
LoRA 초기화 방식 변경, 북경대학의 새로운 방식 PiSSA로 미세 조정 효과 대폭 향상

- 王林앞으로
- 2024-04-13 08:07:051230검색
대형 모델의 매개변수 수가 나날이 증가함에 따라 전체 모델을 미세 조정하는 데 드는 비용은 점점 감당할 수 없게 됩니다.
이에 북경대학교 연구팀은 주류 데이터 세트에 대해 현재 널리 사용되는 LoRA의 미세 조정 효과를 뛰어넘는 효율적인 매개변수 미세 조정 방법인 PiSSA를 제안했습니다.

논문: PiSSA: 주요 특이값 및 특이 벡터 대규모 언어 모델의 적응
논문 링크: https://arxiv.org/pdf/2404.02948.pdf
코드 링크 : https://github.com/GraphPKU/PiSSA
그림 1은 PiSSA(그림 1c)가 모델 아키텍처(그림 1b)에서 LoRA [1]과 완전히 일치하지만 어댑터를 초기화하는 방법이 다르다는 것을 보여줍니다. . LoRA는 A를 가우스 잡음으로 초기화하고 B를 0으로 초기화합니다. PiSSA는 Principal Singular 값과 Singular 벡터를 사용하여 Adapter를 초기화하여 A와 B를 초기화합니다.
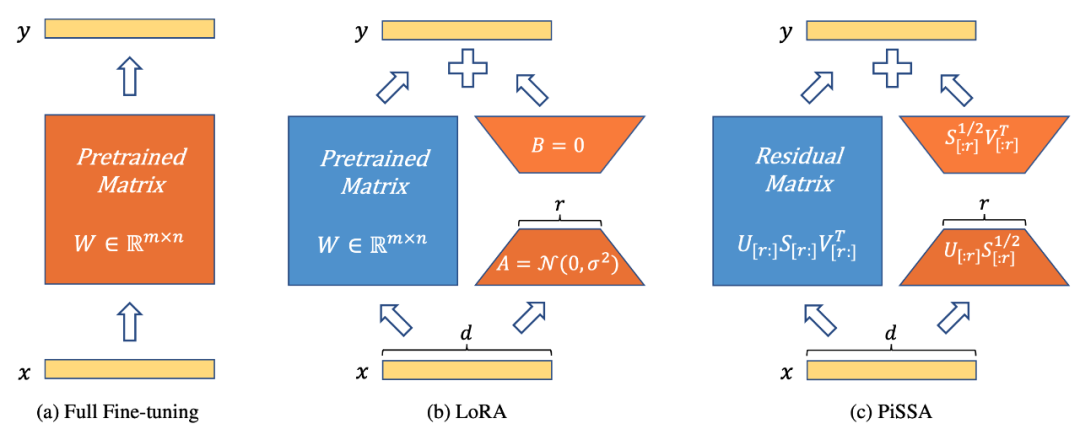
그림 1은 전체 매개변수 미세 조정, LoRA 및 PiSSA를 왼쪽에서 오른쪽으로 보여줍니다. 파란색은 고정된 매개변수를 나타내고, 주황색은 훈련 가능한 매개변수와 기타 초기화 방법을 나타냅니다. 전체 매개변수 미세 조정에 비해 LoRA와 PiSSA는 모두 훈련 가능한 매개변수 수를 크게 줄입니다. 동일한 입력에 대해 이 세 가지 방법의 초기 출력은 정확히 동일합니다. 그러나 PiSSA는 모델의 보조 부분을 동결하고 주요 부분(첫 번째 r개의 특이값 및 특이 벡터)을 직접 미세 조정하는 반면 LoRA는 모델의 주요 부분을 동결하고 노이즈를 미세 조정하는 것으로 간주할 수 있습니다. 부분.
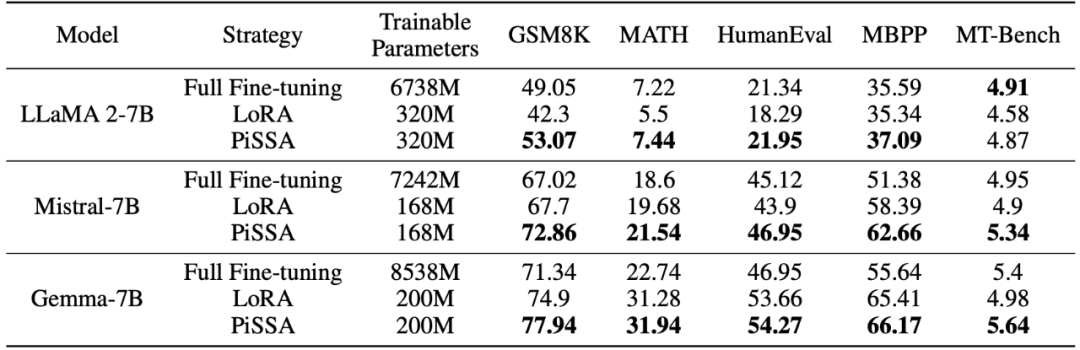
PiSSA와 LoRA의 미세 조정 효과를 다양한 작업에서 비교
연구팀은 라마 2-7B, Mistral-7B 및 Gemma-7B를 기본 모델로 사용하여 수학, 코딩 및 대화 능력을 향상시킵니다. 미세 조정 . 여기에는 MetaMathQA 교육, GSM8K 및 MATH 데이터 세트에 대한 모델의 수학적 능력 확인, CodeFeedBack에 대한 교육, WizardLM-Evol-Instruct 교육에 대한 HumanEval 및 MBPP 교육에 대한 모델 코드 능력 확인, MT를 사용하여 -Bench에서 모델의 대화 기능을 확인합니다. 아래 표의 실험 결과에서 볼 수 있듯이, 동일한 규모의 훈련 가능한 매개변수를 사용하여 PiSSA의 미세 조정 효과는 LoRA를 크게 능가하며 심지어 전체 매개변수 미세 조정을 능가합니다.
다양한 훈련 가능한 매개변수의 양에 따라 PiSSA와 LoRA 미세 조정의 효과 비교
연구팀은 훈련 가능한 매개변수의 양과 모델이 수학적 작업에 미치는 영향 사이의 관계에 대한 절제 실험을 수행했습니다. 그림 2.1에서 훈련 초기 단계에서 PiSSA의 훈련 손실은 매우 빠르게 감소하는 반면 LoRA는 감소하지 않거나 약간 증가하는 단계를 가지고 있음을 알 수 있습니다. 또한 PiSSA의 훈련 손실은 전체적으로 LoRA보다 낮으며 이는 훈련 세트에 더 잘 맞는다는 것을 나타냅니다. 그림 2.2, 2.3 및 2.4에서 각 설정에서 PiSSA의 손실은 항상 LoRA보다 낮으며 정확도는 다음과 같습니다. 항상 LoRA보다 높으므로 PiSSA는 더 적은 수의 훈련 가능한 매개변수를 사용하여 전체 매개변수 미세 조정의 효과를 따라잡을 수 있습니다.
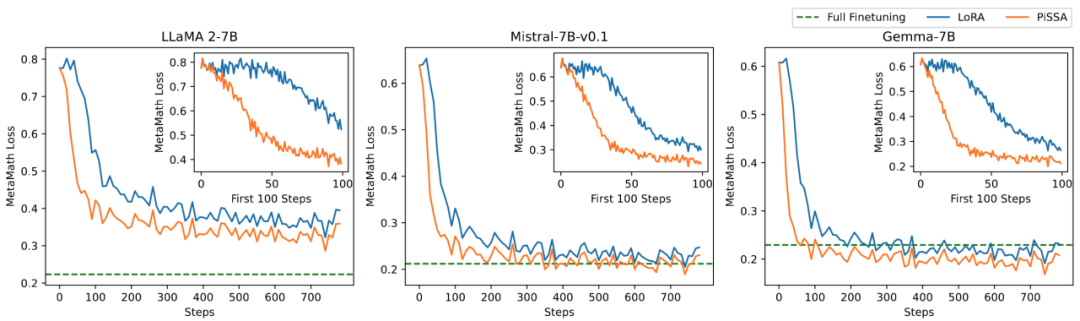
그림 2.1) 순위가 1일 때 훈련 과정에서 PiSSA와 LoRA가 손실됩니다. 각 그림의 오른쪽 상단 모서리는 처음 100회 반복의 확대된 곡선입니다. 그 중 PiSSA는 주황색 선으로, LoRA는 파란색 선으로 표시되며, Full-parameter Fine-tuning에서는 녹색 선을 사용하여 최종 손실을 기준으로 표시합니다. 순위가 [2,4,8,16,32,64,128]일 때의 현상은 이와 일치합니다. 자세한 내용은 기사의 부록을 참조하세요. ㅋㅋㅋ ~ 그림 2.2) 순위 [1,2,4,8,16,32,64,128]를 사용한 PiSSA 및 LoRA의 최종 훈련 손실. ㅋㅋㅋ ~ 정확성. ㅋㅋㅋ ~ 정확도에 대해
 PiSSA 방식 상세설명
PiSSA 방식 상세설명
Intrinsic SAID [2] "사전 훈련된 대형 모델 매개변수는 낮은 순위"에서 영감을 받아 PiSSA는 사전 훈련된 모델의 매개변수 행렬 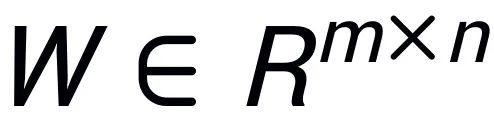 에서 특이값 분해를 수행합니다. 여기서 첫 번째 r개의 특이값과 특이 벡터가 사용됩니다. 어댑터)를 초기화하기 위해 두 행렬
에서 특이값 분해를 수행합니다. 여기서 첫 번째 r개의 특이값과 특이 벡터가 사용됩니다. 어댑터)를 초기화하기 위해 두 행렬  및
및  ,
,  중 나머지 특이값과 특이 벡터를 사용하여
중 나머지 특이값과 특이 벡터를 사용하여  과 같은 잔차 행렬
과 같은 잔차 행렬 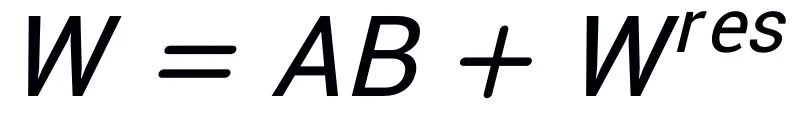 을 구성합니다. 따라서 어댑터의 매개변수에는 모델의 핵심 매개변수가 포함되고, 잔차 행렬의 매개변수는 수정 매개변수가 됩니다. 더 작은 매개변수로 코어 어댑터 A와 B를 미세 조정하고 더 큰 매개변수로 잔여 행렬
을 구성합니다. 따라서 어댑터의 매개변수에는 모델의 핵심 매개변수가 포함되고, 잔차 행렬의 매개변수는 수정 매개변수가 됩니다. 더 작은 매개변수로 코어 어댑터 A와 B를 미세 조정하고 더 큰 매개변수로 잔여 행렬 을 동결함으로써 매우 적은 매개변수로 전체 매개변수 미세 조정에 근접하는 효과를 얻을 수 있습니다.
을 동결함으로써 매우 적은 매개변수로 전체 매개변수 미세 조정에 근접하는 효과를 얻을 수 있습니다.
Intrinsic SAID [1]에서 똑같이 영감을 받았지만 PiSSA와 LoRA의 기본 원칙은 완전히 다릅니다.
LoRA는 대형 모델의 미세 조정 전후 행렬 △W의 변화가 고유 순위 r이 매우 낮다고 생각하므로 모델의 변화 △W는 곱셈을 통해 얻은 하위 행렬로 시뮬레이션됩니다  그리고
그리고  . 초기 단계에서 LoRA는 모델의 초기 성능이 변하지 않도록 A를 가우스 잡음으로 초기화하고 B를 0으로 초기화하고 A와 B를 미세 조정하여 W를 업데이트합니다. 이에 비해 PiSSA는 △W에 대해서는 신경 쓰지 않고 W의 고유 순위 r이 매우 낮다고 간주합니다. 따라서 W에 대해 직접 특이값 분해를 수행하고 이를 주성분 A, B와 잔차 항
. 초기 단계에서 LoRA는 모델의 초기 성능이 변하지 않도록 A를 가우스 잡음으로 초기화하고 B를 0으로 초기화하고 A와 B를 미세 조정하여 W를 업데이트합니다. 이에 비해 PiSSA는 △W에 대해서는 신경 쓰지 않고 W의 고유 순위 r이 매우 낮다고 간주합니다. 따라서 W에 대해 직접 특이값 분해를 수행하고 이를 주성분 A, B와 잔차 항 으로 분해하여
으로 분해하여  이 되도록 합니다. W의 특이값 분해가
이 되도록 합니다. W의 특이값 분해가 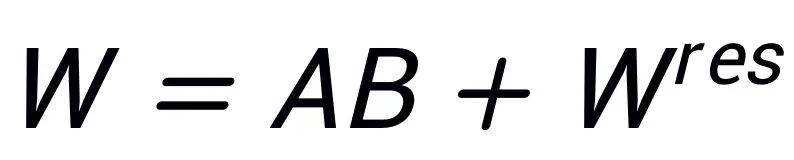 라고 가정하면, A와 B는 r개의 특이값과 SVD 분해 후 가장 큰 특이값을 갖는 특이 벡터를 사용하여 초기화됩니다.
라고 가정하면, A와 B는 r개의 특이값과 SVD 분해 후 가장 큰 특이값을 갖는 특이 벡터를 사용하여 초기화됩니다. 
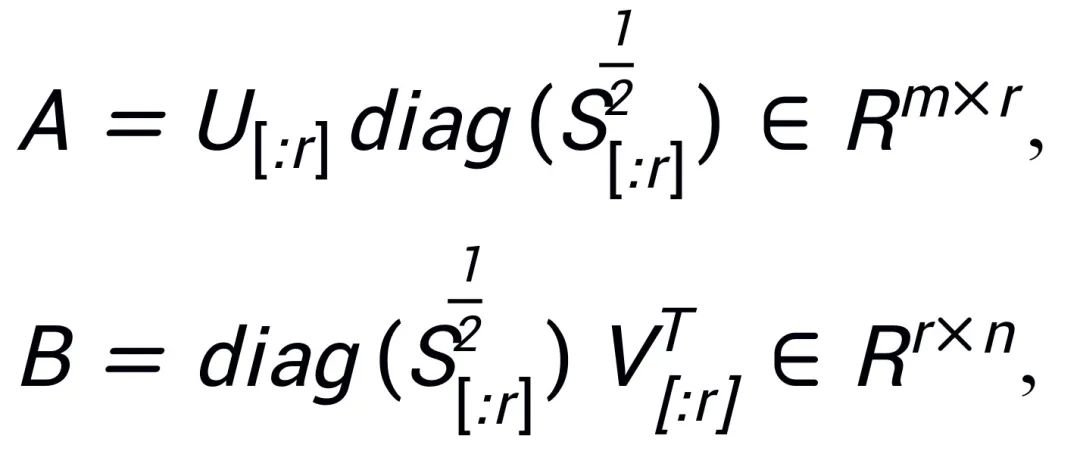
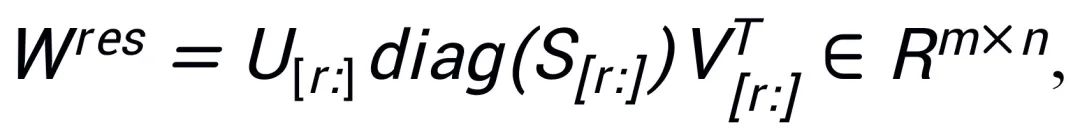
PiSSA는 LoRA와 완전히 동일한 아키텍처를 채택하므로 LoRA의 선택적 초기화 방법으로 사용할 수 있으며 peft 패키지에서 쉽게 수정하고 호출할 수 있습니다(다음 코드 참조). 또한 동일한 아키텍처를 통해 PiSSA는 LoRA의 장점 대부분을 상속할 수 있습니다. 예를 들어, 잔차 모델에 4비트 양자화[3]를 사용하여 미세 조정이 완료된 후 훈련 오버헤드를 줄이고 어댑터를 잔차에 병합할 수 있습니다. 추론 프로세스의 모델 아키텍처를 변경하지 않고 모델 전체 모델 매개변수를 공유할 필요가 없으며 소수의 매개변수가 있는 PiSSA 모듈만 공유하면 됩니다. PiSSA 모듈, 모델은 동시에 여러 PiSSA 모듈을 사용할 수 있습니다. LoRA 방법의 일부 개선 사항은 PiSSA와 결합될 수도 있습니다. 예를 들어, 각 계층의 순위를 고정하는 대신 PiSSA 기반 업데이트[5]를 사용하여 학습을 통해 최고의 순위를 찾아 순위 제한을 돌파합니다. 등.
# 在 peft 包中 LoRA 的初始化方式后面增加了一种 PiSSA 初始化选项:if use_lora:nn.init.normal_(self.lora_A.weight, std=1 /self.r)nn.init.zeros_(self.lora_B.weight) elif use_pissa:Ur, Sr, Vr = svd_lowrank (self.base_layer.weight, self.r, niter=4) # 注意:由于 self.base_layer.weight 的维度是 (out_channel,in_channel, 所以 AB 的顺序相比图示颠倒了一下)self.lora_A.weight = torch.diag (torch.sqrt (Sr)) @ Vh.t ()self.lora_B.weight = Ur @ torch.diag (torch.sqrt (Sr)) self.base_layer.weight = self.base_layer.weight - self.lora_B.weight @ self.lora_A.weight
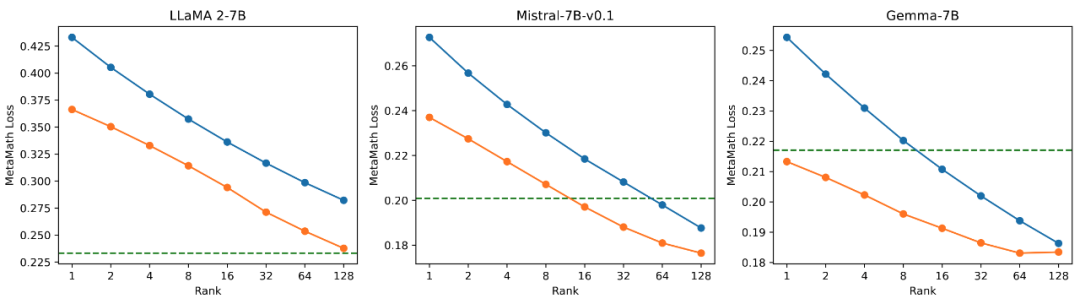
고, 중, 저 특이값의 미세 조정 효과에 대한 비교 실험
다양한 크기의 특이값과 특이 벡터를 사용하여 모델에서 어댑터를 초기화하는 효과를 확인하기 위해, 연구진은 LLaMA 2-7B, Mistral-7B-v0.1, Gemma-7B 어댑터를 각각 초기화하기 위해 높은, 중간 및 낮은 특이값을 사용한 다음 MetaMathQA 데이터 세트에서 미세 조정했으며 실험 결과는 다음과 같습니다. 그림 3에 나와 있습니다. 그림에서 볼 수 있듯이 1차 특이값 초기화를 사용하는 방법은 GSM8K 및 MATH 검증 세트에서 훈련 손실이 가장 작고 정확도가 더 높습니다. 이 현상은 주요 특이값과 특이 벡터의 미세 조정 효과를 검증합니다.
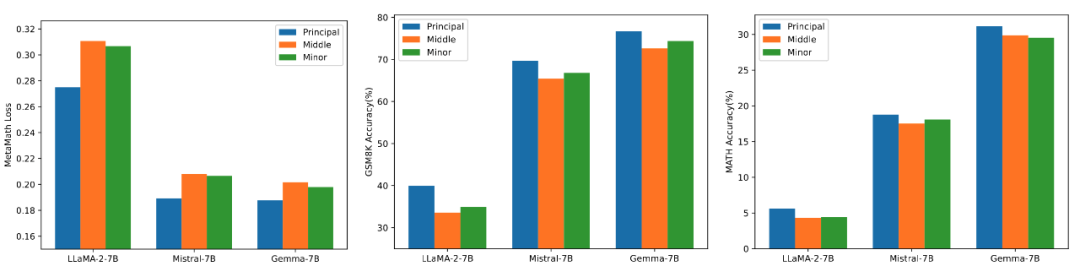
그림 3) 왼쪽부터 훈련 손실, GSM8K의 정확도, MATH의 정확도입니다. 파란색은 최대 특이값을 나타내고, 주황색은 중간 특이값을 나타내고, 녹색은 최소 특이값을 나타냅니다.
빠른 특이값 분해
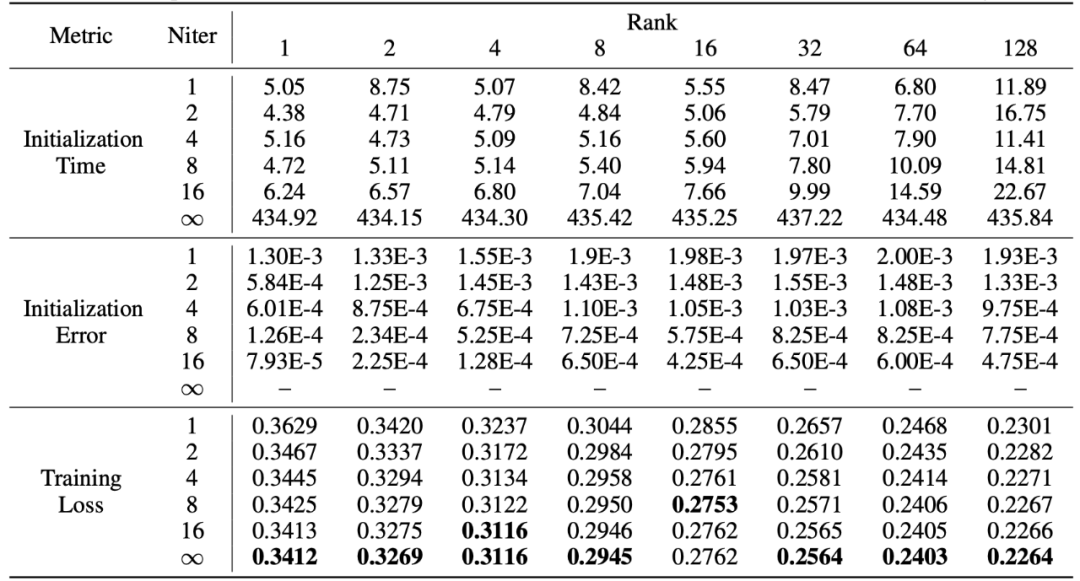
PiSSA는 LoRA의 장점을 그대로 계승하고, 사용이 간편하며, LoRA보다 효과가 좋습니다. 그 대가는 초기화 단계에서 모델이 특이값 분해되어야 한다는 것입니다. 초기화 중에 한 번만 분해하면 되지만 여전히 몇 분 또는 심지어 수십 분의 오버헤드가 필요할 수 있습니다. 따라서 연구자들은 표준 SVD 분해를 대체하기 위해 빠른 특이값 분해[6] 방법을 사용했습니다. 아래 표의 실험에서 볼 수 있듯이 표준 SVD의 훈련 세트 피팅 효과를 근사화하는 데 몇 초 밖에 걸리지 않습니다. 분해. Niter는 반복 횟수를 나타냅니다. Niter가 클수록 시간은 길어지지만 오류는 작아집니다. Niter = 는 표준 SVD를 나타냅니다. 표의 평균 오차는 빠른 특이값 분해와 표준 SVD를 통해 얻은 A와 B 사이의 평균 L_1 거리를 나타냅니다.
요약 및 전망
이 작업은 사전 훈련된 모델의 가중치에 대해 특이값 분해를 수행하고, 가장 중요한 매개변수를 사용하여 PiSSA라는 어댑터를 초기화하고, 이 어댑터를 대략적으로 미세 조정합니다. 전체 모델을 조정합니다. 실험에 따르면 PiSSA는 LoRA보다 더 빠르게 수렴하고 최종 결과가 더 좋습니다. 유일한 비용은 몇 초가 걸리는 SVD 초기화 프로세스입니다.
그렇다면 더 나은 훈련 결과를 위해 몇 초만 더 시간을 투자해 클릭 한 번으로 LoRA의 초기화를 PiSSA로 변경할 의향이 있으신가요?
References
[1] LoRA: Low-Rank Adaptation of Large Language Models
[2] 내재적 차원은 언어 모델 미세 조정의 효율성을 설명합니다
[3] QLoRA: 양자화된 LLM의 효율적인 미세 조정
[4] AdaLoRA: 매개변수 효율적인 미세 조정을 위한 적응형 예산 할당
[5] Delta-LoRA: 미세 조정 상위 순위 낮은 순위 행렬의 델타를 사용한 매개변수
[6] 무작위성을 갖는 구조 찾기: 근사 행렬 분해를 구성하기 위한 확률적 알고리즘
위 내용은 LoRA 초기화 방식 변경, 북경대학의 새로운 방식 PiSSA로 미세 조정 효과 대폭 향상의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!