
Rumah >pangkalan data >Redis >Penjelasan terperinci tentang prinsip kegigihan pembelajaran mendalam Redis
Penjelasan terperinci tentang prinsip kegigihan pembelajaran mendalam Redis

- 青灯夜游ke hadapan
- 2022-03-10 10:54:512509semak imbas
Artikel ini akan membawa anda untuk mengetahui lebih lanjut tentang Redis, menganalisis kegigihan secara terperinci, memperkenalkan prinsip kerjanya, proses kegigihan, dll. Saya harap ia akan membantu anda!
Artikel ini akan memperkenalkan mekanisme kegigihan Redis dari aspek berikut:
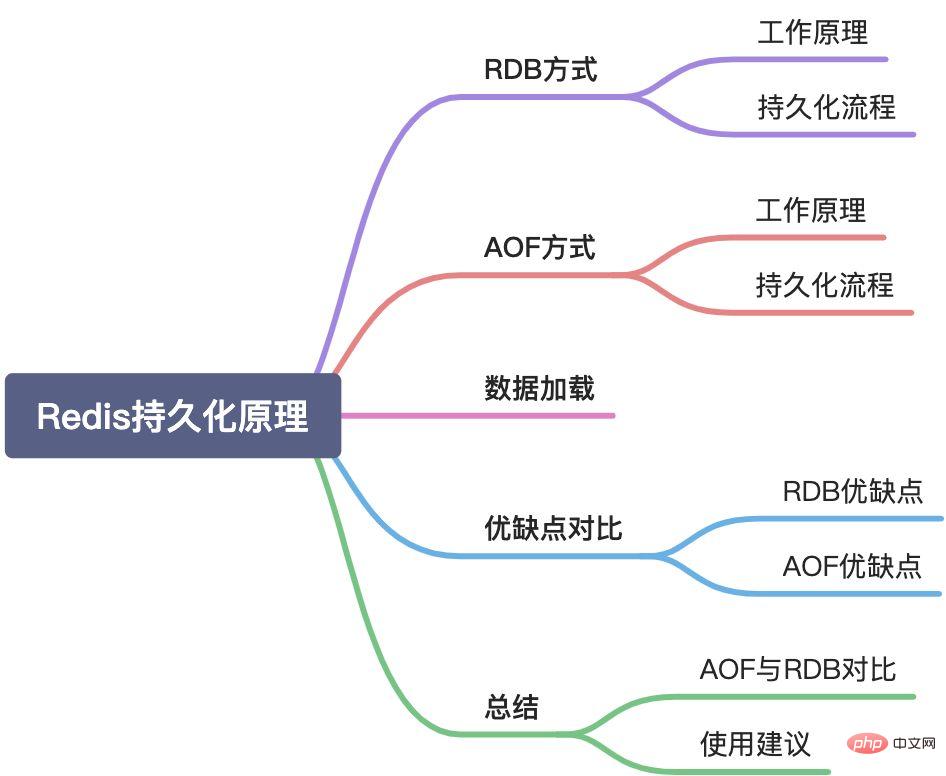 ## Ditulis di hadapan
## Ditulis di hadapan
Artikel ini diperincikan sebagai keseluruhan Memperkenalkan dua kaedah kegigihan Redis, termasuk prinsip kerja, proses kegigihan dan strategi praktikal, serta beberapa pengetahuan teori di belakangnya. Artikel sebelumnya hanya memperkenalkan kegigihan RDB, tetapi kegigihan Redis adalah keseluruhan dan tidak boleh diperkenalkan secara berasingan, jadi ia telah disusun semula. [Cadangan berkaitan: Tutorial video Redis]
Redis ialah pangkalan data dalam memori Semua data akan disimpan dalam ingatan Ini secara langsung berbeza daripada pangkalan data hubungan tradisional seperti MySQL, Oracle. dan SqlServer Berbanding dengan menyimpan data ke cakera keras, kecekapan membaca dan menulis Redis adalah sangat tinggi. Walau bagaimanapun, penjimatan dalam ingatan juga mempunyai kelemahan besar Setelah kuasa terputus atau komputer terputus, semua kandungan dalam pangkalan data memori akan hilang. Untuk mengimbangi kekurangan ini, Redis menyediakan fungsi menyimpan data memori kepada fail cakera keras dan memulihkan data melalui fail sandaran, yang merupakan mekanisme kegigihan Redis.
Redis menyokong dua kaedah kegigihan: petikan RDB dan AOF.
Kegigihan RDB
Petikan RDB Dalam perkataan rasmi: Penyelesaian kegigihan RDB ialah petikan titik ke masa yang dijana daripada set data anda pada selang masa yang ditentukan. Ia menyimpan petikan memori semua objek data dalam pangkalan data Redis pada masa tertentu dalam fail binari termampat, yang boleh digunakan untuk sandaran, pemindahan dan pemulihan data Redis. Setakat ini, ia masih merupakan penyelesaian sokongan lalai rasmi.
Cara RDB berfungsi
Memandangkan RDB ialah petikan titik dalam masa bagi set data dalam Redis, mari kita fahami secara ringkas bagaimana objek data dalam Redis disimpan dan disusun dalam ingatan.
Secara lalai, terdapat 16 pangkalan data dalam Redis, bernombor dari 0-15 Setiap pangkalan data Redis diwakili oleh objek redisDb dan redisDb menggunakan hashtable untuk menyimpan objek K-V. Untuk memudahkan pemahaman, saya mengambil salah satu dbs sebagai contoh untuk melukis gambar rajah skema struktur penyimpanan data dalaman Redis.

Petikan titik dalam masa ialah status setiap objek data dalam setiap DB dalam Redis pada masa tertentu Anggapkan bahawa pada masa ini semua Jika objek data tidak lagi berubah , kita boleh membaca objek data ini dalam urutan dan menulisnya ke fail mengikut hubungan struktur data dalam rajah di atas untuk mencapai kegigihan Redis. Kemudian, apabila Redis dimulakan semula, kandungan fail ini dibaca mengikut peraturan, dan kemudian ditulis ke memori Redis untuk memulihkan kepada keadaan kegigihan.
Sudah tentu, premis ini benar apabila andaian kami di atas adalah benar, jika tidak, kami tidak akan mempunyai cara untuk bermula dalam menghadapi set data yang berubah sepanjang masa. Kami tahu bahawa pemprosesan arahan klien dalam Redis ialah model berbenang tunggal Jika kegigihan diproses sebagai arahan, set data pasti akan berada dalam keadaan statik. Di samping itu, proses anak yang dicipta oleh fungsi fork() yang disediakan oleh sistem pengendalian boleh mendapatkan data memori yang sama seperti proses induk, yang bersamaan dengan mendapatkan salinan data memori selepas garpu selesai, apakah yang perlu; proses ibu bapa lakukan, dan kerja-kerja berterusan negeri diserahkan sahaja kepada proses anak.
Jelas sekali, situasi pertama tidak digalakkan untuk membuat sandaran berterusan akan menyebabkan perkhidmatan Redis tidak tersedia untuk jangka masa yang singkat, yang tidak boleh diterima untuk sistem HA tinggi. Oleh itu, kaedah kedua ialah kaedah praktikal utama kegigihan RDB. Memandangkan data proses induk terus berubah selepas menghentikan proses anak, dan proses anak tidak disegerakkan dengan proses induk, kegigihan RDB tidak dapat menjamin prestasi masa nyata terputus bekalan elektrik atau masa mati selepas kegigihan RDB selesai kehilangan beberapa data; Kekerapan menentukan jumlah data yang hilang. Meningkatkan kekerapan sandaran bermakna proses fork menggunakan lebih banyak sumber CPU dan juga akan membawa kepada I/O cakera yang lebih besar.
Proses kegigihan
Terdapat dua kaedah untuk melengkapkan kegigihan RDB dalam Redis: rdbSave dan rdbSaveBackground (dalam fail kod sumber rdb.c. Mari kita bincangkan secara ringkas tentang perbezaan antara keduanya:
- rdbSave: Ia dilaksanakan secara serentak Proses kegigihan akan dimulakan serta-merta selepas kaedah dipanggil. Memandangkan Redis ialah model berutas tunggal, ia akan disekat semasa proses kegigihan, dan Redis tidak dapat menyediakan perkhidmatan luaran;
- rdbSaveBackground: dilaksanakan di latar belakang (secara tidak segerak). . Proses kegigihan sebenar adalah Apabila dilaksanakan dalam proses anak (memanggil rdbSave), proses utama akan terus menyediakan perkhidmatan
Pencetusan kegigihan RDB mesti tidak dapat dipisahkan daripada dua kaedah di atas kaedah mencetuskan terbahagi kepada manual dan automatik. Pencetusan manual mudah difahami Ini bermakna kami memulakan arahan sandaran kegigihan secara manual ke pelayan Redis melalui klien Redis, dan kemudian pelayan Redis mula melaksanakan proses kegigihan Arahan di sini termasuk simpan dan bgsave. Pencetusan automatik ialah proses kegigihan yang dicetuskan Redis secara automatik apabila syarat pratetap dipenuhi berdasarkan keperluan pengendaliannya sendiri Senario yang dicetuskan secara automatik adalah seperti berikut (dipetik daripada artikel ini):
- serverCron
save m nKonfigurasi. peraturan dicetuskan secara automatik; - Apabila nod hamba disalin sepenuhnya, nod induk menghantar fail rdb ke nod hamba untuk menyelesaikan operasi penyalinan, dan nod induk akan memulakan bgsave
- Jalankan perintah
debug reloaduntuk memuatkan semula masa; - Secara lalai (AOF tidak didayakan), bgsave dilaksanakan secara automatik apabila arahan tutup dilaksanakan
Menggabungkan kod sumber dan artikel rujukan, saya telah menyusun proses kegigihan RDB untuk membantu semua orang Mempunyai pemahaman keseluruhan, dan kemudian menerangkannya dalam beberapa butiran. 
Seperti yang anda lihat daripada gambar di atas:
- Kegigihan RDB yang dicetuskan secara automatik ialah strategi kegigihan yang dilaksanakan dalam sub-proses melalui rdbSaveBackground ;
- Pencetusan manual dicetuskan oleh arahan klien, termasuk perintah save dan bgsave Arahan save diselesaikan dengan memanggil kaedah
rdbSavesecara menyekat dalam urutan pemprosesan arahan Redis.
Proses pencetus automatik ialah pautan lengkap, meliputi rdbSaveBackground, rdbSave, dll. Seterusnya, saya akan menggunakan serverCron sebagai contoh untuk menganalisis keseluruhan proses.
simpan peraturan dan semakan
serverCron ialah fungsi berkala dalam Redis, yang dilaksanakan setiap 100 milisaat Salah satu tugasnya ialah menilai situasi semasa berdasarkan peraturan simpan dalam fail konfigurasi . Proses kegigihan automatik diperlukan, dan jika syarat dipenuhi, percubaan akan dibuat untuk memulakan kegigihan. Ketahui tentang pelaksanaan bahagian ini.
Terdapat beberapa medan yang berkaitan dengan kegigihan RDB dalam redisServer Saya mengekstraknya daripada kod dan melihatnya dalam bahasa Cina dan Inggeris:
struct redisServer {
/* 省略其他字段 */
/* RDB persistence */
long long dirty; /* Changes to DB from the last save
* 上次持久化后修改key的次数 */
struct saveparam *saveparams; /* Save points array for RDB,
* 对应配置文件多个save参数 */
int saveparamslen; /* Number of saving points,
* save参数的数量 */
time_t lastsave; /* Unix time of last successful save
* 上次持久化时间*/
/* 省略其他字段 */
}
/* 对应redis.conf中的save参数 */
struct saveparam {
time_t seconds; /* 统计时间范围 */
int changes; /* 数据修改次数 */
};
saveparamssepadan, parameter simpan ialah strategi pencetus untuk Redis mencetuskan sandaran automatik, redis.conf ialah masa statistik (unit: saat) dan seconds ialah bilangan penulisan yang berlaku dalam masa statistik. changes bermaksud: n menulis dalam m saat akan mencetuskan syot kilat, iaitu sandaran. Berbilang kumpulan parameter simpan boleh dikonfigurasikan untuk memenuhi keperluan sandaran di bawah keadaan yang berbeza. Jika anda perlu mematikan dasar sandaran automatik RDB, anda boleh menggunakan save m n. Berikut ialah perihalan beberapa konfigurasi: save ""
# 表示900秒(15分钟)内至少有1个key的值发生变化,则执行 save 900 1 # 表示300秒(5分钟)内至少有1个key的值发生变化,则执行 save 300 10 # 表示60秒(1分钟)内至少有10000个key的值发生变化,则执行 save 60 10000 # 该配置将会关闭RDB方式的持久化 save ""
Kod pengesanan untuk peraturan simpan RDB adalah seperti berikut: serverCron
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/* 省略其他逻辑 */
/* 如果用户请求进行AOF文件重写时,Redis正在执行RDB持久化,Redis会安排在RDB持久化完成后执行AOF文件重写,
* 如果aof_rewrite_scheduled为true,说明需要执行用户的请求 */
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 后台无 saving/rewrite 子进程才会进行,逐个检查每个save规则*/
for (j = 0; j = sp->changes
&& server.unixtime-server.lastsave > sp->seconds
&&(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...", sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
/* 执行bgsave过程 */
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
/* 省略:Trigger an AOF rewrite if needed. */
}
/* 省略其他逻辑 */
}Jika tiada latar belakang RDB kegigihan atau replikasi AOF Semasa menulis proses, serverCron akan menilai sama ada operasi kegigihan perlu dilakukan berdasarkan konfigurasi dan status di atas Asas untuk penghakiman adalah sama ada lastsave dan dirty memenuhi salah satu syarat dalam tatasusunan saveparams. Jika syarat dipadankan, kaedah rdbSaveBackground dipanggil untuk melaksanakan proses kegigihan tak segerak. rdbSaveBackgroundrdbSaveBackground ialah kaedah tambahan untuk kegigihan RDB. .
- Jika pemanggil adalah proses ibu bapa, hentikan proses anak, simpan maklumat proses anak dan kembalikan terus.
- Jika pemanggil ialah proses anak, panggil rdbSave untuk melaksanakan logik kegigihan RDB dan keluar dari proses anak selepas kegigihan selesai.
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
if (hasActiveChildProcess()) return C_ERR;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
// fork子进程
if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) {
int retval;
/* Child 子进程:修改进程标题 */
redisSetProcTitle("redis-rdb-bgsave");
redisSetCpuAffinity(server.bgsave_cpulist);
// 执行rdb持久化
retval = rdbSave(filename,rsi);
if (retval == C_OK) {
sendChildCOWInfo(CHILD_TYPE_RDB, 1, "RDB");
}
// 持久化完成后,退出子进程
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* Parent 父进程:记录fork子进程的时间等信息*/
if (childpid == -1) {
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %ld",(long) childpid);
// 记录子进程开始的时间、类型等。
server.rdb_save_time_start = time(NULL);
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
return C_OK;
}
return C_OK; /* unreached */
}rdbSave ialah kaedah yang benar-benar melakukan kegigihan Ia melibatkan sejumlah besar operasi I/O dan pengiraan semasa pelaksanaan, yang memakan masa dan mengambil banyak CPU model satu benang Redis Proses kegigihan akan terus menduduki sumber benang, menyebabkan Redis tidak dapat menyediakan perkhidmatan lain. Untuk menyelesaikan masalah ini, Redis menghentikan proses anak dalam rdbSaveBackground, dan proses anak menyelesaikan kerja kegigihan, mengelak daripada menduduki terlalu banyak sumber proses induk. Perlu diingat bahawa jika penggunaan memori proses induk terlalu besar, proses garpu akan lebih memakan masa, dan proses induk tidak akan dapat menyediakan perkhidmatan kepada dunia luar semasa ini proses; sebagai tambahan, penggunaan memori komputer perlu dipertimbangkan secara menyeluruh sebelum memotong proses kanak-kanak Ia akan menduduki dua kali ganda sumber memori, jadi anda perlu memastikan bahawa memori adalah mencukupi. Semak pilihan latest_fork_usec melalui arahan statistik info untuk mendapatkan masa yang diambil untuk operasi fork terkini.
rdbSave
Redis的rdbSave函数是真正进行RDB持久化的函数,流程、细节贼多,整体流程可以总结为:创建并打开临时文件、Redis内存数据写入临时文件、临时文件写入磁盘、临时文件重命名为正式RDB文件、更新持久化状态信息(dirty、lastsave)。其中“Redis内存数据写入临时文件”最为核心和复杂,写入过程直接体现了RDB文件的文件格式,本着一图胜千言的理念,我按照源码流程绘制了下图。
补充说明一下,上图右下角“遍历当前数据库的键值对并写入”这个环节会根据不同类型的Redis数据类型及底层数据结构采用不同的格式写入到RDB文件中,不再展开了。我觉得大家对整个过程有个直观的理解就好,这对于我们理解Redis内部的运作机制大有裨益。
AOF持久化
上一节我们知道RDB是一种时间点(point-to-time)快照,适合数据备份及灾难恢复,由于工作原理的“先天性缺陷”无法保证实时性持久化,这对于缓存丢失零容忍的系统来说是个硬伤,于是就有了AOF。
AOF工作原理
AOF是Append Only File的缩写,它是Redis的完全持久化策略,从1.1版本开始支持;这里的file存储的是引起Redis数据修改的命令集合(比如:set/hset/del等),这些集合按照Redis Server的处理顺序追加到文件中。当重启Redis时,Redis就可以从头读取AOF中的指令并重放,进而恢复关闭前的数据状态。
AOF持久化默认是关闭的,修改redis.conf以下信息并重启,即可开启AOF持久化功能。
# no-关闭,yes-开启,默认no appendonly yes appendfilename appendonly.aof
AOF本质是为了持久化,持久化对象是Redis内每一个key的状态,持久化的目的是为了在Reids发生故障重启后能够恢复至重启前或故障前的状态。相比于RDB,AOF采取的策略是按照执行顺序持久化每一条能够引起Redis中对象状态变更的命令,命令是有序的、有选择的。把aof文件转移至任何一台Redis Server,从头到尾按序重放这些命令即可恢复如初。举个例子:
首先执行指令set number 0,然后随机调用incr number、get number 各5次,最后再执行一次get number ,我们得到的结果肯定是5。
因为在这个过程中,能够引起number状态变更的只有set/incr类型的指令,并且它们执行的先后顺序是已知的,无论执行多少次get都不会影响number的状态。所以,保留所有set/incr命令并持久化至aof文件即可。按照aof的设计原理,aof文件中的内容应该是这样的(这里是假设,实际为RESP协议):
set number 0 incr number incr number incr number incr number incr number
最本质的原理用“命令重放”四个字就可以概括。但是,考虑实际生产环境的复杂性及操作系统等方面的限制,Redis所要考虑的工作要比这个例子复杂的多:
- Redis Server启动后,aof文件一直在追加命令,文件会越来越大。文件越大,Redis重启后恢复耗时越久;文件太大,转移工作就越难;不加管理,可能撑爆硬盘。很显然,需要在合适的时机对文件进行精简。例子中的5条incr指令很明显的可以替换为为一条
set命令,存在很大的压缩空间。 - 众所周知,文件I/O是操作系统性能的短板,为了提高效率,文件系统设计了一套复杂的缓存机制,Redis操作命令的追加操作只是把数据写入了缓冲区(aof_buf),从缓冲区到写入物理文件在性能与安全之间权衡会有不同的选择。
- 文件压缩即意味着重写,重写时即可依据已有的aof文件做命令整合,也可以先根据当前Redis内数据的状态做快照,再把存储快照过程中的新增的命令做追加。
- aof备份后的文件是为了恢复数据,结合aof文件的格式、完整性等因素,Redis也要设计一套完整的方案做支持。
持久化流程
从流程上来看,AOF的工作原理可以概括为几个步骤:命令追加(append)、文件写入与同步(fsync)、文件重写(rewrite)、重启加载(load),接下来依次了解每个步骤的细节及背后的设计哲学。
Tambahan Perintah
Apabila fungsi kegigihan AOF dihidupkan, selepas Redis melaksanakan arahan tulis, ia akan ditulis dalam format protokol (iaitu RESP, protokol komunikasi untuk interaksi antara klien dan pelayan Redis ) Tambahkan perintah tulis yang dilaksanakan pada penghujung penimbal AOF yang diselenggara oleh pelayan Redis. Terdapat hanya operasi tambah satu benang untuk fail AOF, dan tiada operasi yang rumit seperti mencari Tiada risiko kerosakan fail walaupun terdapat gangguan bekalan elektrik atau masa mati. Selain itu, terdapat banyak faedah untuk menggunakan protokol teks:
- Protokol teks mempunyai keserasian yang baik; menjimatkan storan dan Memproses overhed semasa memuatkan;
- Protokol teks boleh dibaca dan mudah untuk dilihat, pengubahsuaian, dll.
- Jenis penimbal AOF ialah struktur data yang direka secara bebas oleh Redis
, sds, dsb.) untuk memproses kandungan arahan mengikut arahan. jenis arahan Akhir sekali tulis kepada penimbal. catAppendOnlyGenericCommandcatAppendOnlyExpireAtCommandPerlu diambil perhatian bahawa jika penulisan semula AOF sedang dijalankan apabila arahan dilampirkan, arahan ini juga akan dilampirkan pada penimbal tulis semula (
aof_rewrite_bufferPenulisan dan penyegerakan fail
Penulisan dan penyegerakan fail AOF tidak boleh dipisahkan daripada sokongan sistem pengendalian Sebelum memulakan pengenalan, kita perlu menambah sedikit pengetahuan tentang Linux I/O penampan. Prestasi I/O cakera keras adalah lemah, dan kelajuan membaca dan menulis fail jauh lebih rendah daripada kelajuan pemprosesan CPU Jika anda menunggu data ditulis ke cakera keras setiap kali anda menulis fail, ia akan merendahkan prestasi keseluruhan sistem pengendalian. Untuk menyelesaikan masalah ini, sistem pengendalian menyediakan mekanisme tulis tertunda untuk meningkatkan prestasi I/O cakera keras.
 Pelaksanaan UNIX tradisional mempunyai cache penimbal atau cache halaman dalam kernel, dan kebanyakan I/O cakera dilakukan melalui penimbalan. Apabila menulis data ke fail, kernel biasanya menyalin data ke salah satu penimbal terlebih dahulu Jika penimbal belum penuh, ia tidak beratur ke dalam baris gilir keluaran, tetapi menunggu untuk diisi atau apabila kernel memerlukan. hingga Apabila penimbal digunakan semula untuk menyimpan data blok cakera lain, penimbal akan beratur ke dalam baris gilir keluaran, dan kemudian operasi I/O sebenar dilakukan hanya apabila ia mencapai kepala baris gilir. Kaedah keluaran ini dipanggil penulisan tertunda.
Pelaksanaan UNIX tradisional mempunyai cache penimbal atau cache halaman dalam kernel, dan kebanyakan I/O cakera dilakukan melalui penimbalan. Apabila menulis data ke fail, kernel biasanya menyalin data ke salah satu penimbal terlebih dahulu Jika penimbal belum penuh, ia tidak beratur ke dalam baris gilir keluaran, tetapi menunggu untuk diisi atau apabila kernel memerlukan. hingga Apabila penimbal digunakan semula untuk menyimpan data blok cakera lain, penimbal akan beratur ke dalam baris gilir keluaran, dan kemudian operasi I/O sebenar dilakukan hanya apabila ia mencapai kepala baris gilir. Kaedah keluaran ini dipanggil penulisan tertunda.
Penulisan tertunda mengurangkan bilangan cakera membaca dan menulis, tetapi ia juga mengurangkan kelajuan kemas kini kandungan fail, supaya data yang akan ditulis pada fail tidak ditulis ke cakera untuk tempoh masa. Apabila kegagalan sistem berlaku, kelewatan ini boleh menyebabkan kemas kini fail hilang. Untuk memastikan ketekalan sistem fail sebenar pada cakera dan kandungan dalam cache penimbal, sistem UNIX menyediakan tiga fungsi: penyegerakan, fsync dan fdatasync untuk menyediakan sokongan untuk penulisan paksa pada cakera keras.
Redis akan memanggil fungsi
sebelum setiap putaran acara tamat ( beforeSleep akan menulis data dalam penimbal AOF (flushAppendOnlyFile) ke penimbal kernel, dan mengikut Konfigurasikan untuk memutuskan strategi yang hendak digunakan untuk menulis data dalam penimbal kernel ke cakera, iaitu, panggil flushAppendOnlyFile. Konfigurasi ini mempunyai tiga pilihan aof_buf, appendfsync dan fsync() Penerangan khusus adalah seperti berikut: alwaysnoeverysecsentiasa: Panggil
- no:
fsync()tidak akan dipanggil. Prestasi terbaik, keselamatan paling teruk. - everysec: Dipanggil hanya apabila syarat penyegerakan dipenuhi
fsync(). Ini adalah strategi penyegerakan yang disyorkan secara rasmi dan juga merupakan konfigurasi lalai. Ia mengambil kira prestasi dan keselamatan data Secara teori, hanya 1 saat data akan hilang sekiranya sistem ditutup secara tiba-tiba. fsync()Nota: Strategi yang diperkenalkan di atas dipengaruhi oleh item konfigurasi
no-appendfsync-on-rewriteJika ditetapkan kepada
, appendfsync atau always yang berterusan di latar belakang menggunakan I/O cakera yang berlebihan, di bawah konfigurasi sistem Linux tertentu, Redis's panggilan ke fsync() mungkin menyekat untuk masa yang lama. Walau bagaimanapun, masalah ini masih belum diselesaikan, kerana operasi tulis segerak akan disekat walaupun semasa melaksanakan everysec dalam urutan yang berbeza. BGSAVEBGREWRITEAOFUntuk mengurangkan isu ini, pilihan boleh digunakan untuk menghalang fsync() daripada dipanggil dalam proses utama semasa fsync() atau
- 设置为
yes意味着,如果子进程正在进行BGSAVE或BGREWRITEAOF,AOF的持久化能力就与appendfsync设置为no有着相同的效果。最糟糕的情况下,这可能会导致30秒的缓存数据丢失。 - 如果你的系统有上面描述的延迟问题,就把这个选项设置为
yes,否则保持为no。
文件重写
如前面提到的,Redis长时间运行,命令不断写入AOF,文件会越来越大,不加控制可能影响宿主机的安全。
为了解决AOF文件体积问题,Redis引入了AOF文件重写功能,它会根据Redis内数据对象的最新状态生成新的AOF文件,新旧文件对应的数据状态一致,但是新文件会具有较小的体积。重写既减少了AOF文件对磁盘空间的占用,又可以提高Redis重启时数据恢复的速度。还是下面这个例子,旧文件中的6条命令等同于新文件中的1条命令,压缩效果显而易见。
我们说,AOF文件太大时会触发AOF文件重写,那到底是多大呢?有哪些情况会触发重写操作呢?
**
与RDB方式一样,AOF文件重写既可以手动触发,也会自动触发。手动触发直接调用bgrewriteaof命令,如果当时无子进程执行会立刻执行,否则安排在子进程结束后执行。自动触发由Redis的周期性方法serverCron检查在满足一定条件时触发。先了解两个配置项:
- auto-aof-rewrite-percentage:代表当前AOF文件大小(aof_current_size)和上一次重写后AOF文件大小(aof_base_size)相比,增长的比例。
- auto-aof-rewrite-min-size:表示运行
BGREWRITEAOF时AOF文件占用空间最小值,默认为64MB;
Redis启动时把aof_base_size初始化为当时aof文件的大小,Redis运行过程中,当AOF文件重写操作完成时,会对其进行更新;aof_current_size为serverCron执行时AOF文件的实时大小。当满足以下两个条件时,AOF文件重写就会触发:
增长比例:(aof_current_size - aof_base_size) / aof_base_size > auto-aof-rewrite-percentage 文件大小:aof_current_size > auto-aof-rewrite-min-size
手动触发与自动触发的代码如下,同样在周期性方法serverCron中:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/* 省略其他逻辑 */
/* 如果用户请求进行AOF文件重写时,Redis正在执行RDB持久化,Redis会安排在RDB持久化完成后执行AOF文件重写,
* 如果aof_rewrite_scheduled为true,说明需要执行用户的请求 */
if (!hasActiveChildProcess() &&
server.aof_rewrite_scheduled)
{
rewriteAppendOnlyFileBackground();
}
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 省略rdb持久化条件检查 */
/* AOF重写条件检查:aof开启、无子进程运行、增长百分比已设置、当前文件大小超过阈值 */
if (server.aof_state == AOF_ON &&
!hasActiveChildProcess() &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
/* 计算增长百分比 */
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
}
/**/
}
AOF文件重写的流程是什么?听说Redis支持混合持久化,对AOF文件重写有什么影响?
从4.0版本开始,Redis在AOF模式中引入了混合持久化方案,即:纯AOF方式、RDB+AOF方式,这一策略由配置参数aof-use-rdb-preamble(使用RDB作为AOF文件的前半段)控制,默认关闭(no),设置为yes可开启。所以,在AOF重写过程中文件的写入会有两种不同的方式。当aof-use-rdb-preamble的值是:
- no:按照AOF格式写入命令,与4.0前版本无差别;
- yes:先按照RDB格式写入数据状态,然后把重写期间AOF缓冲区的内容以AOF格式写入,文件前半部分为RDB格式,后半部分为AOF格式。
结合源码(6.0版本,源码太多这里不贴出,可参考aof.c)及参考资料,绘制AOF重写(BGREWRITEAOF)流程图:
结合上图,总结一下AOF文件重写的流程:
- rewriteAppendOnlyFileBackground开始执行,检查是否有正在进行的AOF重写或RDB持久化子进程:如果有,则退出该流程;如果没有,则继续创建接下来父子进程间数据传输的通信管道。执行fork()操作,成功后父子进程分别执行不同的流程。
-
父进程:
- 记录子进程信息(pid)、时间戳等;
- 继续响应其他客户端请求;
- 收集AOF重写期间的命令,追加至aof_rewrite_buffer;
- 等待并向子进程同步aof_rewrite_buffer的内容;
-
子进程:
- Ubah suai nama proses semasa, buat fail sementara yang diperlukan untuk menulis semula, dan panggil fungsi rewriteAppendOnlyFile; dan selaraskan ke cakera keras ;
- Terima perintah AOF tambahan daripada proses induk, tulis separuh kedua dalam mod AOF, dan selaraskannya ke cakera keras; dan proses kanak-kanak keluar.
aof-use-rdb-preamble - Pemuatan data
. Perlu diingatkan di sini bahawa walaupun kaedah kegigihan boleh menjadi AOF, RDB, atau kedua-duanya, pilihan mesti dibuat apabila memuatkan dua kaedah secara berasingan akan menyebabkan huru-hara.
Secara teorinya, kegigihan AOF mempunyai prestasi masa nyata yang lebih baik daripada RDB Apabila kegigihan AOF didayakan, Redis memberi keutamaan kepada AOF semasa memuatkan data. Selain itu, selepas versi Redis 4.0, AOF menyokong kegigihan hibrid, dan keserasian versi perlu dipertimbangkan semasa memuatkan fail AOF. Proses pemuatan data Redis ditunjukkan dalam rajah di bawah:
loadDataFromDisk
Dalam mod AOF, fail yang dijana dengan menghidupkan mekanisme kegigihan hibrid ialah "RDB head AOF tail", yang dijana apabila ia tidak dihidupkan Semua fail dalam format AOF. Memandangkan keserasian dua format fail, jika Redis mendapati bahawa fail AOF ialah pengepala RDB, ia akan menggunakan kaedah pemuatan data RDB untuk membaca dan memulihkan separuh pertama dan kemudian menggunakan kaedah AOF untuk membaca dan memulihkan separuh kedua . Memandangkan data yang disimpan dalam format AOF ialah arahan protokol RESP, Redis menggunakan klien pseudo untuk melaksanakan arahan untuk memulihkan data.
Jika masa henti berlaku semasa proses penambahan arahan AOF, arahan RESP AOF mungkin tidak lengkap (dipotong) disebabkan oleh ciri teknikal penulisan tertunda. Apabila menghadapi situasi ini, Redis akan melaksanakan strategi pemprosesan yang berbeza mengikut item konfigurasi  . Konfigurasi ini memberitahu Redis untuk membaca fail aof semasa memulakan, dan perkara yang perlu dilakukan jika fail didapati dipenggal (tidak lengkap):
. Konfigurasi ini memberitahu Redis untuk membaca fail aof semasa memulakan, dan perkara yang perlu dilakukan jika fail didapati dipenggal (tidak lengkap):
aof-load-truncatedtidak: ia ranap sistem dan dilarang daripada memulakan fail dan kemudian mulakan semula.
- Ringkasan
- Redis menyediakan dua pilihan kegigihan: RDB menyokong penjanaan syot kilat titik dalam masa untuk set data pada selang masa praktikal tertentu AOF menyimpan setiap maklumat yang diterima oleh Redis Pelayan. Perintah tulis diteruskan ke log, dan data boleh dipulihkan dengan memainkan semula arahan apabila Redis dimulakan semula. Format log ialah protokol RESP, dan hanya operasi tambah dijalankan pada fail log, jadi tiada risiko kerosakan. Dan apabila fail AOF terlalu besar, fail yang dimampatkan boleh ditulis semula secara automatik.
RDB vs AOF
Kelebihan RDB
- RDB ialah fail binari padat dan termampat yang mewakili syot kilat data Redis pada masa tertentu Ia sangat sesuai untuk sandaran, Salinan penuh dan senario lain.
- RDB sangat mesra kepada pemulihan bencana dan pemindahan data boleh dialihkan ke mana-mana tempat yang diperlukan dan dimuat semula.
- RDB ialah petikan memori data Redis, dengan pemulihan data yang lebih pantas dan prestasi yang lebih tinggi daripada main semula arahan AOF.
Kelemahan RDB
- Kaedah RDB tidak boleh mencapai ketekunan masa nyata atau tahap kedua. Oleh kerana proses kegigihan diselesaikan oleh proses anak selepas proses anak bercabang, ingatan proses anak hanyalah gambaran data proses induk pada saat operasi garpu Selepas operasi garpu, proses induk diteruskan untuk berkhidmat kepada dunia luar, dan data dalaman berubah sepanjang masa Data tidak lagi dikemas kini, dan sentiasa terdapat perbezaan antara keduanya, jadi prestasi masa nyata tidak dapat dicapai.
- Operasi fork semasa proses kegigihan RDB akan menggandakan penggunaan memori, dan semakin banyak data yang dimiliki oleh proses induk, semakin lama proses fork.
- Keselarasan tinggi permintaan Redis mungkin kerap memukul peraturan simpan, menyebabkan kekerapan operasi fork dan sandaran berterusan menjadi tidak terkawal
- Fail RDB mempunyai keperluan format fail dan versi Redis yang berbeza akan berubah format fail pelarasan dibuat, dan terdapat masalah bahawa versi lama tidak serasi dengan versi baharu.
Kelebihan AOF
- Kegigihan AOF mempunyai prestasi masa nyata yang lebih baik Kita boleh memilih tiga kaedah berbeza (appendfsync): tidak, setiap saat, sentiasa, setiap As the strategi lalai, kedua mempunyai prestasi terbaik Dalam kes yang melampau, satu saat data mungkin hilang.
- Fail AOF hanya mempunyai operasi tambah, tiada carian rumit dan operasi fail lain, dan tiada risiko kerosakan. Walaupun data bertulis terakhir dipotong, ia boleh dibaiki dengan mudah menggunakan alat
redis-check-aof
- Apabila fail AOF menjadi lebih besar, Redis boleh menulis semula secara automatik di latar belakang. Semasa proses penulisan semula, fail lama akan terus ditulis Selepas penulisan semula selesai, fail baharu akan menjadi lebih kecil, dan arahan tambahan semasa proses penulisan semula juga akan dilampirkan pada fail baharu.
- Fail AOF mengandungi semua perintah operasi untuk data dalam Redis dengan cara yang mudah difahami dan dihuraikan. Walaupun semua data secara tidak sengaja dibersihkan secara tidak sengaja, selagi fail AOF tidak ditulis semula, kami boleh mendapatkan semula semua data dengan mengalih keluar arahan terakhir.
- AOF sudah pun menyokong kegigihan hibrid, saiz fail boleh dikawal dengan berkesan, dan kecekapan pemuatan data dipertingkatkan.
Kelemahan AOF
- Untuk pengumpulan data yang sama, fail AOF biasanya lebih besar daripada fail RDB
- Di bawah strategi fsync tertentu, AOF akan Sedikit; lebih perlahan daripada RDB. Secara umumnya, prestasi fsync_every_second masih sangat tinggi, dan prestasi fsync_no adalah setanding dengan RDB. Tetapi di bawah tekanan tulis yang besar, RDB boleh memberikan jaminan kependaman rendah yang paling hebat.
- Di AOF, Redis pernah menemui beberapa pepijat jarang yang hampir mustahil ditemui pada RDB. Beberapa arahan khas (seperti BRPOPLPUSH) menyebabkan data yang dimuat semula tidak konsisten dengan itu sebelum pegawai Redis diuji dalam keadaan yang sama, tetapi masalah itu tidak dapat diterbitkan semula.
Cadangan Penggunaan
redis-check-aof Setelah memahami prinsip kerja, proses pelaksanaan, kelebihan dan keburukan kedua-dua kaedah kegigihan RDB dan AOF, mari kita fikirkan bagaimana untuk menimbang kebaikan dan keburukan dalam senario sebenar, gunakan dua kaedah kegigihan dengan munasabah. Jika anda hanya menggunakan Redis sebagai alat caching, semua data boleh dibina semula berdasarkan pangkalan data berterusan Anda boleh mematikan fungsi kegigihan dan melakukan kerja perlindungan seperti pemanasan awal, penembusan cache, pecahan dan salji.
Dalam keadaan biasa, Redis akan mengambil lebih banyak kerja, seperti kunci yang diedarkan, kedudukan, pusat pendaftaran, dll. Fungsi kegigihan akan memainkan peranan yang lebih besar dalam pemulihan bencana dan pemindahan data. Adalah disyorkan untuk mengikuti beberapa prinsip:
- Jangan gunakan Redis sebagai pangkalan data Semua data boleh dibina semula secara automatik oleh perkhidmatan aplikasi sebanyak mungkin.
- Gunakan versi 4.0 ke atas Redis dan gunakan fungsi kegigihan hibrid AOF RDB.
- Rancang dengan munasabah memori maksimum yang diduduki oleh Redis untuk mengelakkan sumber yang tidak mencukupi semasa AOF menulis semula atau menyimpan.
- Elakkan menggunakan berbilang kejadian pada satu mesin.
- Kebanyakan persekitaran pengeluaran digunakan dalam kelompok Keupayaan kegigihan boleh didayakan pada hamba, membolehkan tuan memberikan perkhidmatan penulisan luaran dengan lebih baik.
- Fail sandaran hendaklah dimuat naik secara automatik ke bilik komputer luar tapak atau storan awan untuk menyediakan sandaran bencana.
Mengenai fork()
Melalui analisis di atas, kita semua tahu bahawa syot kilat RDB dan penulisan semula AOF memerlukan garpu Ini adalah operasi heavyweight dan akan menyebabkan kerosakan pada blok Redis. Oleh itu, untuk tidak menjejaskan tindak balas proses utama Redis, kita perlu mengurangkan penyekatan sebanyak mungkin.
- Kurangkan kekerapan garpu, contohnya, anda boleh mencetuskan RDB secara manual untuk menjana syot kilat dan menulis semula AOF
- Kawal penggunaan memori maksimum Redis untuk mengelakkan garpu mengambil masa terlalu lama; ;
- Gunakan perkakasan berprestasi tinggi;
- Konfigurasikan strategi peruntukan memori Linux dengan betul untuk mengelakkan kegagalan garpu kerana memori fizikal yang tidak mencukupi.
Untuk lebih banyak pengetahuan berkaitan pengaturcaraan, sila lawati: Pengenalan kepada Pengaturcaraan! !
Atas ialah kandungan terperinci Penjelasan terperinci tentang prinsip kegigihan pembelajaran mendalam Redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Apakah yang perlu kita perhatikan semasa melaksanakan kunci teragih dalam Redis? [Ringkasan perkara yang memerlukan perhatian]
- Bawa anda langkah demi langkah untuk memahami kelompok ketersediaan tinggi Redis
- Ringkaskan 10 petua untuk meningkatkan prestasi Redis
- Memberi anda pemahaman yang mendalam tentang kunci yang diedarkan dalam Redis
- Mari bercakap tentang acara fail redis dan peristiwa masa
- Mari kita bincangkan tentang 5 jenis data dalam Redis dan lihat cara ia boleh digunakan!