
GPT-4와 공동 1위를 차지한 LMSYS 벤치마크에서는 Claude-3 모델이 좋은 성능을 발휘하는 것으로 나타났습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-03-28 17:26:43576검색

3월 28일 뉴스에 따르면 LMSYS Org가 발표한 최신 벤치마크 보고서에 따르면 Claude-3는 GPT-4를 간신히 능가하며 플랫폼에서 "최고의" 대형 언어 모델이 되었습니다.
이 웹사이트에서는 캘리포니아대학교 버클리캠퍼스, 캘리포니아대학교 샌디에고캠퍼스, 카네기멜론대학교가 공동으로 설립한 연구기관인 LMSYS Org를 먼저 소개합니다.
이 시스템은 크라우드 소싱을 사용하여 대형 모델 제품을 익명으로 무작위로 테스트하는 LLM(대형 언어 모델)용 벤치마크 플랫폼인 Chatbot Arena를 출시합니다. 등급은 체스와 같은 경쟁 게임에서 널리 사용되는 Elo 점수 시스템을 기반으로 합니다.
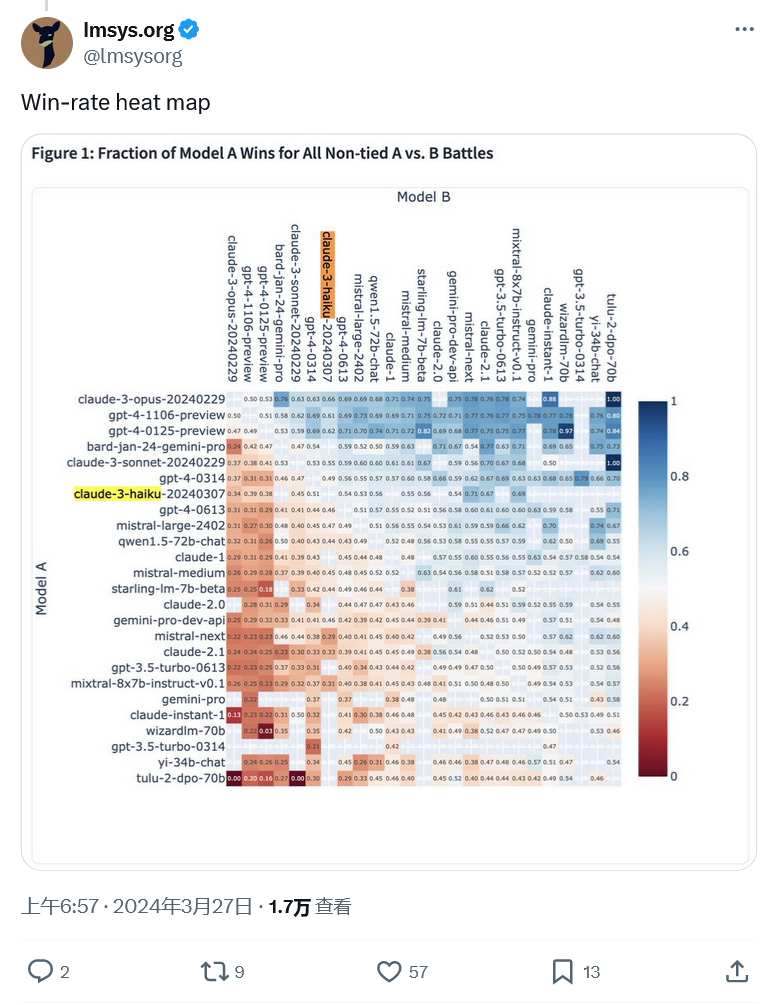
사용자 투표를 통해 생성된 평가 결과를 통해 시스템은 두 대의 대형 모델 로봇을 무작위로 선택하여 매번 사용자와 채팅하고, 사용자는 전체적으로 상대적으로 더 나은 성능을 보이는 대형 모델 제품을 익명으로 선택할 수 있습니다.
챗봇 아레나 GPT-4는 지난해 출시 이후 확고한 1위 자리를 지키며 대형 모델 평가의 기준이 되기도 했습니다.
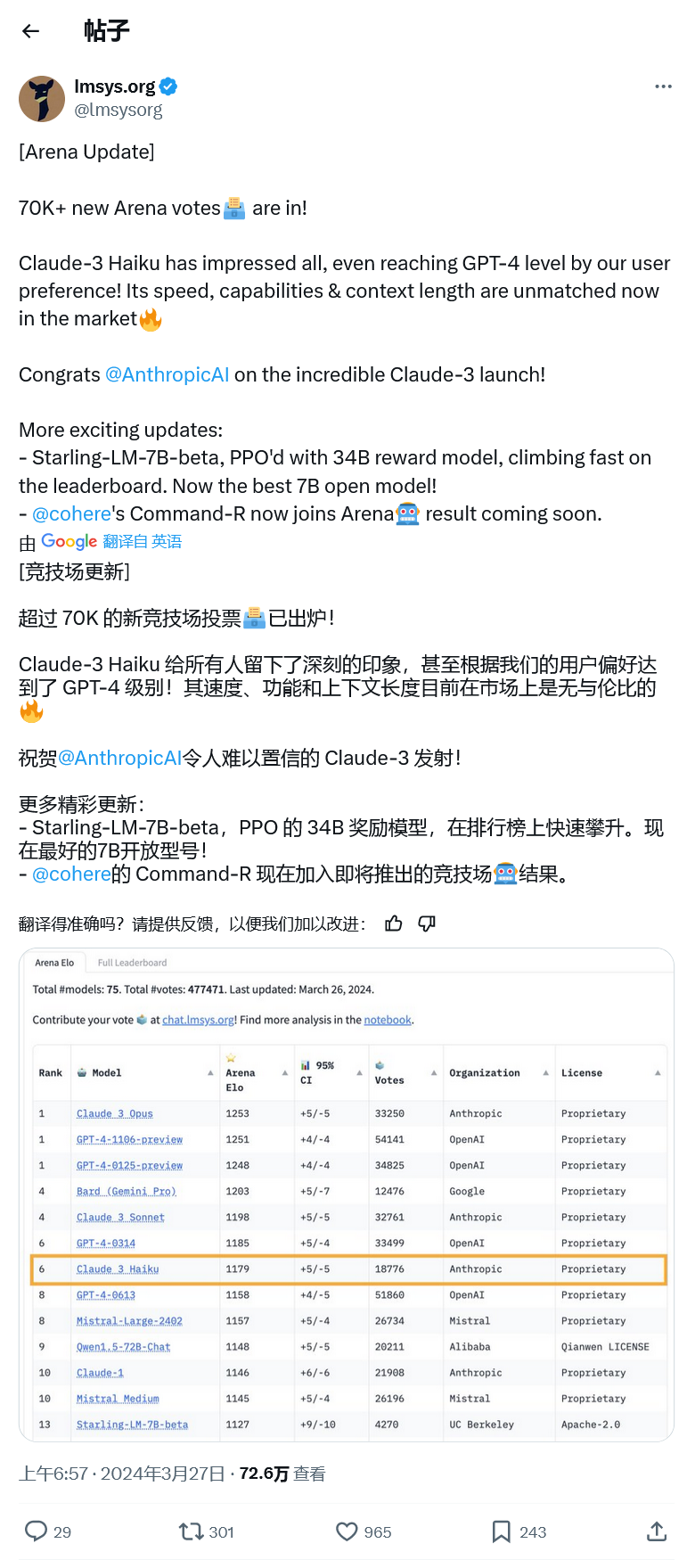
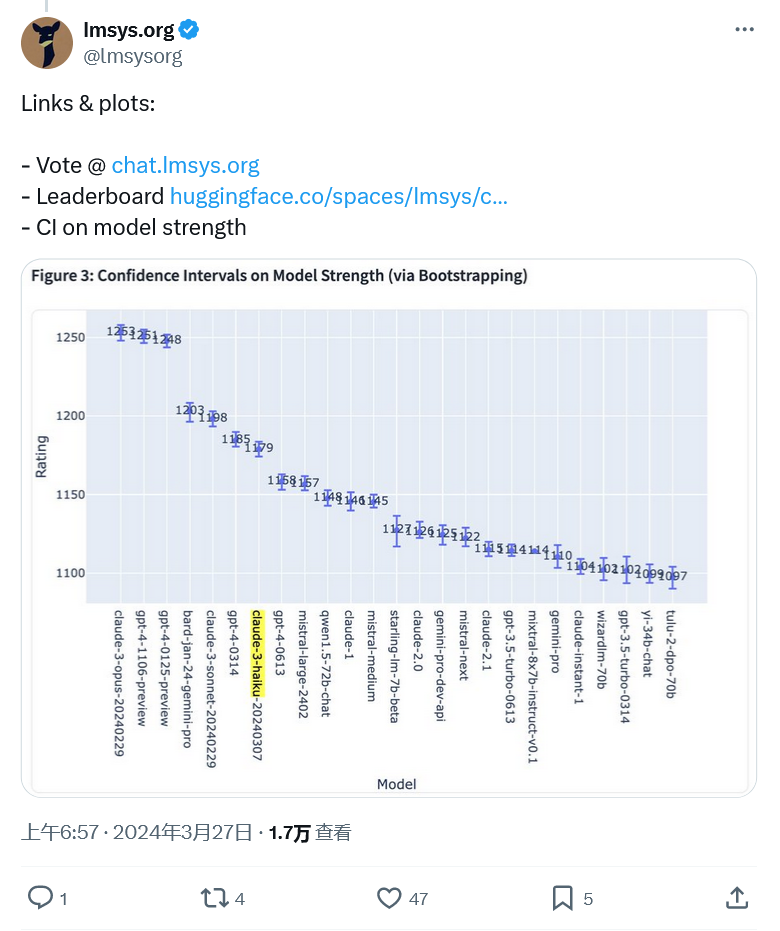
그러나 어제 Anthropic의 Claude 3 Opus가 GPT-4를 1253대 1251의 근소한 차이로 이겼고, OpenAI의 LLM이 1위 자리에서 밀려났습니다. 점수가 너무 가까워서 기관에서는 오류율 고려 사항으로 인해 Claude 3와 GPT-4를 공동 1위로 두었고, GPT-4의 또 다른 미리보기 버전도 공동 1위를 차지했습니다.
위 내용은 GPT-4와 공동 1위를 차지한 LMSYS 벤치마크에서는 Claude-3 모델이 좋은 성능을 발휘하는 것으로 나타났습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!