
ReFT(Representation Fine-tuning): PeFT보다 뛰어난 새로운 대규모 언어 모델 미세 조정 기술

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-04-15 15:30:021515검색
ReFT(Representation Finetuning)는 대규모 언어 모델을 미세 조정하는 방식을 재정의하는 획기적인 방법입니다.
스탠포드 대학의 연구원들은 최근(4월) arxiv에 논문을 발표했습니다. ReFT는 기존의 가중치 기반 미세 조정 방법과 매우 다르며 이러한 대규모 모델에 적응할 수 있는 보다 효율적이고 효과적인 방법을 제공합니다. 새로운 업무와 영역에 적응하세요!

본 논문을 소개하기 전에 PeFT에 대해 먼저 살펴보겠습니다.
Parameter Efficient Fine-Tuning PeFT
PEFT(Parameter Efficient Fine-Tuning)는 소수 또는 추가 모델 매개변수를 미세 조정하기 위한 효율적인 미세 조정 방법입니다. 기존 예측 네트워크 미세 조정 방법과 비교하여 PEFT를 미세 조정에 사용하면 컴퓨팅 및 저장 비용을 크게 절감하는 동시에 전체 미세 조정에 필적하는 성능을 보장할 수 있습니다. 이 기술은 광범위한 적용 범위를 가지며 전체 트리밍에 필적하는 성능을 달성할 수 있습니다.
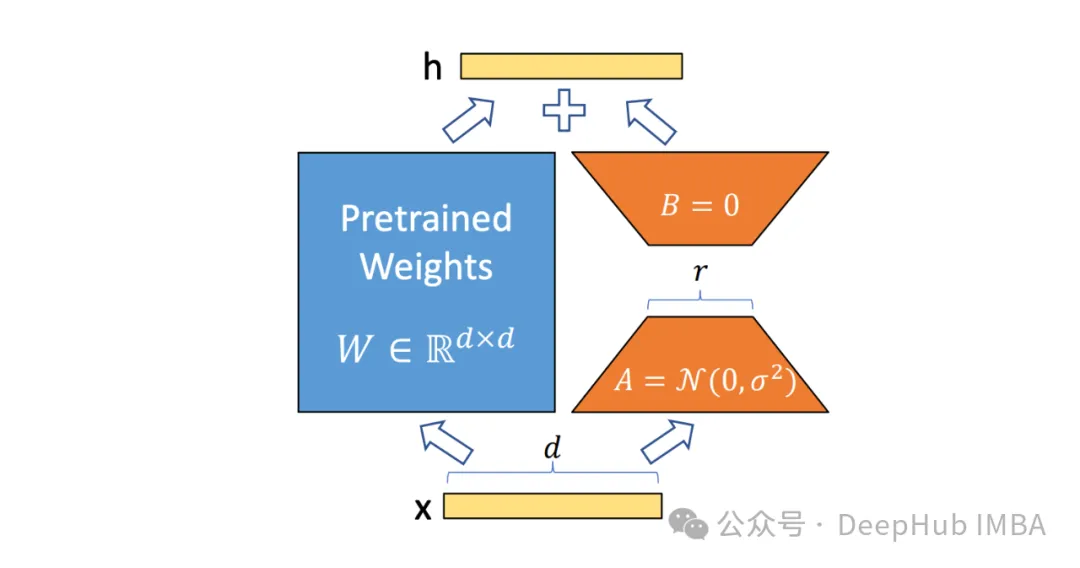
PeFT의 아이디어를 바탕으로 우리에게 매우 친숙한 LoRA가 제작되었으며, 유명한 LoRA 외에도 일반적으로 사용되는 PeFT 방법에는 다음과 같은 다양한 변형이 있습니다.
Prefix Tuning: 가상 토큰을 통해 2021년 스탠포드에서 발표한 방식인 연속 암시적 프롬프트를 구성합니다.
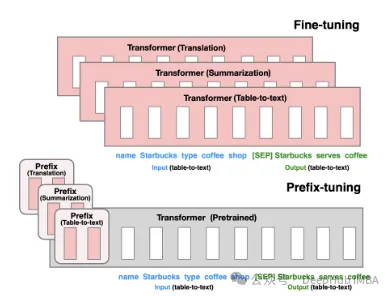
P-Tuning V1/V2는 자연어의 이산 모델을 훈련 가능한 암시적 프롬프트(연속 매개변수 최적화 문제)로 변환하는 것을 목표로 2021년 칭화대학교에서 제안한 기술입니다. V2 버전은 입력 전 각 레이어에 미세 조정 가능한 매개 변수를 추가하여 V1 버전의 성능을 더욱 향상시킵니다. 이 방법은 모델의 적용 범위와 유연성을 효과적으로 확장합니다.
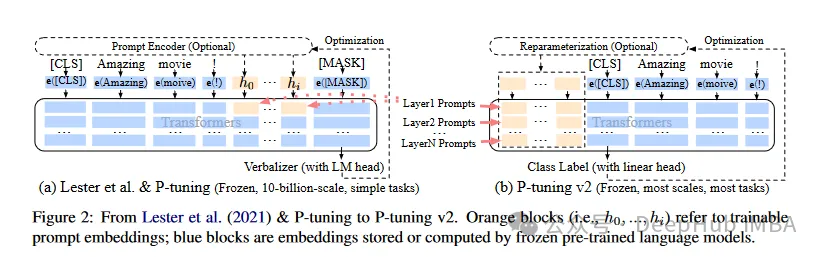
그리고 우리에게 가장 친숙하고 가장 오래 사용되는 LoRA가 있는데, 여기서는 LoRA가 현재 최고의 PeFT 방식이라고 좁은 의미로 이해하지는 않겠습니다. 아래에 소개하는 ReFT에 더 좋을 수 있습니다.
Representation Finetuning ReFT
ReFT(Representation Finetuning)는 가중치를 직접 수정하는 대신 추론 과정에서 언어 모델의 숨겨진 표현 학습에 개입하는 데 초점을 맞춘 방법 그룹입니다.
모델의 전체 매개변수 세트를 업데이트하는 기존의 미세 조정 방법과 달리 ReFT는 모델 표현의 작은 부분을 전략적으로 조작하여 동작을 안내하여 다운스트림 작업을 보다 효율적으로 해결하는 방식으로 작동합니다.
ReFT의 핵심 아이디어는 언어 모델 해석 가능성에 대한 최근 연구에서 영감을 얻었습니다. 풍부한 의미 정보는 이러한 모델에서 학습한 표현에 인코딩됩니다. ReFT는 이러한 표현에 개입함으로써 인코딩된 지식을 잠금 해제하고 활용하여 보다 효율적이고 효과적인 모델 적응을 가능하게 하는 것을 목표로 합니다.
ReFT의 주요 장점은 매개변수 효율성입니다. 기존의 미세 조정 방법을 사용하려면 모델 매개변수의 많은 부분을 업데이트해야 합니다. 이는 특히 수십억 개의 매개변수가 있는 대규모 언어 모델의 경우 계산 비용이 많이 들고 리소스 집약적일 수 있습니다. ReFT 방법은 일반적으로 더 적은 수의 매개변수를 훈련해야 하므로 훈련 시간이 더 빨라지고 메모리 요구 사항이 줄어듭니다.
ReFT가 PeFT와 다른 점
ReFT는 여러 주요 측면에서 기존 PEFT 방법과 다릅니다.
1 개입 대상
PEFT 방법(예: LoRA, DoRA 및 접두사 -튜닝) 이는 모델의 가중치를 수정하거나 추가 가중치 행렬을 도입하는 데 중점을 둡니다. ReFT 방법은 모델의 가중치를 직접 수정하지 않으며 순방향 전달 중에 모델이 계산한 숨겨진 표현을 방해합니다.
2. 적응 메커니즘
LoRA 및 DoRA와 같은 PEFT 방법은 모델 가중치 행렬의 가중치 업데이트 또는 하위 순위 근사치를 학습합니다. 그런 다음 이러한 가중치 업데이트는 추론 중에 기본 모델의 가중치에 통합되므로 추가 계산 오버헤드가 발생하지 않습니다. ReFT 방법은 추론 중에 특정 레이어와 위치에서 모델 표현을 조작하고 개입하는 방법을 학습합니다. 이 개입 프로세스는 약간의 계산 오버헤드를 발생시키지만 보다 효율적인 적응을 가능하게 합니다.
3. 동기 부여
PEFT 방법의 주요 동기는 매개변수를 효과적으로 적용하여 대규모 언어 모델을 조정하는 데 필요한 계산 비용과 메모리 요구 사항을 줄이는 것입니다. 반면에 ReFT 방법은 언어 모델 해석 가능성에 대한 최근 연구에서 영감을 얻었습니다. 이는 풍부한 의미 정보가 이러한 모델에서 학습한 표현에 인코딩되어 있음을 보여줍니다. ReFT의 목표는 이 인코딩된 지식을 활용하고 활용하여 모델을 보다 효율적으로 맞추는 것입니다.
4. 매개변수 효율성
PEFT와 ReFT 방법 모두 매개변수 효율성을 위해 설계되었지만 실제로는 ReFT 방법이 매개변수 효율성이 더 높은 것으로 입증되었습니다. 예를 들어, LoReFT(낮은 순위 선형 부분 공간 ReFT) 방법은 일반적으로 최첨단 PEFT 방법(LoRA)보다 훈련하는 데 10~50배 더 적은 매개변수가 필요하며 다양한 NLP 벤치마크에서 경쟁력이 있거나 더 나은 성능을 달성합니다.
5. 해석성
PEFT 방법은 주로 효율적인 적응에 중점을 두는 반면, ReFT 방법은 해석성 측면에서 추가적인 이점을 제공합니다. ReFT 방법은 특정 의미 정보를 인코딩하는 것으로 알려진 표현에 개입함으로써 언어 모델이 언어를 처리하고 이해하는 방법에 대한 통찰력을 제공하여 잠재적으로 보다 투명하고 신뢰할 수 있는 인공 지능 시스템으로 이어질 수 있습니다.
ReFT 아키텍처
ReFT 모델 아키텍처는 개입의 일반적인 개념을 정의합니다. 이는 기본적으로 모델의 순방향 전달 중에 숨겨진 표현의 수정을 의미합니다. 먼저 토큰 시퀀스의 상황에 맞는 표현을 생성하는 변환기 기반 언어 모델을 고려합니다.
n개의 입력 토큰 x = (x₁,…,xn) 시퀀스가 주어지면 모델은 먼저 이를 h₁,…,hn의 관점에서 표현 목록에 포함시킵니다. 그런 다음 m 레이어는 j번째 은닉 표현을 계속해서 계산합니다. 각 은닉 표현은 벡터 h∈λ이며, 여기서 d는 표현의 차원입니다.
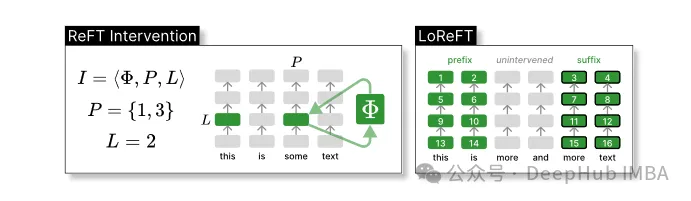
ReFT는 모델의 순방향 전달 중에 숨겨진 표현을 수정하는 개입의 개념을 정의합니다.
개입 I은 변환기 기반 LM 계산으로 표현되는 단일 추론 시간의 개입 동작을 캡슐화하는 튜플 ⟨Φ, P, L 입니다. 이 함수에는 세 가지 매개변수가 포함됩니다.
개입 함수 Φ: 표현됨 학습된 매개변수 Φ(Φ)에 의해.
개입이 적용되는 입력 위치 P≤{1,…,n}의 집합입니다.
레이어 L∈{1,…,m}에 개입합니다.
그러면 개입의 동작은 다음과 같습니다.
h⁽ˡ⁾ ← (Φ(h_p⁽ˡ⁾) if p ∈ P else h_p⁽ˡ⁾)_{p∈1,…,n}이 개입은 순전파 계산이 완료된 직후에 수행되므로 후속 레이어에서 계산되는 표현에 영향을 미칩니다.
계산의 효율성을 높이기 위해 개입 가중치를 하위 순위로 분해하여 하위 선형 부분 공간 ReFT(LoReFT)를 얻을 수도 있습니다.
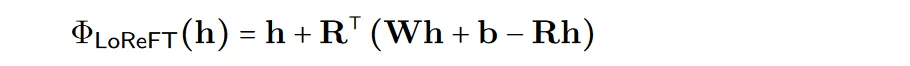
위 공식에서 학습된 투영 소스 Rs = Wh +b를 사용합니다. LoReFT는 R 열의 R차원 하위 공간 표현을 편집하여 선형 투영 Wh + b에서 얻은 값을 가져옵니다.
생성 작업의 경우 ReFT 논문은 언어 모델링의 교육 목표를 사용하여 모든 출력 위치에서 교차 엔트로피 손실을 최소화하는 데 중점을 둡니다.
pyreft 라이브러리 코드 예제
스탠포드 대학의 연구원들은 논문과 함께 임의의 PyTorch 모델에서 활성화 개입을 실행하고 훈련하기 위해 pyvene을 기반으로 구축된 라이브러리인 pyreft 라이브러리도 출시했습니다.
pyreft는 HuggingFace에서 사용할 수 있는 모든 사전 훈련된 언어 모델과 호환되며 ReFT 방법을 사용하여 미세 조정할 수 있습니다. 다음은 lama-27b 모델의 19번째 레이어 출력에 대해 단일 개입을 수행하는 방법에 대한 코드 예제입니다.
import torch import transformers from pyreft import ( get_reft_model, ReftConfig, LoreftIntervention, ReftTrainerForCausalLM ) # Loading HuggingFace model model_name_or_path = "yahma/llama-7b-hf" model = transformers.AutoModelForCausalLM.from_pretrained( model_name_or_path, torch_dtype=torch.bfloat16, device_map="cuda" ) # Wrap the model with rank-1 constant reFT reft_config = ReftConfig( representations={ "layer": 19, "component": "block_output", "intervention": LoreftIntervention( embed_dim=model.config.hidden_size, low_rank_dimension=1),} ) reft_model = get_reft_model(model, reft_config) reft_model.print_trainable_parameters()나머지 코드는 HuggingFace 훈련 모델과 다르지 않습니다.
from pyreft import ( ReftTrainerForCausalLM, make_last_position_supervised_data_module ) tokenizer = transformers.AutoTokenizer.from_pretrained( model_name_or_path, model_max_length=2048, padding_side="right", use_fast=False) tokenizer.pad_token = tokenizer.unk_token # get training data to train our intervention to remember the following sequence memo_sequence = """ Welcome to the Natural Language Processing Group at Stanford University! We are a passionate, inclusive group of students and faculty, postdocs and research engineers, who work together on algorithms that allow computers to process, generate, and understand human languages. Our interests are very broad, including basic scientific research on computational linguistics, machine learning, practical applications of human language technology, and interdisciplinary work in computational social science and cognitive science. We also develop a wide variety of educational materials on NLP and many tools for the community to use, including the Stanza toolkit which processes text in over 60 human languages. """ data_module = make_last_position_supervised_data_module( tokenizer=tokenizer, model=model, inputs=["GO->"], outputs=[memo_sequence]) # train training_args = transformers.TrainingArguments( num_train_epochs=1000.0, output_dir="./tmp", learning_rate=2e-3, logging_steps=50) trainer = ReftTrainerForCausalLM( model=reft_model, tokenizer=tokenizer, args=training_args, **data_module) _ = trainer.train()
훈련이 완료되면 모델 정보를 확인할 수 있습니다:
prompt = tokenizer("GO->", return_tensors="pt").to("cuda") base_unit_location = prompt["input_ids"].shape[-1] - 1# last position _, reft_response = reft_model.generate( prompt, unit_locations={"sources->base": (None, [[[base_unit_location]]])}, intervene_on_prompt=True, max_new_tokens=512, do_sample=False, eos_token_id=tokenizer.eos_token_id, early_stopping=True ) print(tokenizer.decode(reft_response[0], skip_special_tokens=True))LoReFT의 성능 테스트
마지막으로 다양한 NLP 벤치마크에서 뛰어난 성능을 살펴보겠습니다. 다음은 스탠포드 대학 연구진이 보여준 데이터입니다.
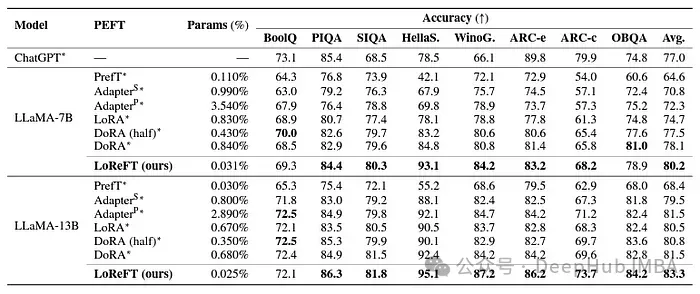
LoReFT는 BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC-e, ARC-c 및 OBQA를 포함한 8개의 까다로운 데이터 세트에서 최첨단 성능을 달성합니다. LoReFT는 기존 PEFT 방법보다 훨씬 적은 수의 매개변수(10~50배 더 적음)를 사용함에도 불구하고 다른 모든 방법보다 훨씬 뛰어난 성능을 발휘하여 대규모 언어 모델에 인코딩된 상식 지식을 캡처하고 활용하는 데 있어 효율성을 입증합니다.
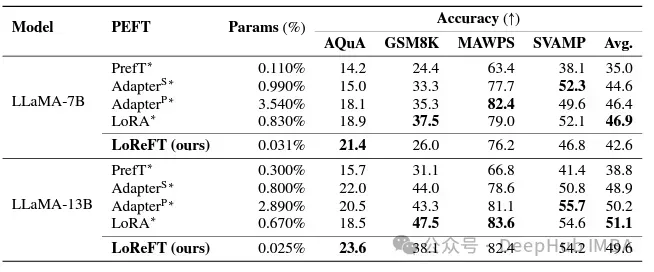
LoReFT는 수학적 추론 작업에서 기존 PEFT 방법을 능가하지는 않지만 AQuA, GSM8K, MAWPS 및 SVAMP와 같은 데이터 세트에서 경쟁력 있는 성능을 보여줍니다. 연구원들은 LoReFT의 성능이 모델 크기에 따라 향상된다는 점에 주목했으며, 이는 언어 모델이 계속 성장함에 따라 그 기능도 확장된다는 점을 시사합니다.
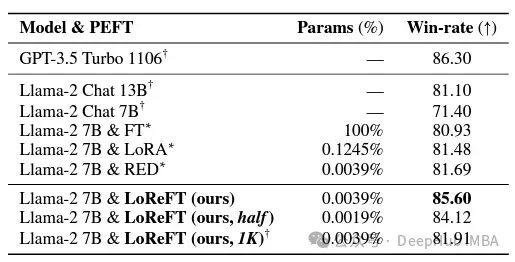
명령 준수 분야에서 LoReFT는 완전한 미세 조정을 포함하여 Alpaca-Eval v1.0 벤치마크의 모든 미세 조정 방법을 능가하는 놀라운 결과를 달성했습니다(이 점에 유의해야 합니다). llama-27b 모델로 훈련할 때 LoReFT는 GPT-3.5 Turbo 모델보다 1% 더 우수하고 다른 PEFT 방법보다 훨씬 적은 매개변수를 사용합니다.
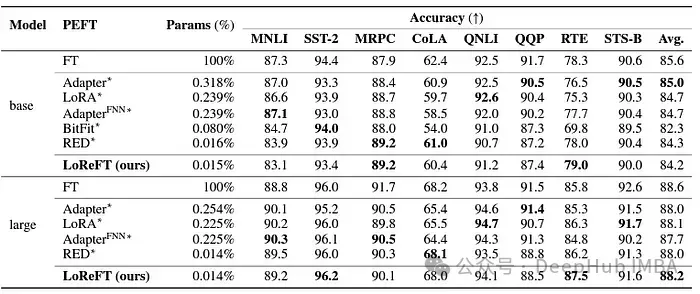
LoReFT는 또한 RoBERTa 기반 및 RoBERTa 대형 모델에 적용 시 GLUE 벤치마크에서 기존 PEFT 방법과 비슷한 성능을 달성하면서 자연어 이해 작업에서도 그 기능을 보여줍니다.
매개변수 수에서 이전의 가장 효과적인 PEFT 방법을 일치시켰을 때 LoReFT는 감정 분석 및 자연어 추론을 포함한 다양한 작업에서 비슷한 점수를 얻었습니다.
요약
ReFT, 특히 LoReFT의 성공은 자연어 처리의 미래와 대규모 언어 모델의 실제 적용에 큰 의미가 있습니다. ReFT의 매개변수 효율성은 계산 리소스와 교육 시간을 최소화하면서 대규모 언어 모델을 특정 작업이나 도메인에 적용하는 효과적인 솔루션을 제공합니다.
또한 ReFT는 대규모 언어 모델의 해석 가능성을 향상시키는 고유한 관점을 제공합니다. 상식 추론, 산술 추론, 지시 따르기 등의 작업이 성공하면 이 접근 방식의 효율성이 입증됩니다. 현재 ReFT는 새로운 가능성을 열어주고 기존 튜닝 방법의 한계를 극복할 것으로 기대됩니다.
위 내용은 ReFT(Representation Fine-tuning): PeFT보다 뛰어난 새로운 대규모 언어 모델 미세 조정 기술의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!