Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Pasukan penyelidik Makmal Kepintaran Buatan Generatif (GAIR Lab) Universiti Jiao Tong Shanghai Arah penyelidikan utama ialah: latihan model besar, penjajaran dan penilaian. Laman utama pasukan: https://plms.ai/
Dalam 20 tahun akan datang, AI dijangka mengatasi kecerdasan manusia. Pemenang Anugerah Turing Hinton menyebut dalam temu bualnya bahawa "dalam 20 tahun akan datang, AI dijangka melepasi tahap kecerdasan manusia" dan mencadangkan syarikat teknologi utama membuat persediaan awal untuk menilai "kecekapan" model besar (termasuk pelbagai modal. model besar) "Tahap kecerdasan" adalah prasyarat yang diperlukan untuk penyediaan ini.
Tanda aras penilaian keupayaan penaakulan kognitif dengan set masalah antara disiplin yang boleh menilai AI dengan teliti daripada pelbagai dimensi telah menjadi sangat mendesak.
1. Model besar terus menduduki peringkat tinggi kecerdasan manusia: dari soalan ujian sekolah rendah hingga peperiksaan kemasukan kolej
Kebangkitan teknologi kecerdasan buatan generatif dengan model besar sebagai teras telah membolehkan manusia tidak hanya mempunyai teks dan gambar interaktif, alat penjanaan video interaktif juga memberi manusia peluang untuk melatih model dengan keupayaan "kecerdasan" Ia boleh dianggap sebagai otak manusia lanjutan, menyelesaikan masalah secara bebas dalam disiplin yang berbeza, dan menjadi model yang boleh. mempercepatkan penemuan saintifik dalam 10 tahun akan datang alat yang paling berkuasa (iaitu AI4Science). Dalam dua tahun kebelakangan ini, kami telah melihat evolusi pesat jenis kecerdasan berasaskan silikon ini yang diwakili oleh model besar Dari awal, ia hanya boleh digunakan untuk menyelesaikan masalah sekolah rendah al. [1] mendapat tempat pertama Buat pertama kalinya, AI dibawa ke bilik peperiksaan "Peperiksaan Masuk Kolej", dan mencapai markah 134 mata dalam Bahasa Inggeris Kertas Kebangsaan II Namun, pada masa itu, AI masih seorang pelajar mata pelajaran separa yang tidak memahami logik matematik dengan baik. Sehingga tahun ini, Peperiksaan Kemasukan Kolej 2024 baru sahaja tamat Walaupun ramai pelajar bekerja keras dalam peperiksaan tahunan ini, menunjukkan pencapaian pembelajaran mereka selama ini, model besar juga telah dibawa ke bilik peperiksaan buat kali pertama di. semua disiplin, dan Membuat kemajuan besar dalam matematik dan sains. Di sini kita tidak boleh tidak berfikir, di manakah siling untuk evolusi kecerdasan AI? Manusia masih belum menyelesaikan masalah yang paling sukar. Adakah itu akan menjadi siling AI?
2. Istana pertandingan intelektual tertinggi: dari peperiksaan kemasukan kolej AI ke Sukan Olimpik AISukan Olimpik empat tahunan juga akan datang tidak lama lagi, tetapi ini bukan sahaja acara puncak pertandingan sukan juga simbol pengejaran dan kejayaan yang berterusan manusia. Olimpik Mata Pelajaran adalah gabungan sempurna kedalaman pengetahuan dan had kecerdasan Ia bukan sahaja penilaian ketat pencapaian akademik, tetapi juga cabaran yang melampau untuk ketangkasan berfikir dan keupayaan inovasi. Di sini, ketegasan sains dan keghairahan Sukan Olimpik bertemu, bersama-sama membentuk semangat mengejar kecemerlangan dan keberanian untuk meneroka.
Olimpik subjek menyediakan tempat terbaik untuk pertarungan puncak antara kecerdasan manusia dan mesin. Tidak kira sama ada AGI boleh direalisasikan pada masa hadapan, penyertaan AI dalam Olympiads akan menjadi perhentian yang perlu dalam perjalanan ke AGI, kerana ini mengkaji keupayaan penaakulan kognitif model yang sangat penting, dan keupayaan ini secara beransur-ansur dicerminkan dalam pelbagai dunia nyata yang kompleks. Dalam senario, sebagai contoh, ejen AI digunakan untuk pembangunan perisian, bekerjasama mengendalikan proses membuat keputusan yang kompleks, dan juga mempromosikan bidang penyelidikan saintifik (AI4Science).
3. Bina arena Olimpik berorientasikan AIDalam konteks ini, pasukan penyelidik Makmal Kepintaran Buatan Generatif Universiti Shanghai Jiao Tong (GAIR Lab) memindahkan model besar dari bilik peperiksaan kemasukan kolej ke sebuah " "Arena Olimpik" yang lebih mencabar, melancarkan model besar baharu (termasuk model besar berbilang modal) penanda aras penilaian keupayaan penaakulan kognitif - OlympicArena. Penanda aras ini menggunakan soalan sukar daripada International Subject Olympiad untuk menguji secara menyeluruh keupayaan penaakulan kognitif kecerdasan buatan dalam bidang antara disiplin. OlympicArena merangkumi tujuh mata pelajaran teras matematik, fizik, kimia, biologi, geografi, astronomi dan sains komputer, termasuk 11,163 soalan dwibahasa dalam bahasa Cina dan Inggeris daripada 62 Olimpik mata pelajaran antarabangsa (seperti IMO, IPhO, IChO, IBO, ICPC, dsb. .), menyediakan penyelidik dengan Kami menyediakan platform yang ideal untuk penilaian menyeluruh model AI. Pada masa yang sama, dalam jangka masa yang lebih panjang, Arena Olimpik akan memainkan peranan yang tidak boleh diabaikan bagi AI untuk menggunakan keupayaan hebatnya dalam bidang sains (AI4Science) dan kejuruteraan (AI4Engineering) pada masa hadapan, dan malah mempromosikan AI untuk memberi inspirasi kepada superintelligence melebihi tahap manusia.
Pasukan penyelidik mendapati bahawa semua model besar semasa tidak dapat memberikan jawapan yang baik dalam subjek Olympiad Malah GPT-4o hanya mempunyai ketepatan 39%, dan GPT-4V hanya mempunyai 33%, yang jauh dari atas. Garis hantaran (kadar betul 60%) masih agak jauh. Prestasi kebanyakan model besar sumber terbuka adalah lebih tidak memuaskan Contohnya, model besar berbilang modal berkuasa semasa seperti LLaVa-NeXT-34B, InternVL-Chat-V1.5, dsb., belum mencapai kadar ketepatan 20%. . Selain itu, kebanyakan model besar berbilang modal tidak pandai menggunakan sepenuhnya maklumat visual untuk menyelesaikan tugas penaakulan yang kompleks Ini juga merupakan perbezaan paling ketara antara model besar dan manusia (manusia cenderung untuk mengutamakan pemprosesan maklumat visual ). Oleh itu, keputusan ujian di OlympicArena menunjukkan bahawa model itu masih ketinggalan berbanding manusia dalam menyelesaikan masalah saintifik, dan keupayaan penaakulan yang wujud masih perlu dipertingkatkan secara berterusan untuk membantu penyelidikan saintifik manusia dengan lebih baik.
- Alamat kertas: https://arxiv.org/pdf/2406.12753
-
Alamat projek: https://gair-nlp.github.io/OlympicArena/: ://github.com/GAIR-NLP/ArenaOlympic mempertimbangkan kedua-dua penilaian yang betul dan salah, dan penilaian setiap langkah penaakulan).
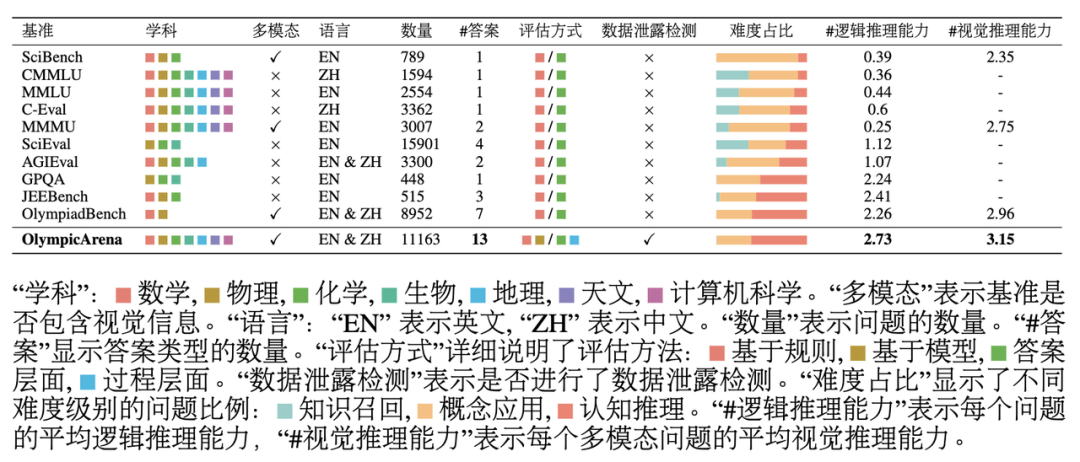
- Komprehensif: OlympicArena merangkumi sejumlah 11,163 soalan daripada 62 pertandingan Olimpik berbeza, merangkumi tujuh subjek teras: matematik, fizik, kimia, biologi, geografi, astronomi dan komputer, melibatkan 34 cabang profesional. Pada masa yang sama, tidak seperti penanda aras sebelumnya yang kebanyakannya tertumpu pada soalan objektif seperti soalan aneka pilihan, OlympicArena menyokong pelbagai jenis soalan, termasuk ungkapan, persamaan, selang waktu, menulis persamaan kimia dan juga soalan pengaturcaraan. Selain itu, OlympicArena menyokong pelbagai modaliti (hampir separuh daripada soalan mengandungi gambar), dan menggunakan format input (imej teks berjalin) yang paling konsisten dengan realiti, menguji sepenuhnya penggunaan maklumat visual untuk membantu model besar dalam menyelesaikan tugasan. Keupayaan untuk menaakul.
- Amat mencabar: Tidak seperti penanda aras sebelumnya yang sama ada tertumpu pada soalan sekolah menengah (peperiksaan masuk kolej) atau soalan kolej, OlympicArena lebih menumpukan pada pemeriksaan tulen kebolehan penaakulan yang kompleks dan bukannya pada pengetahuan besar tentang titik ingatan , keupayaan mengingat atau keupayaan aplikasi mudah. Oleh itu, semua soalan dalam OlympicArena adalah daripada tahap kesukaran Olympiad. Selain itu, untuk menilai secara terperinci prestasi model besar dalam pelbagai jenis keupayaan penaakulan, pasukan penyelidik juga merumuskan 8 jenis keupayaan penaakulan logik dan 5 jenis keupayaan penaakulan visual Selepas itu, mereka secara khusus menganalisis prestasi besar sedia ada model dalam pelbagai jenis keupayaan penaakulan Perbezaan dalam prestasi dalam kebolehan penaakulan.
- Ketegasan: Membimbing pembangunan sihat model besar ialah peranan yang harus dimainkan oleh akademia Pada masa ini, dalam penanda aras awam, banyak model besar yang popular akan mengalami masalah kebocoran data (iaitu, data ujian penanda aras dibocorkan dalam. model besar) dalam data latihan). Oleh itu, pasukan penyelidik secara khusus menguji kebocoran data OlympicArena pada beberapa model besar yang popular untuk mengesahkan keberkesanan penanda aras dengan lebih teliti.
- Penilaian terperinci: Penanda aras sebelumnya selalunya hanya menilai sama ada jawapan akhir yang diberikan oleh model besar adalah konsisten dengan jawapan yang betul Ini adalah berat sebelah dalam penilaian masalah penaakulan yang sangat kompleks dan tidak dapat mencerminkan model semasa . Kemahiran penaakulan yang lebih realistik. Oleh itu, selain menilai jawapan, pasukan penyelidik juga menyertakan penilaian terhadap ketepatan proses soalan (langkah). Pada masa yang sama, pasukan penyelidik juga menganalisis hasil yang berbeza daripada pelbagai dimensi yang berbeza, seperti menganalisis perbezaan prestasi model dalam disiplin yang berbeza, modaliti yang berbeza dan keupayaan penaakulan yang berbeza.
Perbandingan dengan penanda aras yang berkaitan
Seperti yang dapat dilihat dari jadual di atas: OlympicArena mempunyai kesan yang besar terhadap keupayaan penaakulan dari segi liputan mata pelajaran, bahasa dan juga liputan kepelbagaian jenis soalan Kedalaman penyiasatan dan kelengkapan kaedah penilaian adalah berbeza secara ketara daripada penanda aras sedia ada yang memberi tumpuan kepada penilaian isu saintifik. Analisis Eksperimen KEPUTUSAN KELUARGA KELUARGA KEPADA MODEL BESAR MULTIMODAL MODEL BESAR (LMM) dan Model Besar Teks Plain (LLM) pada Olympicarena. Untuk model besar berbilang modal, bentuk input imej teks berselang digunakan untuk model teks biasa besar, ujian dijalankan di bawah dua tetapan, iaitu input teks biasa tanpa sebarang maklumat gambar (teks sahaja LLM). input teks yang mengandungi maklumat perihalan imej (kapsyen imej + LLM). Tujuan menambah ujian model besar teks biasa bukan sahaja untuk meluaskan skop aplikasi penanda aras ini (supaya semua LLM boleh mengambil bahagian dalam penarafan), tetapi juga untuk lebih memahami dan menganalisis prestasi model besar berbilang modal sedia ada dalam yang sepadan Berbanding dengan model teks tulen yang besar, sama ada ia boleh menggunakan sepenuhnya maklumat gambar untuk meningkatkan keupayaan menyelesaikan masalahnya. Semua eksperimen menggunakan gesaan CoT pukulan sifar, yang disesuaikan oleh pasukan penyelidik untuk setiap jenis jawapan dan menentukan format output untuk memudahkan pengekstrakan jawapan dan pemadanan berasaskan peraturan. Ketepatan model berbeza dalam subjek berbeza OlympicArena Soalan pengaturcaraan CS menggunakan indeks pas@k yang tidak berat sebelah, dan selebihnya menggunakan indeks ketepatan. Dapat dilihat daripada keputusan percubaan dalam jadual bahawa semua model besar arus perdana yang ada di pasaran pada masa ini gagal menunjukkan tahap yang tinggi Malah model besar yang paling canggih GPT-4o mempunyai ketepatan keseluruhan hanya 39.97%, manakala yang lain The. ketepatan keseluruhan model sumber terbuka sukar untuk mencapai 20%. Perbezaan yang jelas ini menyerlahkan cabaran penanda aras ini dan membuktikan bahawa ia telah memainkan peranan yang besar dalam menolak had atas keupayaan penaakulan AI semasa. Selain itu, pasukan penyelidik memerhatikan bahawa matematik dan fizik masih merupakan dua subjek yang paling sukar, kerana mereka lebih bergantung kepada kebolehan penaakulan yang kompleks dan fleksibel, mempunyai lebih banyak langkah dalam penaakulan, dan memerlukan kemahiran berfikir yang lebih komprehensif dan diterapkan. Pelbagai. Dalam mata pelajaran seperti biologi dan geografi, kadar ketepatan adalah agak tinggi, kerana subjek ini memberi lebih perhatian kepada keupayaan untuk menggunakan pengetahuan saintifik yang kaya untuk menyelesaikan dan menganalisis masalah praktikal, memberi tumpuan kepada pemeriksaan kebolehan penculikan dan penaakulan sebab, berbanding dengan kompleks. induksi, penaakulan deduktif, model besar lebih mahir menganalisis subjek tersebut dengan bantuan pengetahuan yang kaya yang diperoleh semasa peringkat latihan mereka sendiri. Pertandingan pengaturcaraan komputer juga terbukti sangat sukar, dengan beberapa model sumber terbuka bahkan tidak dapat menyelesaikan sebarang masalah di dalamnya (0 ketepatan), yang menunjukkan sejauh mana model semasa mampu mereka bentuk algoritma yang berkesan untuk diselesaikan masalah kompleks secara pemrograman Masih terdapat banyak ruang untuk penambahbaikan. Perlu dinyatakan bahawa niat asal OlympicArena bukanlah untuk mengejar kesukaran soalan secara membabi buta, tetapi untuk memanfaatkan sepenuhnya keupayaan model besar untuk merentas disiplin dan menggunakan pelbagai keupayaan penaakulan untuk menyelesaikan masalah saintifik praktikal. Keupayaan berfikir yang disebutkan di atas menggunakan penaakulan yang kompleks, keupayaan untuk menggunakan pengetahuan saintifik yang kaya untuk menyelesaikan dan menganalisis masalah praktikal, dan keupayaan untuk menulis program yang cekap dan tepat untuk menyelesaikan masalah adalah sangat diperlukan dalam bidang penyelidikan saintifik, dan sentiasa penanda aras untuk penanda aras ini. Analisis eksperimen berbutir halusUntuk mencapai analisis keputusan eksperimen yang lebih terperinci, pasukan penyelidik menjalankan penilaian lanjut berdasarkan modaliti dan keupayaan penaakulan yang berbeza. Selain itu, pasukan penyelidik juga menjalankan penilaian dan analisis proses penaakulan model terhadap soalan. Penemuan utama adalah seperti berikut: Model berprestasi berbeza dalam penaakulan logik dan kebolehan penaakulan visual yang berbeza
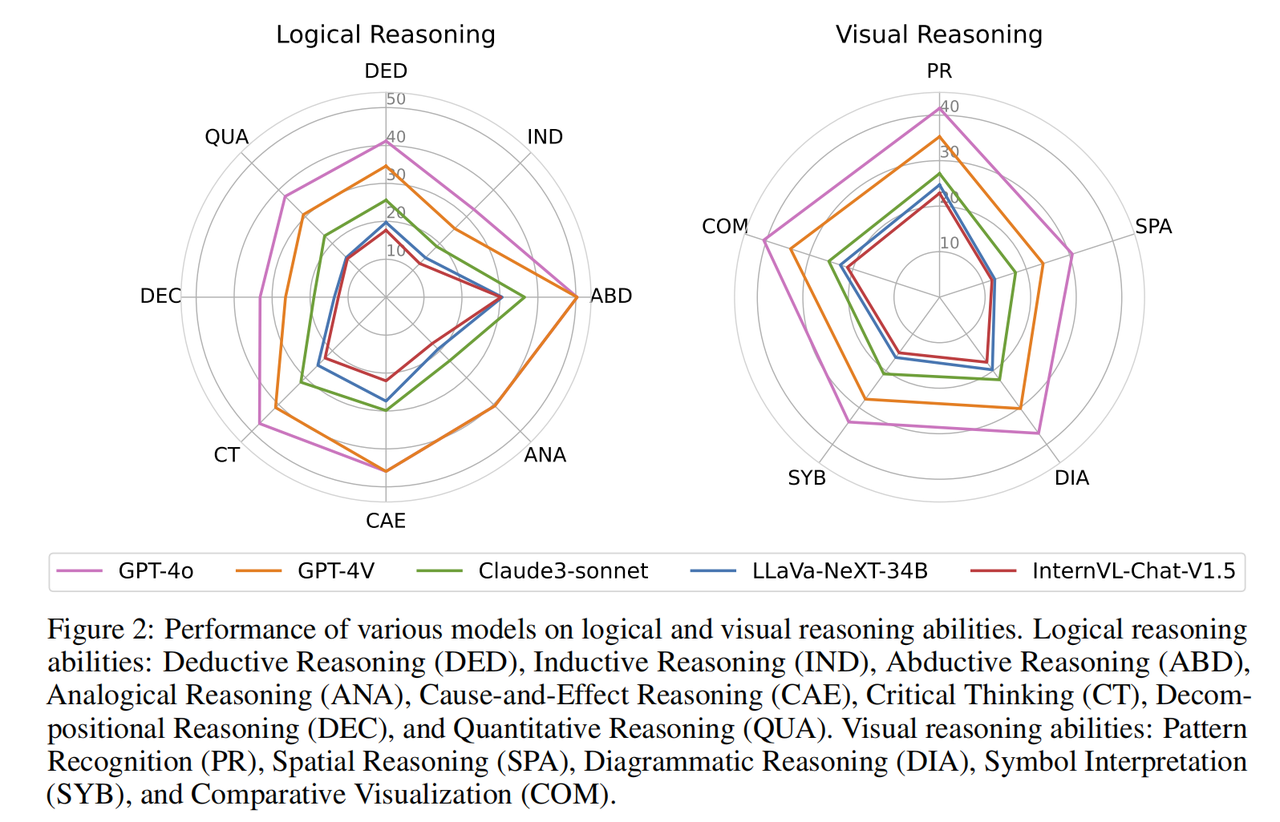
Prestasi setiap model dalam penaakulan logik dan kebolehan penaakulan visual. Kebolehan penaakulan logik termasuk: penaakulan deduktif (DED), penaakulan induktif (IND), penaakulan abduktif (ABD), penaakulan analogi (ANA), penaakulan kausal (CAE), pemikiran kritis (CT), penaakulan penguraian (DEC) dan Penaakulan kuantitatif ( QUA). Kebolehan penaakulan visual termasuk: pengecaman corak (PR), penaakulan spatial (SPA), penaakulan diagram (DIA), tafsiran simbolik (SYB), dan perbandingan visual (COM).
Hampir semua model mempunyai trend prestasi yang sama dalam kebolehan penaakulan logik yang berbeza. Mereka cemerlang dalam penaakulan penculikan dan sebab dan dapat mengenal pasti hubungan sebab dan akibat daripada maklumat yang diberikan. Sebaliknya, model berprestasi buruk pada penaakulan induktif dan penaakulan penguraian. Ini disebabkan oleh kepelbagaian dan sifat tidak konvensional masalah peringkat Olimpik, yang memerlukan keupayaan untuk memecahkan masalah kompleks kepada sub-masalah yang lebih kecil, yang bergantung pada model untuk berjaya menyelesaikan setiap sub-masalah dan menggabungkan sub-masalah untuk menyelesaikan masalah yang lebih besar. Dari segi keupayaan penaakulan visual, model menunjukkan prestasi yang lebih baik dalam pengecaman corak dan perbandingan visual. Namun, mereka menghadapi kesukaran melaksanakan tugas yang melibatkan penaakulan spatial dan geometri serta tugasan yang memerlukan pemahaman simbol abstrak. Daripada analisis terperinci kebolehan penaakulan yang berbeza, kebolehan yang tidak dimiliki oleh model besar (seperti penguraian masalah kompleks, penaakulan visual angka geometri, dll.) adalah sangat diperlukan dan kebolehan penting dalam penyelidikan saintifik, menunjukkan bahawa masih terdapat masa yang panjang. cara untuk pergi sebelum AI benar-benar boleh membantu manusia dalam penyelidikan saintifik dalam semua aspek.
Perbandingan model pelbagai mod (LMM) yang berbeza dan model teks sahaja (LLM) yang sepadan dalam tiga tetapan percubaan berbeza.
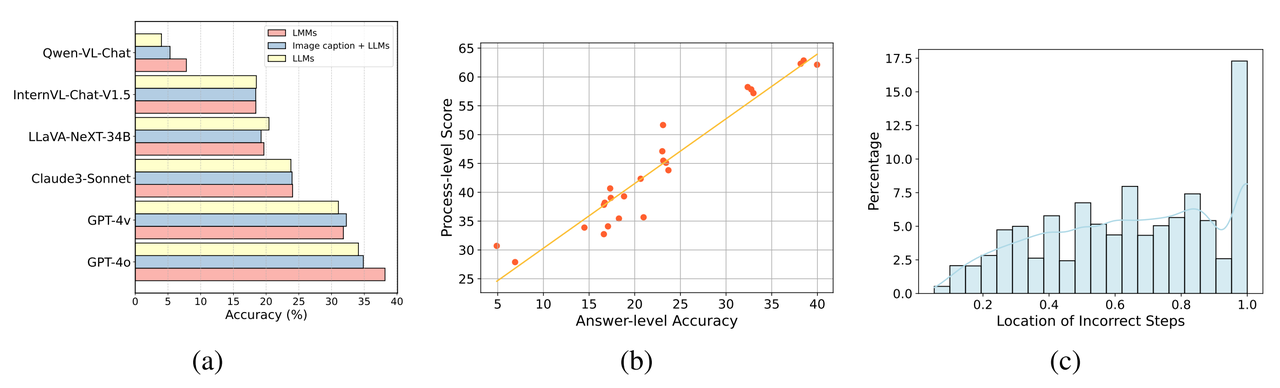
Kebanyakan model multi-modal (LMM) masih tidak pandai menggunakan maklumat visual untuk membantu dalam penaakulanSeperti yang ditunjukkan dalam (a) di atas, hanya terdapat beberapa model multi-modal yang besar (seperti GPT -4o dan Qwen-VL -Chat) menunjukkan peningkatan prestasi yang ketara berbanding rakan teks sahaja apabila diberikan input imej. Banyak model berbilang modal besar tidak menunjukkan peningkatan prestasi semasa memasukkan imej, malah menunjukkan penurunan prestasi semasa memproses imej. Sebab yang mungkin termasuk:
- Apabila teks dan imej dimasukkan bersama, LMM mungkin memberi lebih perhatian kepada teks dan mengabaikan maklumat dalam imej.
- Sesetengah LMM mungkin kehilangan beberapa keupayaan bahasa sedia ada mereka (cth., keupayaan penaakulan) apabila melatih keupayaan visual berdasarkan model teks mereka, yang amat jelas dalam senario kompleks projek ini.
- Soalan penanda aras ini menggunakan format input pembalut imej teks yang kompleks Sesetengah model tidak dapat menyokong format ini dengan baik, mengakibatkan ketidakupayaan mereka untuk memproses dan memahami maklumat kedudukan imej yang dibenamkan dalam teks.
Dalam penyelidikan saintifik, ia selalunya disertai dengan jumlah maklumat visual yang sangat besar seperti carta, angka geometri dan data visual Hanya apabila AI boleh menggunakan keupayaan visualnya dengan mahir untuk membantu penaakulan, ia boleh membantu mempromosikan Kecekapan dan inovasi penyelidikan saintifik telah menjadi alat yang berkuasa untuk menyelesaikan masalah saintifik yang kompleks.
Gambar kiri: Perkaitan antara ketepatan jawapan dan ketepatan proses untuk semua model dalam semua soalan di mana proses inferens dinilai. Kanan: Taburan lokasi langkah proses yang salah.
Analisis hasil penilaian bagi langkah inferensDengan menjalankan penilaian terperinci tentang ketepatan langkah inferens model, pasukan penyelidik mendapati:
- dalam angka yang ditunjukkan b) di atas, penilaian peringkat langkah Biasanya terdapat tahap persetujuan yang tinggi antara keputusan dan penilaian yang bergantung semata-mata pada jawapan. Apabila model menjana jawapan yang betul, kualiti proses inferensnya kebanyakannya lebih tinggi.
- Ketepatan proses penaakulan biasanya lebih tinggi daripada ketepatan hanya melihat jawapan. Ini menunjukkan bahawa walaupun untuk masalah yang sangat kompleks, model boleh melakukan beberapa langkah perantaraan dengan betul. Oleh itu, model mungkin mempunyai potensi besar dalam penaakulan kognitif, yang membuka hala tuju penyelidikan baharu untuk penyelidik. Pasukan penyelidik juga mendapati bahawa dalam beberapa disiplin, beberapa model yang menunjukkan prestasi yang baik apabila dinilai semata-mata pada jawapan menunjukkan prestasi yang buruk pada proses inferens. Pasukan penyelidik membuat spekulasi bahawa ini adalah kerana model kadangkala mengabaikan kebolehpercayaan langkah perantaraan apabila menjana jawapan, walaupun langkah ini mungkin tidak penting untuk keputusan akhir.
- Selain itu, pasukan penyelidik menjalankan analisis statistik taburan lokasi langkah-langkah ralat (lihat Rajah c) dan mendapati bahagian ralat yang lebih tinggi berlaku dalam langkah-langkah penaakulan kemudian dalam soalan. Ini menunjukkan bahawa apabila proses penaakulan terkumpul, model lebih terdedah kepada ralat dan menghasilkan pengumpulan ralat, yang menunjukkan bahawa model masih mempunyai banyak ruang untuk penambahbaikan apabila berhadapan dengan penaakulan logik rantaian panjang.
Pasukan ini juga menyeru semua penyelidik untuk memberi lebih perhatian kepada penyeliaan dan penilaian proses inferens model dalam tugas inferens AI. Ini bukan sahaja dapat meningkatkan kredibiliti dan ketelusan sistem AI dan membantu lebih memahami laluan penaakulan model, tetapi juga mengenal pasti pautan lemah model dalam penaakulan kompleks, dengan itu membimbing penambahbaikan struktur model dan kaedah latihan. Melalui penyeliaan proses yang teliti, potensi AI boleh diterokai dengan lebih lanjut dan penggunaannya yang meluas dalam penyelidikan saintifik dan aplikasi praktikal digalakkan. Analisis jenis ralat model
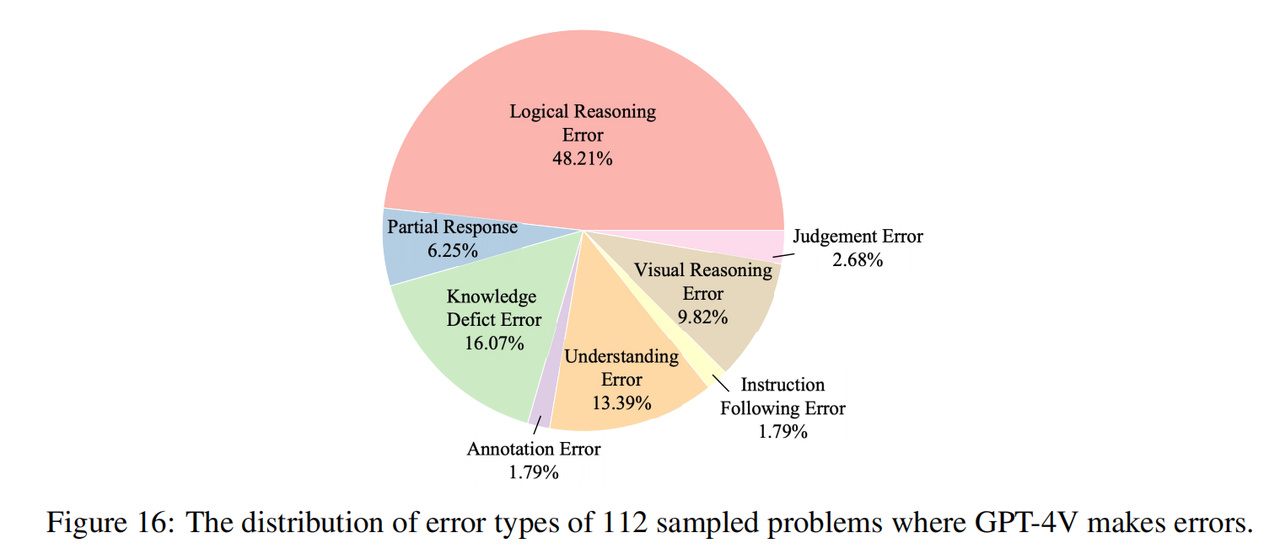
Pasukan penyelidik mengambil sampel 112 soalan dengan jawapan yang salah dalam GPT-4V (16 soalan dalam setiap subjek, 8 daripadanya adalah soalan teks tulen dan 8 daripadanya ialah soalan berbilang modal), dan menandakan secara manual sebab ralat ini. Seperti yang ditunjukkan dalam rajah di atas, ralat penaakulan (termasuk ralat penaakulan logik dan ralat penaakulan visual) merupakan punca terbesar kesilapan, yang menunjukkan bahawa penanda aras kami secara berkesan menyerlahkan kelemahan model semasa dalam keupayaan penaakulan kognitif, yang konsisten dengan niat asal. daripada pasukan penyelidik. Selain itu, sebahagian besar kesilapan juga datang dari kekurangan pengetahuan (walaupun soalan Olimpik hanya berdasarkan pengetahuan sekolah menengah), yang menunjukkan bahawa model semasa kurang pengetahuan domain dan lebih tidak dapat digunakan pengetahuan ini untuk membantu penaakulan. Satu lagi punca ralat yang biasa ialah berat sebelah pemahaman, yang boleh dikaitkan dengan salah faham model terhadap konteks dan kesukaran mengintegrasikan struktur bahasa yang kompleks dan maklumat multimodal. . Buat jumlah yang betul. Memandangkan skala korpus pra-latihan terus berkembang, adalah penting untuk mengesan potensi kebocoran data pada penanda aras. Kelegapan proses pra-latihan sering menjadikan tugas ini mencabar. Untuk tujuan ini, pasukan penyelidik menggunakan metrik pengesanan kebocoran peringkat contoh yang baru dicadangkan yang dipanggil "ketepatan ramalan N-gram." Metrik ini sama rata mengambil sampel beberapa titik permulaan daripada setiap kejadian, meramalkan N-gram seterusnya untuk setiap titik permulaan dan menyemak sama ada semua N-gram yang diramalkan adalah betul untuk menentukan sama ada model mungkin menemuinya semasa fasa latihan ini. Pasukan penyelidik menggunakan metrik ini pada semua model asas yang tersedia.
Seperti yang ditunjukkan dalam rajah di atas, model arus perdana tidak mempunyai masalah kebocoran data yang ketara di Arena Olimpik Walaupun terdapat kebocoran, jumlahnya adalah tidak ketara berbanding set data penanda aras yang lengkap. Sebagai contoh, model Qwen1.5-32B dengan kebocoran paling banyak hanya mempunyai 43 kejadian kebocoran yang disyaki dikesan. Ini secara semula jadi menimbulkan persoalan: Bolehkah model menjawab soalan contoh yang bocor ini dengan betul? Mengenai isu ini, pasukan penyelidik terkejut apabila mendapati bahawa walaupun untuk soalan bocor, model yang sepadan boleh menjawab sangat sedikit soalan dengan betul. Keputusan ini semua menunjukkan bahawa penanda aras telah mengalami sedikit kesan daripada pelanggaran data dan masih agak mencabar untuk mengekalkan keberkesanannya untuk masa yang lama akan datang.
Walaupun OlympicArena mempunyai nilai yang sangat tinggi, pasukan penyelidik menyatakan masih banyak kerja yang perlu dilakukan pada masa hadapan. Pertama sekali, penanda aras OlympicArena pasti akan memperkenalkan beberapa data yang bising, dan pengarang akan secara aktif menggunakan maklum balas komuniti untuk terus menambah baik dan memperbaikinya. Di samping itu, pasukan penyelidik merancang untuk mengeluarkan versi baharu penanda aras setiap tahun untuk mengurangkan lagi isu yang berkaitan dengan pelanggaran data. Tambahan pula, dalam jangka panjang, penanda aras semasa adalah terhad untuk menilai keupayaan model untuk menyelesaikan masalah yang kompleks.
Pada masa hadapan, semua orang berharap kecerdasan buatan dapat membantu dalam menyelesaikan tugasan komprehensif yang kompleks dan menunjukkan nilai dalam aplikasi praktikal, seperti AI4Science dan AI4Engineering, yang akan menjadi matlamat dan tujuan reka bentuk penanda aras masa hadapan. Walaupun begitu, Olympic Arena masih memainkan peranan penting sebagai pemangkin dalam mempromosikan AI ke arah superintelligence. Visi: Momen gemilang kemajuan bersama antara manusia dan AI
Pada masa hadapan, kami mempunyai sebab untuk percaya bahawa apabila teknologi AI terus matang dan senario aplikasi terus berkembang, OlympicArena akan menjadi lebih daripada sekadar tempat untuk menilai keupayaan AI, akan menjadi peringkat untuk menunjukkan potensi aplikasi AI dalam pelbagai bidang. Sama ada dalam penyelidikan saintifik, reka bentuk kejuruteraan, atau dalam bidang yang lebih luas seperti pertandingan sukan, AI akan menyumbang kepada pembangunan masyarakat manusia dengan cara tersendiri.
Akhirnya, pasukan penyelidik juga mengatakan bahawa Olimpik Subjek akan menjadi permulaan kepada Arena Olimpik, dan lebih banyak keupayaan AI yang layak untuk diterokai secara berterusan Contohnya, arena sukan Olimpik akan menjadi arena kecerdasan yang terkandung pada masa hadapan.
Pautan rujukan:
[1] Latihan Prastruktur semula, arXiv 2022, Weizhe Yuan, Pengfei Liu
Atas ialah kandungan terperinci Dari peperiksaan kemasukan kolej ke arena Olimpik: pertempuran muktamad antara model besar dan kecerdasan manusia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!









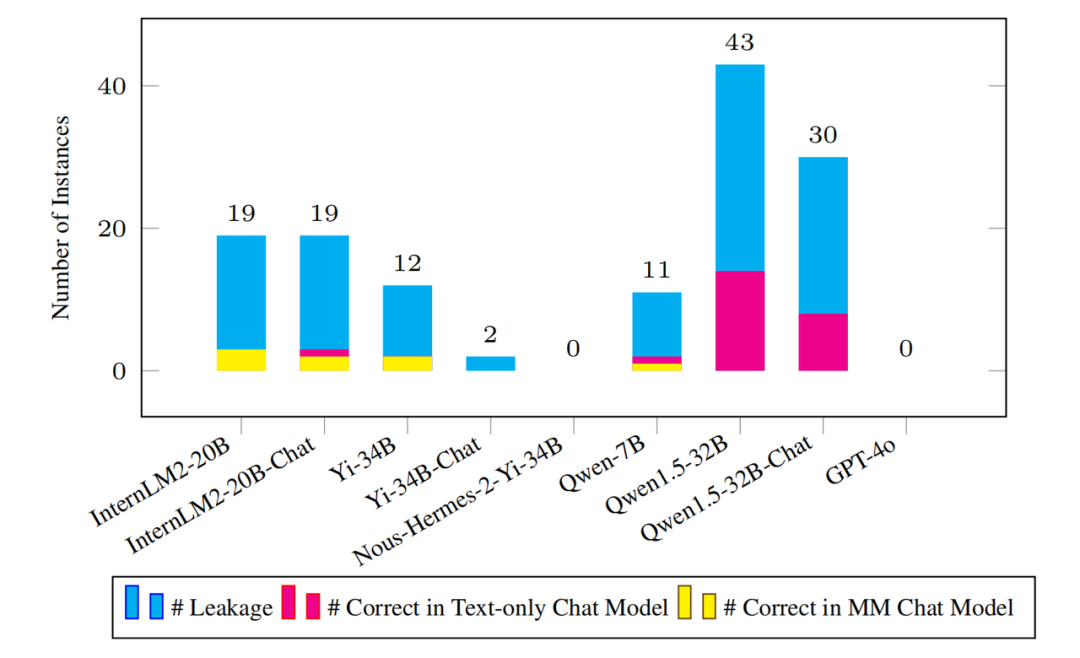 Mengenai isu ini, pasukan penyelidik terkejut apabila mendapati bahawa walaupun untuk soalan bocor, model yang sepadan boleh menjawab sangat sedikit soalan dengan betul. Keputusan ini semua menunjukkan bahawa penanda aras telah mengalami sedikit kesan daripada pelanggaran data dan masih agak mencabar untuk mengekalkan keberkesanannya untuk masa yang lama akan datang.
Mengenai isu ini, pasukan penyelidik terkejut apabila mendapati bahawa walaupun untuk soalan bocor, model yang sepadan boleh menjawab sangat sedikit soalan dengan betul. Keputusan ini semua menunjukkan bahawa penanda aras telah mengalami sedikit kesan daripada pelanggaran data dan masih agak mencabar untuk mengekalkan keberkesanannya untuk masa yang lama akan datang. 
