
Rumah >Peranti teknologi >AI >Piawaian baharu untuk pengimejan AI, hanya 1% daripada data asal boleh mencapai prestasi terbaik, model asas perubatan am yang diterbitkan dalam sub-jurnal Nature
Piawaian baharu untuk pengimejan AI, hanya 1% daripada data asal boleh mencapai prestasi terbaik, model asas perubatan am yang diterbitkan dalam sub-jurnal Nature

- 王林asal
- 2024-07-22 17:38:001053semak imbas

Editor |. Daun Kubis
Model asas pra-latihan berskala besar telah mencapai kejayaan besar dalam bidang bukan perubatan. Walau bagaimanapun, latihan model ini selalunya memerlukan set data yang besar dan komprehensif, berbeza dengan set data yang lebih kecil dan lebih khusus yang biasa dalam pengimejan bioperubatan.
Para penyelidik di Institut Fraunhofer untuk Perubatan Digital MEVIS di Jerman mencadangkan strategi pembelajaran pelbagai tugas yang memisahkan bilangan tugas latihan daripada keperluan ingatan.
Mereka melatih model pra-latihan bioperubatan universal (UMedPT) pada pangkalan data berbilang tugas termasuk tomografi, mikroskop dan imej X-ray serta menggunakan pelbagai strategi pelabelan seperti pengelasan, segmentasi dan pengesanan objek. Model asas UMedPT mengatasi prestasi ImageNet pra-latihan dan model STOA sebelumnya.
Dalam pengesahan bebas luaran, ciri pengimejan yang diekstrak menggunakan UMedPT ditunjukkan untuk menetapkan standard baharu untuk kebolehpindahan merentas pusat.
Kajian itu bertajuk "Mengatasi kekurangan data dalam pengimejan bioperubatan dengan model pelbagai tugas asas" dan diterbitkan dalam "Nature Computational Science" pada 19 Julai 2024.

Pembelajaran mendalam merevolusikan analisis imej bioperubatan secara beransur-ansur kerana keupayaannya untuk mempelajari dan mengekstrak perwakilan imej yang berguna.
Kaedah umum adalah untuk melatih model pada set data imej semula jadi berskala besar (seperti ImageNet atau LAION), dan kemudian memperhalusinya untuk tugasan tertentu atau terus menggunakan ciri yang telah dilatih. Tetapi penalaan halus memerlukan lebih banyak sumber pengkomputeran.
Pada masa yang sama, bidang pengimejan bioperubatan memerlukan sejumlah besar data beranotasi untuk pra-latihan pembelajaran mendalam yang berkesan, tetapi data sedemikian selalunya terhad.
Pembelajaran berbilang tugas (MTL) menyediakan penyelesaian kepada kekurangan data dengan melatih model untuk menyelesaikan pelbagai tugas secara serentak. Ia memanfaatkan banyak set data bersaiz kecil dan sederhana dalam pengimejan bioperubatan untuk pra-melatih perwakilan imej yang sesuai untuk semua tugas dan sesuai untuk domain yang kekurangan data.
MTL telah digunakan untuk analisis imej bioperubatan dalam pelbagai cara, termasuk latihan daripada berbilang set data kecil dan sederhana untuk tugasan yang berbeza, dan menggunakan berbilang jenis label pada satu imej, menunjukkan bahawa ciri yang dikongsi boleh meningkatkan prestasi tugasan.
Dalam penyelidikan terkini, untuk menggabungkan berbilang set data dengan jenis label yang berbeza untuk pra-latihan berskala besar, penyelidik dari Institut MEVIS memperkenalkan strategi latihan pelbagai tugas dan seni bina model yang sepadan, khususnya melalui pembelajaran perwakilan serba boleh merentas modaliti yang berbeza. , penyakit dan jenis label untuk menangani kekurangan data dalam pengimejan bioperubatan.
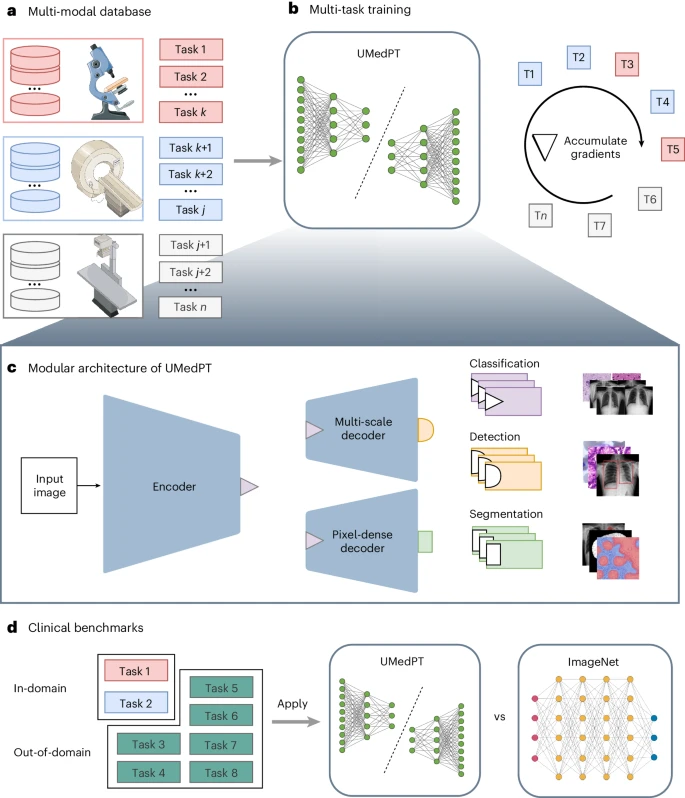
Untuk mengatasi kekangan ingatan yang dihadapi dalam pembelajaran berbilang tugas berskala besar, kaedah ini menggunakan gelung latihan berasaskan pengumpulan kecerunan, yang pengembangannya hampir tidak terhad oleh bilangan tugas latihan.
Atas dasar ini, para penyelidik melatih model asas pengimejan bioperubatan yang diselia sepenuhnya yang dipanggil UMedPT menggunakan 17 tugasan dan anotasi asalnya.
Imej di bawah menunjukkan seni bina rangkaian saraf pasukan, yang terdiri daripada blok kongsi termasuk pengekod, penyahkod segmentasi dan penyahkod penyetempatan, serta ketua khusus tugas. Blok kongsi dilatih untuk digunakan pada semua tugas pralatihan, membantu mengekstrak ciri biasa, manakala penyelia khusus tugas mengendalikan pengiraan dan ramalan kerugian khusus label.
Tugas yang ditetapkan termasuk tiga jenis label yang diselia: pengesanan objek, pembahagian dan pengelasan. Sebagai contoh, tugas klasifikasi boleh memodelkan biomarker binari, tugas segmentasi boleh mengekstrak maklumat spatial dan tugas pengesanan objek boleh digunakan untuk melatih biomarker berdasarkan nombor sel.
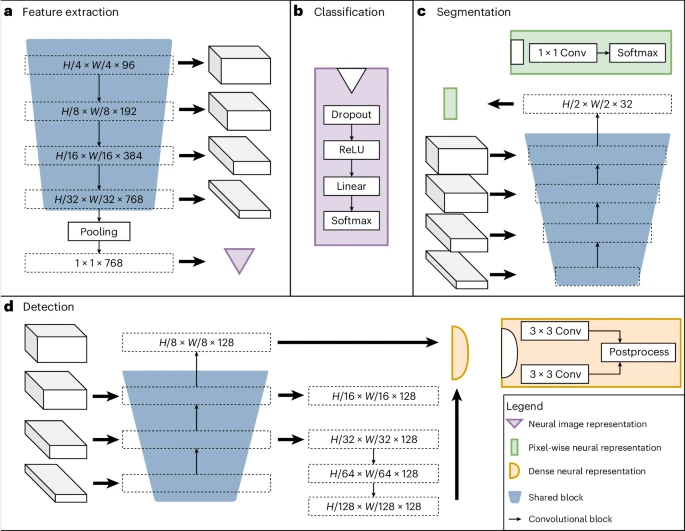
Ilustrasi: Seni bina UMedPT. (Sumber: Kertas)
UMedPT secara konsisten memadankan atau mengatasi prestasi rangkaian ImageNet terlatih pada kedua-dua tugas dalam domain dan luar domain, sambil mengekalkan prestasi kukuh menggunakan kurang data latihan apabila menggunakan tetapan perwakilan imej (pembekuan) dan penalaan halus secara langsung.
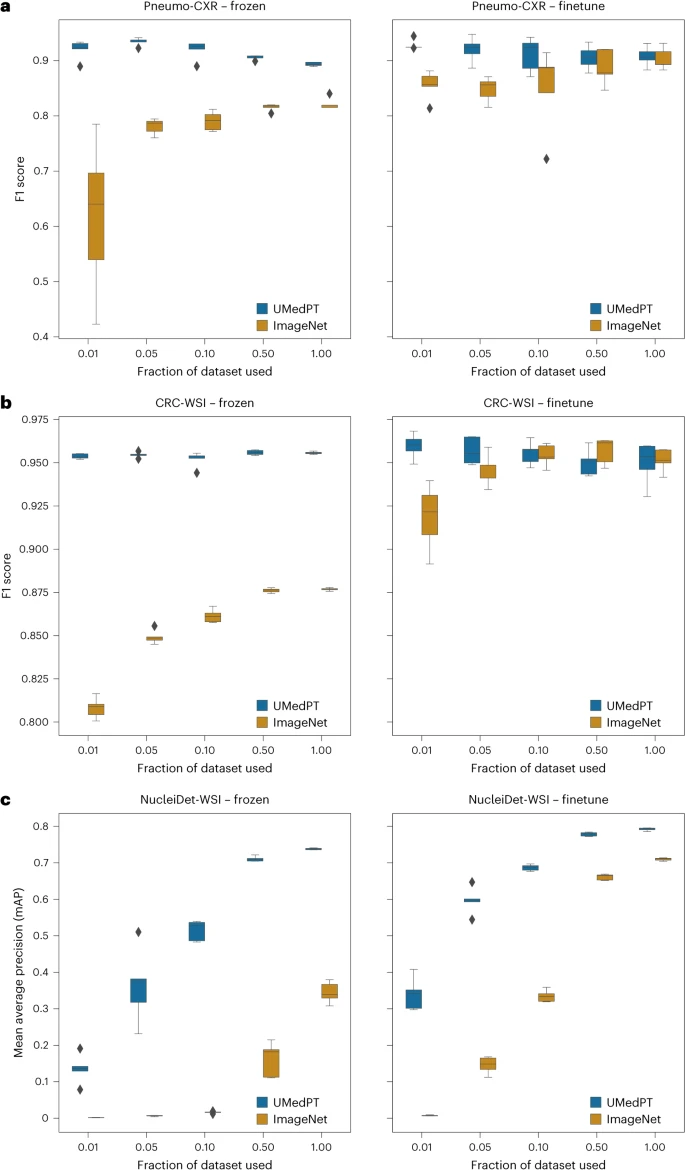
Ilustrasi: Hasil tugasan dalam domain. (Sumber: kertas)
Untuk tugas pengelasan yang dikaitkan dengan pangkalan data pra-latihan, UMedPT mampu mencapai prestasi terbaik garis dasar ImageNet pada semua konfigurasi menggunakan hanya 1% daripada data latihan asal. Model ini mencapai prestasi yang lebih tinggi menggunakan pengekod beku berbanding model yang menggunakan penalaan halus.
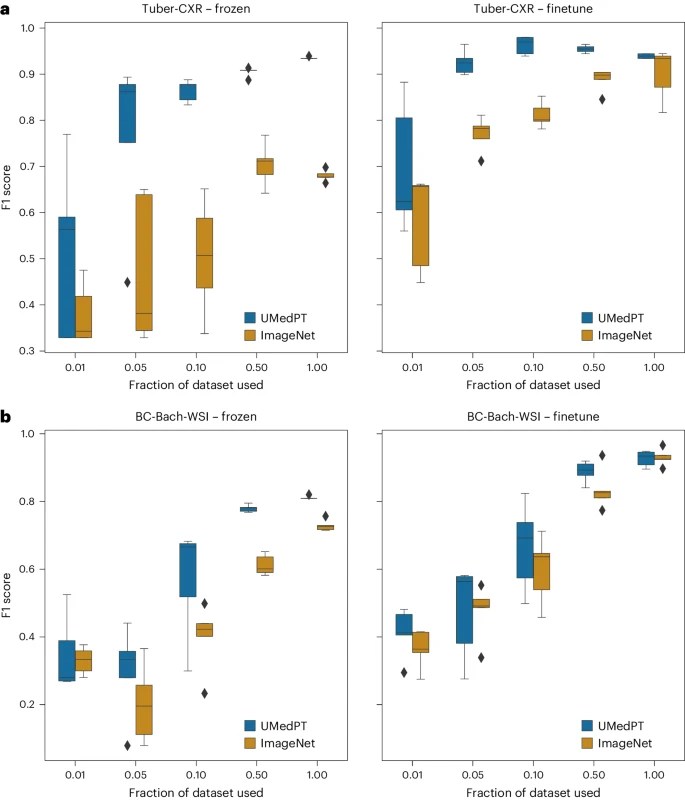
Ilustrasi: Keputusan untuk tugas di luar domain (sumber: kertas)
Untuk tugas di luar domain, UMedPT dapat memadankan prestasi ImageNet menggunakan hanya 50% atau kurang data, walaupun dengan halus- penalaan digunakan.
Selain itu, penyelidik membandingkan prestasi UMedPT dengan keputusan yang dilaporkan dalam literatur. Apabila menggunakan konfigurasi pengekod beku, UMedPT melebihi hasil rujukan luaran dalam kebanyakan tugas. Dalam tetapan ini, ia juga mengatasi purata kawasan di bawah lengkung (AUC) dalam pangkalan data MedMNIST 16 .
Perlu diambil perhatian bahawa tugas yang penggunaan beku UMedPT tidak mengatasi hasil rujukan adalah di luar domain (BC-Bach-WSI untuk klasifikasi kanser payudara dan CNS-MRI untuk diagnosis tumor CNS). Dengan penalaan halus, pra-latihan dengan UMedPT mengatasi hasil rujukan luaran dalam semua tugas.

Ilustrasi: Jumlah data yang diperlukan untuk UMedPT mencapai prestasi terkini pada tugasan dalam domain pengimejan yang berbeza. (Sumber: Kertas)
Sebagai asas untuk perkembangan masa depan dalam bidang kekurangan data, UMedPT membuka prospek aplikasi pembelajaran mendalam dalam bidang perubatan yang mengumpul sejumlah besar data amat mencabar, seperti penyakit jarang berlaku dan pengimejan pediatrik.
Pautan kertas:https://www.nature.com/articles/s43588-024-00662-z
Kandungan berkaitan:https://www.nature.com/articles/s43588-024-006584-006584-006584 9
Atas ialah kandungan terperinci Piawaian baharu untuk pengimejan AI, hanya 1% daripada data asal boleh mencapai prestasi terbaik, model asas perubatan am yang diterbitkan dalam sub-jurnal Nature. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI