


这篇文章主要介绍了SQL Server 磁盘请求超时的833错误原因及解决方法,需要的朋友可以参考下
最近遇到一个SQL Server服务器响应极度缓慢,并且出现客户端请求报错的情况,在数据库中的errorlog中出现磁盘请求超过15s才完成的error消息。
对于此类问题,到底是存储系统或者磁盘的故障,还是SQL Server 自己的问题,亦或是应用程序引发的呢?又要如何解决?
本文将对引起此问题的某一方面的因素进行简单的分析,但是无法涵盖所有潜在的可能性,因此遇到类似问题还要做具体的分析。
SQL Server中的磁盘请求超时
该错误的英文版的错误信息如下:
SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database id %d. The OS file handle is 0x%p. 0
The offset of the latest long I/O is: %#016I64x
中文版的错误信息如下
SQL Server 已遇到 %1! 次对数据库 ID %4! 中的文件 [%3!] 进行的 I/O 请求超过 %2! 秒才完成。操作系统文件句柄为 0x%5!。最新的长时间 I/O 的偏移量为: %6!
参考message信息中的833号错误消息
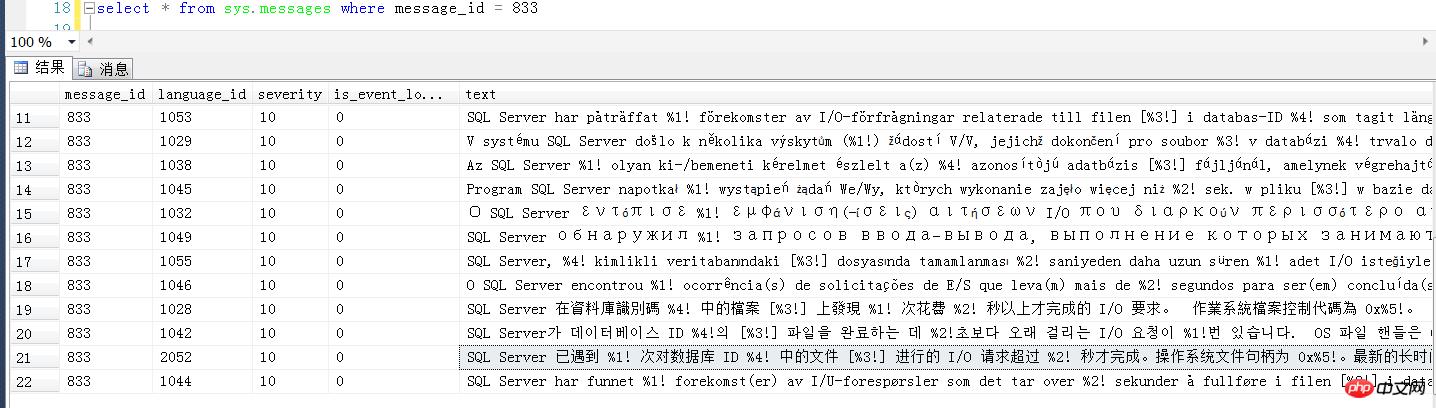
具体的833 error 申请磁盘请求超时现象
具体报错情况如下:
SQL Server 已遇到 m 次对数据库 n 中的文件***进行的 I/O 请求超过 15 秒才完成。操作系统文件句柄为 ***。最新的长时间 I/O 的偏移量为: ***
也就是说在数据库的文件自动增长的过程中遇到了错误。
。
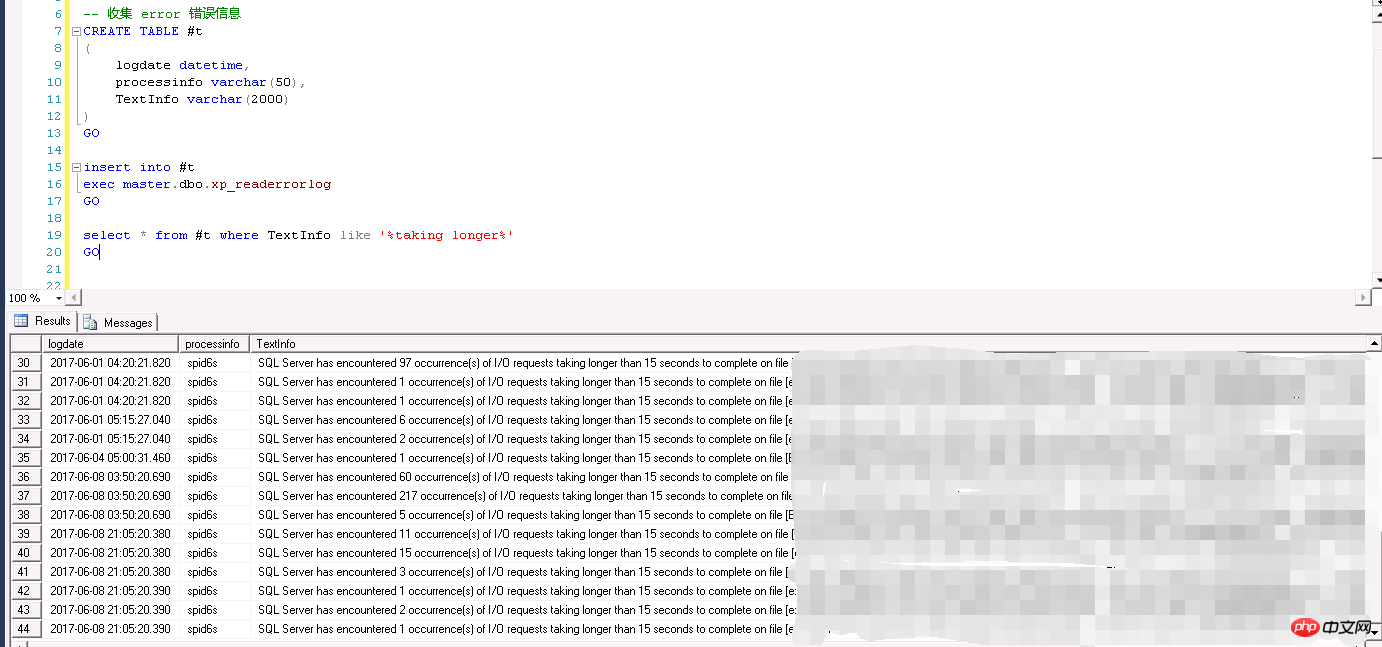
比较有意思的是某DBA将此错误信息报告给负责存储(SAN存储,并非挂的磁盘)的工程师,认为是可能存储系统存在故障或者不稳定造成的,
存储工程师认为存储没有问题,检查服务器后说服务器不正常,内存“几乎占满”,对于数据库服务器,内存“几乎占满”的情况可以说是完全正常的,鉴于负责存储的工程师并非专业DBA,对于SQL Server数据库服务器的内存使用可能不是太了解,提出此疑问也可以理解。
因为数据库服务器使用的存储是高性能的SAN存储,存储是作为一个服务存在的,有N多服务器共同来使用的,其他服务器并没有出现磁盘请求,不太可能说某一台服务器会出现疑似“存储故障”就简单认定为是存储故障。
那么究竟原因在什么地方呢?
数据库引擎错误833的含义
首先来看这个833错误的具体含义是什么,就不自己装13解释一通了,那本经典的书上写的很清楚了。
总之,意思就是,SQL Server在请求磁盘读写的时候,遇到磁盘繁忙或者其他一些因素,超过了15秒还没有完成
比如数据的读写的时候需要向磁盘发起请求,而磁盘正忙或者其他问题,来不及或者相应的不够及时,这样无疑会严重影响SQL Server对外提供服务器的响应时间。
上面简单分析了,因为该问题并非普片发生的,存储系统不太可能出现问题,那就很有可能定位到当前服务器自身的因素了。

原因分析
因为是专门的SQL Server服务器,没有其他应用程序的请求,很有可能跟向sqlserver数据库发起的请求有关。
其实发生这个问题之前,早就有预兆了,平时还算稳定的服务器(CPU很少超过60%,内存的PLE也可以稳定在20分钟以上,磁盘IO延迟较低等等),只是偶尔会存在抽风一阵子的情况
抽风的时候表现为CPU狂飙到80%左右,内存的PLE会严重下降,IO延迟严重增高。
现在只能从SQL Server的Session入手,在观察SQL Server中的活动Session的时候,发现某一类的SQL语句的查询时间非常长,
平时这类SQL在某一个时间段内执行的频率还算比较高。
但是正常情况下,这类SQL的执行效率还是比较高的,为什么突然就变的非常之底?
在检查活动Session的对应的执行计划的时候,发现这类活动Session的等待状态都是IO等待(PAGEIOLATCH_SH),同时SQL的执行完全是意料之外的执行方式。
因为类似查询还是执行的比较频繁的,此类Session会从不同的客户端发起,一旦SQL的执行效率降下来,服务器上会积压大量的活动Session
为什么平时执行的好好的SQL语句突然就变的很慢很慢,
原因就在于在某一点,SQL Server自动触发了统计信息的更新,但是这是一个比较大的表,但是默认统计信息更新的取样比例是不够的,如果取样百分比不够,这个统计信息完全是不可用的。
一旦自动收集统计信息完成之后,会根据当前收集到的统计信息,向之前的SQL语句发出一种它认为高效的方式(table scan而不是index seek),其实这种方式并非是合理的,
由此引发对应的SQL利用一种并非合理的执行计划来实现查询,同时会引发Session的拥堵,客户端发过来大量的Session同时在利用一种低效的方式缓慢执行。
所以CPU会飙升,IO延迟增加,内存的PLE严重下降。
由此也不难理解,数十个查询的Session正在以一种不合理的方式疯狂地想磁盘发出请求,磁盘正在忙于活动Session的数据请求,出现无法响应因为数据或者索引文件的自动增长请求,造成一开始说的问题。
最后经过索引重建(促使统计信息更新,当然纯粹的统计信息更新也可以)解决,长期预防的话,需要安排job人为地定义统计信息更新的阈值以及取样百分比。
总结:
数据库服务器上的问题,很多问题都是一个连锁反应的过程,对应观察到的一部分现象,很有可能并不是表面上的反应的那样(磁盘请求超时,问题出在存储上?)
专业的位置上必须要有专业的素养,比如一开始DBA误以为是存储问题,存储工程师认为服务器内存用满了是不正常的等,其实都不是问题的根本原因所在。
面对问题,要追本溯源,找出来最根本的原因,才是解决问题的关键。
Atas ialah kandungan terperinci SQL Server 磁盘请求超时的833错误原因及解决方法_MsSql. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Bagaimanakah kardinaliti indeks MySQL mempengaruhi prestasi pertanyaan?Apr 14, 2025 am 12:18 AM
Bagaimanakah kardinaliti indeks MySQL mempengaruhi prestasi pertanyaan?Apr 14, 2025 am 12:18 AMCardinality Indeks MySQL mempunyai kesan yang signifikan terhadap prestasi pertanyaan: 1. Indeks kardinaliti yang tinggi dapat lebih berkesan menyempitkan julat data dan meningkatkan kecekapan pertanyaan; 2. Indeks kardinaliti yang rendah boleh membawa kepada pengimbasan jadual penuh dan mengurangkan prestasi pertanyaan; 3. Dalam indeks bersama, urutan kardinaliti yang tinggi harus diletakkan di depan untuk mengoptimumkan pertanyaan.
 MySQL: Sumber dan Tutorial untuk Pengguna BaruApr 14, 2025 am 12:16 AM
MySQL: Sumber dan Tutorial untuk Pengguna BaruApr 14, 2025 am 12:16 AMLaluan pembelajaran MySQL termasuk pengetahuan asas, konsep teras, contoh penggunaan, dan teknik pengoptimuman. 1) Memahami konsep asas seperti jadual, baris, lajur, dan pertanyaan SQL. 2) Ketahui definisi, prinsip kerja dan kelebihan MySQL. 3) menguasai operasi CRUD asas dan penggunaan lanjutan, seperti indeks dan prosedur yang disimpan. 4) Biasa dengan debugging kesilapan biasa dan cadangan pengoptimuman prestasi, seperti penggunaan rasional indeks dan pertanyaan pengoptimuman. Melalui langkah -langkah ini, anda akan memahami sepenuhnya penggunaan dan pengoptimuman MySQL.
 Mysql dunia nyata: Contoh dan kes penggunaanApr 14, 2025 am 12:15 AM
Mysql dunia nyata: Contoh dan kes penggunaanApr 14, 2025 am 12:15 AMAplikasi dunia nyata MySQL termasuk reka bentuk pangkalan data asas dan pengoptimuman pertanyaan kompleks. 1) Penggunaan Asas: Digunakan untuk menyimpan dan mengurus data pengguna, seperti memasukkan, menanyakan, mengemas kini dan memadam maklumat pengguna. 2) Penggunaan lanjutan: Mengendalikan logik perniagaan yang kompleks, seperti perintah dan pengurusan inventori platform e-dagang. 3) Pengoptimuman Prestasi: Meningkatkan prestasi dengan menggunakan indeks, jadual partisi dan cache pertanyaan.
 Perintah SQL di MySQL: Contoh PraktikalApr 14, 2025 am 12:09 AM
Perintah SQL di MySQL: Contoh PraktikalApr 14, 2025 am 12:09 AMPerintah SQL di MySQL boleh dibahagikan kepada kategori seperti DDL, DML, DQL, dan DCL, dan digunakan untuk membuat, mengubah suai, memadam pangkalan data dan jadual, memasukkan, mengemas kini, memadam data, dan melakukan operasi pertanyaan yang kompleks. 1. Penggunaan asas termasuk jadual penciptaan createtable, memasukkan data memasukkan, dan pilih data pertanyaan. 2. Penggunaan lanjutan melibatkan gabungan untuk Jadual Bergabung, Subqueries dan Groupby untuk Agregasi Data. 3. Kesilapan umum seperti kesilapan sintaks, jenis data yang tidak sepadan dan masalah kebenaran boleh disahpepijat melalui pemeriksaan sintaks, penukaran jenis data dan pengurusan kebenaran. 4. Cadangan Pengoptimuman Prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi gabungan dan menggunakan transaksi untuk memastikan konsistensi data.
 Bagaimanakah InnoDB mengendalikan pematuhan asid?Apr 14, 2025 am 12:03 AM
Bagaimanakah InnoDB mengendalikan pematuhan asid?Apr 14, 2025 am 12:03 AMInnoDB mencapai atomik melalui undolog, konsistensi dan pengasingan melalui mekanisme penguncian dan MVCC, dan kegigihan melalui redolog. 1) Atomicity: Gunakan Undolog untuk merekodkan data asal untuk memastikan urus niaga dapat dilancarkan kembali. 2) Konsistensi: Memastikan konsistensi data melalui penguncian peringkat baris dan MVCC. 3) Pengasingan: Menyokong pelbagai tahap pengasingan, dan RepeatableRead digunakan secara lalai. 4) Kegigihan: Gunakan redolog untuk merekodkan pengubahsuaian untuk memastikan data disimpan untuk masa yang lama.
 Tempat Mysql: Pangkalan Data dan PengaturcaraanApr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan PengaturcaraanApr 13, 2025 am 12:18 AMKedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
 Mysql: Dari perniagaan kecil ke perusahaan besarApr 13, 2025 am 12:17 AM
Mysql: Dari perniagaan kecil ke perusahaan besarApr 13, 2025 am 12:17 AMMySQL sesuai untuk perusahaan kecil dan besar. 1) Perniagaan kecil boleh menggunakan MySQL untuk pengurusan data asas, seperti menyimpan maklumat pelanggan. 2) Perusahaan besar boleh menggunakan MySQL untuk memproses data besar dan logik perniagaan yang kompleks untuk mengoptimumkan prestasi pertanyaan dan pemprosesan transaksi.
 Apa yang dibaca oleh Phantom dan bagaimana InnoDB menghalang mereka (kunci seterusnya)?Apr 13, 2025 am 12:16 AM
Apa yang dibaca oleh Phantom dan bagaimana InnoDB menghalang mereka (kunci seterusnya)?Apr 13, 2025 am 12:16 AMInnoDB secara berkesan menghalang pembacaan hantu melalui mekanisme utama. 1) Kekunci seterusnya menggabungkan kunci baris dan kunci jurang untuk mengunci rekod dan jurang mereka untuk mengelakkan rekod baru daripada dimasukkan. 2) Dalam aplikasi praktikal, dengan mengoptimumkan pertanyaan dan menyesuaikan tahap pengasingan, persaingan kunci dapat dikurangkan dan prestasi konkurensi dapat ditingkatkan.


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

Dreamweaver CS6
Alat pembangunan web visual

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

