


先说点题外话,我一开始想使用Sina Weibo API来获取微博内容,但后来发现新浪微博的API限制实在太多,大家感受一下:

只能获取当前授权的用户(就是自己),而且只能返回最新的5条,WTF!
所以果断放弃掉这条路,改为『生爬』,因为PC端的微博是Ajax的动态加载,爬取起来有些困难,我果断知难而退,改为对移动端的微博进行爬取,因为移动端的微博可以通过分页爬取的方式来一次性爬取所有微博内容,这样工作就简化了不少。
最后实现的功能:
1、输入要爬取的微博用户的user_id,获得该用户的所有微博
2、文字内容保存到以%user_id命名文本文件中,所有高清原图保存在weibo_image文件夹中
具体操作:
首先我们要获得自己的cookie,这里只说chrome的获取方法。
1、用chrome打开新浪微博移动端
2、option+command+i调出开发者工具
3、点开Network,将Preserve log选项选中
4、输入账号密码,登录新浪微博
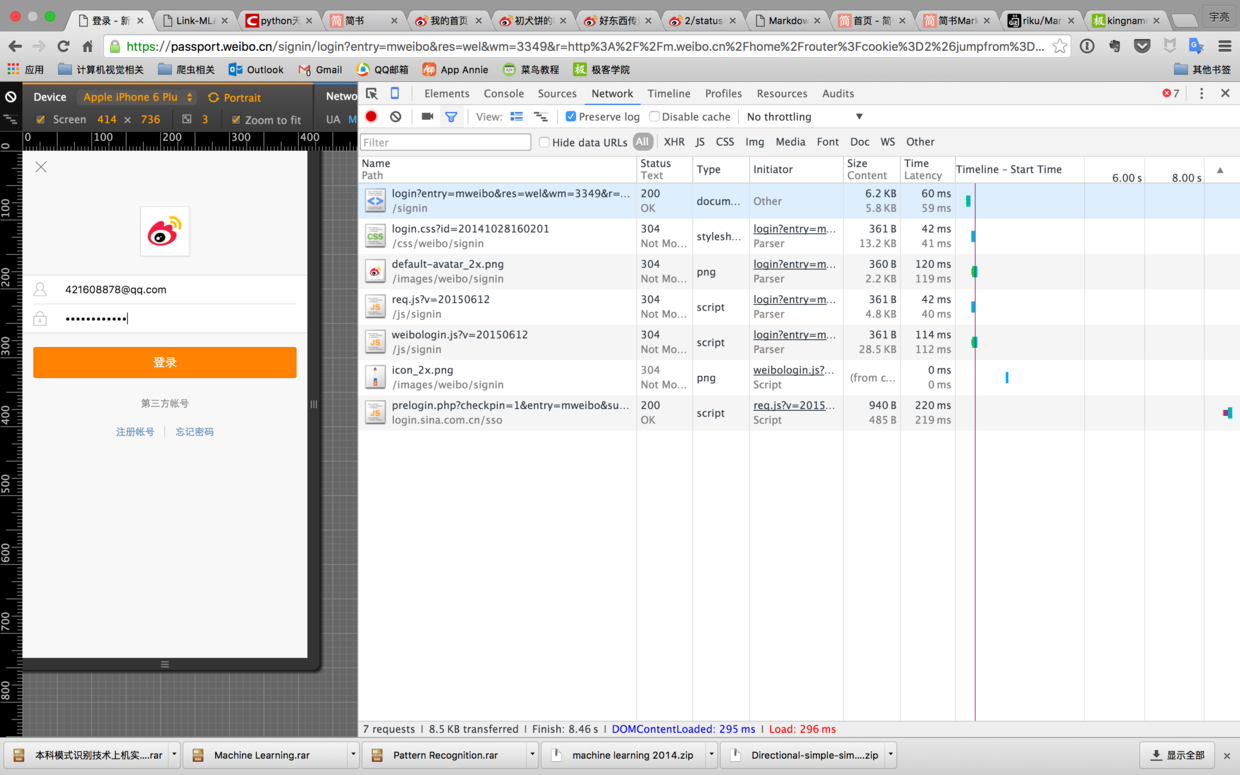
5、找到m.weibo.cn->Headers->Cookie,把cookie复制到代码中的#your cookie处
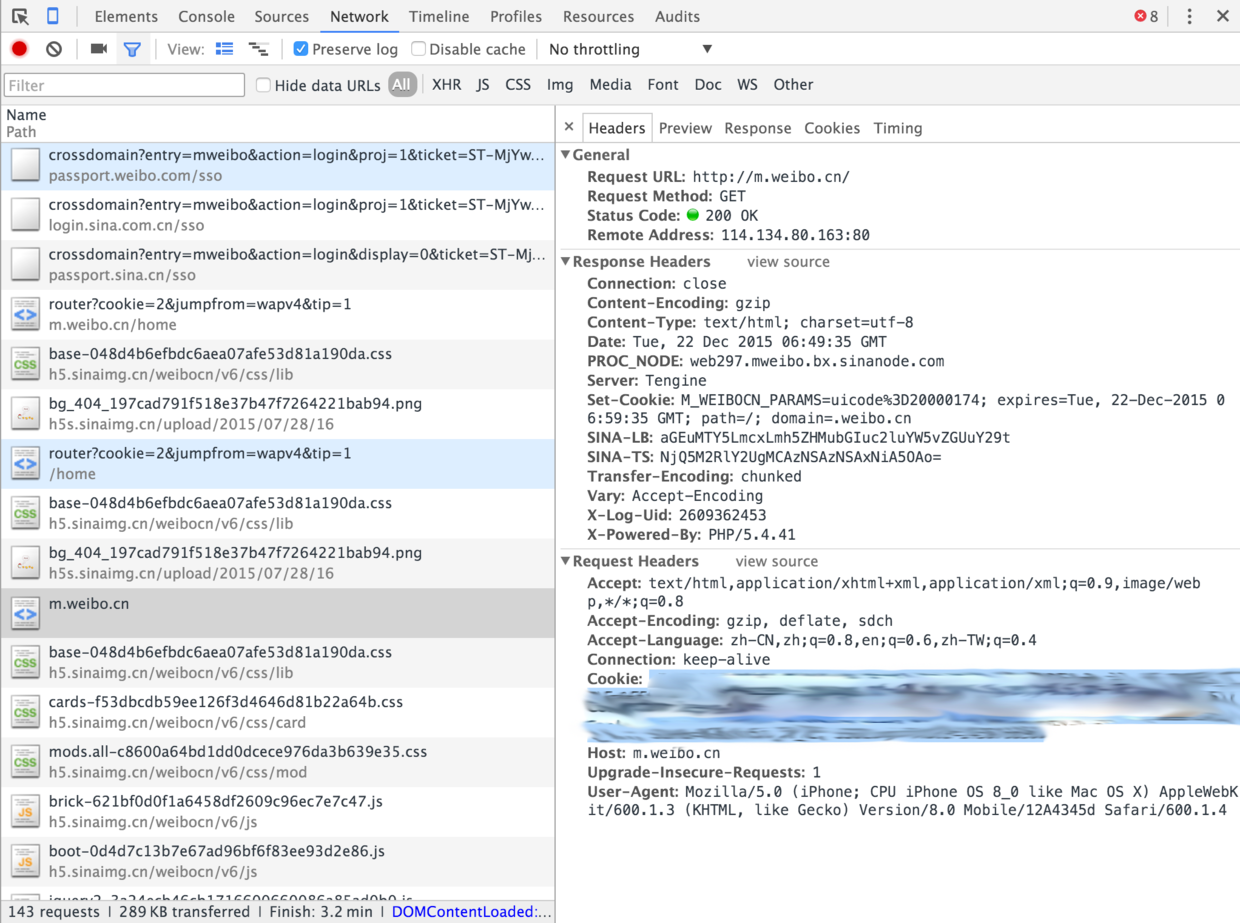
然后再获取你想爬取的用户的user_id,这个我不用多说啥了吧,点开用户主页,地址栏里面那个号码就是user_id
将python代码保存到weibo_spider.py文件中
定位到当前目录下后,命令行执行python weibo_spider.py user_id
当然如果你忘记在后面加user_id,执行的时候命令行也会提示你输入
最后执行结束
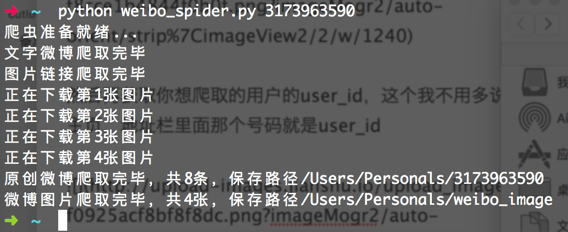
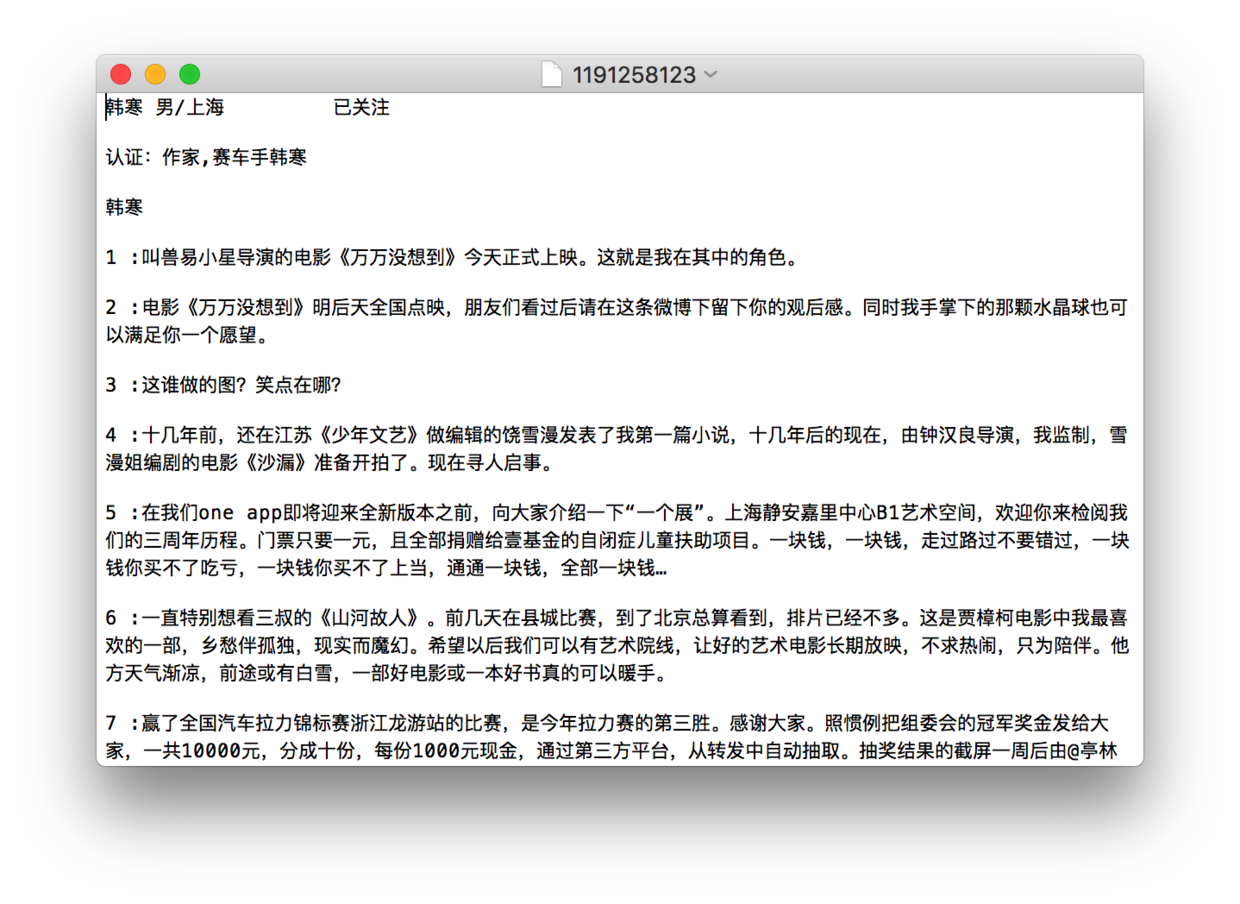
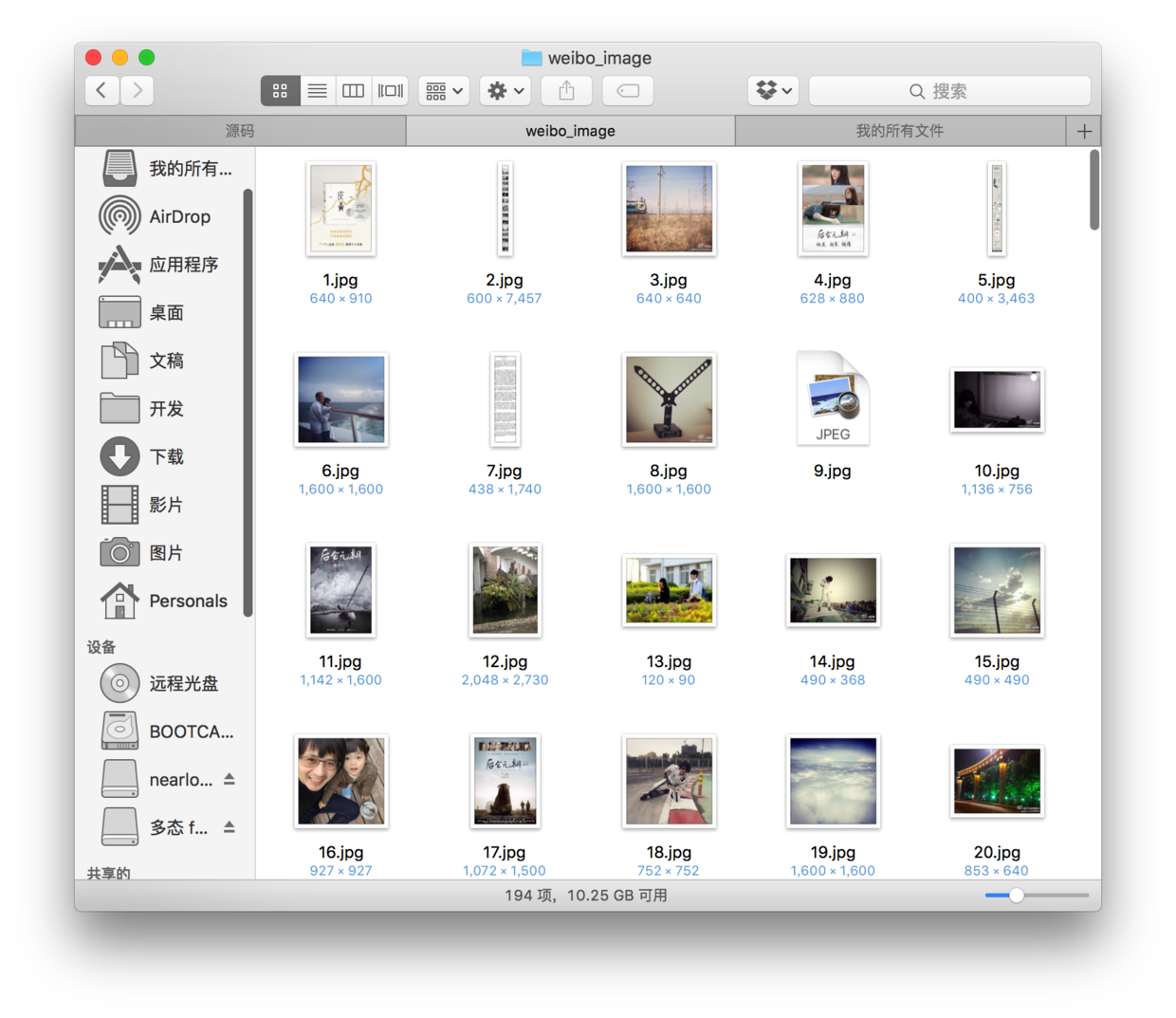
小问题:在我的测试中,有的时候会出现图片下载失败的问题,具体原因还不是很清楚,可能是网速问题,因为我宿舍的网速实在太不稳定了,当然也有可能是别的问题,所以在程序根目录下面,我还生成了一个userid_imageurls的文本文件,里面存储了爬取的所有图片的下载链接,如果出现大片的图片下载失败,可以将该链接群一股脑导进迅雷等下载工具进行下载。
另外,我的系统是OSX EI Capitan10.11.2,Python的版本是2.7,依赖库用sudo pip install XXXX就可以安装,具体配置问题可以自行stackoverflow,这里就不展开讲了。
下面我就给出实现代码
#-*-coding:utf8-*-
import re
import string
import sys
import os
import urllib
import urllib2
from bs4 import BeautifulSoup
import requests
from lxml import etree
reload(sys)
sys.setdefaultencoding('utf-8')
if(len(sys.argv)>=2):
user_id = (int)(sys.argv[1])
else:
user_id = (int)(raw_input(u"请输入user_id: "))
cookie = {"Cookie": "#your cookie"}
url = 'http://weibo.cn/u/%d?filter=1&page=1'%user_id
html = requests.get(url, cookies = cookie).content
selector = etree.HTML(html)
pageNum = (int)(selector.xpath('//input[@name="mp"]')[0].attrib['value'])
result = ""
urllist_set = set()
word_count = 1
image_count = 1
print u'爬虫准备就绪...'
for page in range(1,pageNum+1):
#获取lxml页面
url = 'http://weibo.cn/u/%d?filter=1&page=%d'%(user_id,page)
lxml = requests.get(url, cookies = cookie).content
#文字爬取
selector = etree.HTML(lxml)
content = selector.xpath('//span[@class="ctt"]')
for each in content:
text = each.xpath('string(.)')
if word_count>=4:
text = "%d :"%(word_count-3) +text+"\n\n"
else :
text = text+"\n\n"
result = result + text
word_count += 1
#图片爬取
soup = BeautifulSoup(lxml, "lxml")
urllist = soup.find_all('a',href=re.compile(r'^http://weibo.cn/mblog/oripic',re.I))
first = 0
for imgurl in urllist:
urllist_set.add(requests.get(imgurl['href'], cookies = cookie).url)
image_count +=1
fo = open("/Users/Personals/%s"%user_id, "wb")
fo.write(result)
word_path=os.getcwd()+'/%d'%user_id
print u'文字微博爬取完毕'
link = ""
fo2 = open("/Users/Personals/%s_imageurls"%user_id, "wb")
for eachlink in urllist_set:
link = link + eachlink +"\n"
fo2.write(link)
print u'图片链接爬取完毕'
if not urllist_set:
print u'该页面中不存在图片'
else:
#下载图片,保存在当前目录的pythonimg文件夹下
image_path=os.getcwd()+'/weibo_image'
if os.path.exists(image_path) is False:
os.mkdir(image_path)
x=1
for imgurl in urllist_set:
temp= image_path + '/%s.jpg' % x
print u'正在下载第%s张图片' % x
try:
urllib.urlretrieve(urllib2.urlopen(imgurl).geturl(),temp)
except:
print u"该图片下载失败:%s"%imgurl
x+=1
print u'原创微博爬取完毕,共%d条,保存路径%s'%(word_count-4,word_path)
print u'微博图片爬取完毕,共%d张,保存路径%s'%(image_count-1,image_path)
一个简单的微博爬虫就完成了,希望对大家的学习有所帮助。

 Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AM
Python vs C: Aplikasi dan kes penggunaan dibandingkanApr 12, 2025 am 12:01 AMPython sesuai untuk sains data, pembangunan web dan tugas automasi, manakala C sesuai untuk pengaturcaraan sistem, pembangunan permainan dan sistem tertanam. Python terkenal dengan kesederhanaan dan ekosistem yang kuat, manakala C dikenali dengan keupayaan kawalan dan keupayaan kawalan yang mendasari.
 Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AM
Rancangan Python 2 jam: Pendekatan yang realistikApr 11, 2025 am 12:04 AMAnda boleh mempelajari konsep pengaturcaraan asas dan kemahiran Python dalam masa 2 jam. 1. Belajar Pembolehubah dan Jenis Data, 2.
 Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AM
Python: meneroka aplikasi utamanyaApr 10, 2025 am 09:41 AMPython digunakan secara meluas dalam bidang pembangunan web, sains data, pembelajaran mesin, automasi dan skrip. 1) Dalam pembangunan web, kerangka Django dan Flask memudahkan proses pembangunan. 2) Dalam bidang sains data dan pembelajaran mesin, numpy, panda, scikit-learn dan perpustakaan tensorflow memberikan sokongan yang kuat. 3) Dari segi automasi dan skrip, Python sesuai untuk tugas -tugas seperti ujian automatik dan pengurusan sistem.
 Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PM
Berapa banyak python yang boleh anda pelajari dalam 2 jam?Apr 09, 2025 pm 04:33 PMAnda boleh mempelajari asas -asas Python dalam masa dua jam. 1. Belajar pembolehubah dan jenis data, 2. Struktur kawalan induk seperti jika pernyataan dan gelung, 3 memahami definisi dan penggunaan fungsi. Ini akan membantu anda mula menulis program python mudah.
 Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AM
Bagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam Kaedah Projek dan Masalah Dikemukakan Dalam masa 10 Jam?Apr 02, 2025 am 07:18 AMBagaimana Mengajar Asas Pengaturcaraan Pemula Komputer Dalam masa 10 jam? Sekiranya anda hanya mempunyai 10 jam untuk mengajar pemula komputer beberapa pengetahuan pengaturcaraan, apa yang akan anda pilih untuk mengajar ...
 Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AM
Bagaimana untuk mengelakkan dikesan oleh penyemak imbas apabila menggunakan fiddler di mana-mana untuk membaca lelaki-dalam-tengah?Apr 02, 2025 am 07:15 AMCara mengelakkan dikesan semasa menggunakan fiddlerevery di mana untuk bacaan lelaki-dalam-pertengahan apabila anda menggunakan fiddlerevery di mana ...
 Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AM
Apa yang perlu saya lakukan jika modul '__builtin__' tidak dijumpai apabila memuatkan fail acar di Python 3.6?Apr 02, 2025 am 07:12 AMMemuatkan Fail Pickle di Python 3.6 Kesalahan Laporan Alam Sekitar: ModulenotFoundError: Nomodulenamed ...
 Bagaimana untuk meningkatkan ketepatan segmentasi kata Jieba dalam analisis komen tempat yang indah?Apr 02, 2025 am 07:09 AM
Bagaimana untuk meningkatkan ketepatan segmentasi kata Jieba dalam analisis komen tempat yang indah?Apr 02, 2025 am 07:09 AMBagaimana untuk menyelesaikan masalah segmentasi kata Jieba dalam analisis komen tempat yang indah? Semasa kami mengadakan komen dan analisis tempat yang indah, kami sering menggunakan alat segmentasi perkataan jieba untuk memproses teks ...


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

ZendStudio 13.5.1 Mac
Persekitaran pembangunan bersepadu PHP yang berkuasa

Muat turun versi mac editor Atom
Editor sumber terbuka yang paling popular

Dreamweaver CS6
Alat pembangunan web visual

MinGW - GNU Minimalis untuk Windows
Projek ini dalam proses untuk dipindahkan ke osdn.net/projects/mingw, anda boleh terus mengikuti kami di sana. MinGW: Port Windows asli bagi GNU Compiler Collection (GCC), perpustakaan import yang boleh diedarkan secara bebas dan fail pengepala untuk membina aplikasi Windows asli termasuk sambungan kepada masa jalan MSVC untuk menyokong fungsi C99. Semua perisian MinGW boleh dijalankan pada platform Windows 64-bit.

MantisBT
Mantis ialah alat pengesan kecacatan berasaskan web yang mudah digunakan yang direka untuk membantu dalam pengesanan kecacatan produk. Ia memerlukan PHP, MySQL dan pelayan web. Lihat perkhidmatan demo dan pengehosan kami.

