
Rumah >pangkalan data >Redis >Analisis terperinci tentang cara mengoptimumkan Redis apabila memori penuh
Analisis terperinci tentang cara mengoptimumkan Redis apabila memori penuh

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-03-14 17:09:273584semak imbas
Artikel ini membawakan anda pengetahuan yang berkaitan tentang Redis Ia terutamanya memperkenalkan isu berkaitan cara mengoptimumkan redis apabila memori penuh Ia juga termasuk mekanisme penyingkiran, algoritma LRU dan penyingkiran data , saya harap ia akan membantu semua orang.

Pembelajaran yang disyorkan: Tutorial pembelajaran Redis
Apakah yang perlu saya lakukan jika memori Redis penuh? Bagaimana untuk mengoptimumkan memori?
Terdapat 20 juta data dalam MySQL, tetapi hanya 200,000 data disimpan dalam redis Bagaimana untuk memastikan bahawa data dalam redis adalah data panas
Apabila saiz set data memori redis meningkat. kepada saiz tertentu, ia akan Melaksanakan strategi penghapusan data.
Apakah sumber fizikal yang digunakan terutamanya oleh Redis?
Memori.
Apa yang berlaku apabila Redis kehabisan ingatan?
Jika had atas yang ditetapkan dicapai, arahan tulis Redis akan mengembalikan mesej ralat (tetapi arahan baca masih boleh kembali seperti biasa.) Atau anda boleh mengkonfigurasi mekanisme penghapusan memori, dan apabila Redis mencapai memori atas had, kandungan lama akan disiram .
Bercakap tentang mekanisme penghapusan data cache
Apakah strategi penghapusan untuk cache Redis?
- Satu-satunya strategi yang tidak menghapuskan data ialah noeviction.
Terdapat 7 strategi untuk penyingkiran Kita boleh membahagikannya lagi kepada dua kategori mengikut skop set data calon penyingkiran:
- Dalam kes data dengan masa tamat tempoh ditetapkan Untuk penghapusan, terdapat empat jenis: rawak meruap, ttl meruap, lru meruap dan lfu meruap.
- Hapuskan dalam semua julat data, termasuk allkeys-lru, allkeys-random dan allkeys-lfu.
| 策略 | 规则 |
|---|---|
| volatile-ttl | 在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。 |
| volatile-random | 在设置了过期时间的键值对中,进行随机删除。 |
| volatile-lru | 使用 LRU 算法筛选设置了过期时间的键值对 |
| volatile-lfu | 使用 LFU 算法选择设置了过期时间的键值对 |
| 策略 | 规则 |
|---|---|
| allkeys-random | 从所有键值对中随机选择并删除数据; |
| allkeys-lru | 使用 LRU 算法在所有数据中进行筛选 |
| vallkeys-lfu | 使用 LFU 算法在所有数据中进行筛选 |
Mari kita bincangkan tentang algoritma LRU
adalah untuk menapis data mengikut prinsip yang paling kurang digunakan baru-baru ini Data yang paling jarang digunakan akan ditapis keluar, manakala data yang kerap digunakan baru-baru ini akan kekal dalam cache.
Bagaimana sebenarnya anda ditayangkan? LRU akan menyusun semua data ke dalam senarai terpaut Kepala dan ekor senarai terpaut masing-masing mewakili penghujung MRU dan penghujung LRU, mewakili data yang paling baru digunakan dan data yang paling jarang digunakan. 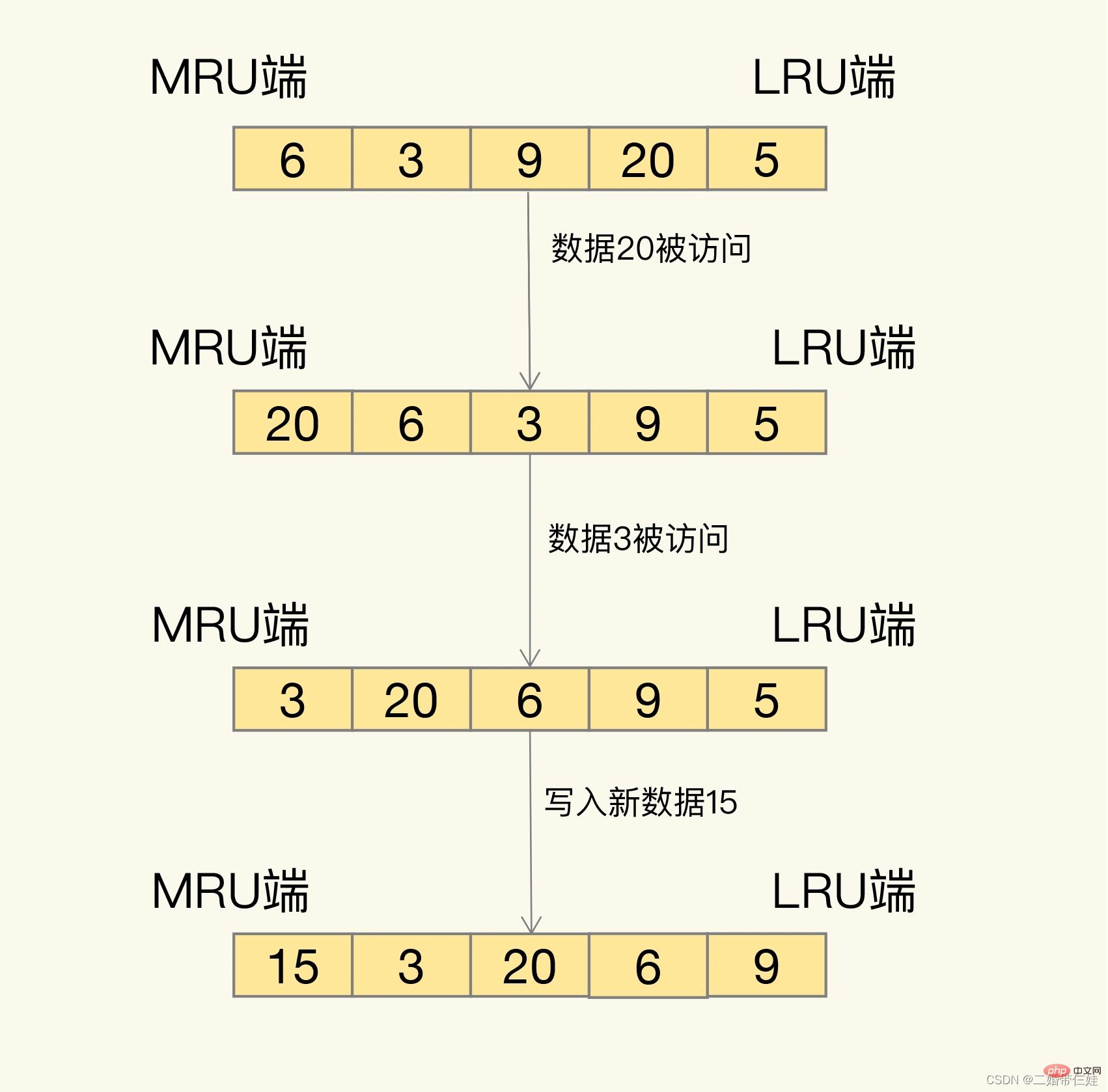
Idea di sebalik algoritma LRU adalah sangat mudah: ia percaya bahawa data yang baru diakses pasti akan diakses semula, jadi ia diletakkan di sebelah MRU data yang belum diakses untuk masa yang lama pasti tidak akan diakses lagi, jadi biarkan ia beransur-ansur kembali ke bahagian LRU Apabila cache penuh, padamkannya terlebih dahulu.
Masalah: Dalam pelaksanaan sebenar, algoritma LRU perlu menggunakan senarai terpaut untuk mengurus semua data cache, yang akan membawa ruang tambahan di atas kepala. Selain itu, apabila data diakses, data perlu dialihkan ke MRU pada senarai terpaut Jika sejumlah besar data diakses, banyak operasi pemindahan senarai terpaut akan berlaku, yang akan memakan masa yang lama dan mengurangkan prestasi cache Redis. .
Penyelesaian:
Dalam Redis, algoritma LRU telah dipermudahkan untuk mengurangkan kesan pengalihan data pada prestasi cache. Khususnya, Redis merekodkan cap waktu akses terkini bagi setiap data secara lalai (dirakam oleh medan lru dalam struktur data pasangan nilai kunci RedisObject). Kemudian, apabila Redis menentukan data untuk dihapuskan, ia akan memilih N keping data secara rawak untuk kali pertama dan menggunakannya sebagai set calon. Seterusnya, Redis akan membandingkan medan lru bagi data N ini dan menghapuskan data dengan nilai medan lru terkecil daripada cache.
Apabila data perlu dihapuskan semula, Redis perlu memilih data ke dalam set calon yang dibuat semasa penyingkiran pertama. Kriteria pemilihan di sini ialah: nilai medan lru bagi data yang boleh memasuki set calon mestilah kurang daripada nilai lru terkecil dalam set calon. Apabila data baharu memasuki set data calon, jika bilangan data dalam set data calon mencapai sampel memori maksimum, Redis akan menghapuskan data dengan nilai medan lru terkecil dalam set data calon.
Cadangan penggunaan:
- Gunakan strategi allkeys-lru dahulu. Dengan cara ini, anda boleh menggunakan sepenuhnya kelebihan LRU, algoritma caching klasik, untuk menyimpan data yang paling terkini diakses dalam cache dan meningkatkan prestasi capaian aplikasi. Jika terdapat perbezaan yang jelas antara data panas dan sejuk dalam data perniagaan anda, saya syorkan anda menggunakan strategi allkeys-lru.
- Jika kekerapan capaian data dalam aplikasi perniagaan tidak jauh berbeza dan tiada perbezaan yang jelas antara data panas dan sejuk, adalah disyorkan untuk menggunakan strategi rawak kekunci semua dan memilih data yang dihapuskan secara rawak.
- Jika terdapat keperluan untuk data yang disematkan dalam perniagaan anda, seperti berita yang disematkan dan video yang disematkan, maka anda boleh menggunakan strategi volatile-lru dan tidak menetapkan masa tamat tempoh untuk data yang disematkan ini. Dengan cara ini, data yang perlu disematkan tidak akan dipadamkan dan data lain akan ditapis mengikut peraturan LRU apabila ia tamat tempoh.
Bagaimana untuk menangani data yang dihapuskan?
Setelah data yang dihapuskan dipilih, jika data adalah data bersih, maka kami akan memadamkannya secara langsung jika data itu adalah data kotor, kami perlu menulisnya semula ke pangkalan data.
Kemudian bagaimana untuk menilai sama ada sekeping data itu bersih atau kotor?
- Perbezaan antara data bersih dan data kotor ialah sama ada ia telah diubah suai berbanding nilai apabila ia dibaca pada asalnya daripada pangkalan data bahagian belakang. Data bersih belum diubah suai, jadi data dalam pangkalan data bahagian belakang juga merupakan nilai terkini. Apabila menggantikan, ia boleh dipadamkan terus.
- Data kotor ialah data yang telah diubah suai dan tidak lagi konsisten dengan data yang disimpan dalam pangkalan data bahagian belakang. Pada masa ini, jika data kotor tidak ditulis kembali ke pangkalan data, nilai terkini data ini akan hilang, yang akan menjejaskan penggunaan biasa aplikasi.
Walaupun data yang dihapuskan adalah data kotor, Redis tidak akan menulisnya kembali ke pangkalan data. Oleh itu, apabila kita menggunakan cache Redis, jika data diubah suai, ia perlu ditulis semula ke pangkalan data apabila data diubah suai. Jika tidak, apabila data kotor dihapuskan, ia akan dipadamkan oleh Redis, dan tidak akan ada data terkini dalam pangkalan data.
Bagaimana Redis mengoptimumkan memori?
1. Kawal bilangan kunci: Apabila menggunakan Redis untuk menyimpan sejumlah besar data, biasanya terdapat sejumlah besar kunci, dan terlalu banyak kunci juga akan menggunakan banyak memori. Redis pada asasnya ialah pelayan struktur data, yang memberikan kami pelbagai struktur data, seperti cincang, senarai, set, zset dan struktur lain. Jangan berlaku salah faham apabila menggunakan Redis Gunakan API seperti dapatkan/set secara meluas dan gunakan Redis sebagai Memcached. Untuk menyimpan kandungan data yang sama, menggunakan struktur data Redis untuk mengurangkan bilangan kunci luar juga boleh menjimatkan banyak memori.
2. Kurangkan objek nilai kunci Cara paling langsung untuk mengurangkan penggunaan memori Redis ialah mengurangkan panjang kunci dan nilai.
- Panjang kunci: Apabila mereka bentuk kunci, apabila perniagaan diterangkan sepenuhnya, lebih pendek nilai kunci, lebih baik.
- Panjang nilai: Pengurangan objek nilai adalah lebih rumit. Pertama sekali, objek perniagaan harus diperkemas dan atribut yang tidak perlu harus dialih keluar untuk mengelakkan penyimpanan data tidak sah. Kedua, dari segi pemilihan alat bersiri, alat bersiri yang lebih cekap harus dipilih untuk mengurangkan saiz tatasusunan bait.
3. Redis menyediakan jenis luaran seperti rentetan, senarai, cincang, set, zet, dll., tetapi Redis secara dalaman mempunyai konsep pengekodan untuk jenis yang berbeza Pengekodan yang dipanggil merujuk kepada struktur data asas khusus yang digunakan untuk pelaksanaan. Pengekodan yang berbeza secara langsung akan menjejaskan penggunaan memori dan kecekapan membaca dan menulis data.
- 1. objek redisObject
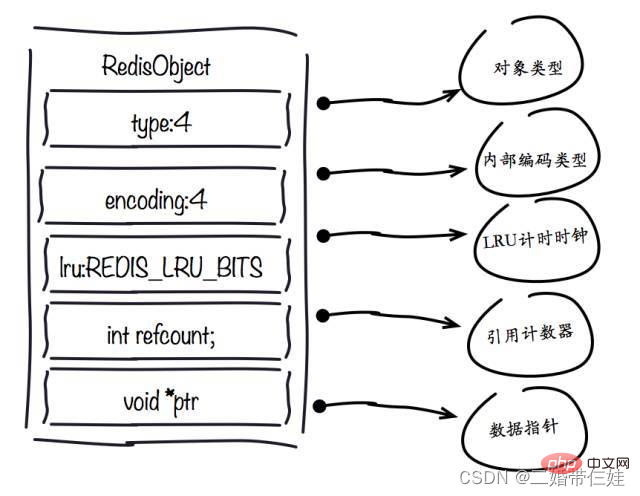
medan jenis:
Gunakan data jenis pengumpulan , kerana biasanya banyak Nilai-Kekunci kecil boleh disimpan bersama dengan cara yang lebih padat. Gunakan cincangan sebanyak mungkin. Contohnya, jika anda mempunyai objek pengguna dalam sistem web anda, jangan tetapkan kunci berasingan untuk nama pengguna, nama keluarga, e-mel dan kata laluan, sebaliknya, simpan semua maklumat pengguna dalam jadual cincang.
medan pengekodan:
Terdapat perbezaan jelas dalam penggunaan memori menggunakan pengekodan yang berbeza
medan lru:
medan pengiraan semula:Apabila objek ialah integer dan julatnya ialah [0-9999], Redis boleh menggunakan objek kongsi untuk menyimpan memori.
:Petua pembangunan: Dalam senario penulisan serentak tinggi, adalah disyorkan agar panjang rentetan dikawal dalam 39 bait jika keadaan membenarkan , mengurangkan bilangan peruntukan memori untuk mencipta redisObject dan meningkatkan prestasi.
2. Kurangkan objek nilai kunci
- Cara paling langsung untuk mengurangkan penggunaan memori Redis ialah mengurangkan panjang kunci dan nilai.
-
Anda boleh menggunakan algoritma pemampatan umum untuk memampatkan json dan xml sebelum menyimpannya dalam Redis, dengan itu mengurangkan penggunaan memori
3 pool
- Kumpulan kongsi objek merujuk kepada kumpulan objek integer [0-9999] yang diselenggara secara dalaman oleh Redis. Mencipta sejumlah besar jenis integer redisObjects melibatkan overhed memori Struktur dalaman setiap redisObject menduduki sekurang-kurangnya 16 bait, malah melebihi penggunaan ruang integer itu sendiri. Oleh itu, memori Redis mengekalkan kumpulan objek integer [0-9999] untuk menyimpan memori. Selain objek nilai integer, jenis lain seperti senarai, cincang, set dan elemen dalaman zset juga boleh menggunakan kumpulan objek integer.
- Oleh itu, dalam pembangunan, atas premis memenuhi keperluan, cuba gunakan objek integer untuk menjimatkan memori.
Apabila maxmemory ditetapkan dan strategi penghapusan berkaitan LRU didayakan seperti: volatile-lru, allkeys-lru, Redis melarang penggunaan kumpulan objek kongsi.
Algoritma LRU perlu mendapatkan masa akses terakhir objek untuk menghapuskan data terpanjang tidak diakses, setiap Masa capaian terakhir objek disimpan dalam medan lru objek redisObject. Perkongsian objek bermakna berbilang rujukan berkongsi redisObject yang sama Pada masa ini, medan lru juga akan dikongsi, menjadikannya mustahil untuk mendapatkan masa akses terakhir setiap objek. Jika maxmemory tidak ditetapkan, Redis tidak akan mencetuskan kitar semula memori sehingga memori habis, jadi kumpulan objek kongsi boleh berfungsi seperti biasa. Ringkasnya, kumpulan objek kongsi bercanggah dengan strategi maxmemory LRU, jadi anda perlu memberi perhatian apabila menggunakannya.
Pertama sekali, kumpulan objek integer mempunyai kebarangkalian tertinggi untuk digunakan semula. Kedua, operasi utama perkongsian objek adalah untuk menilai kesamaan Sebab mengapa Redis hanya mempunyai kumpulan objek integer adalah kerana kerumitan masa algoritma perbandingan integer ialah O(1). Jika kesamaan rentetan dinilai, kerumitan masa menjadi O(n), terutamanya rentetan panjang menggunakan lebih banyak prestasi (nombor titik terapung disimpan secara dalaman dalam Redis menggunakan rentetan). Untuk struktur data yang lebih kompleks seperti cincang, senarai, dsb., pertimbangan kesamaan memerlukan O(n2). Untuk Redis satu benang, overhed sedemikian jelas tidak munasabah, jadi Redis hanya mengekalkan kumpulan objek kongsi integer.
4. Pengoptimuman rentetan
- Redis tidak menggunakan jenis rentetan bahasa C asli tetapi melaksanakan struktur rentetannya sendiri, dengan rentetan dinamik ringkas dalaman, dirujuk sebagai SDS.
:
Ciri:- O(1) pemerolehan kerumitan masa: panjang rentetan, panjang terpakai, Panjang tidak digunakan.
- Boleh digunakan untuk menyimpan tatasusunan bait, menyokong storan data binari yang selamat.
Secara dalaman melaksanakan mekanisme pra-peruntukan ruang untuk mengurangkan bilangan pengagihan semula memori.
Mekanisme pemadaman malas, ruang selepas pengurangan rentetan tidak dilepaskan dan dikhaskan sebagai ruang pra-peruntukan.
: Pembinaan semula rentetan: Kaedah pengekodan kedua berdasarkan jenis cincang. Apabila Redis kehabisan memori, pertimbangan pertama adalah untuk tidak menambah mesin untuk pengembangan mendatar Anda harus cuba mengoptimumkan memori terlebih dahulu. Apabila anda menghadapi kesesakan, pertimbangkan pengembangan mendatar. Malah untuk penyelesaian pengelompokan, pengoptimuman tahap menegak adalah sama penting untuk mengelakkan pembaziran sumber dan kos pengurusan yang tidak perlu selepas pengelompokan. Pembelajaran yang disyorkan: Tutorial Redis
Panjang ID yang digunakan dalam kaedah pengekodan sekunder adalah khusus.
Ia melibatkan masalah – apabila struktur asas jenis Hash kurang daripada nilai yang ditetapkan, senarai termampat digunakan dan apabila lebih besar daripada nilai yang ditetapkan, jadual cincang digunakan.
Setelah ditukar daripada senarai dimampatkan kepada jadual cincang, jenis Cincang akan sentiasa disimpan dalam jadual cincang dan tidak akan ditukar kembali kepada senarai dimampatkan.
Dari segi penjimatan ruang memori, jadual cincang tidak secekap senarai termampat. Untuk menggunakan sepenuhnya susun atur memori padat senarai dimampatkan, secara amnya adalah perlu untuk mengawal bilangan elemen yang disimpan dalam Hash.
Jenis cincang yang dikodkan oleh senarai zip masih menyimpan banyak memori daripada set yang dikodkan oleh jadual cincang.
Petua Pembangunan: Selepas menggunakan cincang senarai zip untuk mengoptimumkan kunci, jika anda ingin menggunakan pemadaman tamat masa fungsi, pembangun boleh Menyimpan masa menulis setiap objek, dan kemudian menggunakan arahan hscan untuk mengimbas data melalui tugas yang dijadualkan untuk mencari item data tamat masa dalam cincang dan memadamnya.
Atas ialah kandungan terperinci Analisis terperinci tentang cara mengoptimumkan Redis apabila memori penuh. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Mari kita bincangkan tentang 5 jenis data dalam Redis dan lihat cara ia boleh digunakan!
- Fahami secara ringkas pelaksanaan algoritma penghapusan cache LRU Redis
- Penjelasan terperinci tentang prinsip kegigihan pembelajaran mendalam Redis
- Penjelasan terperinci tentang teknik klasik Redis: Makefile
- Penjelasan terperinci tentang prinsip kegigihan teknik klasik Redis