



本文实例讲述了基于Python实现的百度贴吧网络爬虫。分享给大家供大家参考。具体如下:
完整实例代码点击此处本站下载。
项目内容:
用Python写的百度贴吧的网络爬虫。
使用方法:
新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行。
程序功能:
将贴吧中楼主发布的内容打包txt存储到本地。
原理解释:
首先,先浏览一下某一条贴吧,点击只看楼主并点击第二页之后url发生了一点变化,变成了:
http://tieba.baidu.com/p/2296712428?see_lz=1&pn=1
可以看出来,see_lz=1是只看楼主,pn=1是对应的页码,记住这一点为以后的编写做准备。
这就是我们需要利用的url。
接下来就是查看页面源码。
首先把题目抠出来存储文件的时候会用到。
可以看到百度使用gbk编码,标题使用h1标记:
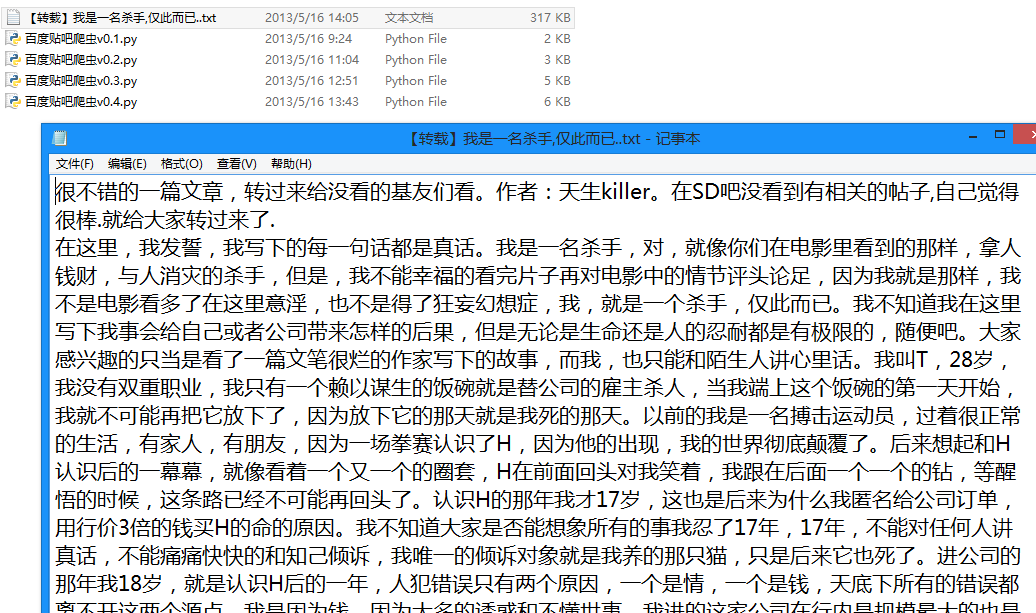
【原创】时尚首席(关于时尚,名利,事业,爱情,励志)
同样,正文部分用div和class综合标记,接下来要做的只是用正则表达式来匹配即可。
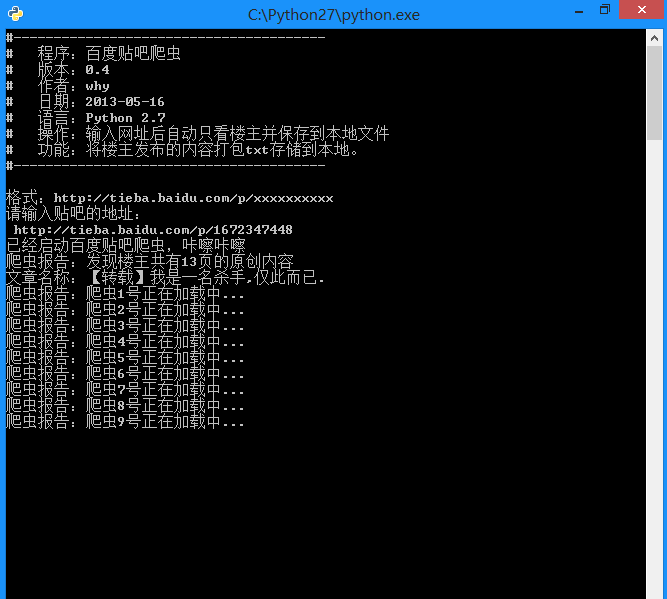
运行截图:
生成的txt文件:
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:百度贴吧爬虫
# 版本:0.5
# 作者:why
# 日期:2013-05-16
# 语言:Python 2.7
# 操作:输入网址后自动只看楼主并保存到本地文件
# 功能:将楼主发布的内容打包txt存储到本地。
#---------------------------------------
import string
import urllib2
import re
#----------- 处理页面上的各种标签 -----------
class HTML_Tool:
# 用非 贪婪模式 匹配 \t 或者 \n 或者 空格 或者 超链接 或者 图片
BgnCharToNoneRex = re.compile("(\t|\n| |<a.*?>|<img .*? alt="基于Python实现的百度贴吧网络爬虫实例" >)")
# 用非 贪婪模式 匹配 任意<>标签
EndCharToNoneRex = re.compile("<.*?>")
# 用非 贪婪模式 匹配 任意<p>标签
BgnPartRex = re.compile("<p.*?>")
CharToNewLineRex = re.compile("(<br/>|</p>|<tr>|<div>|</div>)")
CharToNextTabRex = re.compile("<td>")
# 将一些html的符号实体转变为原始符号
replaceTab = [("<","<"),(">",">"),("&","&"),("&","\""),(" "," ")]
def Replace_Char(self,x):
x = self.BgnCharToNoneRex.sub("",x)
x = self.BgnPartRex.sub("\n ",x)
x = self.CharToNewLineRex.sub("\n",x)
x = self.CharToNextTabRex.sub("\t",x)
x = self.EndCharToNoneRex.sub("",x)
for t in self.replaceTab:
x = x.replace(t[0],t[1])
return x
class Baidu_Spider:
# 申明相关的属性
def __init__(self,url):
self.myUrl = url + '?see_lz=1'
self.datas = []
self.myTool = HTML_Tool()
print u'已经启动百度贴吧爬虫,咔嚓咔嚓'
# 初始化加载页面并将其转码储存
def baidu_tieba(self):
# 读取页面的原始信息并将其从gbk转码
myPage = urllib2.urlopen(self.myUrl).read().decode("gbk")
# 计算楼主发布内容一共有多少页
endPage = self.page_counter(myPage)
# 获取该帖的标题
title = self.find_title(myPage)
print u'文章名称:' + title
# 获取最终的数据
self.save_data(self.myUrl,title,endPage)
#用来计算一共有多少页
def page_counter(self,myPage):
# 匹配 "共有<span class="red">12</span>页" 来获取一共有多少页
myMatch = re.search(r'class="red">(\d+?)</span>', myPage, re.S)
if myMatch:
endPage = int(myMatch.group(1))
print u'爬虫报告:发现楼主共有%d页的原创内容' % endPage
else:
endPage = 0
print u'爬虫报告:无法计算楼主发布内容有多少页!'
return endPage
# 用来寻找该帖的标题
def find_title(self,myPage):
# 匹配 <h1 id="xxxxxxxxxx">xxxxxxxxxx</h1> 找出标题
myMatch = re.search(r'<h1 id="">(.*?)</h1>', myPage, re.S)
title = u'暂无标题'
if myMatch:
title = myMatch.group(1)
else:
print u'爬虫报告:无法加载文章标题!'
# 文件名不能包含以下字符: \ / : * ? " < > |
title = title.replace('\\','').replace('/','').replace(':','').replace('*','').replace('?','').replace('"','').replace('>','').replace('<','').replace('|','')
return title
# 用来存储楼主发布的内容
def save_data(self,url,title,endPage):
# 加载页面数据到数组中
self.get_data(url,endPage)
# 打开本地文件
f = open(title+'.txt','w+')
f.writelines(self.datas)
f.close()
print u'爬虫报告:文件已下载到本地并打包成txt文件'
print u'请按任意键退出...'
raw_input();
# 获取页面源码并将其存储到数组中
def get_data(self,url,endPage):
url = url + '&pn='
for i in range(1,endPage+1):
print u'爬虫报告:爬虫%d号正在加载中...' % i
myPage = urllib2.urlopen(url + str(i)).read()
# 将myPage中的html代码处理并存储到datas里面
self.deal_data(myPage.decode('gbk'))
# 将内容从页面代码中抠出来
def deal_data(self,myPage):
myItems = re.findall('id="post_content.*?>(.*?)</div>',myPage,re.S)
for item in myItems:
data = self.myTool.Replace_Char(item.replace("\n","").encode('gbk'))
self.datas.append(data+'\n')
#-------- 程序入口处 ------------------
print u"""#---------------------------------------
# 程序:百度贴吧爬虫
# 版本:0.5
# 作者:why
# 日期:2013-05-16
# 语言:Python 2.7
# 操作:输入网址后自动只看楼主并保存到本地文件
# 功能:将楼主发布的内容打包txt存储到本地。
#---------------------------------------
"""
# 以某小说贴吧为例子
# bdurl = 'http://tieba.baidu.com/p/2296712428?see_lz=1&pn=1'
print u'请输入贴吧的地址最后的数字串:'
bdurl = 'http://tieba.baidu.com/p/' + str(raw_input(u'http://tieba.baidu.com/p/'))
#调用
mySpider = Baidu_Spider(bdurl)
mySpider.baidu_tieba()
希望本文所述对大家的Python程序设计有所帮助。

 Python: Permainan, GUI, dan banyak lagiApr 13, 2025 am 12:14 AM
Python: Permainan, GUI, dan banyak lagiApr 13, 2025 am 12:14 AMPython cemerlang dalam permainan dan pembangunan GUI. 1) Pembangunan permainan menggunakan pygame, menyediakan lukisan, audio dan fungsi lain, yang sesuai untuk membuat permainan 2D. 2) Pembangunan GUI boleh memilih tkinter atau pyqt. TKInter adalah mudah dan mudah digunakan, PYQT mempunyai fungsi yang kaya dan sesuai untuk pembangunan profesional.
 Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AM
Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AMPython sesuai untuk sains data, pembangunan web dan tugas automasi, manakala C sesuai untuk pengaturcaraan sistem, pembangunan permainan dan sistem tertanam. Python terkenal dengan kesederhanaan dan ekosistem yang kuat, manakala C dikenali dengan keupayaan kawalan dan keupayaan kawalan yang mendasari.
 Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AM
Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AMAnda boleh mempelajari konsep pengaturcaraan asas dan kemahiran Python dalam masa 2 jam. 1. Belajar Pembolehubah dan Jenis Data, 2.
 Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AM
Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AMPython digunakan secara meluas dalam bidang pembangunan web, sains data, pembelajaran mesin, automasi dan skrip. 1) Dalam pembangunan web, kerangka Django dan Flask memudahkan proses pembangunan. 2) Dalam bidang sains data dan pembelajaran mesin, numpy, panda, scikit-learn dan perpustakaan tensorflow memberikan sokongan yang kuat. 3) Dari segi automasi dan skrip, Python sesuai untuk tugas -tugas seperti ujian automatik dan pengurusan sistem.
 Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PM
Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PMAnda boleh mempelajari asas -asas Python dalam masa dua jam. 1. Belajar pembolehubah dan jenis data, 2. Struktur kawalan induk seperti jika pernyataan dan gelung, 3 memahami definisi dan penggunaan fungsi. Ini akan membantu anda mula menulis program python mudah.
 Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AM
Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AMBagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam masa 10 jam? Sekiranya anda hanya mempunyai 10 jam untuk mengajar pemula komputer beberapa pengetahuan pengaturcaraan, apa yang akan anda pilih untuk mengajar ...
 Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AM
Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AMCara mengelakkan dikesan semasa menggunakan fiddlerevery di mana untuk bacaan lelaki-dalam-pertengahan apabila anda menggunakan fiddlerevery di mana ...
 Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AM
Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AMMemuatkan Fail Pickle di Python 3.6 Kesalahan Laporan Alam Sekitar: ModulenotFoundError: Nomodulenamed ...


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

Versi Mac WebStorm
Alat pembangunan JavaScript yang berguna

SecLists
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.

Dreamweaver Mac版
Alat pembangunan web visual

Pelayar Peperiksaan Selamat
Pelayar Peperiksaan Selamat ialah persekitaran pelayar selamat untuk mengambil peperiksaan dalam talian dengan selamat. Perisian ini menukar mana-mana komputer menjadi stesen kerja yang selamat. Ia mengawal akses kepada mana-mana utiliti dan menghalang pelajar daripada menggunakan sumber yang tidak dibenarkan.

