
Rumah >Peranti teknologi >AI >Gunakan NVIDIA Riva untuk menggunakan perkhidmatan AI suara Cina peringkat perusahaan dengan cepat dan mengoptimumkan serta mempercepatkannya
Gunakan NVIDIA Riva untuk menggunakan perkhidmatan AI suara Cina peringkat perusahaan dengan cepat dan mengoptimumkan serta mempercepatkannya

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBasal
- 2024-06-10 21:57:481230semak imbas
1. Gambaran Keseluruhan Riva
1. Ia adalah alat yang sangat disesuaikan dan menggunakan pecutan GPU. Banyak model pra-latihan disediakan pada NGC Model ini sedia untuk digunakan di luar kotak dan boleh digunakan terus menggunakan penyelesaian ASR dan TTS yang disediakan oleh Riva.
 Untuk memenuhi keperluan medan tertentu atau membangunkan fungsi tersuai, pengguna juga boleh menggunakan NeMo untuk melatih semula atau memperhalusi model ini. Ini meningkatkan lagi prestasi model dan menjadikannya lebih mudah disesuaikan dengan keperluan pengguna.
Untuk memenuhi keperluan medan tertentu atau membangunkan fungsi tersuai, pengguna juga boleh menggunakan NeMo untuk melatih semula atau memperhalusi model ini. Ini meningkatkan lagi prestasi model dan menjadikannya lebih mudah disesuaikan dengan keperluan pengguna.
Riva+Skills ialah alat yang sangat disesuaikan yang memanfaatkan GPU untuk mempercepatkan pengecaman pertuturan penstriman masa nyata dan sintesis pertuturan, serta boleh mengendalikan beribu-ribu permintaan serentak secara serentak. Ia menyokong berbilang platform penggunaan, termasuk tempatan, awan dan bahagian hujung.
2. Riva ASR
Dari segi pengecaman pertuturan, Riva menggunakan model SOTA yang sangat tepat, seperti Citrinet, Conformer dan FastConformer yang dibangunkan sendiri oleh NeMo. Pada masa ini, Riva menyokong lebih daripada 10 model bahasa tunggal, dan turut menyokong pengecaman pertuturan berbilang bahasa, termasuk pengecaman pertuturan Inggeris-Sepanyol, Inggeris-Cina dan Inggeris-Jepun.
 Melalui fungsi tersuai, ketepatan model boleh dipertingkatkan lagi. Contohnya, sokongan untuk terminologi industri tertentu, aksen atau dialek dan penyesuaian untuk persekitaran yang bising boleh membantu meningkatkan prestasi pengecaman pertuturan.
Melalui fungsi tersuai, ketepatan model boleh dipertingkatkan lagi. Contohnya, sokongan untuk terminologi industri tertentu, aksen atau dialek dan penyesuaian untuk persekitaran yang bising boleh membantu meningkatkan prestasi pengecaman pertuturan.
Rangka kerja keseluruhan Riva boleh digunakan pada pelbagai senario, seperti perkhidmatan pelanggan dan sistem persidangan. Sebagai tambahan kepada senario umum, perkhidmatan Riva juga boleh disesuaikan mengikut keperluan industri yang berbeza, seperti CSP, pendidikan, kewangan dan industri lain.
3. ASR Pipeline & Customization
Dalam keseluruhan proses Riva ASR, terdapat beberapa modul yang boleh disesuaikan, yang boleh dibahagikan kepada tiga kategori mengikut kesukaran.
Pertama sekali, kotak oren adalah penyesuaian yang boleh dilakukan pada klien semasa proses inferens. Contohnya, ia menyokong fungsi kata panas Dengan menambahkan nama produk atau kata nama khas semasa proses inferens, model pertuturan boleh mengenal pasti perkataan khusus ini dengan lebih tepat. Ciri ini disokong secara asli oleh Riva dan boleh disesuaikan tanpa melatih semula model atau memulakan semula pelayan Riva.
 Dalam kotak ungu terdapat beberapa penyesuaian yang boleh dibuat apabila digunakan. Contohnya, pengecaman penstriman Riva menyediakan dua mod: pengoptimuman kependaman atau pengoptimuman throughput, yang boleh dipilih mengikut keperluan perniagaan untuk mendapatkan prestasi yang lebih baik. Selain itu, semasa proses penempatan, kamus sebutan juga boleh disesuaikan. Dengan kamus sebutan tersuai, anda boleh memastikan sebutan yang betul bagi istilah, nama atau jargon industri tertentu dan meningkatkan ketepatan pengecaman pertuturan.
Dalam kotak ungu terdapat beberapa penyesuaian yang boleh dibuat apabila digunakan. Contohnya, pengecaman penstriman Riva menyediakan dua mod: pengoptimuman kependaman atau pengoptimuman throughput, yang boleh dipilih mengikut keperluan perniagaan untuk mendapatkan prestasi yang lebih baik. Selain itu, semasa proses penempatan, kamus sebutan juga boleh disesuaikan. Dengan kamus sebutan tersuai, anda boleh memastikan sebutan yang betul bagi istilah, nama atau jargon industri tertentu dan meningkatkan ketepatan pengecaman pertuturan.
Kotak hijau adalah penyesuaian yang boleh dilakukan semasa proses latihan, iaitu latihan dan pelarasan yang dilakukan pada bahagian pelayan. Contohnya, dalam fasa penyusunan teks pada permulaan latihan, beberapa pemprosesan teks tertentu boleh ditambah. Selain itu, model akustik boleh diperhalusi atau dilatih semula untuk menyelesaikan masalah seperti aksen dan hingar dalam senario perniagaan tertentu untuk menjadikan model lebih mantap. Anda juga boleh melatih semula model bahasa, memperhalusi model tanda baca, penyusunan teks songsang, dsb.
Di atas adalah bahagian Riva yang boleh disesuaikan.
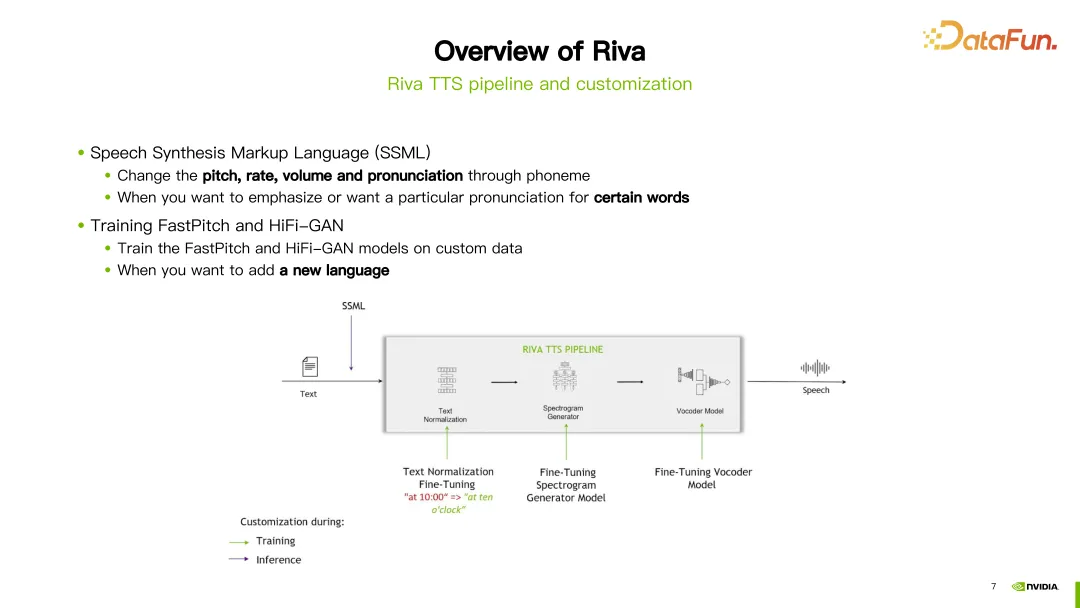
4. Riva TTS
Proses Riva TTS ditunjukkan di sebelah kanan gambar di atas
- Langkah pertama ialah penyusunan teks.
- Langkah kedua ialah G2P, yang menukar unit asas teks kepada unit asas sebutan atau bahasa pertuturan. Contohnya, tukar perkataan kepada fonem.
- Langkah ketiga ialah sintesis spektrum, menukar teks kepada spektrum akustik.
- Langkah keempat ialah sintesis audio, juga dipanggil vocoder. Dalam langkah ini, spektrum yang diperoleh pada langkah sebelumnya ditukar kepada audio.
Dalam gambar di atas, mengambil ayat "Hello World" sebagai contoh, mula-mula masukkan modul penyusunan teks untuk menyeragamkan teks, seperti menormalkan huruf besar dan kecil. Kemudian masukkan modul G2P untuk menukar teks ke dalam urutan fonem. Kemudian masukkan modul sintesis spektrum dan dapatkan spektrum melalui latihan rangkaian saraf. Akhir sekali masukkan vocoder untuk menukar spektrum kepada bunyi akhir.
Riva menyediakan penstriman sokongan TTS, menggunakan gabungan model FastPitch dan HiFi-GAN yang popular pada masa ini. Pada masa ini menyokong berbilang bahasa, termasuk Inggeris, Cina Mandarin, Sepanyol, Itali dan Jerman.
5. TTS Pipeline & Customization

Dalam proses TTS Riva, dua kaedah disediakan untuk penyesuaian. Cara pertama ialah menggunakan Bahasa Penanda Sintesis Pertuturan (SSML), yang merupakan cara yang lebih mudah untuk disesuaikan. Melalui beberapa konfigurasi, nada, kelajuan pertuturan, kelantangan, dsb. sebutan boleh dilaraskan. Biasanya, anda akan memilih kaedah ini jika anda ingin menukar sebutan perkataan tertentu.
Cara lain ialah memperhalusi atau melatih semula model FastPitch atau HiFi-GAN. Kedua-dua model boleh diperhalusi atau dilatih semula menggunakan data khusus anda sendiri. . Berikut adalah beberapa kemas kini penting.
Pertama sekali, teruskan mengoptimumkan model pengecaman pertuturan Cina (ASR). Model ASR terkini boleh didapati di pautan yang sepadan.
Kedua, sokongan untuk Model Bersepadu diperkenalkan. Ini bermakna ramalan tanda baca pengecaman pertuturan boleh dilakukan secara serentak dalam satu inferens.
Ketiga, menambah sokongan untuk model campuran Cina dan Inggeris. Ini bermakna model boleh mengendalikan kedua-dua input pertuturan Cina dan Inggeris.
Selain itu, beberapa modul baharu dan sokongan ciri telah diperkenalkan. Termasuk modul Pengesanan Aktiviti Suara (VAD) dan Diarisasi Speaker berasaskan rangkaian saraf. Fungsi penyusunan teks songsang Cina juga diperkenalkan. Butiran model ini boleh didapati dalam pautan yang sepadan.
2. Word Boosting
Selain itu, kami juga menyediakan tutorial terperinci untuk bahasa Cina. Bahagian pertama ialah tutorial mengenai perkataan panas (Word Boosting).
Kata panas melaraskan berat perkataan tertentu semasa pengecaman untuk menjadikan pengecaman perkataan lebih tepat. Dalam tutorial, contoh model Cina yang menggunakan perkataan panas seperti "Wangyue", yang merupakan nama puisi purba, ditunjukkan, dan kami memberikan kata ini berat 20. Seterusnya, gunakan kaedah add_word_boosting_to_config yang disediakan oleh Riva untuk mengkonfigurasi perkataan yang ingin kami tambah dan markahnya ke dalam klien. Kemudian, hantar permintaan yang dikonfigurasikan kepada pelayan ASR untuk mendapatkan hasil pengiktirafan selepas menambah perkataan panas.
Apabila mengkonfigurasi perkataan panas, anda perlu menetapkan dua parameter: boosted_lm_words dan boosted_lm_score. boosted_lm_words ialah senarai perkataan yang kami ingin tingkatkan ketepatan pengecaman. Boosted_lm_score ialah skor yang ditetapkan untuk perkataan ini, biasanya antara 20 dan 100.
Selain konfigurasi asas sebelumnya, fungsi kata panas Riva juga menyokong beberapa penggunaan lanjutan. Sebagai contoh, berat berbilang perkataan boleh ditingkatkan pada masa yang sama. Sebagai contoh, dalam contoh kami menetapkan pemberat 20 dan 30 untuk perkataan "lima G" dan "empat G" masing-masing.
Selain itu, kita juga boleh menggunakan kata boosting untuk mengurangkan ketepatan perkataan tertentu, iaitu, memberikan mereka pemberat negatif, dengan itu mengurangkan kebarangkalian mereka berlaku. Sebagai contoh, dalam contoh, kita diberikan aksara Cina "dia" dan skornya ditetapkan kepada -100. Dengan cara ini, model akan cenderung untuk tidak mengenali watak Cina. Secara teorinya, kita boleh menetapkan sebarang bilangan perkataan panas tanpa menjejaskan kependaman. Perlu diingat juga bahawa proses penggalak dilaksanakan pada bahagian pelanggan dan tidak mempunyai kesan pada bahagian pelayan.
3. Finetuning Conformer AM
Tutorial kedua ialah tentang cara memperhalusi model akustik Conformer.
Penalaan halus ASR menggunakan alatan NeMo. Selepas mengkonfigurasi akaun NGC, anda boleh menggunakan arahan "NGC muat turun" untuk memuat turun terus model Cina terlatih yang disediakan oleh Riva. Dalam contoh ini, versi kelima model ASR Cina telah dimuat turun. Selepas muat turun selesai, anda perlu memuatkan model yang telah dilatih.
Pertama, anda perlu mengimport beberapa pakej. Laluan model parameter ditetapkan kepada laluan model yang baru dimuat turun. Seterusnya, gunakan fungsi ASRModel.restore_from yang disediakan oleh NeMo untuk mendapatkan fail konfigurasi model, dan gunakan parameter sasaran untuk mendapatkan kategori model ASR asal. Seterusnya, gunakan fungsi import_class_by_path untuk mendapatkan kelas model sebenar. Akhir sekali, gunakan kaedah restore_from model di bawah kategori ini untuk memuatkan parameter model ASR di bawah laluan yang ditentukan.
Selepas memuatkan model, anda boleh menggunakan skrip latihan yang disediakan oleh NeMo untuk penalaan halus. Dalam contoh ini, kami mengambil latihan model CTC sebagai contoh, dan skrip yang digunakan ialah speech_to_text_ctc.py. Beberapa parameter yang perlu dikonfigurasikan termasuk train_ds.manifest_filepath, iaitu laluan fail JSON bagi data latihan, serta sama ada untuk menggunakan GPU, pengoptimum dan bilangan pusingan lelaran maksimum.
Selepas melatih model, ia boleh dinilai. Semasa menilai, anda perlu memberi perhatian kepada menetapkan parameter use_cer kepada benar, kerana untuk bahasa Cina, kami menggunakan Kadar Ralat Aksara (Kadar Ralat Aksara) sebagai penunjuk. Selepas anda menyelesaikan latihan dan menilai model, anda boleh menggunakan perintah nemo2riva untuk menukar model NeMo kepada model Riva. Kemudian gunakan alat Quickstart Riva untuk menggunakan model.
3. Perkhidmatan Riva TTS (Text-to-Speech)
Seterusnya, kami akan memperkenalkan perkhidmatan Riva TTS.
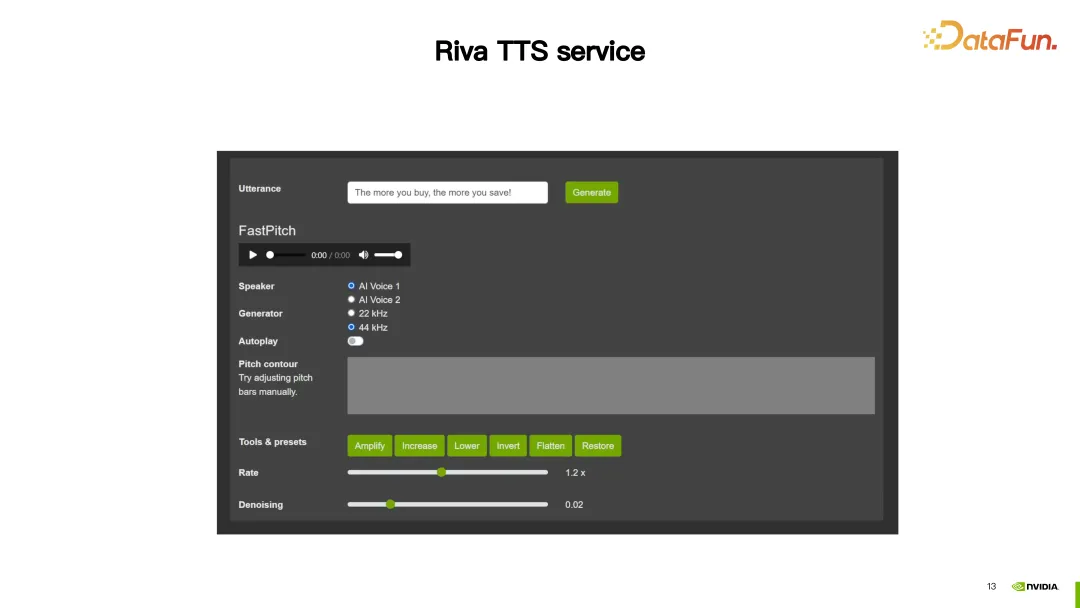
1. Demo
Dalam demo ini, Riva TTS menyediakan fungsi penyesuaian untuk menjadikan pertuturan yang disintesis lebih semula jadi.
Seterusnya, kami akan memperkenalkan dua kaedah penyesuaian yang disediakan oleh Riva TTS.
2. SSML
Yang pertama ialah SSML (Bahasa Penanda Sintesis Pertuturan) yang disebutkan di atas, yang dikonfigurasikan melalui skrip. Melalui SSML, prosodi dalam TTS boleh dilaraskan, termasuk pic dan kadar, dan kelantangan juga boleh dilaraskan.
Seperti yang ditunjukkan dalam gambar di atas, untuk ayat pertama "Hari ini adalah hari yang cerah", tukar pic rima kepada 2.5. Untuk ayat kedua, dua konfigurasi telah dibuat Satu adalah untuk menetapkan kadarnya kepada tinggi, dan satu lagi adalah untuk meningkatkan volum sebanyak 1DB. Dengan cara ini anda boleh mendapatkan hasil tersuai.
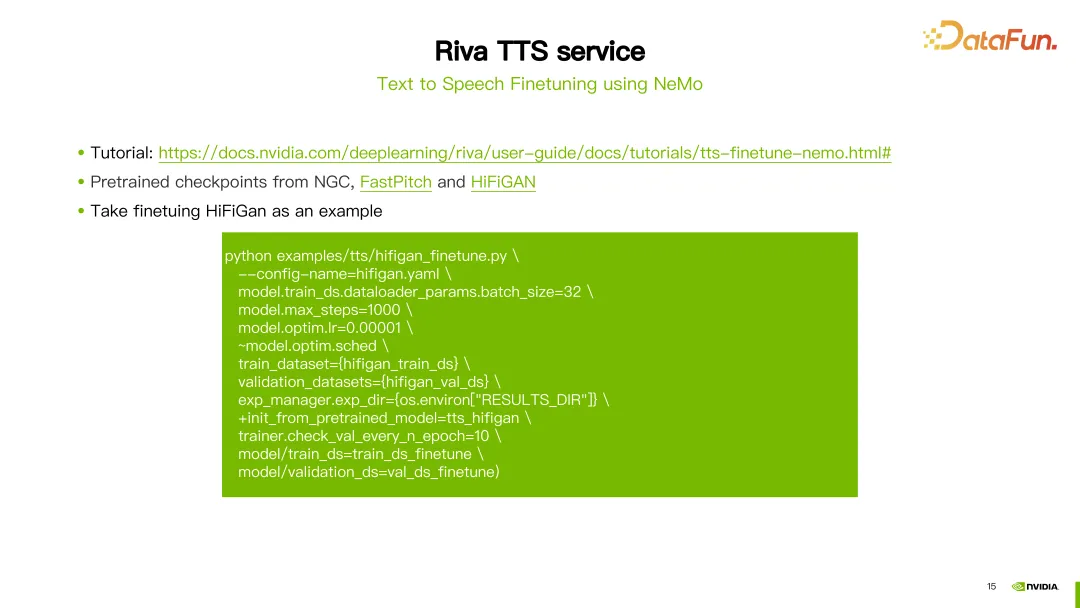
3. TTS Finetuning menggunakan NeMo
Selain SSML, anda juga boleh menggunakan alatan NeMo untuk memperhalusi atau melatih semula model FastPitch atau HiFi-GAN Riva TTS.
Riva menyediakan tutorial dan beberapa model pra-latihan mengenai NGC (lihat pautan dalam imej di atas).
Gambar menunjukkan contoh penalaan halus model HiFi-GAN. Gunakan arahan hifigan_finetune.py dan konfigurasikan parameter seperti nama konfigurasi model, saiz kelompok, bilangan maksimum langkah lelaran dan kadar pembelajaran. Tetapkan laluan set data yang diperlukan untuk memperhalusi HiFi-GAN dengan menetapkan parameter train_dataset. Jika anda memuat turun model pralatihan daripada NGC, anda juga boleh menggunakan parameter init_from_pretrained_model untuk memuatkan model pralatihan. Dengan cara ini model HiFi-GAN boleh dilatih semula.
4. Alat Mula Pantas Riva
Model tersuai boleh digunakan menggunakan alat Mula Pantas.
1. Persediaan
Sebelum anda mula, anda perlu mendaftar akaun NGC, pastikan GPU menyokong Riva, dan persekitaran Docker telah dipasang.
Setelah persiapan selesai, muat turun Riva Quickstart melalui pautan yang disediakan. Jika NGC CLI telah dikonfigurasikan, anda juga boleh menggunakan NGC CLI untuk memuat turun Riva Quickstart secara terus.
2. Permulaan dan penutupan pelayan
Selepas memuat turun Riva Quick Start, anda boleh menggunakan skrip yang disediakan untuk memulakan, memulakan dan menutup pelayan.
Mengambil versi terkini Riva (2.13.1) sebagai contoh, selepas muat turun selesai, anda hanya perlu menjalankan riva_init.sh, riva_start.sh atau riva_stop.sh untuk melengkapkan permulaan, permulaan dan penutupan pelayan.
Jika anda ingin menggunakan model Cina, cuma tetapkan kod bahasa kepada zh-CN, dan alat itu akan memuat turun model pra-latihan yang sepadan secara automatik. Anda boleh memulakan perkhidmatan untuk menggunakan fungsi ASR Cina (pengecaman pertuturan automatik) dan TTS (teks ke pertuturan).
3. Riva Client
Setelah pelayan berjaya dimulakan, anda boleh menggunakan skrip riva_start_client.sh yang disediakan oleh Riva untuk memanggil perkhidmatan. Jika anda mahukan pengecaman pertuturan luar talian, jalankan sahaja arahan riva_asr_client dan tentukan laluan ke fail audio yang anda ingin kenali. Jika anda ingin melakukan pengecaman pertuturan penstriman, anda boleh menggunakan arahan riva_streaming_asr_client. Jika anda ingin melakukan sintesis pertuturan, anda boleh menggunakan arahan riva_tts_client untuk menghantar audio untuk diproses atau disintesis ke pelayan yang baru anda mulakan.
5. Sumber rujukan
Berikut adalah beberapa sumber dokumentasi berkaitan Riva:
Dokumentasi rasmi Riva: Dokumen ini menyediakan maklumat terperinci tentang Riva, termasuk panduan pemasangan, konfigurasi dan penggunaan Anda boleh mendapatkan dokumentasi rasmi Riva di sini untuk mengetahui lebih lanjut tentang dan mempelajari semua aspek Riva.
Panduan Pengguna Mula Pantas Riva: Panduan ini menyediakan pengguna dengan arahan terperinci untuk Mula Pantas Riva, termasuk langkah pemasangan dan konfigurasi, serta jawapan kepada soalan lazim. Jika anda menghadapi sebarang masalah menggunakan Riva Quick Start, anda boleh mendapatkan jawapan dalam panduan pengguna ini.
Nota Keluaran Riva: Dokumen ini menyediakan maklumat terkini tentang model terkini Riva. Anda boleh mengetahui perkara baharu dan dipertingkatkan dalam setiap versi di sini.
Sumber di atas akan membantu pengguna lebih memahami dan menggunakan Riva.
Di atas adalah kandungan yang dikongsikan kali ini, terima kasih semua.
6. Sesi Soal Jawab
S1: Apakah hubungan antara Riva dan Triton? Adakah terdapat beberapa pertindihan fungsi?
A1: Ya, Riva menggunakan rangka kerja inferens Nvidia Triton, yang berdasarkan beberapa pembangunan Nvidia Triton.
S2: Adakah Riva sebenarnya telah dilaksanakan dalam bidang RAG? Atau projek sumber terbuka?
A2: Riva pada masa ini harus memberi tumpuan terutamanya pada bidang Pertuturan AI.
S3: Adakah terdapat hubungan antara Riva dan Nemo?
A3: Riva lebih memfokuskan pada penyelesaian penggunaan Model yang dilatih dengan Nemo boleh digunakan dengan Riva di Riva.
S4: Bolehkah model yang dilatih oleh rangka kerja lain digunakan?
A4: Latihan dengan rangka kerja lain tidak disokong buat sementara waktu, atau memerlukan beberapa kerja pembangunan tambahan.
S5: Bolehkah Riva menggunakan model daripada rangka kerja latihan PyTorch atau TensorFlow?
A5: Riva kini terutamanya menyokong model yang dilatih oleh Nemo sebenarnya dibangunkan berdasarkan PyTorch.
S6: Jika saya menyesuaikan model baharu dalam Nemo, adakah saya perlu menulis kod penggunaan dalam Riva?
A6: Untuk model yang dibangunkan sendiri, jika anda ingin menyokongnya dalam Riva, anda perlu melakukan beberapa pembangunan tambahan.
S7: Bolehkah Riva digunakan dengan GPU memori kecil?
A7: Anda boleh merujuk kepada dokumen berkaitan platform penyesuaian yang disediakan oleh Riva, yang termasuk penyesuaian pelbagai jenis GPU.
S8: Bagaimana dengan cepat mencuba Riva?
A8: Anda boleh mencuba Riva dengan memuat turun kit alat Riva Quickstart terus di NGC.
S9: Jika Riva mahu menyokong dialek Cina, adakah Riva memerlukan latihan yang disesuaikan?
A9: Betul. Anda boleh menggunakan data dalam beberapa dialek anda sendiri. Hanya memperhalusinya berdasarkan model pra-latihan yang disediakan oleh Riva, dan kemudian gunakannya dalam Riva.
S10: Adakah terdapat pertindihan atau perbezaan dalam kedudukan Riva dan Tensor LM?
A10: Pecutan Riva sebenarnya menggunakan Tensor RT Riva adalah produk berasaskan Tensor RT dan Triton.








Atas ialah kandungan terperinci Gunakan NVIDIA Riva untuk menggunakan perkhidmatan AI suara Cina peringkat perusahaan dengan cepat dan mengoptimumkan serta mempercepatkannya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!