


最近为了考试打算抓取网上的软考试题,在抓取中遇到一些问题,下面这篇文章主要介绍的是利用python爬取软考试题之ip自动代理的相关资料,文中介绍的非常详细,需要的朋友们下面来一起看看吧。
前言
最近有个软件专业等级考试,以下简称软考,为了更好的复习备考,我打算抓取www.rkpass.cn网上的软考试题。
首先讲述一下我爬取软考试题的故(keng)事(shi)。现在我已经能自动抓取某一个模块的所有题目了,如下图:
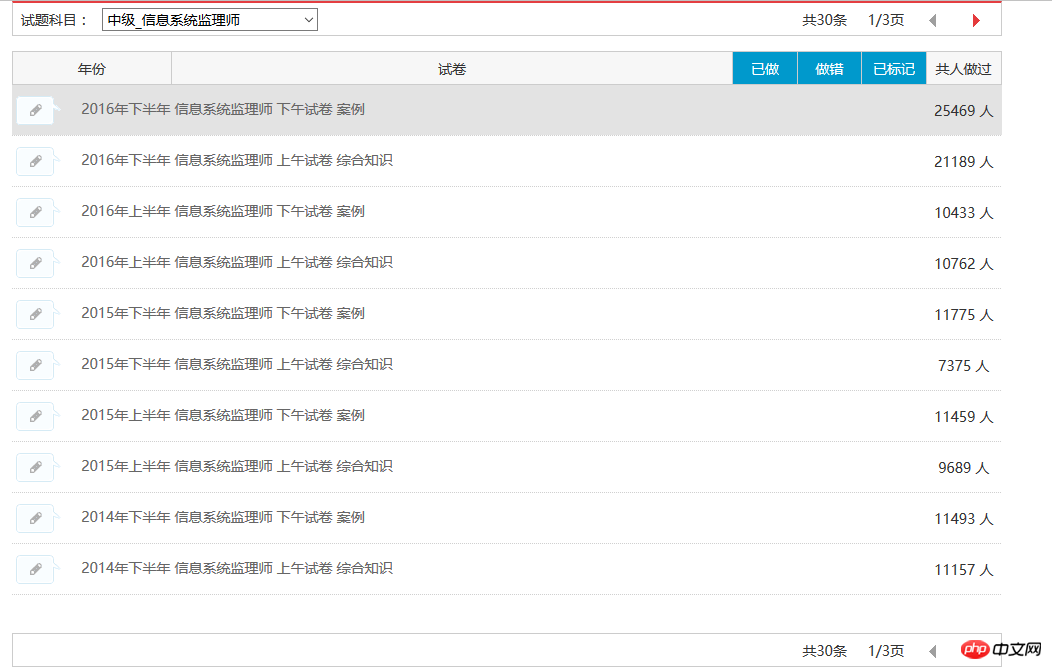
目前可以将信息系统监理师的30条试题记录全部抓取下来,结果如下图所示:
抓取下来的内容图片:

虽然可以将部分信息抓取下来,但是代码的质量并不高,以抓取信息系统监理师为例,因为目标明确,各项参数清晰,为了追求能在短时间内抓取到试卷信息,所以并没有做异常处理,昨天晚上填了很久的坑。
回到主题,今天写这篇博客,是因为又遇到新坑了。从文中标题我们可以猜出个大概,肯定是请求次数过多,所以ip被网站的反爬虫机制给封了。
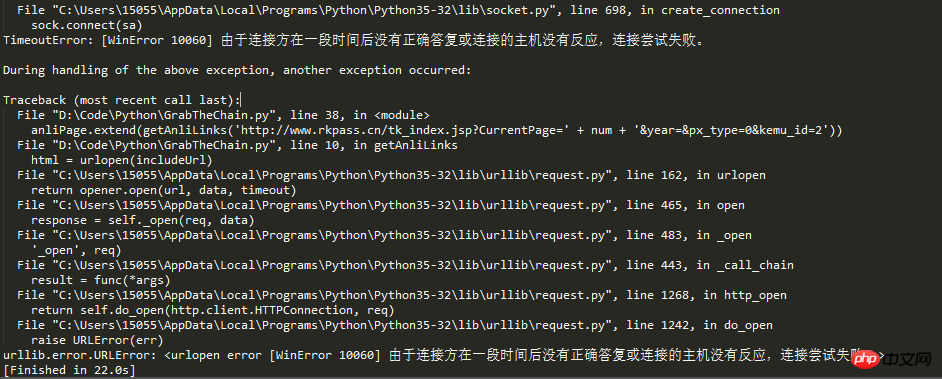
活人不能让尿憋死,革命先辈的事迹告诉我们,作为社会主义的接班人,我们不能屈服于困难,逢山开路,遇水搭桥,为了解决ip问题,ip代理这个思路就出来了。
在网络爬虫抓取信息的过程中,如果抓取频率高过了网站的设置阀值,将会被禁止访问。通常,网站的反爬虫机制都是依据IP来标识爬虫的。
于是在爬虫的开发者通常需要采取两种手段来解决这个问题:
1、放慢抓取速度,减小对于目标网站造成的压力。但是这样会减少单位时间类的抓取量。
2、第二种方法是通过设置代理IP等手段,突破反爬虫机制继续高频率抓取。但是这样需要多个稳定的代理IP。
话不多书,直接上代码:
# IP地址取自国内髙匿代理IP网站:www.xicidaili.com/nn/
# 仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
#获取当前页面上的ip
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text)
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
#从抓取到的Ip中随机获取一个ip
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
#国内高匿代理IP网主地址
url = 'http://www.xicidaili.com/nn/'
#请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
#计数器,根据计数器来循环抓取所有页面的ip
num = 0
#创建一个数组,将捕捉到的ip存放到数组
ip_array = []
while num < 1537:
num += 1
ip_list = get_ip_list(url+str(num), headers=headers)
ip_array.append(ip_list)
for ip in ip_array:
print(ip)
#创建随机数,随机取到一个ip
# proxies = get_random_ip(ip_list)
# print(proxies)运行结果截图:
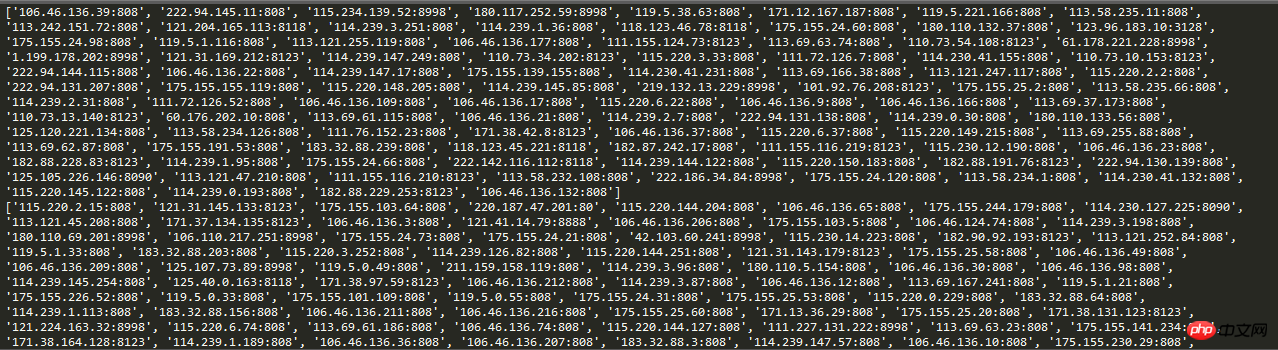
这样,在爬虫请求的时候,把请求ip设置为自动ip,就能有效的躲过反爬虫机制中简单的封锁固定ip这个手段。
-------------------------------------------------------------------------------------------------------------------------------------
为了网站的稳定,爬虫的速度大家还是控制下,毕竟站长也都不容易。本文测试只抓取了17页ip。
总结
Atas ialah kandungan terperinci python爬取技术中的ip自动代理实例. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Python: Permainan, GUI, dan banyak lagiApr 13, 2025 am 12:14 AM
Python: Permainan, GUI, dan banyak lagiApr 13, 2025 am 12:14 AMPython cemerlang dalam permainan dan pembangunan GUI. 1) Pembangunan permainan menggunakan pygame, menyediakan lukisan, audio dan fungsi lain, yang sesuai untuk membuat permainan 2D. 2) Pembangunan GUI boleh memilih tkinter atau pyqt. TKInter adalah mudah dan mudah digunakan, PYQT mempunyai fungsi yang kaya dan sesuai untuk pembangunan profesional.
 Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AM
Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AMPython sesuai untuk sains data, pembangunan web dan tugas automasi, manakala C sesuai untuk pengaturcaraan sistem, pembangunan permainan dan sistem tertanam. Python terkenal dengan kesederhanaan dan ekosistem yang kuat, manakala C dikenali dengan keupayaan kawalan dan keupayaan kawalan yang mendasari.
 Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AM
Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AMAnda boleh mempelajari konsep pengaturcaraan asas dan kemahiran Python dalam masa 2 jam. 1. Belajar Pembolehubah dan Jenis Data, 2.
 Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AM
Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AMPython digunakan secara meluas dalam bidang pembangunan web, sains data, pembelajaran mesin, automasi dan skrip. 1) Dalam pembangunan web, kerangka Django dan Flask memudahkan proses pembangunan. 2) Dalam bidang sains data dan pembelajaran mesin, numpy, panda, scikit-learn dan perpustakaan tensorflow memberikan sokongan yang kuat. 3) Dari segi automasi dan skrip, Python sesuai untuk tugas -tugas seperti ujian automatik dan pengurusan sistem.
 Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PM
Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PMAnda boleh mempelajari asas -asas Python dalam masa dua jam. 1. Belajar pembolehubah dan jenis data, 2. Struktur kawalan induk seperti jika pernyataan dan gelung, 3 memahami definisi dan penggunaan fungsi. Ini akan membantu anda mula menulis program python mudah.
 Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AM
Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AMBagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam masa 10 jam? Sekiranya anda hanya mempunyai 10 jam untuk mengajar pemula komputer beberapa pengetahuan pengaturcaraan, apa yang akan anda pilih untuk mengajar ...
 Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AM
Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AMCara mengelakkan dikesan semasa menggunakan fiddlerevery di mana untuk bacaan lelaki-dalam-pertengahan apabila anda menggunakan fiddlerevery di mana ...
 Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AM
Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AMMemuatkan Fail Pickle di Python 3.6 Kesalahan Laporan Alam Sekitar: ModulenotFoundError: Nomodulenamed ...


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

DVWA
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini

SublimeText3 versi Inggeris
Disyorkan: Versi Win, menyokong gesaan kod!

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

