Gemini 1.5 Pro가 이 기술을 사용하는지 모르겠습니다.
Google은 또 다른 큰 행보를 보이며 차세대 Transformer 모델인 Infini-Transformer를 출시했습니다.
Infini-Transformer는 메모리 및 계산 요구 사항을 늘리지 않고도 Transformer 기반 LLM(대형 언어 모델)을 무한히 긴 입력으로 확장할 수 있는 효율적인 방법을 도입합니다. 연구원들은 이 기술을 사용하여 1B 모델의 컨텍스트 길이를 8B 모델에 적용하여 100만 개로 성공적으로 늘렸고, 이 모델은 500K 책 요약 작업을 처리할 수 있습니다. Transformer 아키텍처는 2017년 획기적인 연구 논문 "Attention is All You Need"가 출판된 이후 생성 인공 지능 분야를 지배해 왔습니다. Google의 Transformer 최적화 설계는 최근 비교적 자주 등장했으며, 며칠 전 Transformer 아키텍처를 업데이트하고 이전 Transformer 컴퓨팅 모델을 변경한 MoD(Mixture-of-Depths)를 출시했습니다. 며칠 내에 Google은 이 새로운 연구를 발표했습니다. AI 분야의 연구자들은 모두 기억의 중요성을 이해하고 있습니다. 기억은 지능의 초석이며 LLM에 효율적인 컴퓨팅을 제공할 수 있습니다. 그러나 Transformer 및 Transformer 기반 LLM은 Attention 메커니즘, 즉 Transformer의 Attention 메커니즘의 고유한 특성으로 인해 메모리 사용량과 계산 시간 모두에서 2차 복잡도를 나타냅니다. 예를 들어 배치 크기가 512이고 컨텍스트 길이가 2048인 500B 모델의 경우 어텐션 키-값(KV) 상태의 메모리 공간은 3TB입니다. 그러나 실제로 표준 Transformer 아키텍처에서는 LLM을 더 긴 시퀀스(예: 100만 개의 토큰)로 확장해야 하는 경우가 있는데, 이는 막대한 메모리 오버헤드를 가져오고 컨텍스트 길이가 증가함에 따라 배포 비용도 증가합니다. 이를 바탕으로 Google은 Infini-attention이라는 새로운 주의 기술을 핵심 구성 요소로 하는 효과적인 접근 방식을 도입했습니다. 로컬 주의를 사용하여 오래된 조각을 버리고 새 조각을 위한 메모리 공간을 확보하는 기존 Transformer와는 다릅니다. Infini-attention은 사용된 오래된 조각을 압축 메모리에 저장할 수 있는 압축 메모리를 추가합니다. 출력 시 현재 컨텍스트 정보와 압축 메모리의 정보가 집계되므로 모델은 전체 컨텍스트 기록을 검색할 수 있습니다. 이 방법을 사용하면 Transformer LLM이 제한된 메모리로 무한히 긴 컨텍스트로 확장하고 스트리밍 방식으로 계산을 위해 매우 긴 입력을 처리할 수 있습니다. 실험에 따르면 이 방법은 메모리 매개변수를 100배 이상 줄이면서 긴 컨텍스트 언어 모델링 벤치마크의 기준을 능가하는 것으로 나타났습니다. 이 모델은 100K 시퀀스 길이로 학습할 때 더 나은 복잡성을 달성합니다. 또한 연구에서는 1B 모델이 5K 시퀀스 길이의 주요 인스턴스에서 미세 조정되어 1M 길이 문제를 해결했음을 발견했습니다. 마지막으로, 논문에서는 Infini-attention을 적용한 8B 모델이 지속적인 사전 학습 및 작업 미세 조정을 거쳐 500K 길이의 책 요약 작업에서 새로운 SOTA 결과를 달성했음을 보여줍니다.
- 장기 압축 메모리와 로컬 인과 주의를 효과적으로 사용하는 Infini-attention을 도입합니다. 장기 및 단기 컨텍스트 종속성을 모델링합니다.
- Infini-attention은 표준 확장 내적 관심을 최소한으로 변경하며 플러그 앤 플레이 연속 사전 학습 및 장기 컨텍스트 자가 학습을 지원하도록 설계되었습니다. 적응
- 이 방법을 사용하면 Transformer LLM이 스트림을 통해 매우 긴 입력을 처리하여 제한된 메모리와 컴퓨팅 리소스로 무한히 긴 컨텍스트로 확장할 수 있습니다. H 논문 링크: https://arxiv.org/pdf/2404.07143.pdf
논문 제목: Leave No Context Behind: Efficient Infinite Context Transformers with Infini-ATENTINTION
Infini-attention을 사용하면 Transformer LLM이 제한된 메모리 공간과 계산으로 무한히 긴 입력을 효율적으로 처리할 수 있습니다. 아래 그림 1에서 볼 수 있듯이 Infini-attention은 압축된 메모리를 일반 Attention 메커니즘에 통합하고 단일 Transformer 블록에 Masked Local Attention 및 장기 선형 Attention 메커니즘을 구축합니다. Transformer 주의 계층에 대한 이 미묘하지만 중요한 수정은 지속적인 사전 훈련과 미세 조정을 통해 기존 LLM의 컨텍스트 창을 무한한 길이로 확장할 수 있습니다.
Infini-attention은 장기 메모리 통합 및 검색을 위해 표준 어텐션 계산의 모든 키, 값 및 쿼리 상태를 가져오고 대신 이전 KV 어텐션 상태를 압축 메모리에 저장합니다. 표준 어텐션 메커니즘처럼 폐기합니다.후속 시퀀스를 처리할 때 Infini-attention은 Attention 쿼리 상태를 사용하여 메모리에서 값을 검색합니다. 최종 컨텍스트 출력을 계산하기 위해 Infini-attention은 장기 메모리 검색 값과 로컬 어텐션 컨텍스트를 집계합니다.
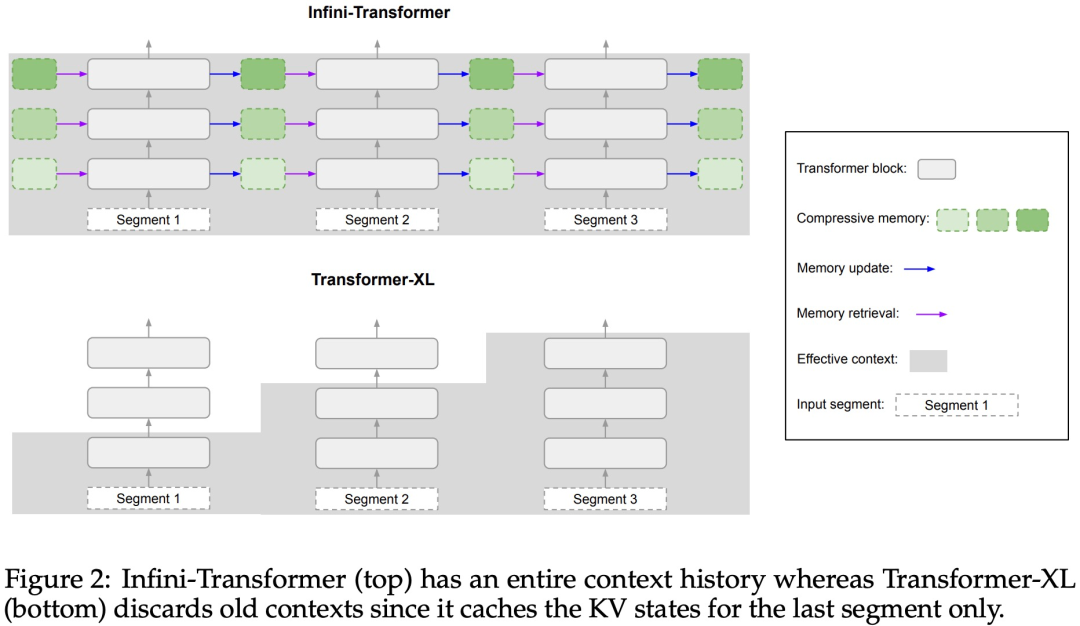
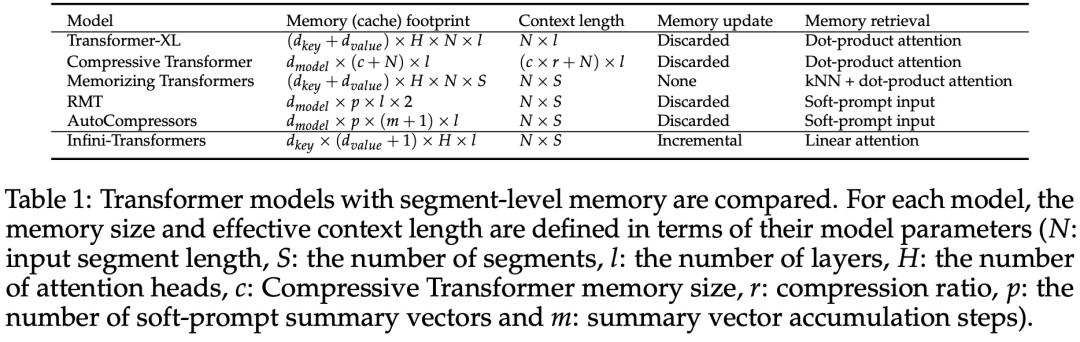
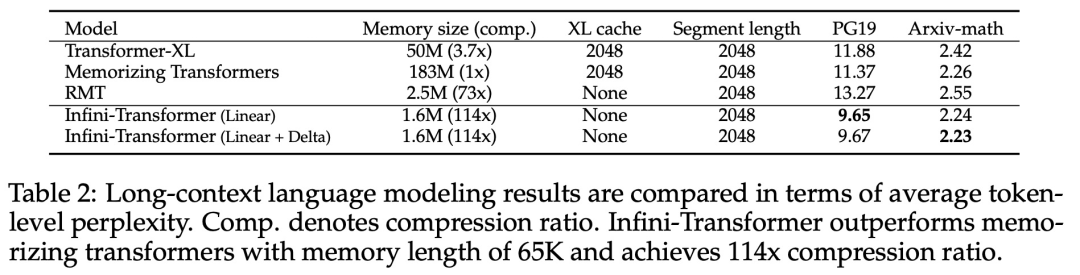
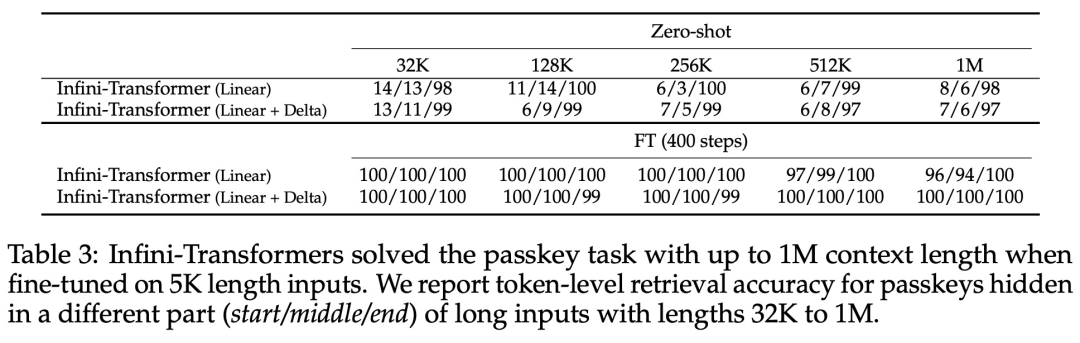
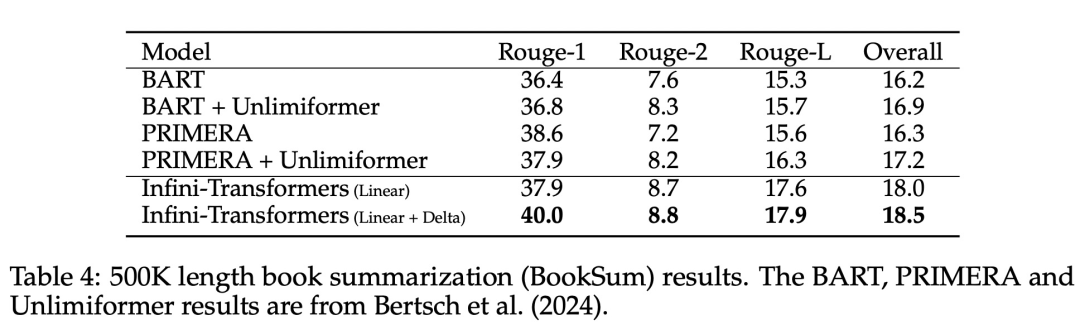
아래 그림 2와 같이 연구팀은 Infini-attention을 기반으로 Infini-Transformer와 Transformer-XL을 비교했습니다. Transformer-XL과 유사하게 Infini-Transformer는 일련의 세그먼트에서 작동하고 각 세그먼트에서 표준 인과 내적 주의 컨텍스트를 계산합니다. 따라서 내적 주의 계산은 어떤 의미에서는 지역적입니다. 그러나 로컬 어텐션은 다음 세그먼트 처리 시 이전 세그먼트의 어텐션 상태를 폐기하지만, Infini-Transformer는 이전 KV 어텐션 상태를 재사용하여 압축 저장을 통해 전체 컨텍스트 히스토리를 유지합니다. 따라서 Infini-Transformer의 각 Attention 레이어는 전역 압축 상태와 로컬 세분화 상태를 갖습니다. 다중 헤드 어텐션(MHA)과 유사하게 내적 어텐션 외에도 Infini-attention은 각 어텐션 레이어에 대해 H개의 병렬 압축 메모리를 유지합니다(H는 어텐션 헤드의 수). 아래 표 1에는 모델 매개변수와 입력 세그먼트 길이를 기반으로 여러 모델에서 정의한 컨텍스트 메모리 공간과 유효 컨텍스트 길이가 나열되어 있습니다. Infini-Transformer는 제한된 메모리 공간으로 무한한 컨텍스트 창을 지원합니다. 이 연구에서는 긴 입력 시퀀스가 매우 긴 긴 컨텍스트 언어 모델링, 1M 길이의 키 컨텍스트 블록 검색 및 500K 길이의 책 요약 작업에 대한 Infini-Transformer 모델을 평가했습니다. 언어 모델링의 경우 연구원들은 모델을 처음부터 훈련하기로 결정했으며 핵심 및 책 요약 작업의 경우 연구원들은 LLM의 지속적인 사전 훈련을 사용하여 Infini-attention의 플러그 앤 플레이 장기 컨텍스트 적응성을 입증했습니다. 긴 컨텍스트 언어 모델링. 표 2 결과는 Infini-Transformer가 Transformer-XL 및 Memorizing Transformers 기준보다 성능이 뛰어나며 Memorizing Transformer 모델에 비해 114배 더 적은 매개변수를 저장한다는 것을 보여줍니다. 핵심 임무. 표 3은 5K 길이 입력으로 미세 조정되어 최대 1M 컨텍스트 길이까지 핵심 작업을 해결하는 Infini-Transformer를 보여줍니다. 실험에서 입력 토큰은 32K에서 1M 범위였습니다. 각 테스트 하위 집합에 대해 연구원은 키가 입력 시퀀스의 시작, 중간 또는 끝 근처에 위치하도록 제어했습니다. 실험에서는 제로샷 정확도와 미세 조정 정확도가 보고되었습니다. 5K 길이 입력에 대해 400단계의 미세 조정을 거친 후 Infini-Transformer는 최대 1M 컨텍스트 길이의 작업을 해결합니다. 요약 작업. 표 4는 요약 작업을 위해 특별히 제작된 인코더-디코더 모델과 Infini-Transformer를 비교합니다. 결과는 Infini-Transformer가 이전 최고 결과를 뛰어넘고 책 전체 텍스트를 처리하여 BookSum에서 새로운 SOTA를 달성한 것으로 나타났습니다. 연구원들은 또한 그림 4에 BookSum 데이터 검증 분할의 전체 Rouge 점수를 표시했습니다. 폴리라인 추세는 Infini-Transformer가 입력 길이가 증가함에 따라 요약 성능 메트릭을 향상시키는 것을 보여줍니다.
위 내용은 무한 길이로 직접 확장되는 Google Infini-Transformer는 컨텍스트 길이 논쟁을 종식시킵니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!