6380 dan Konfigurasikan satu lagi baris replika 127.0.0.1 6379
Slave2 Node Port Setting 6381 Konfigurasi satu lagi baris replika 127.0.0.1 6379 6379
redis-server slave1.conf
redis-server slave2.conf
redis-server slave3.conf
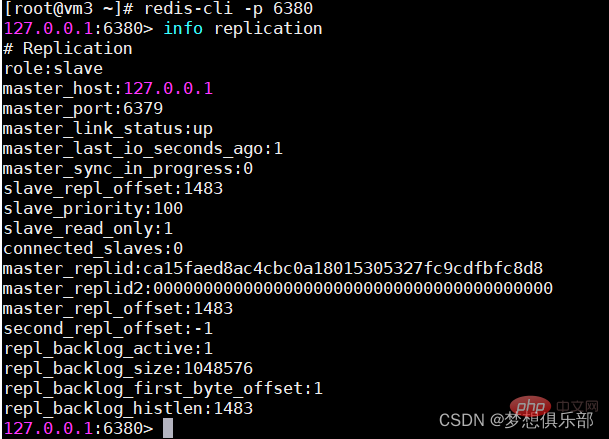
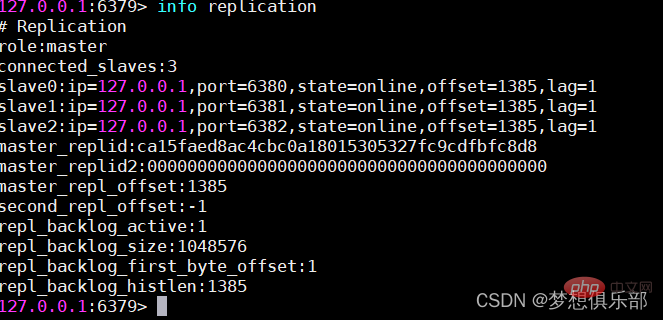
Tuan boleh menyegerakkan data secara automatik kepada hamba, dan boleh memisahkan bacaan dan penulisan untuk berkongsi tekanan baca tuan
Penyegerakan antara tuan dan hamba dilakukan dengan cara yang tidak menyekat tempoh penyegerakan, pelanggan masih boleh menghantar Pertanyaan atau permintaan kemas kini
2. Kelemahan:
Induk dimatikan Jika data tidak disegerakkan sebelum masa henti, akan berlaku ketidakkonsistenan data selepas menukar IP
Sukar untuk dilakukan. menyokong pengembangan dalam talian, dan kapasiti Redis dihadkan oleh konfigurasi bersendirian
Malah, induk redis Mod hamba sangat mudah dan jarang digunakan dalam persekitaran pengeluaran sebenar Ia tidak disyorkan untuk menggunakan master-. mod hamba dalam persekitaran pengeluaran sebenar untuk menyediakan ketersediaan sistem yang tinggi Sebab mengapa ia tidak disyorkan adalah kerana kekurangannya Dalam data Mod induk-hamba juga tidak stabil apabila volum sangat besar, atau apabila keperluan ketersediaan tinggi daripada sistem adalah tinggi. Walaupun model ini sangat mudah, model ini adalah asas kepada model lain, jadi memahami model ini akan sangat membantu untuk mempelajari model lain.
Memantau sama ada tuan dan hamba berjalan seperti biasa
Apabila tuan gagal, ia secara automatik boleh menukar hamba kepada tuan (kakak meninggal, memilih adik untuk mengambil alih)
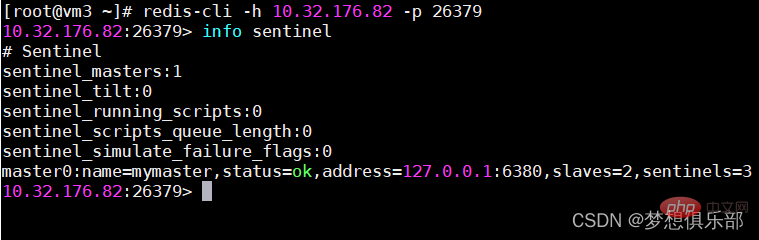
Berbilang sentri boleh memantau Redis yang sama dan sentinel juga akan dipantau secara automatik
Selepas menemui hamba dan nod sentinel lain secara automatik, sentinel boleh memantau dengan kerap sama ada pangkalan data dan nod ini telah menghentikan perkhidmatan dengan menghantar arahan PING dengan kerap.
Jika pangkalan data atau nod sedang PING tamat (dikonfigurasikan oleh sentinel turun-selepas milisaat nama induk milisaat) dan tidak membalas, Sentinel menganggapnya sebagai luar talian secara subjektif (sdown, s bermaksud Subjektif - subjektif). Jika tuan berada di luar talian, pengawal akan menghantar arahan kepada pengawal lain untuk bertanya kepada mereka sama ada mereka juga berpendapat bahawa tuan berada di luar talian secara subjektif Jika bilangan tertentu (iaitu, kuorum dalam fail konfigurasi) undian dicapai, maka sentinel akan menganggap bahawa induk telah berada di luar talian secara objektif (odown , o secara Objektif - secara objektif), dan memilih nod sentinel terkemuka untuk memulakan pemulihan kegagalan untuk sistem induk-hamba. Jika proses sentinel tidak mencukupi untuk bersetuju dengan status luar talian induk, status luar talian objektif induk akan dialih keluar Jika induk mengembalikan balasan yang sah kepada arahan PING yang dihantar ke proses sentinel sekali lagi, status luar talian subjektif induk akan dialih keluar. .
Sentri percaya bahawa selepas tuan berada di luar talian secara objektif, operasi pemulihan kesalahan perlu dilakukan oleh sentinel pemimpin yang dipilih
Selepas pemimpin dipilih, pemimpin mula melakukan pemulihan kesalahan pada sistem , bermula daripada tuan yang gagal Pilih satu daripada pangkalan data untuk memilih tuan baharu,
Selepas memilih hamba yang perlu dijayakan, sentinel terkemuka menghantar arahan kepada pangkalan data untuk menaik tarafnya kepada tuan, kemudian menghantar arahan kepada hamba lain untuk menerima tuan baru, dan akhirnya mengemas kini data. Kemas kini tuan lama yang dihentikan kepada pangkalan data hamba tuan baharu, supaya ia boleh terus berjalan sebagai hamba selepas perkhidmatan dipulihkan. 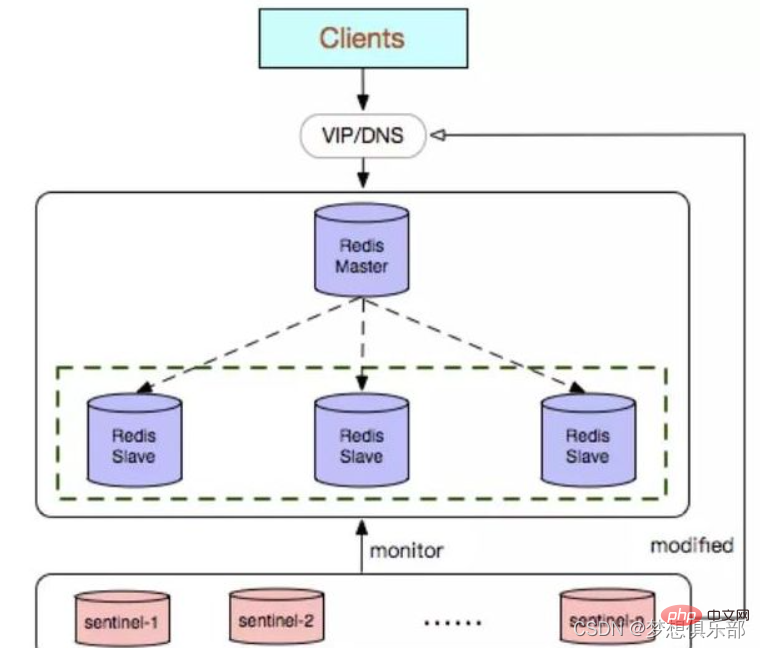
Mod sentinel adalah berdasarkan mod replikasi tuan-hamba sebelumnya. Fail konfigurasi Sentinel ialah sentinel.conf Tambah konfigurasi berikut dalam direktori yang sepadan Berhati-hati agar tidak bercanggah dengan port:
port 26379 protected-mode no daemonize yes pidfile "/var/run/redis-sentinel-26379.pid" logfile "/data/redis/logs/sentinel_26379.log" dir "/data/redis/6379" sentinel monitor mymaster 127.0.0.1 6379 2 ##指定主机IP地址和端口,并且指定当有2台哨兵认为主机挂了,则对主机进行容灾切换 #sentinel auth-pass mymaster pwdtest@2019 ##当在Redis实例中开启了requirepass,这里就需要提供密码 sentinel down-after-milliseconds mymaster 3000 ##这里设置了主机多少秒无响应,则认为挂了 sentinel failover-timeout mymaster 180000 ##故障转移的超时时间,这里设置为三分钟
Formatnya adalah seperti berikut:
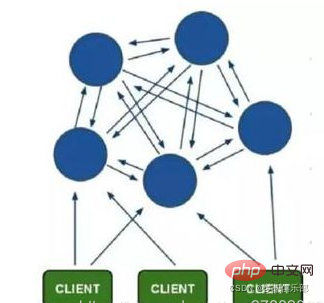
Pelanggan disambungkan terus ke nod redis Pelanggan tidak perlu menyambung ke semua nod dalam gugusan Ia boleh menyambung ke mana-mana nod yang tersedia dalam gugusan
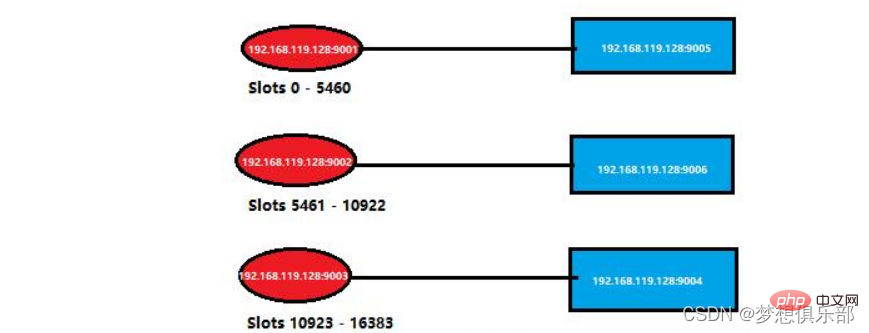
Pada setiap nod Redis Terdapat slot (slot), julat nilai ialah 0-16383, sejumlah 16384 slot
Apabila kita mengakses kekunci, Redis akan dapatkan keputusan berdasarkan algoritma CRC16, dan kemudian bandingkan hasilnya dengan 16384 Cari baki, supaya setiap kunci akan sepadan dengan slot cincang bernombor antara 0-16383 Gunakan nilai ini untuk mencari nod yang sepadan dengan slot yang sepadan, dan kemudian secara automatik melompat ke nod yang sepadan untuk storan.
Untuk meningkatkan kebolehcapaian kluster, penyelesaian yang disyorkan secara rasmi adalah untuk mengkonfigurasi nod ke dalam struktur induk-hamba, iaitu, nod induk dan n nod hamba. Pada masa ini, jika nod induk gagal, Kluster Redis akan memilih salah satu nod hamba untuk dinaikkan ke nod induk berdasarkan algoritma pilihan Raya Keseluruhan kluster akan terus menyediakan perkhidmatan kepada dunia luar Kluster Redis itu sendiri toleransi kesalahan.
Menurut mekanisme pemilihan kluster dan pelaksanaan sandaran tuan-hamba, redis memerlukan sekurang-kurangnya tiga tuan dan tiga hamba secara keseluruhan untuk membentuk kluster redis Persekitaran ujian boleh bermula 6 nod pada satu mesin fizikal nod redis, tetapi sekurang-kurangnya 2 hingga 3 mesin fizikal mesti disediakan untuk persekitaran pengeluaran. (Tiga mesin maya digunakan di sini)
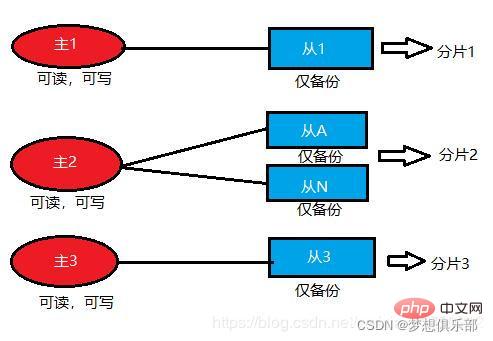
该模式就支持动态扩容,可以在线增加或删除节点,而且客户端可以连接任何一个主节点进行读写,不过此时的从节点仅仅只是备份的作用。至于为何能做到动态扩容,主要是因为Redis集群没有使用一致性hash,而是使用的哈希槽。Redis集群会有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽,而集群的每个节点负责一部分hash槽。
那么这样就很容易添加或者删除节点, 比如如果我想新添加个新节点, 我只需要从已有的节点中的部分槽到过来;如果我想移除某个节点,就只需要将该节点的槽移到其它节点上,然后将没有任何槽的A节点从集群中移除即可。由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
需要注意的是,该模式下不支持同时处理多个key(如MSET/MGET),因为redis需要把key均匀分布在各个节点上,并发量很高的情况下同时创建key-value会降低性能并导致不可预测的行为。
搭建集群
这里就直接搭建较为复杂的Cluster模式集群,也是企业级开发过程中使用最多的。
1.建redis各节点目录
最终目录结构如下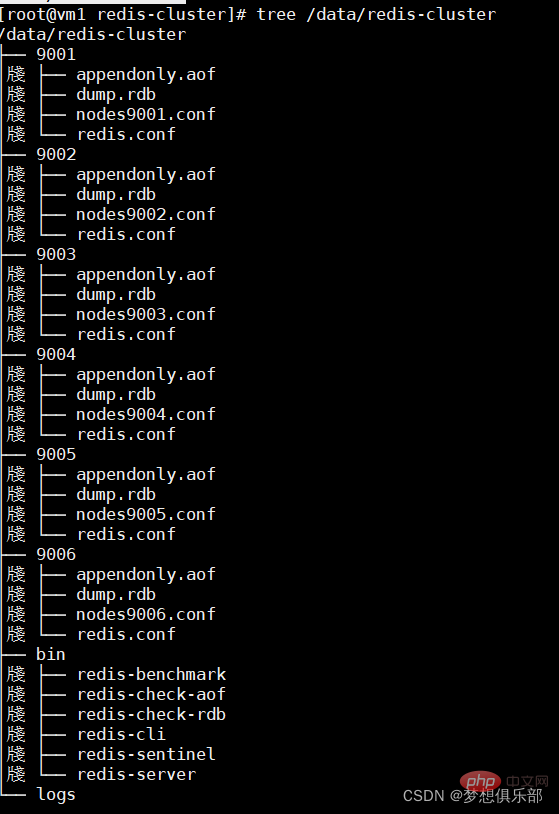
2.逐个修改redis配置
以 9001 的为例子,其余五个类似。
编辑 /data/redis-cluster/9001/redis.conf
redis.conf修改如下:
port 9001(每个节点的端口号) daemonize yes appendonly yes //开启aof bind 0.0.0.0(绑定当前机器 IP) dir "/data/redis-cluster/9001"(数据文件存放位置,,自己加到最后一行 快捷键 shift+g) pidfile /var/run/redis_9001.pid(pid 9001和port要对应) logfile "/data/redis-cluster/logs/9001.log" cluster-enabled yes(启动集群模式) cluster-config-file nodes9001.conf(9001和port要对应) cluster-node-timeout 15000
3.逐个启动redis节点
/data/redis-cluster/bin/redis-server /data/redis-cluster/9001/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9002/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9003/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9004/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9005/redis.conf
/data/redis-cluster/bin/redis-server /data/redis-cluster/9006/redis.conf
现在检查一下是否成功开启,如下图所示,都开启成功。
ps -el | grep redis
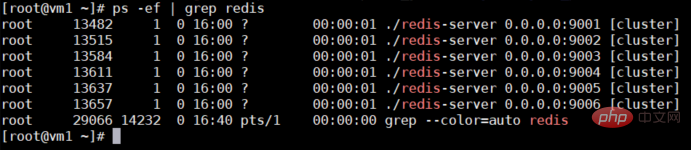
4.集群配置
此时的节点虽然都启动成功了,但他们还不在一个集群里面,不能互相发现,测试会报错:(error) CLUSTERDOWN Hash slot not served。
如下图所示

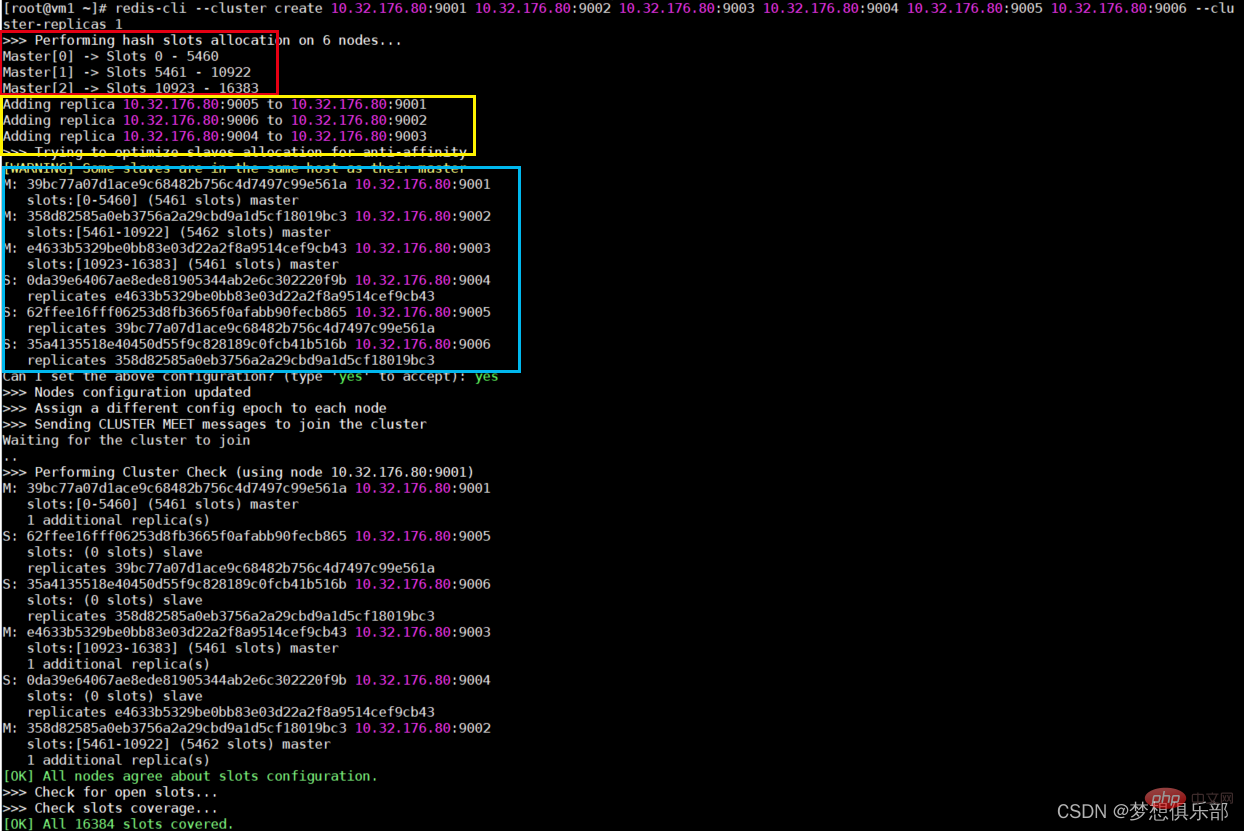
redis-cli --cluster create 10.32.176.80:9001 10.32.176.80:9002 10.32.176.80:9003 10.32.176.80:9004 10.32.176.80:9005 10.32.176.80:9006 --cluster-replicas 1
–cluster-replicas 1 这个指的是从机的数量,表示我们希望为集群中的每个主节点创建一个从节点。
红色选框是给三个主节点分配的共16384个槽点。
黄色选框是主从节点的分配情况。
蓝色选框是各个节点的详情。
5.测试
现在通过客户端命令连接上,通过集群命令看一下状态和节点信息等
/data/redis-cluster/bin/redis-cli -c -h 10.32.176.80 -p 9001 cluster info cluster nodes
效果图如下,集群搭建成功。
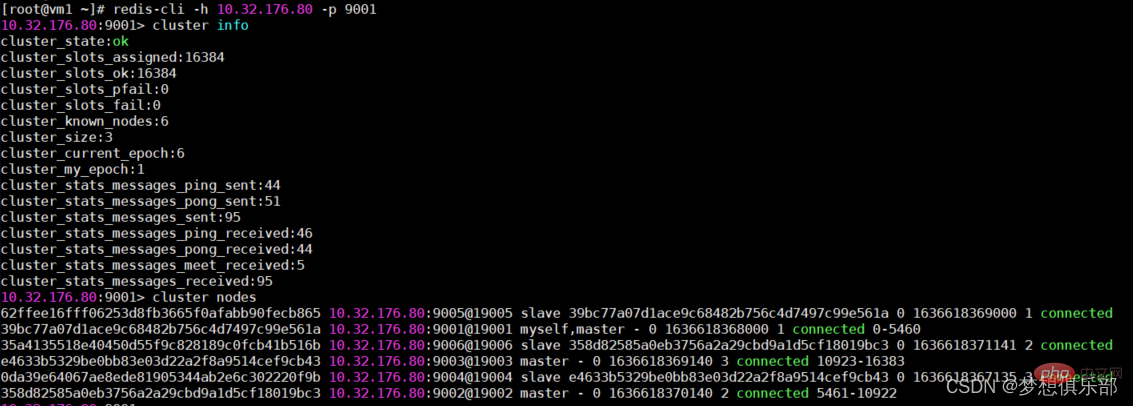
现在往9001这个主节点写入一条信息,我们可以在9002这个主节点取到信息,集群间各个节点可以通信。
6.故障转移
故障转移机制详解
集群中的节点会向其它节点发送PING消息(该PING消息会带着当前集群和节点的信息),如果在规定时间内,没有收到对应的PONG消息,就把此节点标记为疑似下线。当被分配了slot槽位的主节点中有超过一半的节点都认为此节点疑似下线(就是其它节点以更高的频次,更频繁的与该节点PING-PONG),那么该节点就真的下线。其它节点收到某节点已经下线的广播后,把自己内部的集群维护信息也修改为该节点已事实下线。
节点资格审查:然后对从节点进行资格审查,每个从节点检查最后与主节点的断线时间,如果该值超过配置文件的设置,那么取消该从节点的资格。准备选举时间:这里使用了延迟触发机制,主要是给那些延迟低的更高的优先级,延迟低的让它提前参与被选举,延迟高的让它靠后参与被选举。(延迟的高低是依据之前与主节点的最后断线时间确定的)
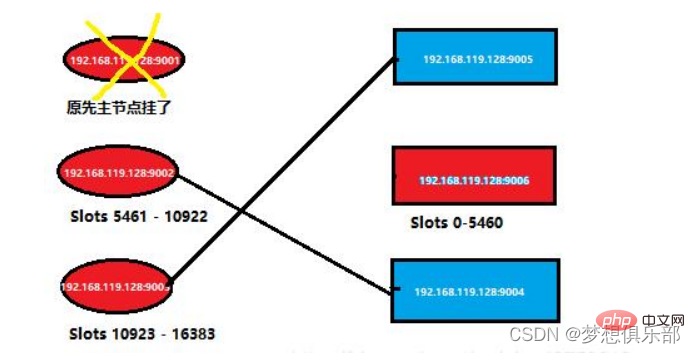
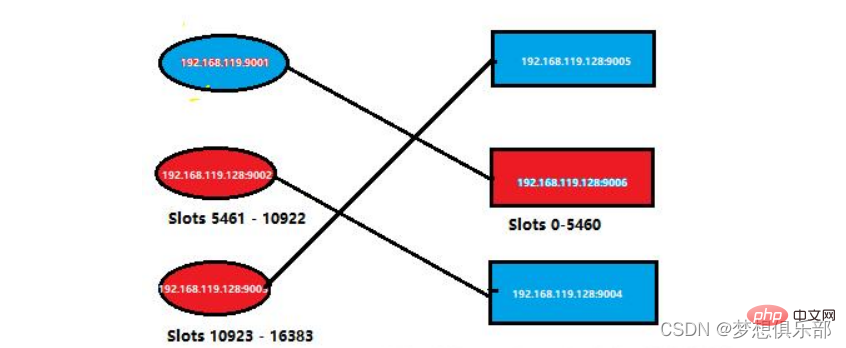
Pengundian pilihan raya: Apabila nod hamba memperoleh kelayakan pilihan raya, ia akan memulakan permintaan pilihan raya kepada nod induk lain dengan slot, dan mereka akan mengundi Lebih tinggi nod hamba keutamaan, lebih besar kemungkinan ia menjadi nod induk Apabila jumlah undian yang diperolehi daripada nod hamba mencapai nilai tertentu (contohnya, jika terdapat N nod induk dalam kelompok, maka selagi satu nod hamba memperoleh N/2 1 undi, ia akan dianggap sebagai pemenang. ), ia akan digantikan sebagai nod induk.
Ganti nod induk: Nod hamba yang dipilih akan melaksanakan tiada hamba untuk menukar statusnya daripada hamba kepada induk, kemudian laksanakan operasi clusterDelSlot untuk membatalkan slot yang bertanggungjawab untuk nod induk yang gagal, dan laksanakan clusterAddSlot untuk memperuntukkan slot ini kepada dirinya sendiri, dan kemudian menyiarkan mesej pongnya sendiri kepada kluster untuk memberitahu semua nod dalam kluster bahawa nod hamba semasa telah menjadi nod induk.
Operasi berkaitan pengambilalihan: Nod induk baharu mengambil alih maklumat slot nod induk yang gagal sebelum ini, menerima dan memproses permintaan arahan yang berkaitan dengan slotnya sendiri.
Ujian Failover
Ini adalah situasi nod tertentu dalam kluster sebelum ini. Anda boleh melihat kembali maklumat kluster dalam gambar .
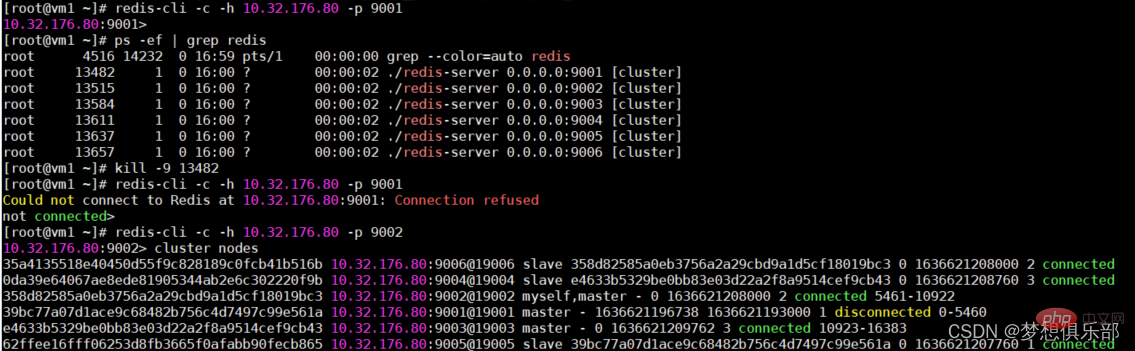
Tutup proses port 9001 di sini, iaitu untuk mensimulasikan bahawa nod induk dimatikan.
Jika anda log masuk ke nod redis mati, anda akan dinafikan perkhidmatan Masuk melalui nod induk yang masih berjalan seperti biasa, dan kemudian semak maklumat dalam kluster sekali lagi


Atas ialah kandungan terperinci Pemahaman mendalam tentang penyelesaian kluster redis (mod master-slave, mod sentinel, mod Kluster Redis). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Analisis terperinci tentang cara mengoptimumkan Redis apabila memori penuh
- Apakah yang perlu saya lakukan jika cache tulis dua kali Redis dan MySQL tidak konsisten? Perkongsian penyelesaian
- Mari analisa mod sentri Redis bersama-sama
- Bagaimana untuk memastikan konsistensi antara cache Redis dan pangkalan data
- Ringkaskan dan susun enam struktur data asas Redis