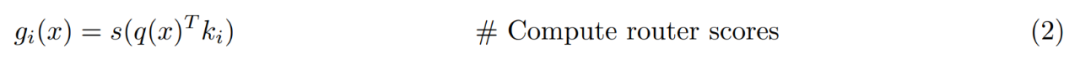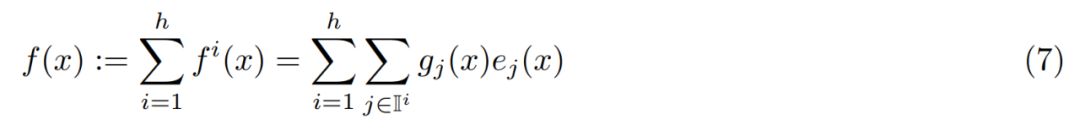Buka kunci potensi untuk meningkatkan skala Transformer sambil mengekalkan kecekapan pengiraan. Lapisan
Feedforward (FFW) dalam seni bina Transformer standard menghasilkan peningkatan linear dalam kos pengiraan dan ingatan pengaktifan apabila lebar lapisan tersembunyi meningkat. Oleh kerana saiz model bahasa besar (LLM) terus meningkat, seni bina pakar campuran jarang (MoE) telah menjadi kaedah yang boleh dilaksanakan untuk menyelesaikan masalah ini, yang memisahkan saiz model daripada kos pengiraan. Banyak model MoE yang baru muncul boleh mencapai prestasi yang lebih baik dan prestasi yang lebih berkuasa pada saiz yang sama. Undang-undang pengembangan terperinci MoE yang baru ditemui menunjukkan bahawa butiran yang lebih tinggi membawa kepada prestasi yang lebih baik. Walau bagaimanapun, model KPM sedia ada terhad kepada bilangan pakar yang rendah disebabkan oleh cabaran pengiraan dan pengoptimuman. Selasa ini, Penyelidikan baharu daripada Google DeepMind memperkenalkan mekanisme pengambilan pakar cekap parameter yang memanfaatkan teknologi utama produk untuk melakukan pengambilan semula jarang daripada satu juta pakar mikro. 
Pautan: https://arxiv.org/abs/2407.04153Pendekatan ini cuba memisahkan kos pengiraan daripada kiraan parameter dengan menggabungkan secara cekap kepada sebilangan besar pakar struktur kecil yang dipelajari untuk melalui penghalaan . Menunjukkan kecekapan unggul berbanding lapisan FFW padat, MoE berbutir kasar dan Ingatan Utama Produk (PKM). Kerja ini memperkenalkan seni bina Parameter Efficient Expert Retrieval (PEER) (parameter efficient expert retrieval), yang menggunakan perolehan kunci produk untuk laluan yang cekap kepada sejumlah besar pakar, memisahkan kos pengiraan daripada jumlah parameter. Reka bentuk ini menunjukkan tahap prestasi pengiraan yang unggul dalam eksperimen, meletakkannya sebagai alternatif yang kompetitif kepada lapisan FFW padat untuk memanjangkan model asas. Sumbangan utama kerja ini ialah: Penerokaan tetapan KPM yang melampau: Tidak seperti tumpuan kepada beberapa pakar besar dalam kajian KPM sebelum ini, kerja ini menyiasat situasi yang kurang diterokai oleh ramai pakar kecil. Struktur Indeks yang Dipelajari untuk Penghalaan: Demonstrasi pertama bahawa struktur indeks yang dipelajari boleh disalurkan dengan cekap kepada lebih sejuta pakar. Reka bentuk lapisan baharu: Menggabungkan penghalaan kunci produk dengan pakar neuron tunggal, kami memperkenalkan lapisan PEER, yang menskalakan kapasiti lapisan tanpa overhed pengiraan yang ketara. Keputusan empirikal menunjukkan kecekapan yang lebih tinggi berbanding lapisan FFW padat, MoE berbutir kasar dan Ingatan Utama Produk (PKM). Kajian ablasi yang komprehensif: Kami mengkaji kesan pilihan reka bentuk yang berbeza untuk PEER (seperti bilangan pakar, parameter aktiviti, bilangan kepala dan penormalan kelompok pertanyaan) pada tugas pemodelan bahasa. Dalam bahagian ini, penyelidik menerangkan secara terperinci lapisan Parametric Efficient Expert Retrieval (PEER), seni bina pakar hibrid yang menggunakan kunci produk sebagai anneuroning M dan tunggal pakar. Rajah 2 di bawah menunjukkan proses pengiraan dalam lapisan PEER.
Gambaran Keseluruhan Lapisan PEER. Secara formal, lapisan PEER ialah fungsi f : R^n → R^m, yang terdiri daripada tiga bahagian: kumpulan N pakar E := {e_i}^N_i=1, di mana setiap pakar e_i : R^n → R ^m berkongsi tandatangan yang sama seperti f; set kunci produk N yang sepadan K := {k_i}^N_i=1 ⊂ R^d dan rangkaian pertanyaan q : R^n → R ^d, yang memetakan vektor input x ∈ R^n kepada vektor pertanyaan q (x). Biar T_k mewakili operator top-k. Memandangkan input x, mula-mula dapatkan subset pakar k yang kunci produk yang sepadan mempunyai produk dalaman tertinggi dengan pertanyaan q (x).
Kemudian gunakan pengaktifan tak linear (seperti softmax atau sigmoid) pada produk dalaman kunci pertanyaan pakar k teratas untuk mendapatkan skor penghalaan.
Akhirnya output dikira dengan menggabungkan secara linear output pakar yang ditimbang dengan skor penghalaan.
Pengambilan Kunci Produk. Memandangkan penyelidik berhasrat untuk menggunakan sejumlah besar pakar (N ≥ 10^6), hanya mengira indeks k teratas dalam Persamaan 1 boleh menjadi sangat mahal, jadi teknik pengambilan kunci produk digunakan. Daripada menggunakan N vektor dimensi d bebas sebagai kunci k_i, mereka menciptanya dengan menggabungkan vektor daripada dua set subkunci d/2 dimensi bebas (iaitu, C, C ′ ⊂ R d/2):
Parametrik pakar cekap dan carian berbilang kepala. Tidak seperti seni bina MoE yang lain, seni bina ini biasanya menetapkan lapisan tersembunyi setiap pakar kepada saiz yang sama seperti lapisan FFW yang lain. Dalam PEER, setiap pakar e_i adalah MLP tunggal, dengan kata lain, ia hanya mempunyai satu lapisan tersembunyi dengan neuron tunggal:
Para penyelidik tidak mengubah saiz pakar individu, tetapi menggunakan Multi-head retrieval is digunakan untuk melaraskan keupayaan ekspresif lapisan PEER, yang serupa dengan mekanisme perhatian berbilang kepala dalam pengubah dan memori berbilang kepala dalam PKM. Secara khusus, mereka menggunakan h rangkaian pertanyaan bebas, setiap rangkaian mengira pertanyaannya sendiri dan mendapatkan set k pakar yang berasingan. Walau bagaimanapun, ketua yang berbeza berkongsi kumpulan pakar yang sama, dengan set kunci produk yang sama. Output dari h head ini secara ringkasnya diringkaskan seperti berikut:
Mengapa kita memerlukan sejumlah besar pakar kecil ? Lapisan MoE tertentu boleh dicirikan oleh tiga hiperparameter: jumlah bilangan parameter P, bilangan parameter aktif bagi setiap token P_active dan saiz P_expert pakar tunggal. Krajewski et al. (2024) menunjukkan bahawa undang-undang penskalaan model MoE mempunyai bentuk berikut:
Untuk PEER, penyelidik menggunakan saiz pakar yang paling kecil dengan menetapkan d_expert = 1, dan bilangan neuron yang diaktifkan ialah kepala carian Nombor didarab dengan bilangan pakar yang diambil setiap kepala: d_active = hk. Oleh itu, kebutiran PEER sentiasa G = P_active/P_expert = d_active/d_expert = hk.
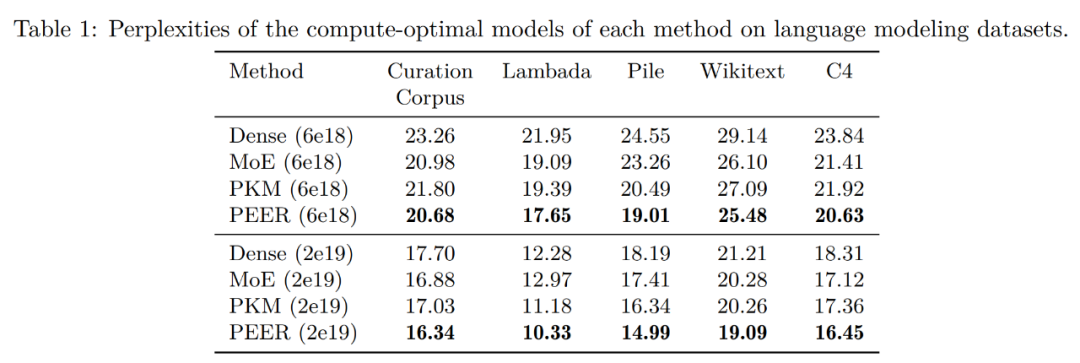
Mari kita lihat dahulu hasil penilaian pada set data pemodelan bahasa. Selepas menentukan model pengiraan optimum untuk setiap kaedah berdasarkan keluk isoFLOP, penyelidik menilai prestasi model pra-latihan ini pada set data pemodelan bahasa popular berikut:
di bawah menunjukkan keputusan evaluasi.
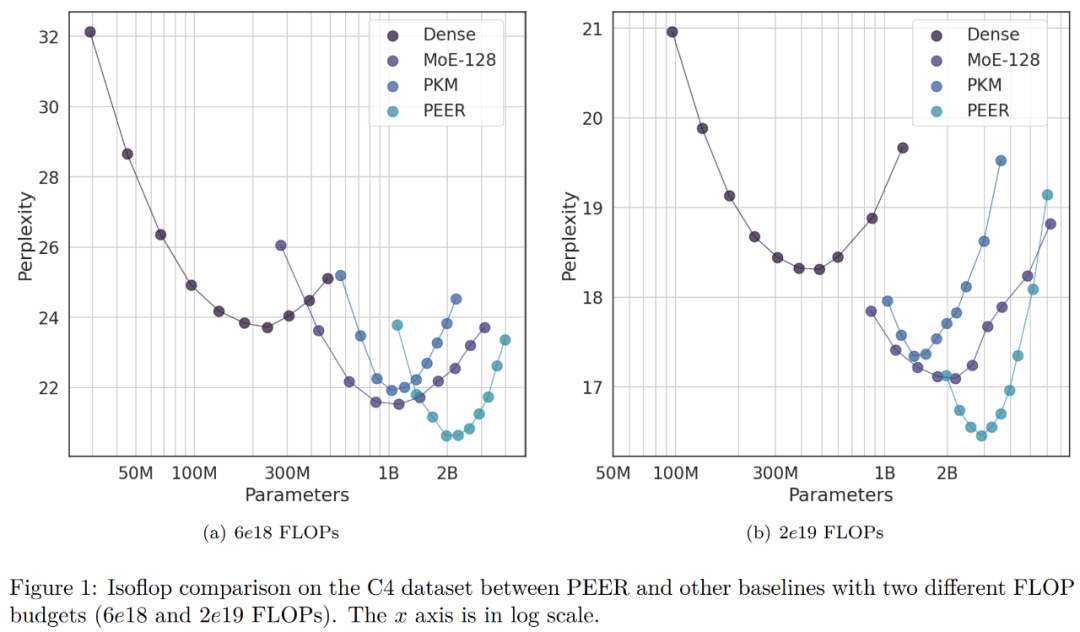
Para penyelidik mengumpulkan model berdasarkan belanjawan FLOP yang digunakan semasa latihan. Seperti yang dapat dilihat, PEER mempunyai kebingungan paling rendah pada set data pemodelan bahasa ini. 🎜🎜🎜🎜🎜Dalam eksperimen ablasi, penyelidik menukar jumlah bilangan pakar. Model yang ditunjukkan dalam lengkung isoFLOP dalam Rajah 1 di bawah semuanya mempunyai lebih satu juta (1024^2) pakar. 🎜🎜🎜🎜
Penyelidik memilih model dengan kedudukan optimum isoFLOP dan menukar bilangan pakar dalam lapisan PEER (N = 128^2, 256^2, 512^2, 1024^2), sambil mengekalkan bilangan pakar aktif tidak berubah (h = 8, k = 16). Keputusan ditunjukkan dalam Rajah 3(a) di bawah. Ia boleh dilihat bahawa lengkung isoFLOP interpolasi antara model PEER dengan pakar 1024^2 dan tulang belakang padat yang sepadan tanpa menggantikan lapisan FFW di blok tengah dengan lapisan PEER. Ini menunjukkan prestasi model boleh dipertingkatkan hanya dengan menambah bilangan pakar. Pada masa yang sama, penyelidik menukar bilangan pakar aktif. Mereka secara sistematik mengubah bilangan pakar aktif (hk = 32, 64, 128, 256, 512) sambil mengekalkan jumlah bilangan pakar tetap (N = 1024^2). Untuk hk tertentu, penyelidik kemudian bersama-sama menukar h dan k untuk menentukan gabungan terbaik. Rajah 3(b) di bawah memplot keluk isoFLOP berkenaan dengan bilangan kepala (h).
Jadual 2 di bawah menyenaraikan penggunaan pakar dan ketidaksamaan untuk bilangan pakar yang berbeza dengan dan tanpa BN. Dapat dilihat bahawa walaupun untuk pakar 1M, kadar penggunaan pakar adalah hampir 100%, dan menggunakan BN boleh menjadikan kadar penggunaan pakar lebih seimbang dan tahap kekeliruan lebih rendah. Penemuan ini menunjukkan keberkesanan model PEER dalam memanfaatkan sejumlah besar pakar.
Para penyelidik juga membandingkan keluk isoFLOP dengan dan tanpa BN. Rajah 4 di bawah menunjukkan bahawa model PEER dengan BN secara amnya boleh mencapai kebingungan yang lebih rendah. Walaupun perbezaannya tidak ketara, ia paling ketara berhampiran kawasan optimum isoFLOP.
Pengenalan kepada pengarangKajian PEER hanya mempunyai seorang pengarang, Xu He (Owen), yang merupakan saintis penyelidikan di Google DeepMind dan berkelulusan PhD dari University of Groningen pada tahun 2017.
Atas ialah kandungan terperinci Kertas pengarang tunggal, Google mencadangkan berjuta-juta pakar Campuran, mengatasi suapan hadapan yang padat dan jarang MoE. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn