
 pembangunan bahagian belakangTutorial PythonJanus B: Model Bersatu untuk Pemahaman Multimodal dan Tugasan Penjanaan
pembangunan bahagian belakangTutorial PythonJanus B: Model Bersatu untuk Pemahaman Multimodal dan Tugasan Penjanaan
Janus 1.3B
Janus ialah rangka kerja autoregresif baharu yang menyepadukan pemahaman dan penjanaan pelbagai mod. Tidak seperti model sebelumnya, yang menggunakan pengekod visual tunggal untuk tugas pemahaman dan penjanaan, Janus memperkenalkan dua laluan pengekodan visual yang berasingan untuk fungsi ini.
Perbezaan dalam Pengekodan untuk Pemahaman dan Penjanaan
- Dalam tugas pemahaman multimodal, pengekod visual mengekstrak maklumat semantik peringkat tinggi seperti kategori objek dan atribut visual. Pengekod ini memfokuskan pada menyimpulkan makna yang kompleks, menekankan elemen semantik dimensi lebih tinggi.
- Sebaliknya, dalam tugas penjanaan visual, penekanan diberikan pada penjanaan butiran halus dan mengekalkan konsistensi keseluruhan. Akibatnya, pengekodan dimensi lebih rendah yang boleh menangkap struktur dan tekstur spatial diperlukan.
Menyediakan Persekitaran
Berikut ialah langkah untuk menjalankan Janus dalam Google Colab:
git clone https://github.com/deepseek-ai/Janus cd Janus pip install -e . # If needed, install the following as well # pip install wheel # pip install flash-attn --no-build-isolation
Tugas Penglihatan
Memuatkan Model
Gunakan kod berikut untuk memuatkan model yang diperlukan untuk tugas penglihatan:
import torch from transformers import AutoModelForCausalLM from janus.models import MultiModalityCausalLM, VLChatProcessor from janus.utils.io import load_pil_images # Specify the model path model_path = "deepseek-ai/Janus-1.3B" vl_chat_processor = VLChatProcessor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer vl_gpt = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True) vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
Memuatkan dan Menyediakan Imej untuk Pengekodan
Seterusnya, muatkan imej dan tukarkannya kepada format yang boleh difahami oleh model:
conversation = [
{
"role": "User",
"content": "<image_placeholder>\nDescribe this chart.",
"images": ["images/pie_chart.png"],
},
{"role": "Assistant", "content": ""},
]
# Load the image and prepare input
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device)
# Run the image encoder and obtain image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
</image_placeholder>
Menjana Tindak Balas
Akhir sekali, jalankan model untuk menjana respons:
# Run the model and generate a response
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
)
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)
Contoh Output
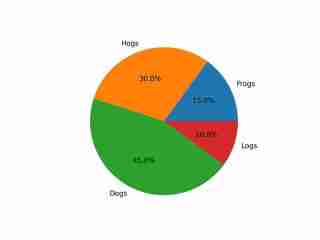
The image depicts a pie chart that illustrates the distribution of four different categories among four distinct groups. The chart is divided into four segments, each representing a category with a specific percentage. The categories and their corresponding percentages are as follows: 1. **Hogs**: This segment is colored in orange and represents 30.0% of the total. 2. **Frog**: This segment is colored in blue and represents 15.0% of the total. 3. **Logs**: This segment is colored in red and represents 10.0% of the total. 4. **Dogs**: This segment is colored in green and represents 45.0% of the total. The pie chart is visually divided into four segments, each with a different color and corresponding percentage. The segments are arranged in a clockwise manner starting from the top-left, moving clockwise. The percentages are clearly labeled next to each segment. The chart is a simple visual representation of data, where the size of each segment corresponds to the percentage of the total category it represents. This type of chart is commonly used to compare the proportions of different categories in a dataset. To summarize, the pie chart shows the following: - Hogs: 30.0% - Frog: 15.0% - Logs: 10.0% - Dogs: 45.0% This chart can be used to understand the relative proportions of each category in the given dataset.
Output menunjukkan pemahaman yang sesuai tentang imej, termasuk warna dan teksnya.
Tugas Penjanaan Imej
Memuatkan Model
Muatkan model yang diperlukan untuk tugas penjanaan imej dengan kod berikut:
import os import PIL.Image import torch import numpy as np from transformers import AutoModelForCausalLM from janus.models import MultiModalityCausalLM, VLChatProcessor # Specify the model path model_path = "deepseek-ai/Janus-1.3B" vl_chat_processor = VLChatProcessor.from_pretrained(model_path) tokenizer = vl_chat_processor.tokenizer vl_gpt = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True) vl_gpt = vl_gpt.to(torch.bfloat16).cuda().eval()
Menyediakan Prompt
Seterusnya, sediakan gesaan berdasarkan permintaan pengguna:
# Set up the prompt
conversation = [
{
"role": "User",
"content": "cute japanese girl, wearing a bikini, in a beach",
},
{"role": "Assistant", "content": ""},
]
# Convert the prompt into the appropriate format
sft_format = vl_chat_processor.apply_sft_template_for_multi_turn_prompts(
conversations=conversation,
sft_format=vl_chat_processor.sft_format,
system_prompt="",
)
prompt = sft_format + vl_chat_processor.image_start_tag
Menjana Imej
Fungsi berikut digunakan untuk menjana imej. Secara lalai, 16 imej dijana:
@torch.inference_mode()
def generate(
mmgpt: MultiModalityCausalLM,
vl_chat_processor: VLChatProcessor,
prompt: str,
temperature: float = 1,
parallel_size: int = 16,
cfg_weight: float = 5,
image_token_num_per_image: int = 576,
img_size: int = 384,
patch_size: int = 16,
):
input_ids = vl_chat_processor.tokenizer.encode(prompt)
input_ids = torch.LongTensor(input_ids)
tokens = torch.zeros((parallel_size*2, len(input_ids)), dtype=torch.int).cuda()
for i in range(parallel_size*2):
tokens[i, :] = input_ids
if i % 2 != 0:
tokens[i, 1:-1] = vl_chat_processor.pad_id
inputs_embeds = mmgpt.language_model.get_input_embeddings()(tokens)
generated_tokens = torch.zeros((parallel_size, image_token_num_per_image), dtype=torch.int).cuda()
for i in range(image_token_num_per_image):
outputs = mmgpt.language_model.model(
inputs_embeds=inputs_embeds,
use_cache=True,
past_key_values=outputs.past_key_values if i != 0 else None,
)
hidden_states = outputs.last_hidden_state
logits = mmgpt.gen_head(hidden_states[:, -1, :])
logit_cond = logits[0::2, :]
logit_uncond = logits[1::2, :]
logits = logit_uncond + cfg_weight * (logit_cond - logit_uncond)
probs = torch.softmax(logits / temperature, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
generated_tokens[:, i] = next_token.squeeze(dim=-1)
next_token = torch.cat([next_token.unsqueeze(dim=1), next_token.unsqueeze(dim=1)], dim=1).view(-1)
img_embeds = mmgpt.prepare_gen_img_embeds(next_token)
inputs_embeds = img_embeds.unsqueeze(dim=1)
dec = mmgpt.gen_vision_model.decode_code(
generated_tokens.to(dtype=torch.int),
shape=[parallel_size, 8, img_size // patch_size, img_size // patch_size],
)
dec = dec.to(torch.float32).cpu().numpy().transpose(0, 2, 3, 1)
dec = np.clip((dec + 1) / 2 * 255, 0, 255)
visual_img = np.zeros((parallel_size, img_size, img_size, 3), dtype=np.uint8)
visual_img[:, :, :] = dec
os.makedirs('generated_samples', exist_ok=True)
for i in range(parallel_size):
save_path = os.path.join('generated_samples', f"img_{i}.jpg")
PIL.Image.fromarray(visual_img[i]).save(save_path)
# Run the image generation
generate(vl_gpt, vl_chat_processor, prompt)
Imej yang dijana akan disimpan dalam folder generated_samples.
Contoh Hasil Dijana
Di bawah ialah contoh imej yang dijana:

- Anjing digambarkan dengan agak baik.
- Bangunan mengekalkan bentuk keseluruhan, walaupun beberapa butiran, seperti tingkap, mungkin kelihatan tidak realistik.
- Manusia, bagaimanapun, mencabar untuk menjana dengan baik, dengan herotan ketara dalam kedua-dua gaya foto-realistik dan seperti anime.
Atas ialah kandungan terperinci Janus B: Model Bersatu untuk Pemahaman Multimodal dan Tugasan Penjanaan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Python: Permainan, GUI, dan banyak lagiApr 13, 2025 am 12:14 AM
Python: Permainan, GUI, dan banyak lagiApr 13, 2025 am 12:14 AMPython cemerlang dalam permainan dan pembangunan GUI. 1) Pembangunan permainan menggunakan pygame, menyediakan lukisan, audio dan fungsi lain, yang sesuai untuk membuat permainan 2D. 2) Pembangunan GUI boleh memilih tkinter atau pyqt. TKInter adalah mudah dan mudah digunakan, PYQT mempunyai fungsi yang kaya dan sesuai untuk pembangunan profesional.
 Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AM
Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AMPython sesuai untuk sains data, pembangunan web dan tugas automasi, manakala C sesuai untuk pengaturcaraan sistem, pembangunan permainan dan sistem tertanam. Python terkenal dengan kesederhanaan dan ekosistem yang kuat, manakala C dikenali dengan keupayaan kawalan dan keupayaan kawalan yang mendasari.
 Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AM
Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AMAnda boleh mempelajari konsep pengaturcaraan asas dan kemahiran Python dalam masa 2 jam. 1. Belajar Pembolehubah dan Jenis Data, 2.
 Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AM
Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AMPython digunakan secara meluas dalam bidang pembangunan web, sains data, pembelajaran mesin, automasi dan skrip. 1) Dalam pembangunan web, kerangka Django dan Flask memudahkan proses pembangunan. 2) Dalam bidang sains data dan pembelajaran mesin, numpy, panda, scikit-learn dan perpustakaan tensorflow memberikan sokongan yang kuat. 3) Dari segi automasi dan skrip, Python sesuai untuk tugas -tugas seperti ujian automatik dan pengurusan sistem.
 Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PM
Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PMAnda boleh mempelajari asas -asas Python dalam masa dua jam. 1. Belajar pembolehubah dan jenis data, 2. Struktur kawalan induk seperti jika pernyataan dan gelung, 3 memahami definisi dan penggunaan fungsi. Ini akan membantu anda mula menulis program python mudah.
 Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AM
Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AMBagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam masa 10 jam? Sekiranya anda hanya mempunyai 10 jam untuk mengajar pemula komputer beberapa pengetahuan pengaturcaraan, apa yang akan anda pilih untuk mengajar ...
 Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AM
Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AMCara mengelakkan dikesan semasa menggunakan fiddlerevery di mana untuk bacaan lelaki-dalam-pertengahan apabila anda menggunakan fiddlerevery di mana ...
 Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AM
Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AMMemuatkan Fail Pickle di Python 3.6 Kesalahan Laporan Alam Sekitar: ModulenotFoundError: Nomodulenamed ...


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

EditPlus versi Cina retak
Saiz kecil, penyerlahan sintaks, tidak menyokong fungsi gesaan kod

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

Dreamweaver Mac版
Alat pembangunan web visual

