
Rumah >applet WeChat >pembangunan WeChat >微信开发之数据访问的方法详解
微信开发之数据访问的方法详解

- Y2Jasal
- 2017-05-12 11:20:271592semak imbas
这篇文章主要介绍了微信小程序 数据访问实例详解的相关资料,需要的朋友可以参考下
先简单说一下,小程序的结构
如图所示
1、每个视图(.wxml)只需要添加对应名字的脚本(.js)和样式(.wxss)就可以了,不需要引用,page下面的脚本以及样式都是继承至最外面的app.js , app.wxcss
2、脚本也就是.js文件,他有固定格式:page,是用于获取数据的
3、utils是用来放置数据接口的
数据访问,如果懂点ajax,都不是问题,没啥好讲的
微信小程序,因为IDE太烂了,如果代码再写得难以阅读,整个项目就很难维护了。
因为没有写过app,不知道在app中数据访问是怎么封装的
作为一个有3天工作经验的小程序码农,觉得如果每个页面的数据都是自己去访问数据接口,那就太不OOP了
然后想到了linq to sql,只取了其中的两个方法,原本打算用singelordefault,firstordefault的,想想也麻烦,就用了getbyparams,getbyid,根据条件查找出所有数据,或者根据id获取一条数据
直接看方法吧,有点啰嗦了
const API_URL = 'http://localhost:4424/api/'
function getApi(url,params){
return new Promise((res,rej)=>{
wx.request({
url:API_URL+'/'+url,
data:Object.assign({},params),
header:{'Content-Type': 'application/json'},
success:res,
fail:rej
})
})
}
module.exports = {
GetByParams(url,page=1,pageSize=20,search = ''){
const params = { start: (page - 1) * pageSize, pageSize: pageSize }
return getApi(url, search ? Object.assign(params, { q: search }) : params)
.then(res => res.data)
},
GetById(url,id){
return getApi(url, id)
.then(res => res.data)
}
}module.exports = {}是固定写法,里面写一个一个的方法,每个方法用,隔开。
我设置了一个url参数,因为不可能把所有的接口都放在一个conntroller里面,所以url的格式是“conntroller/action”
看一个调用的栗子吧,就明白怎么用了
const req = require('../../utils/util.js')
Page({
data: {
imgUrls: [],
indicatorDots: true,
autoplay: true,
interval: 2000,
duration: 2000
},
onLoad(){
req.GetByParams('home/homebanner')//看这里 看这里 看这里
.then(d=>this.setData({imgUrls:d,loading:false}))
.catch(e=>{
this.setData({imgUrls:[],loading:false})
})
}
})这是index的获取banner图的方法,req.GetByParams('home/homebanner'),这里也可以带参数,也可以空着
最终的页面是这样的
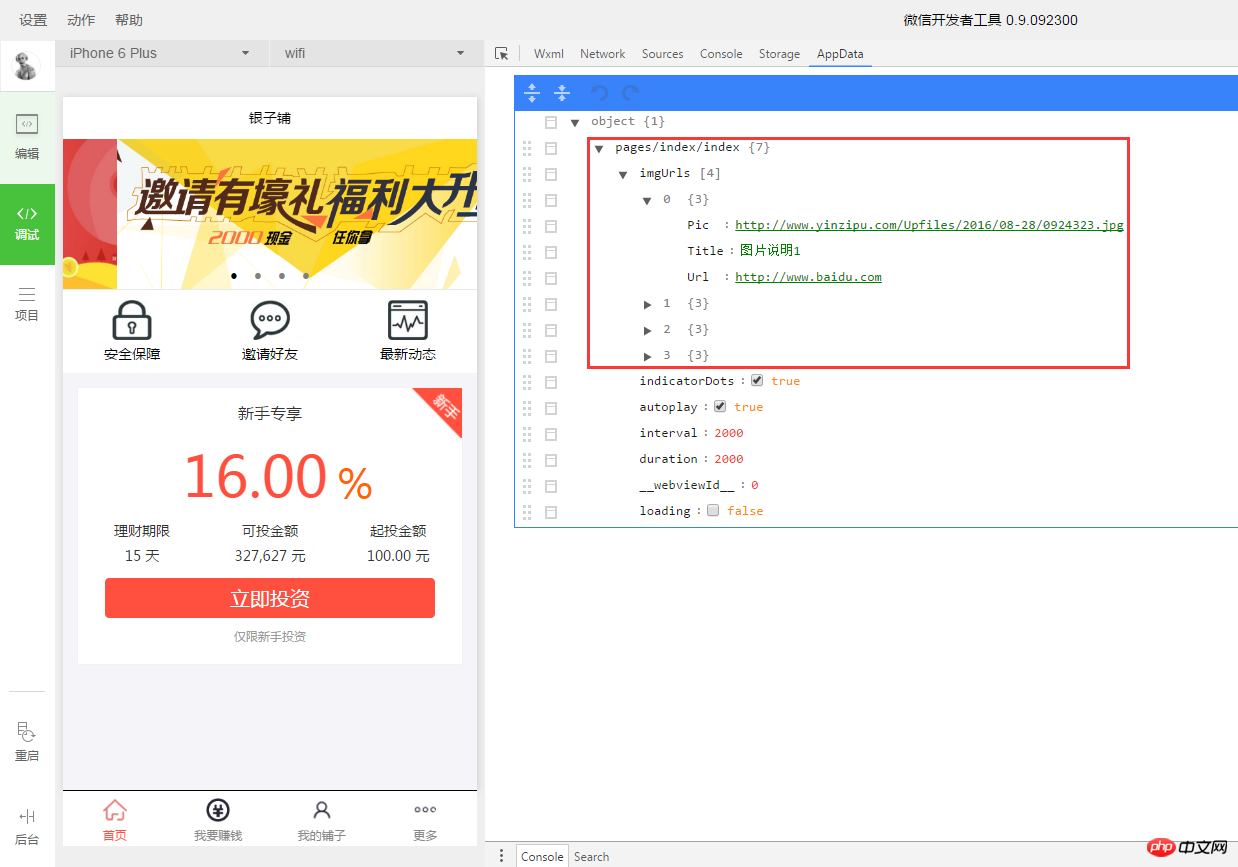
在右边的红色框里面,我们可以看到请求返回的数据,也可以在右边修改数据,界面会跟随着变化,这是关于调试的事情了,容后再议
【相关推荐】
1. 微信公众号平台源码下载
2. 微信投票源码下载
Atas ialah kandungan terperinci 微信开发之数据访问的方法详解. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!