


Metrik Ralat untuk Algoritma Regresi
Apabila kami mencipta algoritma regresi dan ingin mengetahui sejauh mana keberkesanan model ini, kami menggunakan metrik ralat untuk mendapatkan nilai yang mewakili ralat model pembelajaran mesin kami. Metrik dalam artikel ini penting apabila kita ingin mengukur ralat model ramalan untuk nilai berangka (nyata, integer).
Dalam artikel ini kami akan merangkumi metrik ralat utama untuk algoritma regresi, melakukan pengiraan secara manual dalam Python dan mengukur ralat model pembelajaran mesin pada set data sebut harga dolar.
Metrik Diatasi
- SE — Jumlah ralat
- SAYA — Min ralat
- MAE — Min Ralat Mutlak
- MPE — Ralat Peratusan Min
- MAPAE — Ralat Peratusan Mutlak Min
Kedua-dua metrik adalah sedikit serupa, di mana kami mempunyai metrik untuk purata dan peratusan ralat dan metrik untuk purata dan peratusan ralat mutlak, dibezakan supaya hanya satu kumpulan memperoleh nilai sebenar perbezaan dan satu lagi memperoleh nilai mutlak daripada perbezaan. Adalah penting untuk diingat bahawa dalam kedua-dua metrik, lebih rendah nilai, lebih baik ramalan kami.
SE — Jumlah ralat
Metrik SE adalah yang paling mudah antara semua dalam artikel ini, dengan formulanya ialah:
SE = εR — P
Oleh itu, ia adalah jumlah perbezaan antara nilai sebenar (pembolehubah sasaran model) dan nilai ramalan. Metrik ini mempunyai beberapa mata negatif, seperti tidak menganggap nilai sebagai mutlak, yang seterusnya akan menghasilkan nilai palsu.
SAYA — Makna kesilapan
Metrik ME ialah "pelengkap" SE, di mana kita pada asasnya mempunyai perbezaan bahawa kita akan memperoleh purata SE memandangkan bilangan elemen:
ME = ε(R-P)/N
Tidak seperti SE, kami hanya membahagikan hasil SE dengan bilangan elemen. Metrik ini, seperti SE, bergantung pada skala, iaitu, kita mesti menggunakan set data yang sama dan boleh membandingkan dengan model ramalan yang berbeza.
MAE — Min ralat mutlak
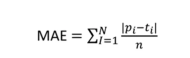
Metrik MAE ialah ME tetapi hanya mengambil kira nilai mutlak (bukan negatif). Apabila kita mengira perbezaan antara sebenar dan ramalan, kita mungkin mempunyai keputusan negatif dan perbezaan negatif ini digunakan pada metrik sebelumnya. Dalam metrik ini, kita perlu mengubah perbezaan menjadi nilai positif dan kemudian mengambil purata berdasarkan bilangan elemen.
MPE — Ralat Peratusan Min
Metrik MPE ialah ralat purata sebagai peratusan daripada jumlah setiap perbezaan. Di sini kita perlu mengambil peratusan perbezaan, menambahnya dan kemudian membahagikannya dengan bilangan elemen untuk mendapatkan purata. Oleh itu, perbezaan antara nilai sebenar dan nilai ramalan dibuat, dibahagikan dengan nilai sebenar, didarab dengan 100, kami menjumlahkan semua peratusan ini dan membahagikan dengan bilangan elemen. Metrik ini bebas daripada skala (%).
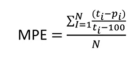
MAPAE — Ralat Peratusan Mutlak Min
Metrik MAPAE sangat serupa dengan metrik sebelumnya, tetapi perbezaan antara ramalan x sebenar dibuat secara mutlak, iaitu, anda mengiranya dengan nilai positif. Oleh itu, metrik ini ialah perbezaan mutlak dalam peratusan ralat. Metrik ini juga bebas skala.
Menggunakan metrik dalam amalan
Memandangkan penjelasan setiap metrik, kami akan mengira kedua-duanya secara manual dalam Python berdasarkan ramalan daripada model pembelajaran mesin kadar pertukaran dolar. Pada masa ini, kebanyakan metrik regresi wujud dalam fungsi sedia dalam pakej Sklearn, namun di sini kami akan mengiranya secara manual untuk tujuan pengajaran sahaja.

Kami akan menggunakan algoritma RandomForest dan Decision Tree sahaja untuk membandingkan hasil antara kedua-dua model.

Analisis Data
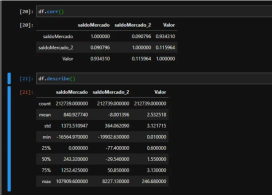
Dalam set data kami, kami mempunyai lajur SaldoMercado dan saldoMercado_2 yang merupakan maklumat yang mempengaruhi lajur Nilai (sebut harga dolar kami). Seperti yang dapat kita lihat, baki MercadoMercado mempunyai hubungan yang lebih rapat dengan sebut harga berbanding baki Merado_2. Anda juga boleh melihat bahawa kami tidak mempunyai nilai yang hilang (nilai tak terhingga atau Nan) dan lajur balanceMercado_2 mempunyai banyak nilai bukan mutlak.
Penyediaan Model
Kami menyediakan nilai kami untuk model pembelajaran mesin dengan mentakrifkan pembolehubah peramal dan pembolehubah yang ingin kami ramalkan. Kami menggunakan train_test_split untuk membahagikan data secara rawak kepada 30% untuk ujian dan 70% untuk latihan.


Akhir sekali, kami memulakan kedua-dua algoritma (RandomForest dan DecisionTree), menyesuaikan data dan mengukur skor kedua-duanya dengan data ujian. Kami memperoleh skor 83% untuk TreeRegressor dan 90% untuk ForestRegressor, yang secara teori menunjukkan bahawa ForestRegressor berprestasi lebih baik.



Keputusan dan Analisis
Memandangkan prestasi ForestRegressor yang diperhatikan separa, kami mencipta set data dengan data yang diperlukan untuk menggunakan metrik. Kami melakukan ramalan pada data ujian dan mencipta DataFrame dengan nilai sebenar dan ramalan, termasuk lajur untuk perbezaan dan peratusan.
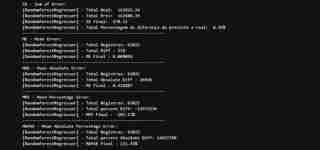
Kami dapat melihat bahawa berhubung dengan jumlah sebenar kadar dolar berbanding kadar yang diramalkan oleh model kami:
- Kami mempunyai jumlah perbezaan R$578.00
- Ini mewakili 0.36% perbezaan antara ramalan x Sebenar (tidak dianggap nilai mutlak)
- Dari segi purata ralat (ME) kami mempunyai nilai yang rendah, purata R$0.009058
- Untuk purata mutlak, nilai ini meningkat sedikit kerana kami mempunyai nilai negatif dalam set data kami
Saya menegaskan bahawa di sini kami melakukan pengiraan secara manual untuk tujuan pengajaran. Walau bagaimanapun, adalah disyorkan untuk menggunakan fungsi metrik daripada pakej Sklearn kerana prestasi yang lebih baik dan kemungkinan ralat yang rendah dalam pengiraan.
Kod lengkap tersedia di GitHub saya: github.com/AirtonLira/artigo_metricasregressao
Pengarang: Airton Lira Junior
LinkedIn: linkedin.com/in/airton-lira-junior-6b81a661/
Atas ialah kandungan terperinci Metrik untuk algoritma regresi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Python: Automasi, skrip, dan pengurusan tugasApr 16, 2025 am 12:14 AM
Python: Automasi, skrip, dan pengurusan tugasApr 16, 2025 am 12:14 AMPython cemerlang dalam automasi, skrip, dan pengurusan tugas. 1) Automasi: Sandaran fail direalisasikan melalui perpustakaan standard seperti OS dan Shutil. 2) Penulisan Skrip: Gunakan Perpustakaan Psutil untuk memantau sumber sistem. 3) Pengurusan Tugas: Gunakan perpustakaan jadual untuk menjadualkan tugas. Kemudahan penggunaan Python dan sokongan perpustakaan yang kaya menjadikannya alat pilihan di kawasan ini.
 Python dan Masa: Memanfaatkan masa belajar andaApr 14, 2025 am 12:02 AM
Python dan Masa: Memanfaatkan masa belajar andaApr 14, 2025 am 12:02 AMUntuk memaksimumkan kecekapan pembelajaran Python dalam masa yang terhad, anda boleh menggunakan modul, masa, dan modul Python. 1. Modul DateTime digunakan untuk merakam dan merancang masa pembelajaran. 2. Modul Masa membantu menetapkan kajian dan masa rehat. 3. Modul Jadual secara automatik mengatur tugas pembelajaran mingguan.
 Python: Permainan, GUI, dan banyak lagiApr 13, 2025 am 12:14 AM
Python: Permainan, GUI, dan banyak lagiApr 13, 2025 am 12:14 AMPython cemerlang dalam permainan dan pembangunan GUI. 1) Pembangunan permainan menggunakan pygame, menyediakan lukisan, audio dan fungsi lain, yang sesuai untuk membuat permainan 2D. 2) Pembangunan GUI boleh memilih tkinter atau pyqt. TKInter adalah mudah dan mudah digunakan, PYQT mempunyai fungsi yang kaya dan sesuai untuk pembangunan profesional.
 Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AM
Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AMPython sesuai untuk sains data, pembangunan web dan tugas automasi, manakala C sesuai untuk pengaturcaraan sistem, pembangunan permainan dan sistem tertanam. Python terkenal dengan kesederhanaan dan ekosistem yang kuat, manakala C dikenali dengan keupayaan kawalan dan keupayaan kawalan yang mendasari.
 Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AM
Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AMAnda boleh mempelajari konsep pengaturcaraan asas dan kemahiran Python dalam masa 2 jam. 1. Belajar Pembolehubah dan Jenis Data, 2.
 Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AM
Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AMPython digunakan secara meluas dalam bidang pembangunan web, sains data, pembelajaran mesin, automasi dan skrip. 1) Dalam pembangunan web, kerangka Django dan Flask memudahkan proses pembangunan. 2) Dalam bidang sains data dan pembelajaran mesin, numpy, panda, scikit-learn dan perpustakaan tensorflow memberikan sokongan yang kuat. 3) Dari segi automasi dan skrip, Python sesuai untuk tugas -tugas seperti ujian automatik dan pengurusan sistem.
 Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PM
Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PMAnda boleh mempelajari asas -asas Python dalam masa dua jam. 1. Belajar pembolehubah dan jenis data, 2. Struktur kawalan induk seperti jika pernyataan dan gelung, 3 memahami definisi dan penggunaan fungsi. Ini akan membantu anda mula menulis program python mudah.
 Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AM
Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AMBagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam masa 10 jam? Sekiranya anda hanya mempunyai 10 jam untuk mengajar pemula komputer beberapa pengetahuan pengaturcaraan, apa yang akan anda pilih untuk mengajar ...


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

