
Rumah >Peranti teknologi >AI >Melangkaui kaedah CVPR 2024, DynRefer mencapai berbilang SOTA dalam tugas pengecaman pelbagai mod peringkat serantau
Melangkaui kaedah CVPR 2024, DynRefer mencapai berbilang SOTA dalam tugas pengecaman pelbagai mod peringkat serantau

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-06-20 20:31:51730semak imbas
Untuk mencapai pemahaman multi-modal peringkat serantau ketepatan tinggi, kertas kerja ini mencadangkan skema resolusi dinamik untuk mensimulasikan sistem kognitif visual manusia.
Pengarang artikel ini adalah daripada Makmal LAMP Akademi Sains Universiti Cina Pengarang pertama Zhao Yuzhong ialah pelajar kedoktoran Universiti Akademi Sains Cina pada tahun 2023, dan pengarang bersama Liu. Feng ialah pelajar kedoktoran langsung Universiti Akademi Sains Cina pada tahun 2020. Arah penyelidikan utama mereka ialah model bahasa visual dan persepsi objek visual.

Tajuk kertas: DynRefer: Menyelidiki Tugasan Pelbagai Modaliti peringkat Wilayah melalui Resolusi Dinamik Pautan kertas: https://arxiv.org/abs/2401 https://arxiv.org/abs/071https://kod. ://github.com/callsys/DynRefer


Kaedah
1. Simulasikan imej resolusi dinamik (Pembinaan berbilang paparan).
 mewakili saiz keseluruhan imej, dan t mewakili pekali interpolasi. Semasa latihan, kami memilih n paparan secara rawak daripada paparan calon untuk mensimulasikan imej yang dijana disebabkan oleh pandangan dan pergerakan mata yang pantas. N pandangan ini sepadan dengan pekali interpolasi t, iaitu
mewakili saiz keseluruhan imej, dan t mewakili pekali interpolasi. Semasa latihan, kami memilih n paparan secara rawak daripada paparan calon untuk mensimulasikan imej yang dijana disebabkan oleh pandangan dan pergerakan mata yang pantas. N pandangan ini sepadan dengan pekali interpolasi t, iaitu  . Kami mengekalkan paparan yang mengandungi hanya kawasan rujukan (iaitu
. Kami mengekalkan paparan yang mengandungi hanya kawasan rujukan (iaitu  ). Pandangan ini telah terbukti secara eksperimen untuk membantu mengekalkan butiran serantau, yang penting untuk semua tugasan pelbagai mod serantau.
). Pandangan ini telah terbukti secara eksperimen untuk membantu mengekalkan butiran serantau, yang penting untuk semua tugasan pelbagai mod serantau. 


 . Ini ditunjukkan di sebelah kiri Rajah 3. Pembenaman rantau ini tidak dijajarkan secara spatial disebabkan oleh ralat spatial yang diperkenalkan oleh pemangkasan, saiz semula dan Penjajaran RoI. Diilhamkan oleh operasi lilitan boleh ubah bentuk, kami mencadangkan modul penjajaran untuk mengurangkan bias dengan menjajarkan
. Ini ditunjukkan di sebelah kiri Rajah 3. Pembenaman rantau ini tidak dijajarkan secara spatial disebabkan oleh ralat spatial yang diperkenalkan oleh pemangkasan, saiz semula dan Penjajaran RoI. Diilhamkan oleh operasi lilitan boleh ubah bentuk, kami mencadangkan modul penjajaran untuk mengurangkan bias dengan menjajarkan 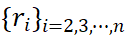 ke
ke  , dengan
, dengan  ialah pembenaman rantau pengekodan paparan yang mengandungi hanya rantau rujukan. Untuk setiap pembenaman rantau
ialah pembenaman rantau pengekodan paparan yang mengandungi hanya rantau rujukan. Untuk setiap pembenaman rantau  , ia mula-mula digabungkan dengan
, ia mula-mula digabungkan dengan  dan kemudian peta mengimbangi 2D dikira melalui lapisan konvolusi. Ciri spatial
dan kemudian peta mengimbangi 2D dikira melalui lapisan konvolusi. Ciri spatial  kemudiannya disampel semula berdasarkan offset 2D. Akhir sekali, benam kawasan yang dijajarkan disatukan di sepanjang dimensi saluran dan digabungkan melalui lapisan linear. Output dimampatkan lagi melalui modul pensampelan semula visual, iaitu Q-bekas, dengan itu mengekstrak perwakilan serantau bagi rantau rujukan
kemudiannya disampel semula berdasarkan offset 2D. Akhir sekali, benam kawasan yang dijajarkan disatukan di sepanjang dimensi saluran dan digabungkan melalui lapisan linear. Output dimampatkan lagi melalui modul pensampelan semula visual, iaitu Q-bekas, dengan itu mengekstrak perwakilan serantau bagi rantau rujukan  imej asal x (
imej asal x ( dalam Rajah 3).
dalam Rajah 3). 
 generasi. Kami menggunakan penyahkod pengecaman berasaskan pertanyaan yang ringan untuk penjanaan label rantau. Penyahkod
generasi. Kami menggunakan penyahkod pengecaman berasaskan pertanyaan yang ringan untuk penjanaan label rantau. Penyahkod  ditunjukkan dalam Rajah 3 (kanan). Proses penandaan dilengkapkan dengan mengira keyakinan teg yang dipratentukan menggunakan teg sebagai pertanyaan,
ditunjukkan dalam Rajah 3 (kanan). Proses penandaan dilengkapkan dengan mengira keyakinan teg yang dipratentukan menggunakan teg sebagai pertanyaan, kepada huraian bahasa.

 . Paparan satu ditetapkan (
. Paparan satu ditetapkan ( ), paparan dua dipilih atau ditetapkan secara rawak.
), paparan dua dipilih atau ditetapkan secara rawak.  daripada sampel n pandangan, kita boleh mendapatkan perwakilan serantau dengan ciri resolusi dinamik. Untuk menilai sifat pada resolusi dinamik yang berbeza, kami melatih model DynRefer dwi-pandangan (n=2) dan menilainya pada empat tugas berbilang modal. Seperti yang dapat dilihat daripada lengkung dalam Rajah 4, pengesanan atribut mencapai hasil yang lebih baik untuk paparan tanpa maklumat kontekstual (
daripada sampel n pandangan, kita boleh mendapatkan perwakilan serantau dengan ciri resolusi dinamik. Untuk menilai sifat pada resolusi dinamik yang berbeza, kami melatih model DynRefer dwi-pandangan (n=2) dan menilainya pada empat tugas berbilang modal. Seperti yang dapat dilihat daripada lengkung dalam Rajah 4, pengesanan atribut mencapai hasil yang lebih baik untuk paparan tanpa maklumat kontekstual ( ). Ini boleh dijelaskan oleh fakta bahawa tugas sedemikian sering memerlukan maklumat serantau yang terperinci. Untuk tugasan kapsyen peringkat Wilayah dan Kapsyen padat, paparan kaya konteks (
). Ini boleh dijelaskan oleh fakta bahawa tugas sedemikian sering memerlukan maklumat serantau yang terperinci. Untuk tugasan kapsyen peringkat Wilayah dan Kapsyen padat, paparan kaya konteks ( ) diperlukan untuk memahami sepenuhnya kawasan rujukan. Adalah penting untuk ambil perhatian bahawa pandangan dengan terlalu banyak konteks (
) diperlukan untuk memahami sepenuhnya kawasan rujukan. Adalah penting untuk ambil perhatian bahawa pandangan dengan terlalu banyak konteks ( ) merendahkan prestasi pada semua tugasan kerana ia memperkenalkan terlalu banyak maklumat yang tidak berkaitan wilayah. Apabila jenis tugasan diketahui, kita boleh mencuba pandangan yang sesuai berdasarkan ciri tugasan. Apabila jenis tugasan tidak diketahui, kami mula-mula membina satu set pandangan calon di bawah pekali interpolasi yang berbeza t,
) merendahkan prestasi pada semua tugasan kerana ia memperkenalkan terlalu banyak maklumat yang tidak berkaitan wilayah. Apabila jenis tugasan diketahui, kita boleh mencuba pandangan yang sesuai berdasarkan ciri tugasan. Apabila jenis tugasan tidak diketahui, kami mula-mula membina satu set pandangan calon di bawah pekali interpolasi yang berbeza t,  . Daripada set calon, n paparan diambil melalui algoritma carian tamak. Fungsi objektif carian ditakrifkan sebagai:
. Daripada set calon, n paparan diambil melalui algoritma carian tamak. Fungsi objektif carian ditakrifkan sebagai:  di mana
di mana  mewakili pekali interpolasi bagi pandangan ke-i,
mewakili pekali interpolasi bagi pandangan ke-i,  mewakili pandangan ke-i, pHASH (・) mewakili fungsi cincang imej persepsi dan
mewakili pandangan ke-i, pHASH (・) mewakili fungsi cincang imej persepsi dan  mewakili XOR operasi. Untuk membandingkan maklumat pandangan daripada perspektif global, kami menggunakan fungsi "pHASH (・)" untuk menukar paparan daripada domain spatial kepada domain kekerapan dan kemudian mengekodnya ke dalam kod cincang. Untuk item ini
mewakili XOR operasi. Untuk membandingkan maklumat pandangan daripada perspektif global, kami menggunakan fungsi "pHASH (・)" untuk menukar paparan daripada domain spatial kepada domain kekerapan dan kemudian mengekodnya ke dalam kod cincang. Untuk item ini  , kami mengurangkan berat paparan kaya konteks untuk mengelakkan daripada memperkenalkan terlalu banyak maklumat berlebihan.
, kami mengurangkan berat paparan kaya konteks untuk mengelakkan daripada memperkenalkan terlalu banyak maklumat berlebihan.





Baris 1-6: Berbilang paparan dinamik rawak adalah lebih baik daripada paparan tetap. Baris 6-10: Lihat pilihan dengan memaksimumkan maklumat adalah lebih baik daripada memilih paparan secara rawak. Baris 10-13: Latihan pelbagai tugas boleh mempelajari perwakilan wilayah yang lebih baik. .
Atas ialah kandungan terperinci Melangkaui kaedah CVPR 2024, DynRefer mencapai berbilang SOTA dalam tugas pengecaman pelbagai mod peringkat serantau. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Mengambil 'Exhibition Express', Qingdao Artificial Intelligence Industrial Park meneroka cara baharu untuk menarik pelaburan
- Artikel ciri|Permintaan untuk kuasa pengkomputeran meletup di bawah ledakan model besar AI: Lingang mahu membina industri berpuluh-puluh bilion, dan SenseTime akan menjadi 'tuan rantai'
- Robot humanoid tujuan am domestik akan dikeluarkan, dan industri akan mempercepatkan kejayaan
- Liu Qiang: Membina ekosistem kandungan industri pelancongan budaya Internet generasi seterusnya
- Perkembangan pesat sistem pengendalian Hongmeng pada pelbagai peranti akan membuka industri baharu bernilai trilion