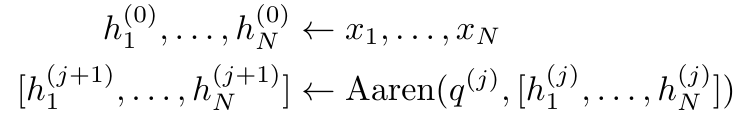Kemajuan dalam pemodelan jujukan sangat memberi kesan kerana ia memainkan peranan penting dalam pelbagai aplikasi, termasuk pembelajaran pengukuhan (cth., robotik dan pemanduan autonomi), klasifikasi siri masa (cth., pengesanan penipuan kewangan dan diagnosis perubatan) tunggu. Dalam beberapa tahun kebelakangan ini, kemunculan Transformer telah menandakan kejayaan besar dalam pemodelan jujukan, terutamanya disebabkan fakta bahawa Transformer menyediakan seni bina berprestasi tinggi yang boleh memanfaatkan pemprosesan selari GPU. Walau bagaimanapun, Transformer mempunyai overhed pengiraan yang tinggi semasa inferens, terutamanya disebabkan oleh pengembangan kuadratik memori dan keperluan pengkomputeran, dengan itu mengehadkan aplikasinya dalam persekitaran sumber rendah (cth., peranti mudah alih dan terbenam). Walaupun teknik seperti caching KV boleh diguna pakai untuk meningkatkan kecekapan inferens, Transformer masih sangat mahal untuk domain sumber rendah disebabkan oleh: (1) memori yang meningkat secara linear dengan bilangan token, dan (2) menyimpan semua token sebelumnya ke dalam model. Masalah ini lebih menjejaskan inferens Transformer dalam persekitaran dengan konteks yang panjang (iaitu, sejumlah besar token). Untuk menyelesaikan masalah ini, penyelidik dari Royal Bank of Canada AI Research Institute Borealis AI dan University of Montreal menyediakan penyelesaian dalam kertas "Perhatian sebagai RNN". Perlu dinyatakan bahawa kami mendapati pemenang Anugerah Turing Yoshua Bengio muncul dalam ruangan pengarang. .
Secara khusus, selidiki Pengarang mula-mula mengkaji mekanisme perhatian dalam Transformer, iaitu komponen yang menyebabkan kerumitan pengiraan Transformer meningkat secara kuadratik. Kajian ini menunjukkan bahawa mekanisme perhatian boleh dianggap sebagai jenis rangkaian neural berulang (RNN) khas, dengan keupayaan untuk mengira output RNN banyak-ke-satu dengan cekap. Dengan menggunakan rumusan perhatian RNN, kajian ini menunjukkan bahawa model berasaskan perhatian yang popular seperti Transformer dan Perceiver boleh dianggap sebagai varian RNN. Walau bagaimanapun, tidak seperti RNN tradisional seperti LSTM dan GRU, model perhatian popular seperti Transformer dan Perceiver boleh dianggap sebagai varian RNN. Malangnya, mereka tidak boleh dikemas kini dengan cekap dengan token baharu.
- Untuk menyelesaikan masalah ini, penyelidikan ini memperkenalkan formula perhatian baharu berdasarkan algoritma imbasan awalan selari, yang boleh mengira dengan cekap banyak-ke-banyak (banyak-ke-banyak) perhatian kepada- banyak) output RNN untuk mencapai kemas kini yang cekap.
Berdasarkan formula perhatian baharu ini, kajian itu mencadangkan Aaren ([A] perhatian [a] s a [re] rangkaian saraf [n] semasa), modul yang cekap dari segi pengiraan, bukan sahaja boleh dilatih secara selari seperti Transformer , tetapi juga boleh dikemas kini dengan cekap seperti RNN.
Hasil eksperimen menunjukkan bahawa prestasi Aaren adalah setanding dengan Transformer pada 38 set data yang meliputi empat tetapan data jujukan biasa: pembelajaran pengukuhan, ramalan peristiwa, pengelasan siri masa dan tugas ramalan siri masa, Ia juga lebih cekap dari segi masa dan ingatan.
Untuk menyelesaikan masalah di atas, penulis mencadangkan modul yang cekap berdasarkan perhatian, yang boleh memanfaatkan keselarian GPU dan mengemas kini dengan cekap pada masa yang sama.
Pertama, pengarang menunjukkan dalam Bahagian 3.1 bahawa perhatian boleh dilihat sebagai sejenis RNN dengan keupayaan istimewa untuk mengira output RNN banyak-ke-satu dengan cekap (Rajah 1a). Dengan memanfaatkan bentuk perhatian RNN, penulis selanjutnya menggambarkan bahawa model berasaskan perhatian yang popular, seperti Transformer (Rajah 1b) dan Perceiver (Rajah 1c), boleh dianggap sebagai RNN. Walau bagaimanapun, tidak seperti RNN tradisional, model ini tidak boleh mengemas kini diri mereka dengan cekap berdasarkan token baharu, mengehadkan potensinya dalam masalah berurutan apabila data tiba dalam bentuk strim.
Untuk menyelesaikan masalah ini, penulis memperkenalkan kaedah yang cekap untuk mengira perhatian dalam RNN banyak-ke-banyak berdasarkan algoritma imbasan awalan selari dalam Bahagian 3.2. Atas dasar ini, penulis memperkenalkan Aaren dalam Bahagian 3.3 - modul cekap pengiraan yang bukan sahaja boleh dilatih secara selari (sama seperti Transformer), tetapi juga boleh dikemas kini dengan cekap dengan token baharu semasa inferens hanya memerlukan Memori yang berterusan (hanya seperti RNN tradisional).
Anggap perhatian sebagai RNN banyak-dengan-satuPerhatian vektor pertanyaan q boleh dilihat sebagai fungsi yang melepasi kunci dan nilai N token konteks x_1:  Ia memetakan kepada satu output o_N = Perhatian (q, k_1:N, v_1:N). Diberi s_i = titik (q, k_i), output o_N boleh dinyatakan sebagai: di mana pengangka adalah ialah dan penyebutnya. Memikirkan perhatian sebagai RNN, dan boleh dikira secara berulang dalam cara penjumlahan bergolek apabila k = 1,...,.... Walau bagaimanapun, dalam amalan, pelaksanaan ini tidak stabil dan mengalami masalah berangka disebabkan oleh perwakilan ketepatan yang terhad dan kemungkinan eksponen yang sangat kecil atau sangat besar (iaitu, exp (s)). Bagi mengurangkan masalah ini, penulis menggunakan istilah maksimum kumulatif untuk menulis semula formula rekursi untuk mengira dan . Perlu diingat bahawa keputusan akhir adalah sama , pengiraan gelung m_k adalah seperti berikut:
Ia memetakan kepada satu output o_N = Perhatian (q, k_1:N, v_1:N). Diberi s_i = titik (q, k_i), output o_N boleh dinyatakan sebagai: di mana pengangka adalah ialah dan penyebutnya. Memikirkan perhatian sebagai RNN, dan boleh dikira secara berulang dalam cara penjumlahan bergolek apabila k = 1,...,.... Walau bagaimanapun, dalam amalan, pelaksanaan ini tidak stabil dan mengalami masalah berangka disebabkan oleh perwakilan ketepatan yang terhad dan kemungkinan eksponen yang sangat kecil atau sangat besar (iaitu, exp (s)). Bagi mengurangkan masalah ini, penulis menggunakan istilah maksimum kumulatif untuk menulis semula formula rekursi untuk mengira dan . Perlu diingat bahawa keputusan akhir adalah sama , pengiraan gelung m_k adalah seperti berikut:
Dengan merangkumkan pengiraan kitaran a_k, c_k dan m_k daripada a_(k-1), c_(k-1) dan m_(k-1), pengarang memperkenalkan unit RNN yang boleh mengira secara lelaran output perhatian (Lihat Rajah 2). Unit RNN perhatian mengambil (a_(k-1), c_(k-1), m_(k-1), q) sebagai input dan mengira (a_k, c_k, m_k, q). Ambil perhatian bahawa vektor pertanyaan q dihantar dalam unit RNN. Keadaan awal tersembunyi perhatian RNN ialah (a_0, c_0, m_0, q) = (0, 0, 0, q). Kaedah untuk mengira perhatian: Dengan menganggap perhatian sebagai RNN, anda boleh melihat cara yang berbeza untuk mengira perhatian: token pengiraan gelung mengikut token dalam memori O (1) (iaitu pengiraan berurutan); pengkomputeran selari), memerlukan memori O(N) linear. Memandangkan perhatian boleh dianggap sebagai RNN, kaedah tradisional untuk mengira perhatian juga boleh dianggap sebagai kaedah yang cekap untuk mengira output RNN banyak-ke-satu perhatian, iaitu, output RNN mengambil pelbagai token konteks sebagai input, tetapi dalam Pada penghujung RNN, hanya satu token adalah output (lihat Rajah 1a). Akhir sekali, perhatian juga boleh dikira sebagai RNN yang memproses ketulan token demi ketul, bukannya sepenuhnya secara berurutan atau selari sepenuhnya, yang memerlukan ingatan O(b), dengan b ialah saiz bongkah. Anggap model perhatian sedia ada sebagai RNN. Dengan menganggap perhatian sebagai RNN, model berasaskan perhatian sedia ada juga boleh dilihat sebagai varian RNN. Contohnya, perhatian kendiri Transformer ialah RNN (Rajah 1b), dan token konteks ialah keadaan awal tersembunyinya. Perhatian silang perceiver ialah RNN (Rajah 1c) yang keadaan tersembunyi awalnya ialah pembolehubah pendam bergantung konteks. Dengan memanfaatkan bentuk RNN daripada mekanisme perhatian mereka, model sedia ada ini boleh mengira stor keluaran mereka dengan cekap. Namun, apabila model berasaskan perhatian sedia ada (seperti Transformers) dianggap sebagai RNN, model ini tidak mempunyai ciri penting yang biasa dilihat dalam RNN tradisional (seperti LSTM dan GRU). Perlu diperhatikan bahawa LSTM dan GRU dapat mengemas kini diri mereka dengan cekap dengan token baharu hanya dalam memori dan pengiraan tetap O(1), sebaliknya, paparan RNN Transformer (lihat Rajah 1b) akan Token baharu ditambah sebagai keadaan awal dan RNN baharu ditambahkan untuk memproses token baharu. RNN baharu ini memproses semua token sebelumnya, memerlukan pengiraan linear O(N). Dalam Perceiver, disebabkan seni binanya, pembolehubah terpendam (L_i dalam Rajah 1c) adalah bergantung kepada input, bermakna nilainya berubah apabila menerima token baharu. Apabila keadaan awal tersembunyi (iaitu pembolehubah pendam) RNNnya berubah, Perceiver oleh itu perlu mengira semula RNNnya dari awal, memerlukan amaun linear pengiraan O (NL), dengan N ialah bilangan token dan L ialah bilangan pembolehubah terpendam. Anggap perhatian sebagai RNN banyak-ke-banyakSebagai tindak balas kepada batasan ini, penulis mencadangkan untuk membangunkan model berasaskan perhatian yang memanfaatkan keupayaan formulasi kemas kini RNN yang cekap untuk melaksanakan . Untuk tujuan ini, pengarang mula-mula memperkenalkan kaedah selari yang cekap untuk mengira perhatian sebagai RNN banyak-ke-banyak, iaitu kaedah pengkomputeran selari . Untuk tujuan ini, pengarang menggunakan algoritma imbasan awalan selari (lihat Algoritma 1), kaedah pengkomputeran selari yang mengira N awalan daripada N titik data berturut-turut melalui operator korelasi ⊕.Algoritma ini boleh mengira dengan cekap Semakan, di mana , Untuk mengira dengan cekap, dan boleh dikira melalui algoritma selari dan kemudiannya . ⊕ ,. Input kepada algoritma imbasan selari ialah
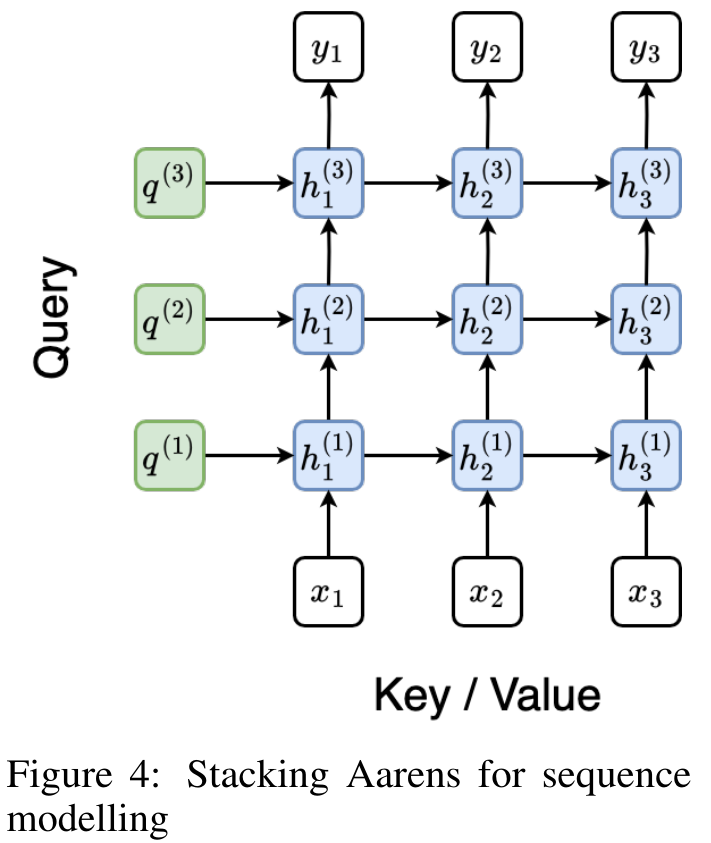
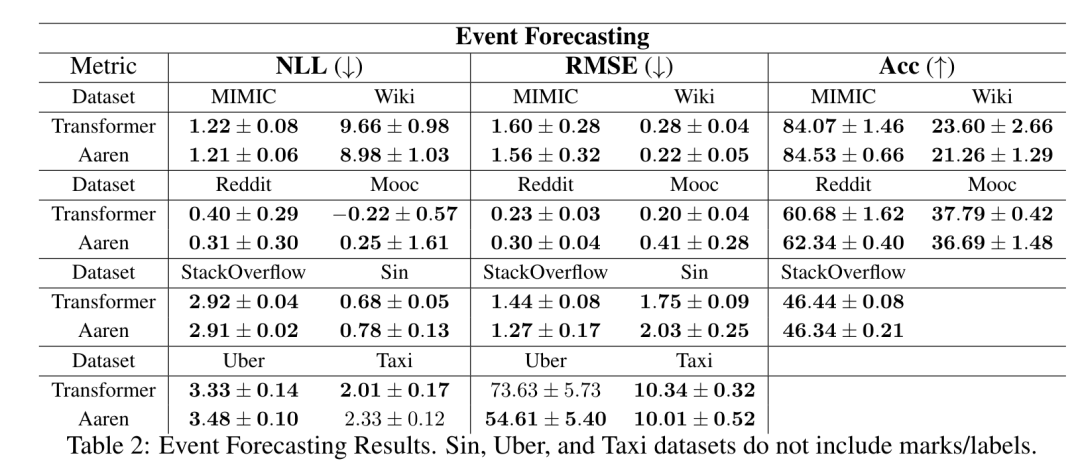
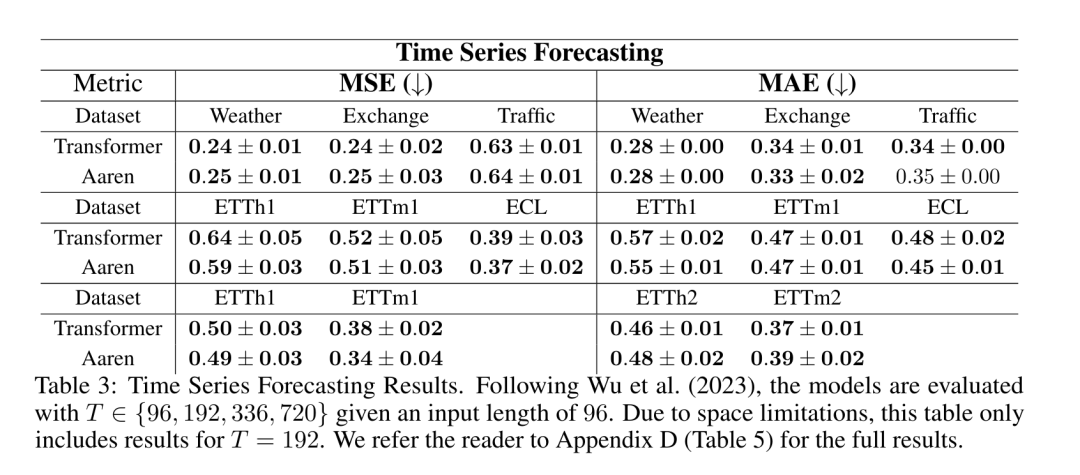
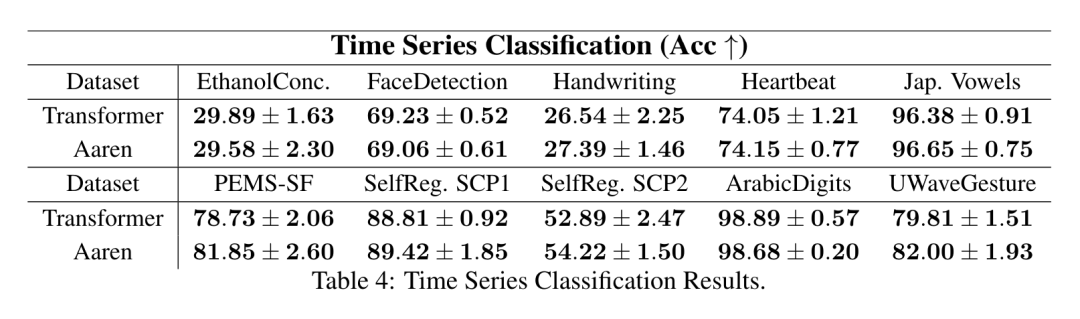
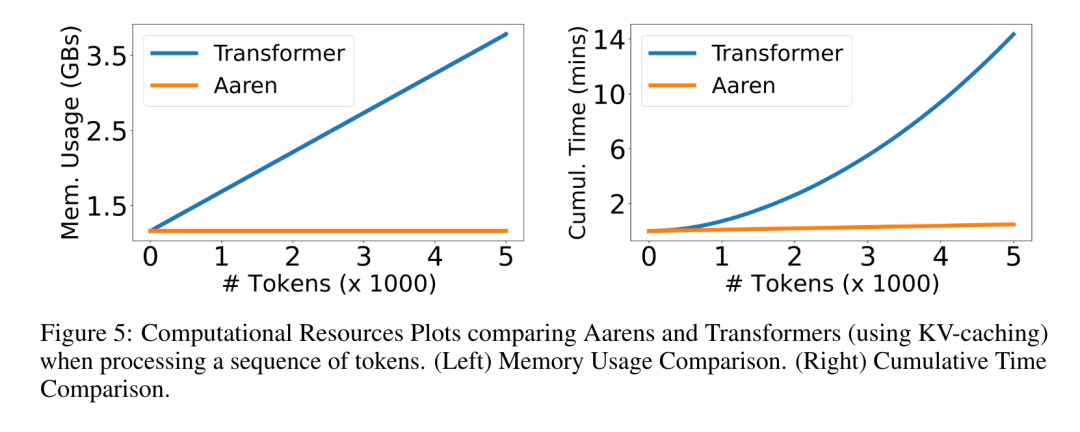
. Algoritma secara rekursif menggunakan operator ⊕ dan berfungsi seperti berikut: , di mana , . Selepas melengkapkan aplikasi rekursif pengendali, algoritma mengeluarkan . Juga dikenali sebagai . Menggabungkan dua nilai terakhir dari tuple keluaran, diperoleh menghasilkan kaedah selari yang cekap untuk mengira perhatian sebagai RNN banyak-ke-banyak (Rajah 3). Aaren: [A] perhatian [a] s a [semula] neural semasa [n] etwork adalah antara muka N, sama seperti antara muka Trans, antara muka N sama dipetakan kepada keluaran N, dan keluaran ke-i ialah pengagregatan input ke-1 hingga ke-i. Di samping itu, Aaren secara semula jadi boleh disusun dan boleh mengira terma kerugian berasingan untuk setiap token jujukan. Walau bagaimanapun, tidak seperti Transformers yang menggunakan perhatian kendiri sebab, Aaren menggunakan kaedah pengiraan perhatian di atas sebagai RNN banyak-ke-banyak, menjadikannya lebih cekap. Bentuk Aaren adalah seperti berikut: Berbeza dengan Transformer, dalam Transformer, pertanyaan adalah salah satu input token untuk perhatian, manakala dalam Aaren, token pertanyaan melalui backpropagation q semasa proses latihan Dipelajari. Rajah di bawah menunjukkan contoh model Aaren bertindan Token konteks input model ialah x_1:3 dan output ialah y_1:3. Perlu diingat bahawa memandangkan Aaren menggunakan mekanisme perhatian dalam bentuk RNN, menyusun Aaren juga bersamaan dengan menyusun RNN. Oleh itu, Aarens juga dapat mengemas kini dengan cekap dengan token baharu, iaitu pengiraan berulang y_k hanya memerlukan pengiraan berterusan kerana ia hanya bergantung pada h_k-1 dan x_k. Model berasaskan Transformer memerlukan memori linear (apabila menggunakan cache KV) dan perlu menyimpan semua token sebelumnya, termasuk yang berada dalam lapisan Transformer perantaraan, tetapi model berasaskan memori Aaren hanya memerlukan Dan tidak perlu menyimpan semua token sebelumnya, yang menjadikan Aaren jauh lebih baik daripada Transformer dari segi kecekapan pengiraan. Matlamat bahagian eksperimen adalah untuk membandingkan Aaren dan Transformer dari segi prestasi dan sumber yang diperlukan (masa dan ingatan). Untuk perbandingan menyeluruh, pengarang melakukan penilaian ke atas empat masalah: pembelajaran pengukuhan, ramalan peristiwa, ramalan siri masa dan klasifikasi siri masa. Penulis terlebih dahulu membandingkan prestasi Aaren dan Transformer dalam pembelajaran pengukuhan. Pembelajaran pengukuhan popular dalam persekitaran interaktif seperti robotik, enjin cadangan dan kawalan trafik. Keputusan dalam Jadual 1 menunjukkan prestasi Aaren setanding dengan Transformer merentas kesemua 12 set data dan 4 persekitaran. Walau bagaimanapun, tidak seperti Transformer, Aaren juga merupakan RNN dan oleh itu boleh mengendalikan interaksi persekitaran baharu dengan cekap dalam pengiraan berterusan, menjadikannya lebih sesuai untuk pembelajaran pengukuhan. Seterusnya, penulis membandingkan prestasi Aaren dan Transformer dalam ramalan acara. Ramalan acara popular dalam banyak tetapan dunia nyata, seperti kewangan (cth., urus niaga), penjagaan kesihatan (cth., pemerhatian pesakit) dan e-dagang (cth., pembelian). Keputusan dalam Jadual 2 menunjukkan bahawa Aaren berprestasi setanding dengan Transformer pada semua set data.Keupayaan Aaren untuk memproses input baharu dengan cekap amat berguna dalam persekitaran ramalan peristiwa, di mana peristiwa berlaku dalam aliran yang tidak teratur. Kemudian, penulis membandingkan prestasi Aaren dan Transformer dalam ramalan siri masa. Model ramalan siri masa biasanya digunakan dalam bidang yang berkaitan dengan iklim (seperti cuaca), tenaga (seperti bekalan dan permintaan), dan ekonomi (seperti harga saham). Keputusan dalam Jadual 3 menunjukkan prestasi Aaren setanding dengan Transformer pada semua set data. Walau bagaimanapun, tidak seperti Transformer, Aaren boleh memproses data siri masa dengan cekap, menjadikannya lebih sesuai untuk medan berkaitan siri masa. Seterusnya, penulis membandingkan prestasi Aaren dan Transformer dalam klasifikasi siri masa. Pengelasan siri masa adalah perkara biasa dalam banyak aplikasi penting, seperti pengecaman corak (cth. elektrokardiogram), pengesanan anomali (cth. penipuan bank) atau ramalan kerosakan (cth. turun naik grid kuasa). Seperti yang dapat dilihat daripada Jadual 4, Aaren berprestasi serupa dengan Transformer pada semua set data. Akhir sekali, penulis membandingkan sumber yang diperlukan oleh Aaren dan Transformer. Kerumitan Memori: Dalam Rajah 5 (kiri), penulis membandingkan penggunaan memori Aaren dan Transformer (menggunakan cache KV) pada masa inferens. Dapat dilihat dengan penggunaan teknologi cache KV, penggunaan memori Transformer meningkat secara linear. Sebaliknya, Aaren hanya menggunakan jumlah memori yang tetap tanpa mengira bagaimana bilangan token berkembang, jadi ia adalah lebih cekap. Kerumitan masa: Dalam Rajah 5 (kanan), penulis membandingkan masa terkumpul yang diperlukan untuk Aaren dan Transformer (menggunakan cache KV) untuk memproses jujukan token mengikut turutan. Untuk Transformer, jumlah pengiraan terkumpul ialah kuasa dua bilangan token, iaitu, O (1 + 2 + ... + N) = O (N^2). Sebaliknya, usaha pengiraan terkumpul Aaren adalah linear. Dalam rajah, anda dapat melihat bahawa masa terkumpul yang diperlukan oleh model mempunyai hasil yang serupa. Secara khusus, masa kumulatif yang diperlukan oleh Transformer meningkat secara kuadratik, manakala masa kumulatif yang diperlukan oleh Aaren meningkat secara linear. Bilangan parameter: Disebabkan keperluan untuk mempelajari keadaan awal tersembunyi q, modul Aaren memerlukan lebih sedikit parameter daripada modul Transformer. Walau bagaimanapun, kerana q hanyalah vektor, perbezaannya tidak ketara. Melalui pengukuran empirikal pada model yang serupa, penulis mendapati Transformer menggunakan 3, 152, 384 parameter. Sebagai perbandingan, Aaren yang setara menggunakan 3,152,896 parameter, peningkatan parameter hanya 0.016%—harga yang boleh diabaikan untuk membayar perbezaan ketara dalam ingatan dan kerumitan masa. Atas ialah kandungan terperinci Kerja baru oleh Bengio et al.: Perhatian boleh dianggap sebagai RNN Model baharu adalah setanding dengan Transformer, tetapi sangat menjimatkan memori.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan:Kandungan artikel ini disumbangkan secara sukarela oleh netizen, dan hak cipta adalah milik pengarang asal. Laman web ini tidak memikul tanggungjawab undang-undang yang sepadan. Jika anda menemui sebarang kandungan yang disyaki plagiarisme atau pelanggaran, sila hubungi admin@php.cn



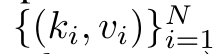 Ia memetakan kepada satu output o_N = Perhatian (q, k_1:N, v_1:N). Diberi s_i = titik (q, k_i), output o_N boleh dinyatakan sebagai:
Ia memetakan kepada satu output o_N = Perhatian (q, k_1:N, v_1:N). Diberi s_i = titik (q, k_i), output o_N boleh dinyatakan sebagai: 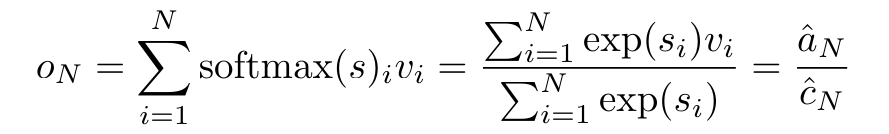
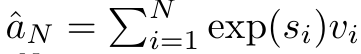 ialah
ialah 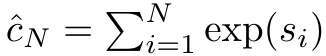 dan penyebutnya. Memikirkan perhatian sebagai RNN,
dan penyebutnya. Memikirkan perhatian sebagai RNN, 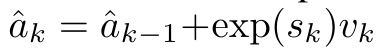 dan
dan  boleh dikira secara berulang dalam cara penjumlahan bergolek apabila k = 1,...,.... Walau bagaimanapun, dalam amalan, pelaksanaan ini tidak stabil dan mengalami masalah berangka disebabkan oleh perwakilan ketepatan yang terhad dan kemungkinan eksponen yang sangat kecil atau sangat besar (iaitu, exp (s)). Bagi mengurangkan masalah ini, penulis menggunakan istilah maksimum kumulatif
boleh dikira secara berulang dalam cara penjumlahan bergolek apabila k = 1,...,.... Walau bagaimanapun, dalam amalan, pelaksanaan ini tidak stabil dan mengalami masalah berangka disebabkan oleh perwakilan ketepatan yang terhad dan kemungkinan eksponen yang sangat kecil atau sangat besar (iaitu, exp (s)). Bagi mengurangkan masalah ini, penulis menggunakan istilah maksimum kumulatif 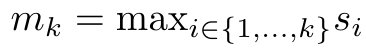 untuk menulis semula formula rekursi untuk mengira
untuk menulis semula formula rekursi untuk mengira 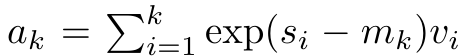 dan
dan 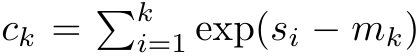 . Perlu diingat bahawa keputusan akhir adalah sama
. Perlu diingat bahawa keputusan akhir adalah sama 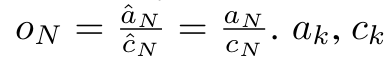 , pengiraan gelung m_k adalah seperti berikut:
, pengiraan gelung m_k adalah seperti berikut: 

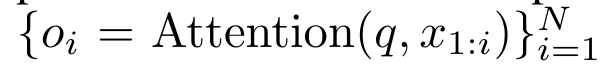 . Untuk tujuan ini, pengarang menggunakan algoritma imbasan awalan selari (lihat Algoritma 1), kaedah pengkomputeran selari yang mengira N awalan daripada N titik data berturut-turut melalui operator korelasi ⊕.Algoritma ini boleh mengira dengan cekap
. Untuk tujuan ini, pengarang menggunakan algoritma imbasan awalan selari (lihat Algoritma 1), kaedah pengkomputeran selari yang mengira N awalan daripada N titik data berturut-turut melalui operator korelasi ⊕.Algoritma ini boleh mengira dengan cekap 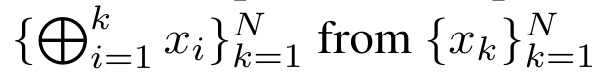

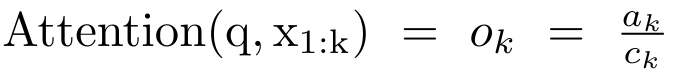 , di mana
, di mana 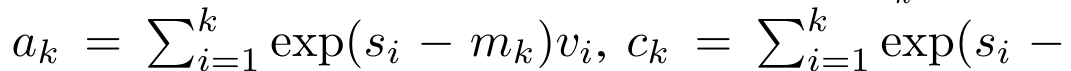
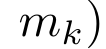 ,
, 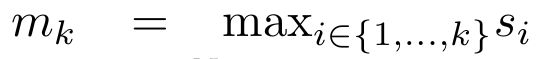 Untuk mengira
Untuk mengira 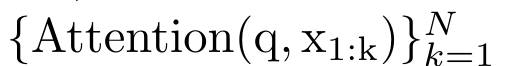 dengan cekap,
dengan cekap, 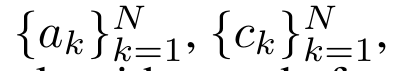 dan
dan  boleh dikira melalui algoritma selari dan kemudiannya
boleh dikira melalui algoritma selari dan kemudiannya  . ⊕ ,
. ⊕ ,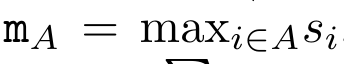 , di mana
, di mana 
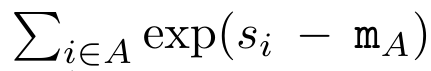 ,
, 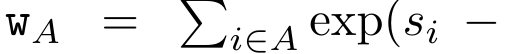
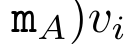 .
. 
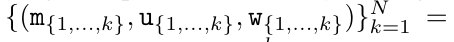
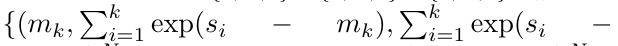
 . Juga dikenali sebagai
. Juga dikenali sebagai 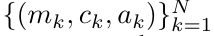 . Menggabungkan dua nilai terakhir dari tuple keluaran,
. Menggabungkan dua nilai terakhir dari tuple keluaran, 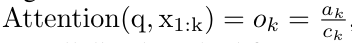 diperoleh menghasilkan kaedah selari yang cekap untuk mengira perhatian sebagai RNN banyak-ke-banyak (Rajah 3).
diperoleh menghasilkan kaedah selari yang cekap untuk mengira perhatian sebagai RNN banyak-ke-banyak (Rajah 3).