



YOLO (You Only Look Once) has been a leading real-time object detection framework, with each iteration improving upon the previous versions. The latest version YOLO v12 introduces advancements that significantly enhance accuracy while maintaining real-time processing speeds. This article explores the key innovations in YOLO v12, highlighting how it surpasses the previous versions while minimizing computational costs without compromising detection efficiency.
Table of contents
- What’s New in YOLO v12?
- Key Improvements Over Previous Versions
- Computational Efficiency Enhancements
- YOLO v12 Model Variants
- Let’s compare YOLO v11 and YOLO v12 Models
- Expert Opinions on YOLOv11 and YOLOv12
- Conclusion
What’s New in YOLO v12?
Previously, YOLO models relied on Convolutional Neural Networks (CNNs) for object detection due to their speed and efficiency. However, YOLO v12 makes use of attention mechanisms, a concept widely known and used in Transformer models which allow it to recognize patterns more effectively. While attention mechanisms have originally been slow for real-time object detection, YOLO v12 somehow successfully integrates them while maintaining YOLO’s speed, leading to an Attention-Centric YOLO framework.
Key Improvements Over Previous Versions
1. Attention-Centric Framework
YOLO v12 combines the power of attention mechanisms with CNNs, resulting in a model that is both faster and more accurate. Unlike its predecessors which relied solely on CNNs, YOLO v12 introduces optimized attention modules to improve object recognition without adding unnecessary latency.
2. Superior Performance Metrics
Comparing performance metrics across different YOLO versions and real-time detection models reveals that YOLO v12 achieves higher accuracy while maintaining low latency.
- The mAP (Mean Average Precision) values on datasets like COCO show YOLO v12 outperforming YOLO v11 and YOLO v10 while maintaining comparable speed.
- The model achieves a remarkable 40.6% accuracy (mAP) while processing images in just 1.64 milliseconds on an Nvidia T4 GPU. This performance is superior to YOLO v10 and YOLO v11 without sacrificing speed.
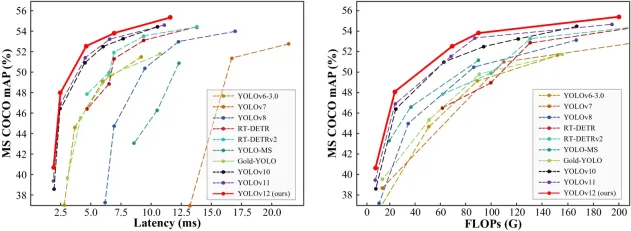
3. Outperforming Non-YOLO Models
YOLO v12 surpasses previous YOLO versions; it also outperforms other real-time object detection frameworks, such as RT-Det and RT-Det v2. These alternative models have higher latency yet fail to match YOLO v12’s accuracy.
Computational Efficiency Enhancements
One of the major concerns with integrating attention mechanisms into YOLO models was their high computational cost (Attention Mechanism) and memory inefficiency. YOLO v12 addresses these issues through several key innovations:
1. Flash Attention for Memory Efficiency
Traditional attention mechanisms consume a large amount of memory, making them impractical for real-time applications. YOLO v12 introduces Flash Attention, a technique that reduces memory consumption and speeds up inference time.
2. Area Attention for Lower Computation Cost
To further optimize efficiency, YOLO v12 employs Area Attention, which focuses only on relevant regions of an image instead of processing the entire feature map. This technique dramatically reduces computation costs while retaining accuracy.

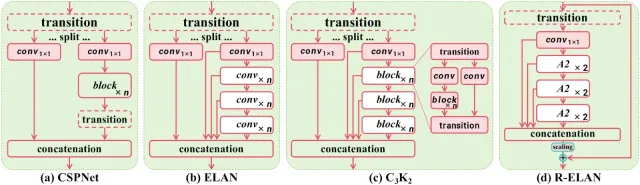
3. R-ELAN for Optimized Feature Processing
YOLO v12 also introduces R-ELAN (Re-Engineered ELAN), which optimizes feature propagation making the model more efficient in handling complex object detection tasks without increasing computational demands.
YOLO v12 Model Variants
YOLO v12 comes in five different variants, catering to different applications:
- N (Nano) & S (Small): Designed for real-time applications where speed is crucial.
- M (Medium): Balances accuracy and speed, suitable for general-purpose tasks.
- L (Large) & XL (Extra Large): Optimized for high-precision tasks where accuracy is prioritized over speed.
Also read:
- A Step-by-Step Introduction to the Basic Object Detection Algorithms (Part 1)
- A Practical Implementation of the Faster R-CNN Algorithm for Object Detection (Part 2)
- A Practical Guide to Object Detection using the Popular YOLO Framework – Part III (with Python codes)
Let’s compare YOLO v11 and YOLO v12 Models
We’ll be experimenting with YOLO v11 and YOLO v12 small models to understand their performance across various tasks like object counting, heatmaps, and speed estimation.
1. Object Counting
YOLO v11
import cv2
from ultralytics import solutions
cap = cv2.VideoCapture("highway.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)), int(cap.get(cv2.CAP_PROP_FPS)))
# Define region points
region_points = [(20, 1500), (1080, 1500), (1080, 1460), (20, 1460)] # Lower rectangle region counting
# Video writer (MP4 format)
video_writer = cv2.VideoWriter("object_counting_output.mp4", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
# Init ObjectCounter
counter = solutions.ObjectCounter(
show=False, # Disable internal window display
region=region_points,
model="yolo11s.pt",
)
# Process video
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
im0 = counter.count(im0)
# Resize to fit screen (optional — scale down for large videos)
im0_resized = cv2.resize(im0, (640, 360)) # Adjust resolution as needed
# Show the resized frame
cv2.imshow("Object Counting", im0_resized)
video_writer.write(im0)
# Press 'q' to exit
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
video_writer.release()
cv2.destroyAllWindows()
Output
YOLO v12
import cv2
from ultralytics import solutions
cap = cv2.VideoCapture("highway.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)), int(cap.get(cv2.CAP_PROP_FPS)))
# Define region points
region_points = [(20, 1500), (1080, 1500), (1080, 1460), (20, 1460)] # Lower rectangle region counting
# Video writer (MP4 format)
video_writer = cv2.VideoWriter("object_counting_output.mp4", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
# Init ObjectCounter
counter = solutions.ObjectCounter(
show=False, # Disable internal window display
region=region_points,
model="yolo12s.pt",
)
# Process video
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
im0 = counter.count(im0)
# Resize to fit screen (optional — scale down for large videos)
im0_resized = cv2.resize(im0, (640, 360)) # Adjust resolution as needed
# Show the resized frame
cv2.imshow("Object Counting", im0_resized)
video_writer.write(im0)
# Press 'q' to exit
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
video_writer.release()
cv2.destroyAllWindows()
Output
2. Heatmaps
YOLO v11
import cv2
from ultralytics import solutions
cap = cv2.VideoCapture("mall_arial.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
# Video writer
video_writer = cv2.VideoWriter("heatmap_output_yolov11.mp4", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
# In case you want to apply object counting + heatmaps, you can pass region points.
# region_points = [(20, 400), (1080, 400)] # Define line points
# region_points = [(20, 400), (1080, 400), (1080, 360), (20, 360)] # Define region points
# region_points = [(20, 400), (1080, 400), (1080, 360), (20, 360), (20, 400)] # Define polygon points
# Init heatmap
heatmap = solutions.Heatmap(
show=True, # Display the output
model="yolo11s.pt", # Path to the YOLO11 model file
colormap=cv2.COLORMAP_PARULA, # Colormap of heatmap
# region=region_points, # If you want to do object counting with heatmaps, you can pass region_points
# classes=[0, 2], # If you want to generate heatmap for specific classes i.e person and car.
# show_in=True, # Display in counts
# show_out=True, # Display out counts
# line_width=2, # Adjust the line width for bounding boxes and text display
)
# Process video
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
im0 = heatmap.generate_heatmap(im0)
im0_resized = cv2.resize(im0, (w, h))
video_writer.write(im0_resized)
cap.release()
video_writer.release()
cv2.destroyAllWindows()
Output
YOLO v12
import cv2
from ultralytics import solutions
cap = cv2.VideoCapture("mall_arial.mp4")
assert cap.isOpened(), "Error reading video file"
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
# Video writer
video_writer = cv2.VideoWriter("heatmap_output_yolov12.mp4", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
# In case you want to apply object counting + heatmaps, you can pass region points.
# region_points = [(20, 400), (1080, 400)] # Define line points
# region_points = [(20, 400), (1080, 400), (1080, 360), (20, 360)] # Define region points
# region_points = [(20, 400), (1080, 400), (1080, 360), (20, 360), (20, 400)] # Define polygon points
# Init heatmap
heatmap = solutions.Heatmap(
show=True, # Display the output
model="yolo12s.pt", # Path to the YOLO11 model file
colormap=cv2.COLORMAP_PARULA, # Colormap of heatmap
# region=region_points, # If you want to do object counting with heatmaps, you can pass region_points
# classes=[0, 2], # If you want to generate heatmap for specific classes i.e person and car.
# show_in=True, # Display in counts
# show_out=True, # Display out counts
# line_width=2, # Adjust the line width for bounding boxes and text display
)
# Process video
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
im0 = heatmap.generate_heatmap(im0)
im0_resized = cv2.resize(im0, (w, h))
video_writer.write(im0_resized)
cap.release()
video_writer.release()
cv2.destroyAllWindows()
Output
3. Speed Estimation
YOLO v11
import cv2
from ultralytics import solutions
import numpy as np
cap = cv2.VideoCapture("cars_on_road.mp4")
assert cap.isOpened(), "Error reading video file"
# Capture video properties
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(cap.get(cv2.CAP_PROP_FPS))
# Video writer
video_writer = cv2.VideoWriter("speed_management_yolov11.mp4", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
# Define speed region points (adjust for your video resolution)
speed_region = [(300, h - 200), (w - 100, h - 200), (w - 100, h - 270), (300, h - 270)]
# Initialize SpeedEstimator
speed = solutions.SpeedEstimator(
show=False, # Disable internal window display
model="yolo11s.pt", # Path to the YOLO model file
region=speed_region, # Pass region points
# classes=[0, 2], # Optional: Filter specific object classes (e.g., cars, trucks)
# line_width=2, # Optional: Adjust the line width
)
# Process video
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
# Estimate speed and draw bounding boxes
out = speed.estimate_speed(im0)
# Draw the speed region on the frame
cv2.polylines(out, [np.array(speed_region)], isClosed=True, color=(0, 255, 0), thickness=2)
# Resize the frame to fit the screen
im0_resized = cv2.resize(out, (1280, 720)) # Resize for better screen fit
# Show the resized frame
cv2.imshow("Speed Estimation", im0_resized)
video_writer.write(out)
# Press 'q' to exit
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
video_writer.release()
cv2.destroyAllWindows()
Output
YOLO v12
import cv2
from ultralytics import solutions
import numpy as np
cap = cv2.VideoCapture("cars_on_road.mp4")
assert cap.isOpened(), "Error reading video file"
# Capture video properties
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = int(cap.get(cv2.CAP_PROP_FPS))
# Video writer
video_writer = cv2.VideoWriter("speed_management_yolov12.mp4", cv2.VideoWriter_fourcc(*"mp4v"), fps, (w, h))
# Define speed region points (adjust for your video resolution)
speed_region = [(300, h - 200), (w - 100, h - 200), (w - 100, h - 270), (300, h - 270)]
# Initialize SpeedEstimator
speed = solutions.SpeedEstimator(
show=False, # Disable internal window display
model="yolo12s.pt", # Path to the YOLO model file
region=speed_region, # Pass region points
# classes=[0, 2], # Optional: Filter specific object classes (e.g., cars, trucks)
# line_width=2, # Optional: Adjust the line width
)
# Process video
while cap.isOpened():
success, im0 = cap.read()
if not success:
print("Video frame is empty or video processing has been successfully completed.")
break
# Estimate speed and draw bounding boxes
out = speed.estimate_speed(im0)
# Draw the speed region on the frame
cv2.polylines(out, [np.array(speed_region)], isClosed=True, color=(0, 255, 0), thickness=2)
# Resize the frame to fit the screen
im0_resized = cv2.resize(out, (1280, 720)) # Resize for better screen fit
# Show the resized frame
cv2.imshow("Speed Estimation", im0_resized)
video_writer.write(out)
# Press 'q' to exit
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
video_writer.release()
cv2.destroyAllWindows()
Output
Also Read: Top 30+ Computer Vision Models For 2025
Expert Opinions on YOLOv11 and YOLOv12
Muhammad Rizwan Munawar — Computer Vision Engineer at Ultralytics
“YOLOv12 introduces flash attention, which enhances accuracy, but it requires careful CUDA setup. It’s a solid step forward, especially for complex detection tasks, though YOLOv11 remains faster for real-time needs. In short, choose YOLOv12 for accuracy and YOLOv11 for speed.”
Linkedin Post – Is YOLOv12 really a state-of-the-art model? ?
Muhammad Rizwan, recently tested YOLOv11 and YOLOv12 side by side to break down their real-world performance. His findings highlight the trade-offs between the two models:
- Frames Per Second (FPS): YOLOv11 maintains an average of 40 FPS, while YOLOv12 lags behind at 30 FPS. This makes YOLOv11 the better choice for real-time applications where speed is critical, such as traffic monitoring or live video feeds.
- Training Time: YOLOv12 takes about 20% longer to train than YOLOv11. On a small dataset with 130 training images and 43 validation images, YOLOv11 completed training in 0.009 hours, while YOLOv12 needed 0.011 hours. While this might seem minor for small datasets, the difference becomes significant for larger-scale projects.
- Accuracy: Both models achieved similar accuracy after fine-tuning for 10 epochs on the same dataset. YOLOv12 didn’t dramatically outperform YOLOv11 in terms of accuracy, suggesting the newer model’s improvements lie more in architectural enhancements than raw detection precision.
- Flash Attention: YOLOv12 introduces flash attention, a powerful mechanism that speeds up and optimizes attention layers. However, there’s a catch — this feature isn’t natively supported on the CPU, and enabling it with CUDA requires careful version-specific setup. For teams without powerful GPUs or those working on edge devices, this can become a roadblock.
The PC specifications used for testing:
- GPU: NVIDIA RTX 3050
- CPU: Intel Core-i5-10400 @2.90GHz
- RAM: 64 GB
The model specifications:
- Model = YOLO11n.pt and YOLOv12n.pt
- Image size = 640 for inference
Conclusion
YOLO v12 marks a significant leap forward in real-time object detection, combining CNN speed with Transformer-like attention mechanisms. With improved accuracy, lower computational costs, and a range of model variants, YOLO v12 is poised to redefine the landscape of real-time vision applications. Whether for autonomous vehicles, security surveillance, or medical imaging, YOLO v12 sets a new standard for real-time object detection efficiency.
What’s Next?
- YOLO v13 Possibilities: Will future versions push the attention mechanisms even further?
- Edge Device Optimization: Can Flash Attention or Area Attention be optimized for lower-power devices?
To help you better understand the differences, I’ve attached some code snippets and output results in the comparison section. These examples illustrate how both YOLOv11 and YOLOv12 perform in real-world scenarios, from object counting to speed estimation and heatmaps. I’m excited to see how you guys perceive this new release! Are the improvements in accuracy and attention mechanisms enough to justify the trade-offs in speed? Or do you think YOLOv11 still holds its ground for most applications?
Atas ialah kandungan terperinci Bagaimana cara menggunakan Yolo V12 untuk pengesanan objek?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Carta 10 kuasa bi yang paling banyak digunakan - Analytics VidhyaApr 16, 2025 pm 12:05 PM
Carta 10 kuasa bi yang paling banyak digunakan - Analytics VidhyaApr 16, 2025 pm 12:05 PMMemanfaatkan kekuatan visualisasi data dengan carta Microsoft Power BI Dalam dunia yang didorong oleh data hari ini, dengan berkesan menyampaikan maklumat yang rumit kepada penonton bukan teknikal adalah penting. Visualisasi data jambatan jurang ini, mengubah data mentah i
 Sistem Pakar di AIApr 16, 2025 pm 12:00 PM
Sistem Pakar di AIApr 16, 2025 pm 12:00 PMSistem Pakar: menyelam yang mendalam ke dalam kuasa membuat keputusan AI Bayangkan mempunyai akses kepada nasihat pakar mengenai apa -apa, dari diagnosis perubatan kepada perancangan kewangan. Itulah kuasa sistem pakar dalam kecerdasan buatan. Sistem ini meniru pro
 Tiga coder getaran terbaik memecahkan revolusi AI ini dalam kodApr 16, 2025 am 11:58 AM
Tiga coder getaran terbaik memecahkan revolusi AI ini dalam kodApr 16, 2025 am 11:58 AMPertama sekali, jelas bahawa ini berlaku dengan cepat. Pelbagai syarikat bercakap mengenai perkadaran kod mereka yang kini ditulis oleh AI, dan ini semakin meningkat pada klip pesat. Terdapat banyak anjakan pekerjaan
 Runway AI's Gen-4: Bagaimanakah montaj AI boleh melampaui kebodohanApr 16, 2025 am 11:45 AM
Runway AI's Gen-4: Bagaimanakah montaj AI boleh melampaui kebodohanApr 16, 2025 am 11:45 AMIndustri filem, bersama semua sektor kreatif, dari pemasaran digital ke media sosial, berdiri di persimpangan teknologi. Sebagai kecerdasan buatan mula membentuk semula setiap aspek bercerita visual dan mengubah landskap hiburan
 Bagaimana untuk mendaftar selama 5 hari kursus percuma ISRO AI? - Analytics VidhyaApr 16, 2025 am 11:43 AM
Bagaimana untuk mendaftar selama 5 hari kursus percuma ISRO AI? - Analytics VidhyaApr 16, 2025 am 11:43 AMKursus Online AI/ML percuma ISRO: Gerbang ke Inovasi Teknologi Geospatial Pertubuhan Penyelidikan Angkasa India (ISRO), melalui Institut Pengesan Jauh India (IIRS), menawarkan peluang yang hebat untuk pelajar dan profesional
 Algoritma Carian Tempatan di AIApr 16, 2025 am 11:40 AM
Algoritma Carian Tempatan di AIApr 16, 2025 am 11:40 AMAlgoritma Carian Tempatan: Panduan Komprehensif Merancang acara berskala besar memerlukan pengagihan beban kerja yang cekap. Apabila pendekatan tradisional gagal, algoritma carian tempatan menawarkan penyelesaian yang kuat. Artikel ini meneroka pendakian bukit dan simul
 Terbuka beralih fokus dengan GPT-4.1, mengutamakan pengekodan dan kecekapan kosApr 16, 2025 am 11:37 AM
Terbuka beralih fokus dengan GPT-4.1, mengutamakan pengekodan dan kecekapan kosApr 16, 2025 am 11:37 AMPelepasan ini termasuk tiga model yang berbeza, GPT-4.1, GPT-4.1 Mini dan GPT-4.1 Nano, menandakan langkah ke arah pengoptimuman khusus tugas dalam landskap model bahasa yang besar. Model-model ini tidak segera menggantikan antara muka yang dihadapi pengguna seperti
 Prompt: CHATGPT menjana pasport palsuApr 16, 2025 am 11:35 AM
Prompt: CHATGPT menjana pasport palsuApr 16, 2025 am 11:35 AMGergasi Chip Nvidia berkata pada hari Isnin ia akan memulakan pembuatan superkomputer AI - mesin yang boleh memproses sejumlah besar data dan menjalankan algoritma kompleks - sepenuhnya dalam A.S. untuk kali pertama. Pengumuman itu datang selepas Presiden Trump Si


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)

PhpStorm versi Mac
Alat pembangunan bersepadu PHP profesional terkini (2018.2.1).

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

