Llama 3.1 akhirnya muncul, tetapi sumbernya bukan Meta rasmi. Hari ini, berita tentang kebocoran model besar Llama baharu menjadi viral di Reddit Selain model asas, ia turut menyertakan hasil penanda aras 8B, 70B dan parameter maksimum 405B. 
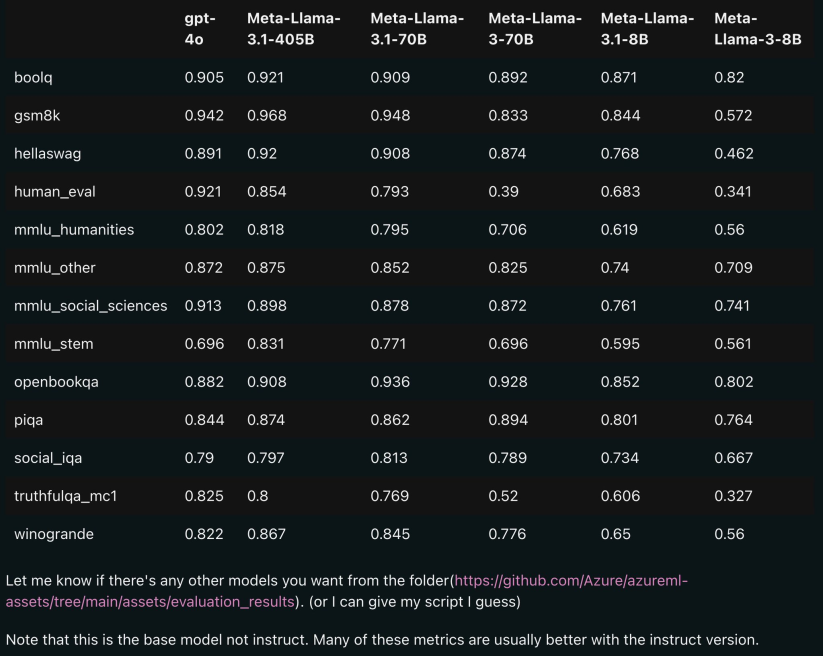
Gambar di bawah menunjukkan hasil perbandingan setiap versi Llama 3.1 dengan OpenAI GPT-4o dan Llama 3 8B/70B. Seperti yang anda boleh lihat, malah versi 70B mengatasi GPT-4o pada berbilang penanda aras.
, model 8B dan 70B versi 3.1 disuling daripada 405B, jadi berbanding dengan Generasi sebelumnya mempunyai peningkatan prestasi yang ketara.
Sesetengah netizen berkata ini adalah kali pertama model sumber terbuka mengatasi model sumber tertutup seperti GPT4o dan Claude Sonnet 3.5 dan mencapai SOTA pada berbilang penanda aras.
Pada masa yang sama, kad model Llama 3.1 bocor dan butirannya bocor (tarikh yang ditanda dalam kad model menunjukkan bahawa ia berdasarkan keluaran 23 Julai).
SomeOne meringkaskan sorotan berikut:
The Model menggunakan token 15t+ dari sumber awam untuk latihan, dan tarikh akhir data pra-latihan adalah Disember 2023; Set data penalaan halus arahan yang tersedia (tidak seperti Llama 3) dan 15 juta sampel sintetik;
Model menyokong berbilang bahasa, termasuk bahasa Inggeris, Perancis, Jerman, Hindi, Itali, Portugis, Sepanyol dan Thai.
-
-
Walaupun pautan Github yang bocor pada masa ini adalah 404, beberapa netizen telah memberikan pautan muat turun ( Namun, demi keselamatan, adalah disyorkan untuk menunggu pengumuman rasmi saluran malam ini):
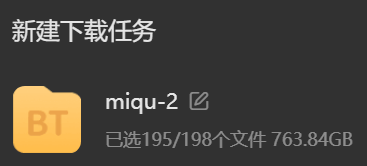
Tetapi ini adalah model tahap 100 bilion lagipun, sila sediakan ruang cakera keras yang mencukupi sebelum memuat turun:
Berikut ialah model Llama 3.1 Kandungan penting dalam kad:
maklumat model
Meta Llama 3.1 Koleksi Model Bahasa Besar Berbilang Bahasa (LLM) ialah set model generatif yang telah dilatih dan ditala halus, setiap satu bersaiz 8B, 70B dan 405B (input teks/output teks). Model teks sahaja yang diperhalusi perintah Llama 3.1 (8B, 70B, 405B) dioptimumkan untuk kes penggunaan perbualan berbilang bahasa dan mengatasi banyak model sembang sumber terbuka dan tertutup yang tersedia pada penanda aras industri biasa. Seni bina model: Llama 3.1 ialah model bahasa autoregresif seni bina Transformer yang dioptimumkan. Versi diperhalusi menggunakan SFT dan RLHF untuk menyelaraskan keutamaan kebolehgunaan dan keselamatan.
Bahasa yang disokong: Inggeris, Jerman, Perancis, Itali, Portugis, Hindi, Sepanyol dan Thai. Ia boleh disimpulkan daripada maklumat kad model bahawa panjang konteks model siri
Llama 3.1 ialah 128k. Semua versi model menggunakan Perhatian Pertanyaan Berkumpulan (GQA) untuk meningkatkan kebolehskalaan inferens.
PENGGUNAAN YANG DIINGINKAN KES PENGGUNAAN YANG DIINGINKAN. Llama 3.1 bertujuan untuk aplikasi dan penyelidikan perniagaan berbilang bahasa. Model teks sahaja yang ditala arahan sesuai untuk sembang seperti pembantu, manakala model pra-latihan boleh disesuaikan dengan pelbagai tugas penjanaan bahasa semula jadi. Set model Llama 3.1 juga menyokong keupayaan untuk memanfaatkan output modelnya untuk menambah baik model lain, termasuk penjanaan data sintetik dan penyulingan. Lesen Komuniti Llama 3.1 membenarkan kes penggunaan ini. Llama 3.1 melatih set bahasa yang lebih luas berbanding 8 bahasa yang disokong. Pembangun boleh memperhalusi model Llama 3.1 untuk bahasa selain daripada 8 bahasa yang disokong, dengan syarat mereka mematuhi Perjanjian Lesen Komuniti Llama 3.1 dan Dasar Penggunaan Boleh Diterima, dan bertanggungjawab dalam kes sedemikian untuk memastikan bahasa lain digunakan dalam cara yang selamat dan bertanggungjawab Bahasa Llama 3.1. Infrastruktur perisian dan perkakasanYang pertama ialah elemen latihan Llama 3.1 menggunakan perpustakaan latihan tersuai, kluster GPU tersuai Meta dan infrastruktur pengeluaran untuk pra-latihan, dan juga diperhalusi. infrastruktur pengeluaran, anotasi dan penilaian. Yang kedua ialah penggunaan tenaga latihan latihan Llama 3.1 menggunakan jumlah pengiraan jam GPU sebanyak 39.3 M pada perkakasan jenis H100-80GB (TDP ialah 700W). Di sini masa latihan ialah jumlah masa GPU yang diperlukan untuk melatih setiap model, dan penggunaan kuasa ialah kapasiti kuasa puncak setiap peranti GPU, diselaraskan untuk kecekapan kuasa. Latihan tentang pelepasan gas rumah hijau. Jumlah pelepasan gas rumah hijau berdasarkan penanda aras geografi dianggarkan sebanyak 11,390 tan CO2e semasa tempoh latihan Llama 3.1. Sejak 2020, Meta telah mengekalkan pelepasan gas rumah hijau bersih-sifar merentas operasi globalnya dan memadankan 100% penggunaan elektriknya dengan tenaga boleh diperbaharui, menghasilkan jumlah pelepasan gas rumah hijau asas pasaran sebanyak 0 tan CO2e semasa tempoh latihan . Kaedah yang digunakan untuk menentukan penggunaan tenaga latihan dan pelepasan gas rumah hijau boleh didapati dalam kertas berikut. Oleh kerana Meta mengeluarkan model ini secara terbuka, yang lain tidak perlu menanggung beban latihan penggunaan tenaga dan pelepasan gas rumah hijau. . pra- latihan. Data penalaan halus termasuk set data arahan yang tersedia untuk umum, dan lebih 25 juta contoh yang dijana secara sintetik. Kesegaran data: Tarikh akhir untuk data pra-latihan ialah Disember 2023. Dalam bahagian ini, Meta melaporkan hasil pemarkahan model Llama 3.1 pada penanda aras anotasi. Untuk semua penilaian, Meta menggunakan perpustakaan penilaian dalaman. Llama 연구팀은 보안 미세 조정의 견고성을 연구할 수 있는 귀중한 리소스를 연구 커뮤니티에 제공하고 개발자에게 다양한 보안을 위한 안전하고 강력한 기성 모델을 제공하기 위해 최선을 다하고 있습니다. 보안 AI 시스템을 배포하는 개발자의 작업량을 줄이기 위한 애플리케이션입니다. 연구팀은 잠재적인 보안 위험을 완화하기 위해 공급업체에서 인간이 생성한 데이터와 합성 데이터를 결합하는 다각적인 데이터 수집 접근 방식을 사용합니다. 연구팀은 고품질 프롬프트와 응답을 신중하게 선택하기 위해 다수의 LLM(대형 언어 모델) 기반 분류기를 개발하여 데이터 품질 관리를 강화했습니다. Llama 3.1은 양성 프롬프트와 거부 톤의 모델 거부에 큰 중요성을 부여한다는 점을 언급할 가치가 있습니다. 연구팀은 보안 데이터 정책에 경계 프롬프트와 적대적 프롬프트를 도입하고 톤 지침을 따르도록 보안 데이터 응답을 수정했습니다. Llama 3.1 모델은 단독으로 배포하도록 설계되지 않았지만 필요에 따라 추가 "안전 가드레일"을 제공하여 전체 인공 지능 시스템의 일부로 배포해야 합니다. 개발자는 에이전트 시스템을 구축할 때 시스템 보안 조치를 배포해야 합니다. 이번 릴리스에는 더 길어진 컨텍스트 창, 다국어 입력 및 출력, 타사 도구와의 개발자 통합 등 새로운 기능이 도입되었습니다. 이러한 새로운 기능을 사용하여 구축할 때는 모든 생성 AI 사용 사례에 일반적으로 적용되는 모범 사례를 고려하는 것 외에도 다음 문제에도 특별한 주의를 기울여야 합니다. 도구 사용: 표준 소프트웨어 개발과 마찬가지로 개발자는 자신이 선택한 도구 및 서비스와 LLM을 통합할 책임이 있습니다. 사용 사례에 대한 명확한 정책을 개발하고 이 기능을 사용할 때 안전 및 보안 제한 사항을 이해하기 위해 사용하는 타사 서비스의 무결성을 평가해야 합니다. 다국어: Lama 3.1은 영어 외에 프랑스어, 독일어, 힌디어, 이탈리아어, 포르투갈어, 스페인어, 태국어 등 7개 언어를 지원합니다. Llama는 다른 언어로 텍스트를 출력할 수 있지만 이 텍스트는 보안 및 지원 가능성 성능 임계값을 충족하지 못할 수 있습니다. Llama 3.1의 핵심 가치는 개방성, 포용성, 유용성입니다. 모든 사람에게 서비스를 제공하도록 설계되었으며 다양한 사용 사례에 적합합니다. 따라서 Llama 3.1은 모든 배경, 경험 및 관점을 가진 사람들이 접근할 수 있도록 설계되었습니다. Llama 3.1은 불필요한 판단이나 규범을 삽입하지 않고 사용자와 그들의 요구에 중점을 두는 동시에 일부 상황에서는 문제가 될 수 있는 콘텐츠라도 다른 상황에서는 유용할 수 있다는 인식을 반영합니다. Llama 3.1은 모든 사용자의 존엄성과 자율성을 존중하며, 특히 혁신과 발전을 촉진하는 자유로운 사고와 표현의 가치를 존중합니다. 하지만 Llama 3.1은 신기술이며 다른 신기술과 마찬가지로 사용 시 위험이 따릅니다. 현재까지 실시된 테스트는 모든 상황을 다룰 수 없으며 다룰 수도 없습니다. 따라서 모든 LLM과 마찬가지로 Llama 3.1의 잠재적 결과는 미리 예측할 수 없으며 경우에 따라 모델이 사용자 프롬프트에 부정확하거나 편향되거나 달리 불쾌하게 반응할 수 있습니다. 따라서 Llama 3.1 모델의 애플리케이션을 배포하기 전에 개발자는 모델의 특정 애플리케이션에 대한 보안 테스트 및 미세 조정을 수행해야 합니다. 모델 카드 출처 : https://pastebin.com/9jGkYbXY참고 정보 : https://x.com/op7418/status/1815340034717069728 https: //x.com/iScienceLuvr/status/1815519917715730702https://x.com/mattshumer_/status/1815444612414087294Atas ialah kandungan terperinci Model sumber terbuka pertama yang melepasi tahap GPT4o! Llama 3.1 bocor: 405 bilion parameter, pautan muat turun dan kad model tersedia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn



 Tetapi ini adalah model tahap 100 bilion lagipun, sila sediakan ruang cakera keras yang mencukupi sebelum memuat turun:
Tetapi ini adalah model tahap 100 bilion lagipun, sila sediakan ruang cakera keras yang mencukupi sebelum memuat turun: