
Rumah >pangkalan data >Redis >Bawa anda langkah demi langkah untuk memahami kelompok ketersediaan tinggi Redis
Bawa anda langkah demi langkah untuk memahami kelompok ketersediaan tinggi Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2022-03-04 17:03:452714semak imbas
Artikel ini membawakan anda pengetahuan yang berkaitan tentang Redis, yang terutamanya memperkenalkan isu yang berkaitan dengan gugusan Redis ialah penyelesaian pangkalan data yang diedarkan melalui serpihan dan fungsi replikasi semoga ianya bermanfaat kepada semua.

Pembelajaran yang disyorkan: Tutorial pembelajaran Redis
Beberapa penyelesaian ketersediaan tinggi Redis. Termasuk: "Mod Guru-Hamba", "Mekanisme Sentinel" dan "Kluster Sentinel".
- "mod tuan-hamba" mempunyai kelebihan pengasingan membaca dan menulis, berkongsi tekanan membaca, sandaran data dan menyediakan berbilang salinan.
- "Mekanisme Sentinel" secara automatik boleh mempromosikan nod hamba kepada nod induk selepas nod induk gagal, dan perkhidmatan boleh dipulihkan tanpa campur tangan manual.
- "Sentinel Cluster" menyelesaikan masalah satu titik kegagalan dan "misjudgment" yang disebabkan oleh Sentinel mesin tunggal.
Redis telah beralih daripada versi bersendirian yang paling ringkas kepada ketekunan data, salinan berbilang hamba induk dan gugusan sentinel melalui pengoptimuman sedemikian, prestasi dan kestabilan telah menjadi lebih tinggi dan lebih tinggi.
Namun, dengan perkembangan masa, volum perniagaan syarikat telah mengalami pertumbuhan yang meletup? Bolehkah model seni bina pada masa ini masih mampu menampung jumlah trafik yang begitu besar?
Sebagai contoh, terdapat keperluan sedemikian: gunakan Redis untuk menyimpan 5000 万 pasangan nilai kunci, setiap pasangan nilai kunci adalah kira-kira 512B Untuk menggunakan dan menyediakan perkhidmatan luaran dengan cepat, kami menggunakan hos awan untuk menjalankan mereka contoh Redis, kemudian bagaimana untuk memilih kapasiti memori hos awan?
Mengikut pengiraan, ruang memori yang diduduki oleh pasangan nilai kunci ini adalah lebih kurang 25GB (50 juta *512B).
Penyelesaian pertama yang terlintas di fikiran ialah: pilih hos awan dengan memori 32GB untuk menggunakan Redis. Kerana memori 32GB boleh menyimpan semua data, dan masih ada 7GB lagi untuk memastikan operasi normal sistem.
Pada masa yang sama, RDB juga digunakan untuk mengekalkan data bagi memastikan data boleh dipulihkan daripada RDB selepas kegagalan kejadian Redis.
Namun, semasa penggunaan, anda akan mendapati bahawa tindak balas Redis kadangkala sangat perlahan. Gunakan INFO命令 untuk menyemak latest_fork_usec nilai penunjuk Redis (menunjukkan masa yang diambil untuk garpu terkini), dan ternyata nilai penunjuk ini sangat tinggi.
Ini berkaitan dengan mekanisme kegigihan Redis.
Apabila menggunakan RDB untuk kegigihan, Redis akan fork sub-proses untuk menyelesaikannya fork Masa operasi berkaitan secara positif dengan jumlah data dalam Redis , dan fork Akan menyekat utas utama semasa pelaksanaan. Semakin besar jumlah data, semakin lama benang utama akan disekat kerana operasi garpu.
Jadi, apabila menggunakan RDB untuk mengekalkan 25GB data, jumlah data adalah besar dan proses anak yang berjalan di latar belakang menyekat urutan utama apabila fork dicipta, yang menyebabkan Respons Redis lebih perlahan.
Jelas sekali penyelesaian ini tidak boleh dilaksanakan dan kita mesti mencari penyelesaian lain.
Bagaimana untuk menyimpan lebih banyak data?
Untuk menyimpan sejumlah besar data, kami biasanya mempunyai dua kaedah: "Peluasan menegak" dan "Peluasan mendatar":
- Peluasan Menegak: Naik taraf konfigurasi sumber bagi satu tika Redis, termasuk meningkatkan kapasiti memori, meningkatkan kapasiti cakera dan menggunakan CPU konfigurasi lebih tinggi: Pengembangan mendatar: secara mendatar meningkatkan bilangan tika Redis semasa .
- Pertama sekali, kelebihan "pengembangan menegak" ialah ia mudah dan mudah untuk dilaksanakan. Walau bagaimanapun, penyelesaian ini juga menghadapi dua masalah yang berpotensi.
- mungkin disekat dalam proses anak.
-
forkSoalan kedua: Peluasan menegak akan dihadkan oleh perkakasan dan kos. - Ini mudah difahami Lagipun, ia adalah mudah untuk mengembangkan memori daripada 32GB kepada 64GB Namun, jika anda ingin mengembangkan kepada 1TB, anda akan menghadapi had dalam kapasiti dan kos perkakasan. Berbanding dengan "pengembangan menegak", "pengembangan mendatar" ialah penyelesaian berskala yang lebih baik. Ini kerana jika anda ingin menyimpan lebih banyak data, jika anda menggunakan penyelesaian ini, anda hanya perlu menambah bilangan kejadian Redis, dan anda tidak perlu risau tentang had perkakasan dan kos satu contoh.
Kluster Redis dilaksanakan berdasarkan "pengembangan mendatar". .
Kluster Redis
Kluster Redis ialah penyelesaian pangkalan data teragih Kluster menggunakan
(, juga dipanggil 分片) untuk berkongsi data dan menyediakan fungsi replikasi dan Failover. sharding切片Berbalik kepada senario yang baru kami ada, jika data 25GB dibahagikan sama rata kepada 5 bahagian (sudah tentu ia tidak perlu dibahagikan sama rata), dan 5 kejadian digunakan untuk menyimpannya, setiap kejadian hanya perlu menyimpan data 5GB. Seperti yang ditunjukkan di bawah:
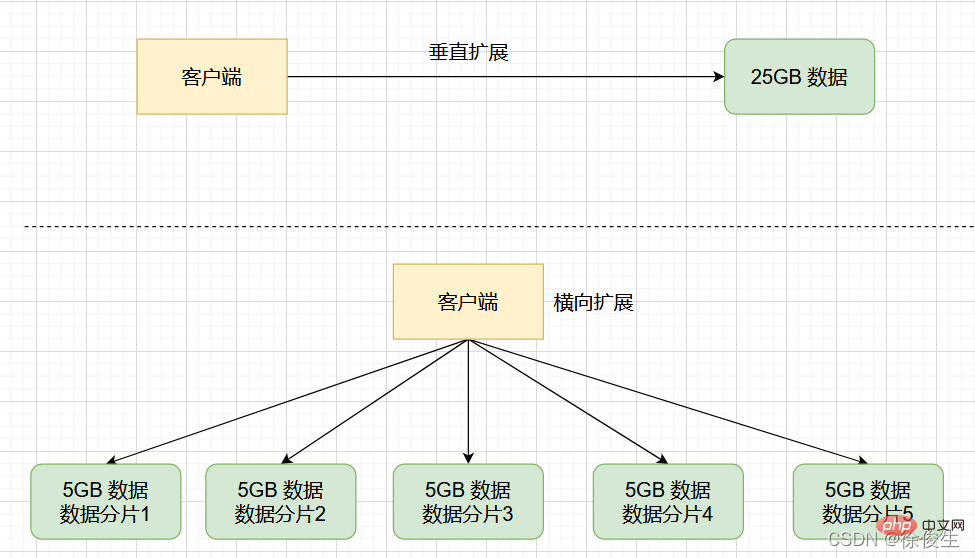
Kemudian, dalam kelompok penghirisan, apabila kejadian menjana RDB untuk data 5GB, jumlah data adalah jauh lebih kecil fork Proses anak secara amnya tidak menyekat utas utama untuk masa yang lama .
Selepas menggunakan berbilang kejadian untuk menyimpan kepingan data, kami bukan sahaja boleh menyimpan 25GB data, tetapi juga mengelakkan kelembapan mendadak sebagai tindak balas yang disebabkan oleh fork proses kanak-kanak menyekat urutan utama.
Apabila menggunakan Redis dalam amalan, apabila skala perniagaan berkembang, biasanya tidak dapat dielakkan untuk menyimpan sejumlah besar data. Dan kelompok Redis adalah penyelesaian yang sangat baik.
Mari kita mula mengkaji cara membina gugusan Redis?
Membina gugusan Redis
Kluster Redis biasanya terdiri daripada berbilang nod Pada permulaannya, setiap nod adalah bebas antara satu sama lain dan tiada hubungan antara nod. Untuk membentuk kelompok yang berfungsi, kita mesti menyambungkan setiap nod bebas bersama-sama untuk membentuk kelompok yang mengandungi berbilang nod.
Kita boleh menyambungkan setiap nod melalui perintah CLUSTER MEET:
CLUSTER MEET <ip> <port></port></ip>
- ip: ip nod yang akan ditambahkan pada kluster
- port : untuk ditambahkan Port nod Kluster
Perihalan arahan: Dengan menghantar perintah CLUSTER MEET ke nod A, nod A yang menerima arahan boleh menambah nod B lain pada gugusan di mana nod A berada terletak.
Ini agak abstrak, mari kita lihat contoh.
Andaikan kini terdapat tiga nod bebas 127.0.0.1:7001, 127.0.0.1:7002, 127.0.0.1:7003.
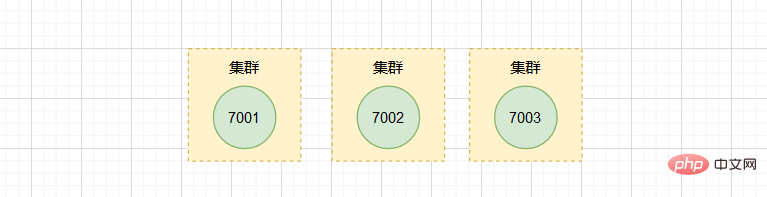
Kami mula-mula menggunakan klien untuk menyambung ke nod 7001:
$ redis-cli -c -p 7001
dan kemudian menghantar arahan ke nod 7001 untuk menukar nod 7002 Ditambah pada gugusan di mana 7001 terletak:
127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7002
Begitu juga, kami menghantar arahan ke 7003 dan juga menambahnya pada gugusan di mana 7001 dan 7002 terletak .
127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7003
Gunakan perintah
CLUSTER NODESuntuk melihat maklumat nod dalam kelompok.
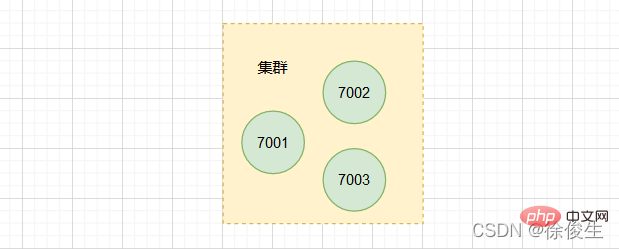
Kelompok kini mengandungi tiga nod: 7001, 7002 dan 7003. Walau bagaimanapun, apabila menggunakan satu contoh, adalah sangat jelas di mana data wujud dan di mana pelanggan mengaksesnya. Walau bagaimanapun, penghirisan gugusan sudah semestinya melibatkan isu pengurusan yang diedarkan bagi berbilang kejadian.
Untuk menggunakan gugusan penghirisan, kita perlu menyelesaikan dua masalah utama:
- Bagaimana untuk mengedarkan data antara berbilang kejadian selepas menghiris?
- Bagaimanakah pelanggan menentukan contoh data yang ingin diakses olehnya?
Seterusnya, kami akan selesaikan satu persatu.
Hubungan pengedaran yang sepadan antara kepingan data dan kejadian
Dalam kelompok penghirisan, data perlu diedarkan pada kejadian yang berbeza Jadi, bagaimanakah koresponden antara data dan kejadian?
Ini berkaitan dengan rancangan Redis Cluster yang akan saya bincangkan seterusnya. Walau bagaimanapun, kita mesti terlebih dahulu memahami kaitan dan perbezaan antara gugusan hirisan dan Redis Cluster.
Sebelum Redis 3.0, pegawai itu tidak memberikan penyelesaian khusus untuk menghiris gugusan. Bermula dari 3.0, pegawai itu menyediakan penyelesaian yang dipanggil
Redis Clusteruntuk melaksanakan gugusan penghirisan.
Malah, gugusan penghirisan ialah mekanisme umum untuk menyimpan sejumlah besar data, dan mekanisme ini boleh mempunyai penyelesaian pelaksanaan yang berbeza. Redis Cluster Peraturan yang sepadan untuk data dan kejadian ditetapkan dalam pelan.
Secara khususnya, penyelesaian Redis Cluster menggunakan Slot Cincang (Slot Cincang) untuk mengendalikan hubungan pemetaan antara data dan kejadian.
Slot cincang dan pemetaan contoh Redis
Dalam skema Redis Cluster, gugusan hirisan mempunyai sejumlah 16384 slot cincang (2^14), slot cincang ini serupa dengan data Pembahagian, setiap pasangan nilai kunci akan dipetakan ke slot cincang mengikut kuncinya.
Dalam analisis kami di atas, tiga nod CLUSTER MEET, 7001 dan 7002 disambungkan ke gugusan yang sama melalui perintah 7003, tetapi gugusan ini sedang di luar talian status ialah , kerana tiga nod dalam kelompok tidak mempunyai sebarang slot ditetapkan.
Jadi, bagaimanakah slot cincang ini dipetakan kepada kejadian Redis tertentu?
Kita boleh menggunakan perintah CLUSTER MEET untuk mewujudkan sambungan antara kejadian secara manual untuk membentuk kelompok, dan kemudian menggunakan perintah CLUSTER ADDSLOTS untuk menentukan bilangan slot cincang pada setiap tika.
CLUSTER ADDSLOTS <slot> [slot ...]</slot>
Redis5.0 menyediakan perintah
CLUSTER CREATEuntuk mencipta gugusan Dengan menggunakan arahan ini, Redis akan mengedarkan slot ini secara sekata antara kejadian gugusan.
举个例子,我们通过以下命令,给 7001、7002、7003 三个节点分别指派槽。
将槽 0 ~ 槽5000 指派给 给 7001 :
127.0.0.1:7001> CLUSTER ADDSLOTS 0 1 2 3 4 ... 5000
将槽 5001 ~ 槽10000 指派给 给 7002 :
127.0.0.1:7002> CLUSTER ADDSLOTS 5001 5002 5003 5004 ... 10000
将槽 10001~ 槽 16383 指派给 给 7003 :
127.0.0.1:7003> CLUSTER ADDSLOTS 10001 10002 10003 10004 ... 16383
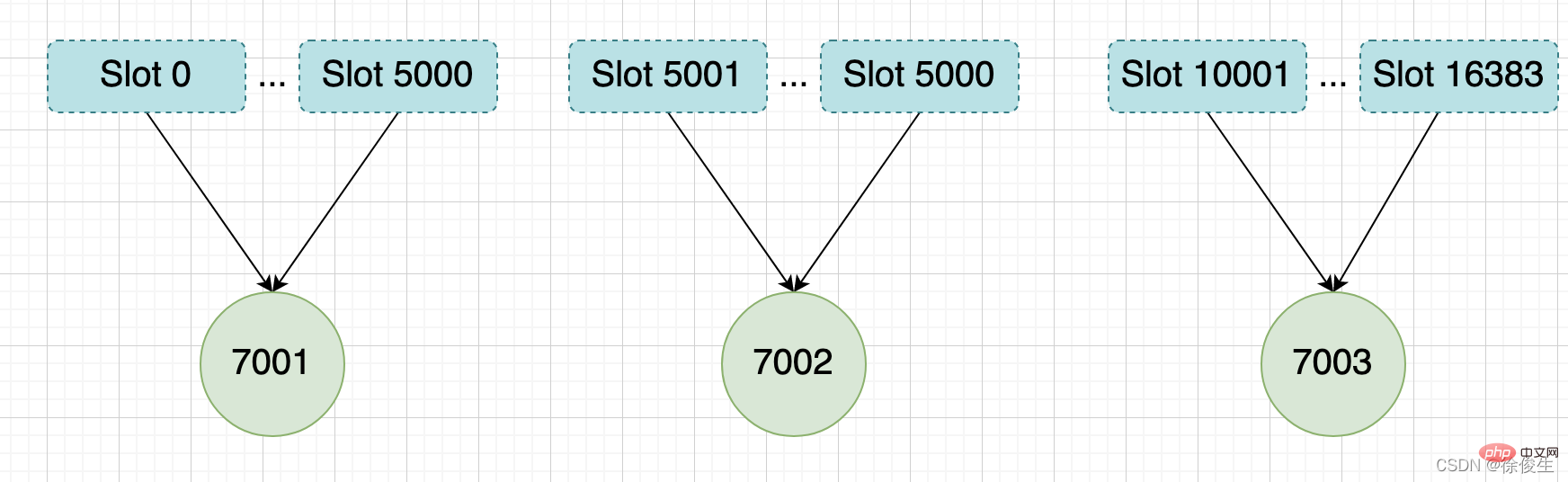
当三个 CLUSTER ADDSLOTS 命令都执行完毕之后,数据库中的 16384 个槽都已经被指派给了对应的节点,此时集群进入上线状态。
通过哈希槽,切片集群就实现了数据到哈希槽、哈希槽再到实例的分配。
但是,即使实例有了哈希槽的映射信息,客户端又是怎么知道要访问的数据在哪个实例上呢?
客户端如何定位数据?
一般来说,客户端和集群实例建立连接后,实例就会把哈希槽的分配信息发给客户端。但是,在集群刚刚创建的时候,每个实例只知道自己被分配了哪些哈希槽,是不知道其他实例拥有的哈希槽信息的。
那么,客户端是如何可以在访问任何一个实例时,就能获得所有的哈希槽信息呢?
Redis 实例会把自己的哈希槽信息发给和它相连接的其它实例,来完成哈希槽分配信息的扩散。当实例之间相互连接后,每个实例就有所有哈希槽的映射关系了。
客户端收到哈希槽信息后,会把哈希槽信息缓存在本地。当客户端请求键值对时,会先计算键所对应的哈希槽,然后就可以给相应的实例发送请求了。
当客户端向节点请求键值对时,接收命令的节点会计算出命令要处理的数据库键属于哪个槽,并检查这个槽是否指派给了自己:
- 如果键所在的槽刚好指派给了当前节点,那么节点会直接执行这个命令;
- 如果没有指派给当前节点,那么节点会向客户端返回一个
MOVED错误,然后重定向(redirect)到正确的节点,并再次发送之前待执行的命令。
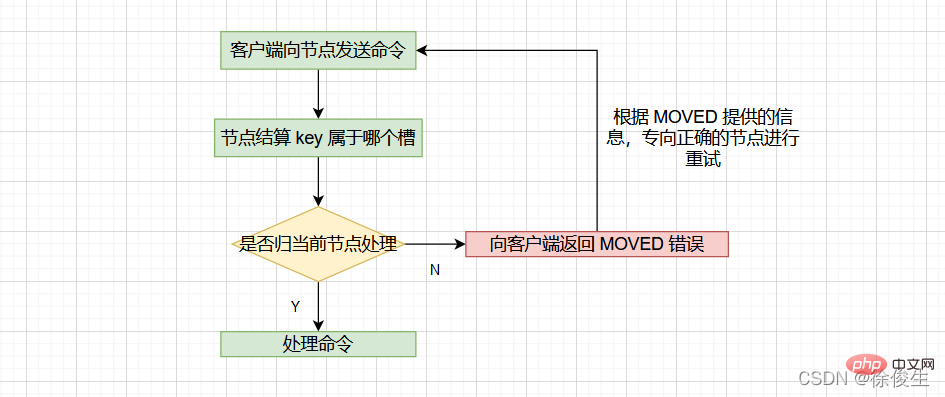
计算键属于哪个槽
节点通过以下算法来定义 key 属于哪个槽:
crc16(key,keylen) & 0x3FFF;
- crc16:用于计算 key 的 CRC-16 校验和
- 0x3FFF:换算成 10 进制是 16383
- & 0x3FFF:用于计算出一个介于 0~16383 之间的整数作为 key 的槽号。
通过
CLUSTER KEYSLOT <key></key>命令可以查看 key 属于哪个槽。
判断槽是否由当前节点负责处理
当节点计算出 key 所属的 槽 i 之后,节点会判断 槽 i 是否被指派了自己。那么如何判断呢?
每个节点会维护一个 「slots数组」,节点通过检查 slots[i] ,判断 槽 i 是否由自己负责:
- 如果说
slots[i]对应的节点是当前节点的话,那么说明槽 i由当前节点负责,节点可以执行客户端发送的命令; - 如果说
slots[i]对应的不是当前节点,节点会根据slots[i]所指向的节点向客户端返回MOVED错误,指引客户端转到正确的节点。
MOVED 错误
格式:
MOVED <slot> <ip>:<port></port></ip></slot>
- slot:键所在的槽
- ip:负责处理槽 slot 节点的 ip
- port:负责处理槽 slot 节点的 port
比如:MOVED 10086 127.0.0.1:7002,表示,客户端请求的键值对所在的哈希槽 10086,实际是在 127.0.0.1:7002 这个实例上。
通过返回的 MOVED 命令,就相当于把哈希槽所在的新实例的信息告诉给客户端了。
这样一来,客户端就可以直接和 7002 连接,并发送操作请求了。
同时,客户端还会更新本地缓存,将该槽与 Redis 实例对应关系更新正确。
集群模式的
redis-cli客户端在接收到MOVED错误时,并不会打印出MOVED错误,而是根据MOVED错误自动进行节点转向,并打印出转向信息,所以我们是看不见节点返回的MOVED错误的。而使用单机模式的redis-cli客户端可以打印MOVED错误。
其实,Redis 告知客户端重定向访问新实例分两种情况:MOVED 和 ASK 。下面我们分析下 ASK 重定向命令的使用方法。
重新分片
在集群中,实例和哈希槽的对应关系并不是一成不变的,最常见的变化有两个:
- 在集群中,实例有新增或删除,Redis 需要重新分配哈希槽;
- 为了负载均衡,Redis 需要把哈希槽在所有实例上重新分布一遍。
重新分片可以在线进行,也就是说,重新分片的过程中,集群不需要下线。
举个例子,上面提到,我们组成了 7001、7002、7003 三个节点的集群,我们可以向这个集群添加一个新节点127.0.0.1:7004。
$ redis-cli -c -p 7001 127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7004 OK
然后通过重新分片,将原本指派给节点 7003 的槽 15001 ~ 槽 16383 改为指派给 7004。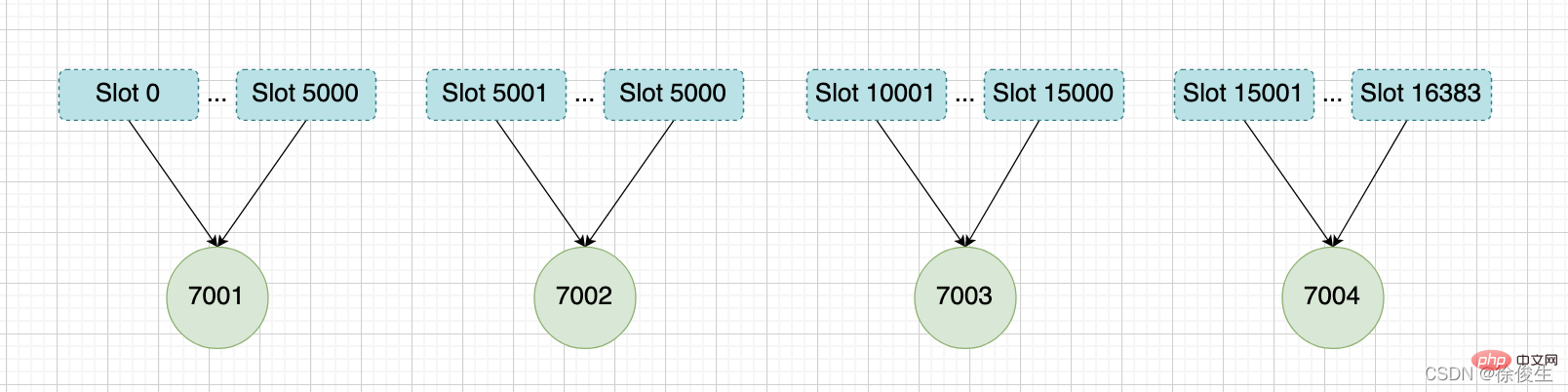
在重新分片的期间,源节点向目标节点迁移槽的过程中,可能会出现这样一种情况:如果某个槽的数据比较多,部分迁移到新实例,还有一部分没有迁移咋办?
在这种迁移部分完成的情况下,客户端就会收到一条 ASK 报错信息。
ASK 错误
如果客户端向目标节点发送一个与数据库键有关的命令,并且这个命令要处理的键正好属于被迁移的槽时:
- 源节点会先在自己的数据库里查找指定的键,如果找到的话,直接执行命令;
- 相反,如果源节点没有找到,那么这个键就有可能已经迁移到了目标节点,源节点就会向客户端发送一个
ASK错误,指引客户端转向目标节点,并再次发送之前要执行的命令。
看起来好像有点复杂,我们举个例子来解释一下。
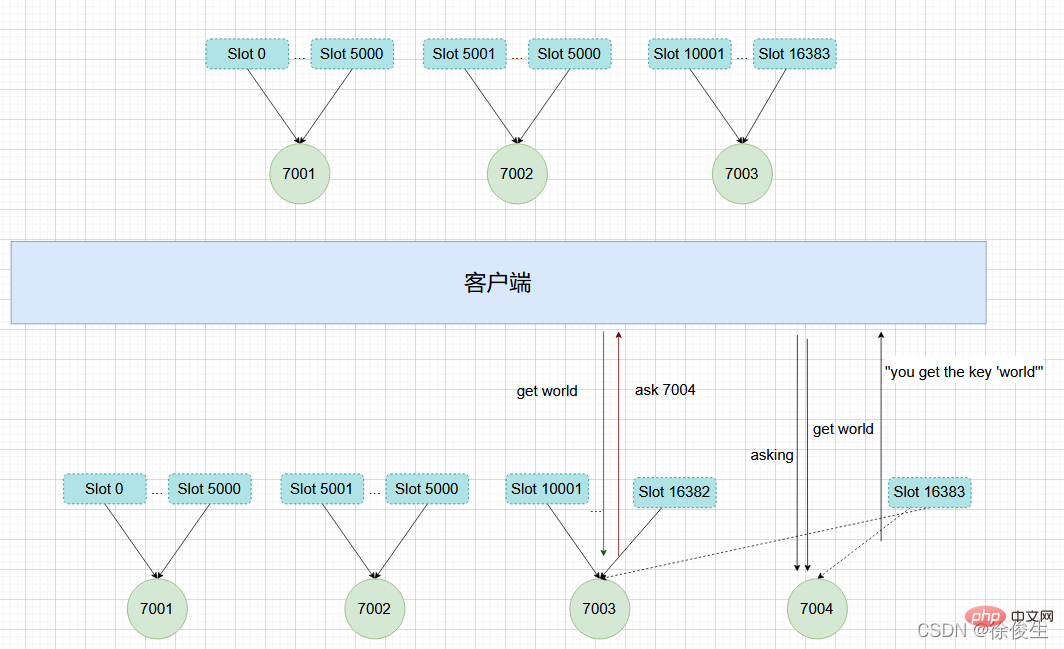
如上图所示,节点 7003 正在向 7004 迁移 槽 16383,这个槽包含 hello 和 world,其中键 hello 还留在节点 7003,而 world 已经迁移到 7004。
我们向节点 7003 发送关于 hello 的命令 这个命令会直接执行:
127.0.0.1:7003> GET "hello" "you get the key 'hello'"
如果我们向节点 7003 发送 world 那么客户端就会被重定向到 7004:
127.0.0.1:7003> GET "world" -> (error) ASK 16383 127.0.0.1:7004
客户端在接收到 ASK 错误之后,先发送一个 ASKING 命令,然后在发送 GET "world" 命令。
ASKING命令用于打开节点的ASKING标识,打开之后才可以执行命令。
ASK 和 MOVED 的区别
ASK 错误和 MOVED 错误都会导致客户端重定向,它们的区别在于:
- MOVED 错误代表槽的负责权已经从一个节点转移到了另一个节点:在客户端收到关于
槽 i的MOVED错误之后,客户端每次遇到关于槽 i的命令请求时,都可以直接将命令请求发送至MOVED错误指向的节点,因为该节点就是目前负责槽 i的节点。 - 而 ASK 只是两个节点迁移槽的过程中的一种临时措施:在客户端收到关于
槽 i的ASK错误之后,客户端只会在接下来的一次命令请求中将关于槽 i的命令请求发送到ASK错误指向的节点,但是 ,如果客户端再次请求槽 i中的数据,它还是会给原来负责槽 i的节点发送请求。
这也就是说,ASK 命令的作用只是让客户端能给新实例发送一次请求,而且也不会更新客户端缓存的哈希槽分配信息。而不像 MOVED 命令那样,会更改本地缓存,让后续所有命令都发往新实例。
我们现在知道了 Redis 集群的实现原理。下面我们再来分析下,Redis 集群如何实现高可用的呢?
复制与故障转移
Redis 集群中的节点也是分为主节点和从节点。
- 主节点用于处理槽
- 从节点用于复制主节点,如果被复制的主节点下线,可以代替主节点继续提供服务。
举个例子,对于包含 7001 ~ 7004 的四个主节点的集群,可以添加两个节点:7005、7006。并将这两个节点设置为 7001 的从节点。
设置从节点命令:
CLUSTER REPLICATE <node_id></node_id>
如图:
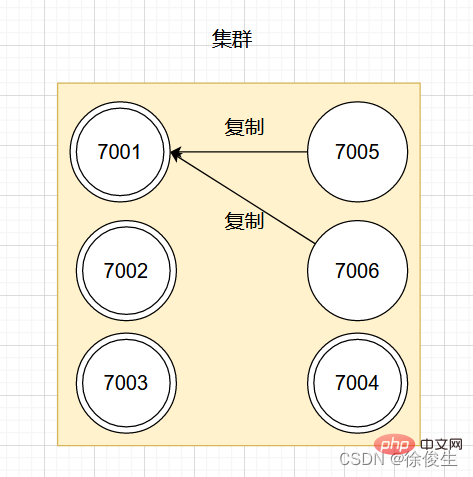
如果此时,主节点 7001 下线,那么集群中剩余正常工作的主节点将在 7001 的两个从节点中选出一个作为新的主节点。
例如,节点 7005 被选中,那么原来由节点 7001 负责处理的槽会交给节点 7005 处理。而节点 7006 会改为复制新主节点 7005。如果后续 7001 重新上线,那么它将成为 7005 的从节点。如下图所示:
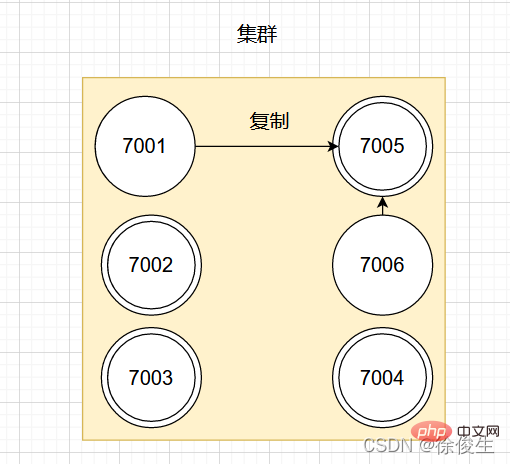
故障检测
集群中每个节点会定期向其他节点发送 PING 消息,来检测对方是否在线。如果接收消息的一方没有在规定时间内返回 PONG 消息,那么接收消息的一方就会被发送方标记为「疑似下线」。
集群中的各个节点会通过互相发消息的方式来交换各节点的状态信息。
节点的三种状态:
- 在线状态
- 疑似下线状态 PFAIL
- 已下线状态 FAIL
一个节点认为某个节点失联了并不代表所有的节点都认为它失联了。在一个集群中,半数以上负责处理槽的主节点都认定了某个主节点下线了,集群才认为该节点需要进行主从切换。
Redis 集群节点采用 Gossip 协议来广播自己的状态以及自己对整个集群认知的改变。比如一个节点发现某个节点失联了 (PFail),它会将这条信息向整个集群广播,其它节点也就可以收到这点失联信息。
我们都知道,哨兵机制可以通过监控、自动切换主库、通知客户端实现故障自动切换。那么 Redis Cluster 又是如何实现故障自动转移呢?
故障转移
当一个从节点发现自己正在复制的主节点进入了「已下线」状态时,从节点将开始对下线主节点进行故障切换。
故障转移的执行步骤:
- 在复制下线主节点的所有从节点里,选中一个从节点
- 被选中的从节点执行
SLAVEOF no one命令,成为主节点 - 新的主节点会撤销所有对已下线主节点的槽指派,将这些槽全部指派给自己
- 新的主节点向集群广播一条
PONG消息,让集群中其他节点知道,该节点已经由从节点变为主节点,且已经接管了原主节点负责的槽 - 新的主节点开始接收自己负责处理槽有关的命令请求,故障转移完成。
选主
这个选主方法和哨兵的很相似,两者都是基于 Raft算法 的领头算法实现的。流程如下:
- 集群的配置纪元是一个自增计数器,初始值为0;
- 当集群里的某个节点开始一次故障转移操作时,集群配置纪元加 1;
- 对于每个配置纪元,集群里每个负责处理槽的主节点都有一次投票的机会,第一个向主节点要求投票的从节点将获得主节点的投票;
- 当从节点发现自己复制的主节点进入「已下线」状态时,会向集群广播一条消息,要求收到这条消息,并且具有投票权的主节点为自己投票;
- 如果一个主节点具有投票权,且尚未投票给其他从节点,那么该主节点会返回一条消息给要求投票的从节点,表示支持从节点成为新的主节点;
- 每个参与选举的从节点会计算获得了多少主节点的支持;
- 如果集群中有 N 个具有投票权的主节点,当一个从节点收到的支持票
大于等于 N/2 + 1时,该从节点就会当选为新的主节点; - 如果在一个配置纪元里没有从节点收集到足够多的票数,那么集群会进入一个新的配置纪元,并再次进行选主。
消息
集群中的各个节点通过发送和接收消息来进行通信,我们把发送消息的节点称为发送者,接收消息的称为接收者。
节点发送的消息主要有五种:
- Mesej MEET
- Mesej PING
- Mesej PONG
- Mesej GAGAL
- TERBITKAN mesej
Kluster Setiap nod dalam pertukaran maklumat status nod yang berbeza melalui protokol Gossip terdiri daripada tiga mesej: Gossip, MEET dan PING. PONG
, MEET, PING, ia akan secara rawak memilih dua nod (yang boleh menjadi nod induk atau nod hamba) daripada senarai nod yang diketahui dan dihantar ke penerima. PONG
, MEET, PING, ia akan melakukan pemprosesan yang berbeza mengikut sama ada ia mengetahui kedua-dua nod ini: PONG
- Jika dipilih The nod yang menerima senarai nod yang diketahui tidak wujud, menunjukkan bahawa ia adalah kenalan pertama Penerima akan berkomunikasi mengikut IP dan nombor port bagi nod yang dipilih; telah selesai sebelum ini. Kemudian maklumat nod yang dipilih asal akan dikemas kini.
- Pembelajaran yang disyorkan: Tutorial Redis
Atas ialah kandungan terperinci Bawa anda langkah demi langkah untuk memahami kelompok ketersediaan tinggi Redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!