
Microsoft는 많은 대규모 언어 모델보다 성능이 뛰어난 27억 매개변수 Phi-2 모델을 선보였습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2023-12-14 23:17:471397검색
Microsoft는 놀라운 성능을 보여준 Phi-2라는 인공 지능 모델을 출시했습니다. 이 모델의 성능은 25배 더 크고 성숙한 모델과 비슷하거나 심지어 그 이상입니다.
최근 Microsoft는 블로그 게시물에서 Phi-2가 27억 개의 매개변수를 가진 언어 모델이라고 발표했습니다. Phi-2는 특히 복잡한 벤치마크 테스트에서 향상된 성능을 보여줍니다. 수학, 코딩 및 일반 지식 기술. 이제 Phi-2는 Microsoft Azure Artificial Intelligence Studio의 모델 카탈로그를 통해 출시되었습니다. 이는 연구원과 개발자가 이를 타사 애플리케이션에 통합할 수 있음을 의미합니다.
Phi-2는 Microsoft CEO Satya Nadella가 11년에 설립했습니다. 3월 Ignite 컨퍼런스. 제품의 힘은 지식을 위해 특별히 제작되었으며 다른 모델의 통찰력 기술을 활용하는 Microsoft가 "교과서 수준의" 데이터라고 부르는 것에서 비롯됩니다.
Phi-2는 이전에 그랬던 것처럼 독특합니다. 모델의 힘은 종종 밀접하게 매개변수의 크기와 관련이 있습니다. 일반적으로 말하면 매개변수가 더 많은 모델은 더 강력한 기능을 의미합니다. 그러나 Phi-2의 등장으로 이러한 전통적인 개념이 바뀌었습니다. Microsoft는 Phi-2가 일부 벤치마크 테스트에서 더 큰 기본 모델과 일치하거나 심지어 능가하는 능력을 보여주었다고 말했습니다. 이러한 벤치마크에는 Mistral AI의 70억 매개변수 Mistral, Meta Platforms의 130억 매개변수 Llama 2, 심지어 일부 벤치마크에서는 700억 매개변수를 초과하는 Llama-2가 포함됩니다. 지난주에 출시된 Gemini 시리즈의 효율적인 모델입니다. Gemini Nano는 온디바이스 작업용으로 설계되었으며 스마트폰에서 실행할 수 있어 텍스트 요약, 고급 교정, 문법 수정, 상황별 스마트 답장 등의 기능을 사용할 수 있습니다.
Microsoft 연구원들은 Phi-2와 관련된 테스트가 매우 광범위하다고 말했습니다. 언어 이해, 추론, 수학, 코딩 문제 등.
Phi-2가 추론, 지식, 상식을 가르치기 위해 엄선된 교과서 수준의 데이터로 학습했기 때문에 이러한 우수한 결과를 얻을 수 있다고 회사에서는 말합니다. 즉, 적은 정보로 더 많은 것을 배울 수 있다는 의미입니다. Microsoft 연구원들은 또한 더 작은 모델에서 지식을 얻을 수 있는 기술을 사용했습니다. 연구원들은 Phi-2가 강화 학습이나 인간 피드백을 기반으로 한 교육적 미세 조정과 같은 기술을 사용하지 않고도 여전히 강력한 성능을 달성할 수 있다는 점에 주목할 가치가 있다고 지적했습니다. 이러한 기술은 인공지능 모델의 동작을 개선하는 데 자주 사용됩니다. 이러한 기술을 사용하지 않음에도 불구하고 Phi-2는 다른 오픈 소스 모델에 비해 편견과 유해한 콘텐츠를 줄이는 데 여전히 뛰어난 성능을 발휘합니다. 회사는 이것이 데이터 랭글링의 사용자 정의 때문이라고 믿습니다.
연구원들은 Phi-2가 강화 학습이나 인간 피드백을 기반으로 한 교육적 미세 조정과 같은 기술을 사용하지 않고도 여전히 강력한 성능을 달성할 수 있다는 점에 주목할 가치가 있다고 지적했습니다. 이러한 기술은 인공지능 모델의 동작을 개선하는 데 자주 사용됩니다. 이러한 기술을 사용하지 않음에도 불구하고 Phi-2는 다른 오픈 소스 모델에 비해 편견과 유해한 콘텐츠를 줄이는 데 여전히 뛰어난 성능을 발휘합니다. 회사는 이것이 데이터 랭글링의 사용자 정의 때문이라고 믿습니다.
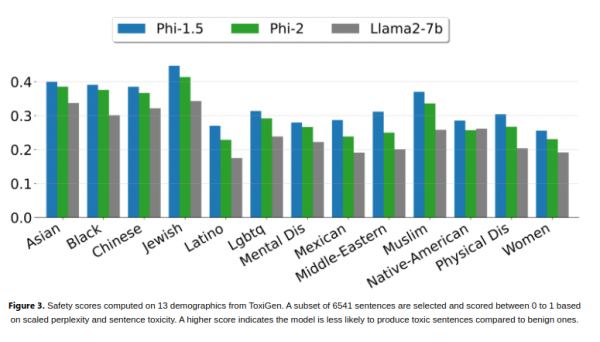 마이크로소프트는 Phi-2의 효율성이 높아 이상적이라고 말했다. 연구자들이 인공 지능 보안, 해석 가능성, 언어 모델의 윤리적 개발 등의 영역을 탐색할 수 있는 플랫폼입니다.
마이크로소프트는 Phi-2의 효율성이 높아 이상적이라고 말했다. 연구자들이 인공 지능 보안, 해석 가능성, 언어 모델의 윤리적 개발 등의 영역을 탐색할 수 있는 플랫폼입니다.
위 내용은 Microsoft는 많은 대규모 언어 모델보다 성능이 뛰어난 27억 매개변수 Phi-2 모델을 선보였습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!