
Rumah >Peranti teknologi >AI >Universiti Sains dan Teknologi China dan Huawei Noah mencadangkan Undang-undang Entropi untuk mendedahkan hubungan antara prestasi model besar, kadar pemampatan data dan kehilangan latihan.
Universiti Sains dan Teknologi China dan Huawei Noah mencadangkan Undang-undang Entropi untuk mendedahkan hubungan antara prestasi model besar, kadar pemampatan data dan kehilangan latihan.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-07-22 16:39:35873semak imbas

Lajur AIxiv ialah lajur di mana kandungan akademik dan teknikal diterbitkan di laman web ini. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com

Pasukan: Pasukan Chen Enhong di National Key Laboratory of Cognitive Intelligence, University of Science and Technology of China, Huawei Noah's Ark Laboratory Pautan kertas: https://arxiv.org/pdf Pautan kod : https://github.com/USTC-StarTeam/ZIP

- Kehilangan latihan L: Menunjukkan sama ada data sukar untuk diingati oleh model. Di bawah model asas yang sama, kehilangan latihan yang tinggi biasanya disebabkan oleh kehadiran bunyi bising atau maklumat yang tidak konsisten dalam set data.
- Ketekalan data C: Ketekalan data dicerminkan oleh entropi kebarangkalian token seterusnya memandangkan situasi sebelumnya. Konsistensi data yang lebih tinggi biasanya membawa kepada kehilangan latihan yang lebih rendah.
- Kualiti data purata S: mencerminkan purata kualiti peringkat sampel data, yang boleh diukur melalui pelbagai aspek objektif dan subjektif.
di mana f ialah fungsi tersirat. Memandangkan model asas tertentu, skala L biasanya bergantung pada R dan C dan boleh dinyatakan sebagai: 
Memandangkan set data dengan homogeniti yang lebih tinggi atau ketekalan data yang lebih baik lebih mudah dipelajari oleh model, L Ia dijangka menjadi monotonik dalam R dan C. Oleh itu, kita boleh menulis semula formula di atas sebagai: 
di mana g' ialah fungsi songsang. Dengan menggabungkan tiga persamaan di atas, kita mendapat: 
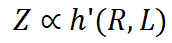
Jika C dianggap sebagai pemalar, kehilangan latihan secara langsung dipengaruhi oleh kadar mampatan. Oleh itu, prestasi model dikawal oleh nisbah mampatan: jika nisbah mampatan data R lebih tinggi, maka Z biasanya lebih teruk, yang akan disahkan dalam eksperimen kami. Di bawah nisbah mampatan yang sama, kehilangan latihan yang lebih tinggi bermakna konsistensi data yang lebih rendah. Oleh itu, pengetahuan berkesan yang dipelajari oleh model mungkin lebih terhad. Ini boleh digunakan untuk meramalkan prestasi LLM pada data berbeza dengan nisbah mampatan dan kualiti sampel yang serupa. Kami akan menunjukkan aplikasi penaakulan ini dalam amalan kemudian. . jumlah maklumat berkesan di bawah bajet data latihan yang terhad. Atas sebab kecekapan, kami mengguna pakai paradigma tamak berbilang peringkat berulang untuk mendapatkan penyelesaian anggaran dengan cekap dengan kadar mampatan yang agak rendah. Dalam setiap lelaran, kami mula-mula menggunakan peringkat pemilihan global untuk memilih kumpulan sampel calon dengan nisbah mampatan rendah untuk mencari sampel dengan ketumpatan maklumat yang tinggi. Kami kemudiannya menggunakan peringkat pemilihan tempatan berbutir kasar untuk memilih set sampel yang lebih kecil yang mempunyai redundansi terendah dengan sampel yang dipilih. Akhir sekali, kami menggunakan peringkat pemilihan tempatan yang terperinci untuk meminimumkan persamaan antara sampel yang akan ditambah. Proses di atas diteruskan sehingga data yang mencukupi diperolehi. Algoritma khusus adalah seperti berikut:

Berdasarkan eksperimen pemilihan data SFT, kami berdasarkan kesan model, kadar mampatan data dan kehilangan data daripada model dalam langkah latihan sebelumnya, masing-masing Pelbagai keluk hubungan telah dipasang. Keputusan ditunjukkan dalam Rajah 2 dan 3, dari mana kita boleh melihat korelasi rapat antara tiga faktor. Pertama sekali, data kadar mampatan rendah biasanya membawa kepada hasil model yang lebih baik Ini kerana proses pembelajaran LLM sangat berkaitan dengan pemampatan maklumat Kita boleh menganggap LLM sebagai pemampat data, jadi data dengan kadar mampatan yang lebih rendah bermakna lebih banyak pengetahuan dan dengan itu lebih berharga kepada pemampat. Pada masa yang sama, boleh diperhatikan bahawa nisbah mampatan yang lebih rendah biasanya disertai dengan kehilangan latihan yang lebih tinggi Ini kerana data yang sukar untuk dimampatkan membawa lebih banyak pengetahuan, menimbulkan cabaran yang lebih besar untuk LLM menyerap pengetahuan yang terkandung di dalamnya. 

到

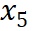
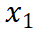

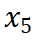
Atas ialah kandungan terperinci Universiti Sains dan Teknologi China dan Huawei Noah mencadangkan Undang-undang Entropi untuk mendedahkan hubungan antara prestasi model besar, kadar pemampatan data dan kehilangan latihan.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI