
Rumah >pembangunan bahagian belakang >tutorial php >网易云音乐评论爬取
网易云音乐评论爬取
- jackloveasal
- 2018-06-11 23:42:122807semak imbas
# coding=gbk
import requests
import json
c='网易云爬虫实战一'
print(c)
music_url = 'https://music.163.com/#/song?id=28815250'
id = music_url.split('=')[1]
# print(id)
url = 'https://music.163.com/weapi/v1/resource/comments/R_SO_4_%s?csrf_token=7e19029fe28aa3e09cfe87e89d2e4eeb' %(id)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Referer': 'https://music.163.com/song?id=%s' %(id),
'Origin': 'https://music.163.com',
}
formdata = {
'params': 'AoF/ZXuccqvtaCMCPHecFGVPfrbtDj4JFPJsaZ3tYn9J+r0NcnKPhZdVECDz/jM+1CpA+ByvAO2J9d44B/MG97WhjmxWkfo4Tm++AfyBgK11NnSbKsuQ5bxJR6yE0MyFhU8sPq7wb9DiUPFKs2ulw0GxwU/il1NS/eLrq+bbYikK/cyne90S/yGs6ldxpbcNd1yQTuOL176aBZXTJEcGkfbxY+mLKCwScAcCK1s3STo=',
'encSecKey': '365b4c31a9c7e2ddc002e9c42942281d7e450e5048b57992146633181efe83c1e26acbc8d84b988d746370d788b6ae087547bace402565cca3ad59ccccf7566b07d364aa1d5b2bbe8ccf2bc33e0f03182206e29c66ae4ad6c18cb032d23f1793420ceda05e796401f170dbdb825c20356d27f07870598b2798f8d344807ad6f2',
}
response = requests.post(url, headers = headers, data = formdata)
messages = json.loads(response.text)
data_list=[]
data={}
for message in messages['hotComments']:
data['nickname']=message['user']['nickname']
data['content']=message['content']
data_list.append(data)
data={}
#print(data_list)
for i in data_list:
c = ' '+i['nickname']+':'+i['content']
print('\n\n'+c.replace('\n',''))
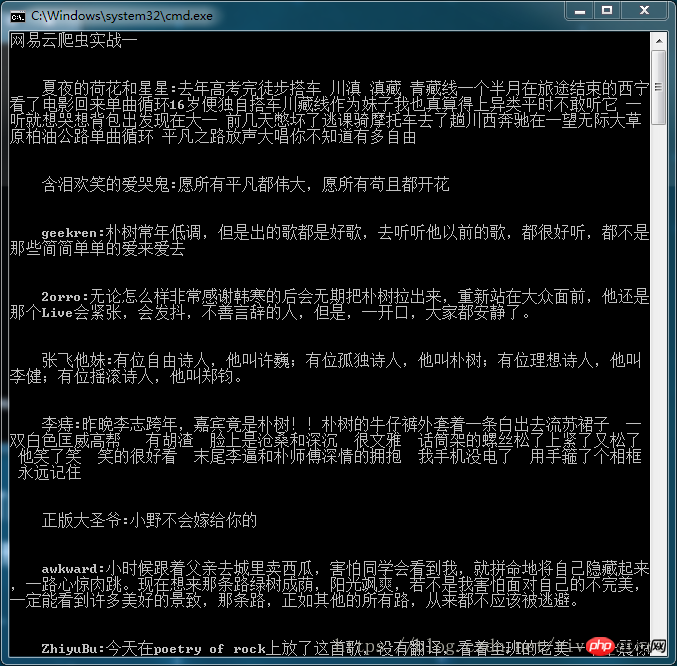
总结:
1、第一行的“# coding=gbk”表示的是可以在文本编辑器中输入文字字符串。
2、"id = music_url.split('=')[1]"中split()函数表示对元素进行分组,例中为“https://music.163.com/#/song?id=”,“28815250”
3、由requests模块获取的HTML文本需要用json.loads()方法进行转化为Python可读的文本,否则会报错。在jupyter notebook中则不会出现这种情况。
4、replace()函数可以去除字符串中的元素,例中将换行符变为空。
最终显示结果如下图:
本文介绍了网易云音乐评论爬取 的相关内容,请关注php中文网。
相关推荐:
Atas ialah kandungan terperinci 网易云音乐评论爬取. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:
Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn
Artikel sebelumnya:php生成二维码的三种方法Artikel seterusnya:Echarts 折线图设置梯度背景色
Artikel berkaitan
Lihat lagi- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Cara menggunakan cURL untuk melaksanakan permintaan Dapatkan dan Hantar dalam PHP
- Semua simbol ungkapan dalam ungkapan biasa (ringkasan)