
CMU Zhu Junyan과 Adobe의 새로운 작업: 512x512 이미지 추론, A100은 0.11초만 소요

- PHPz앞으로
- 2024-03-21 16:31:25874검색
CMU와 Adobe가 공동으로 진행한 연구를 통해 간단한 스케치를 한 번의 클릭으로 다양한 스타일의 그림으로 변환하고 추가 설명을 추가할 수 있습니다.
CMU 조교수 Junyan Zhu는 연구의 저자이며 그의 팀은 ICCV 2021 컨퍼런스에서 관련 연구를 발표했습니다. 이 연구는 기존 GAN 모델을 하나 또는 몇 개의 손으로 그린 스케치로 사용자 정의하여 스케치와 일치하는 이미지를 생성하는 방법을 보여줍니다.

- 문서 주소: https://arxiv.org/pdf/2403.12036.pdf
- GitHub 주소: https://github.com/GaParmar/img2img-turbo
- 시험 주소: https://huggingface.co/spaces/gparmar/img2img-turbo-sketch
- 논문 제목: One-Step Image Translation with Text-to-Image Models
효과는 어때요? 우리는 그것을 시험해보고 그것이 매우 플레이 가능하다는 결론에 도달했습니다. 출력 이미지 스타일은 영화 스타일, 3D 모델, 애니메이션, 디지털 아트, 사진 스타일, 픽셀 아트, 판타지 스쿨, 네온 펑크, 만화 등 다양합니다.
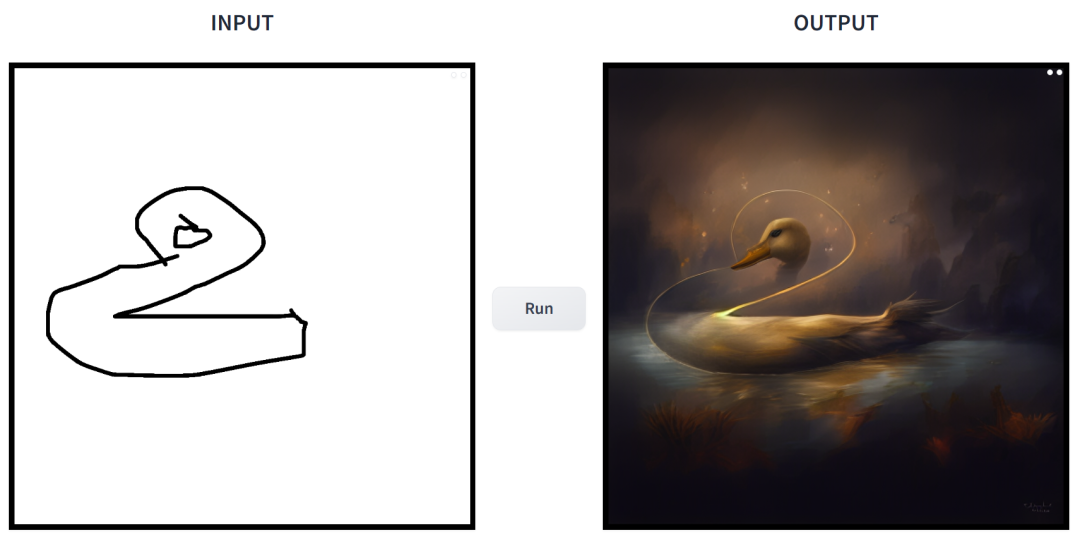
프롬프트는 "오리"입니다.
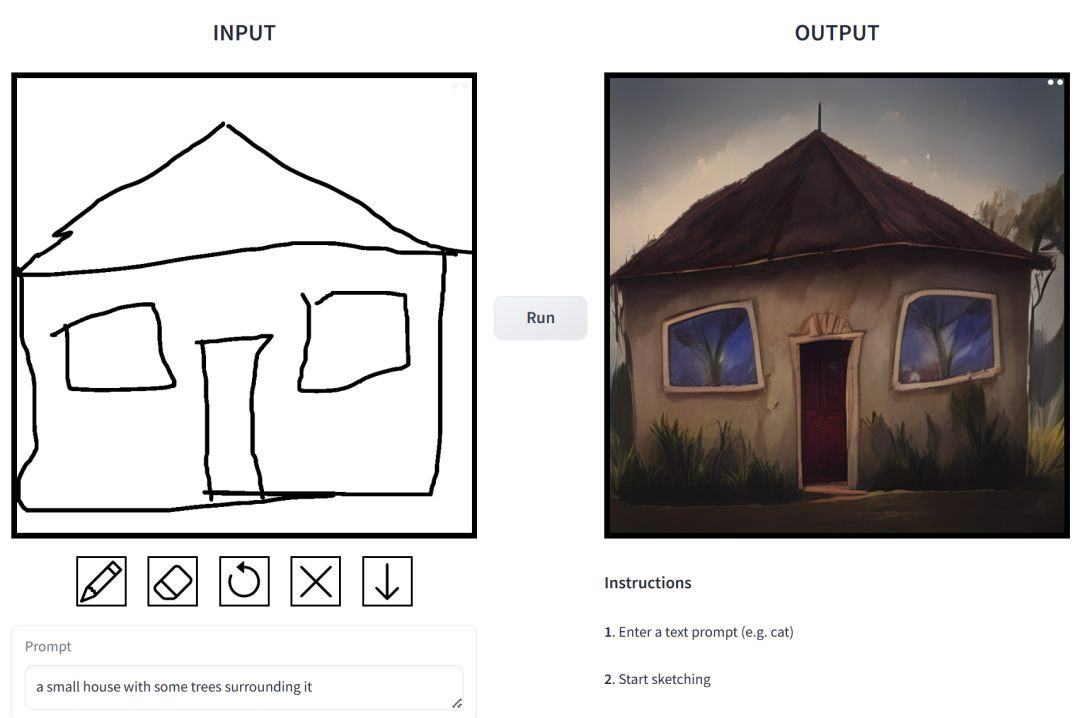
프롬프트는 "식물로 둘러싸인 작은 집"입니다.
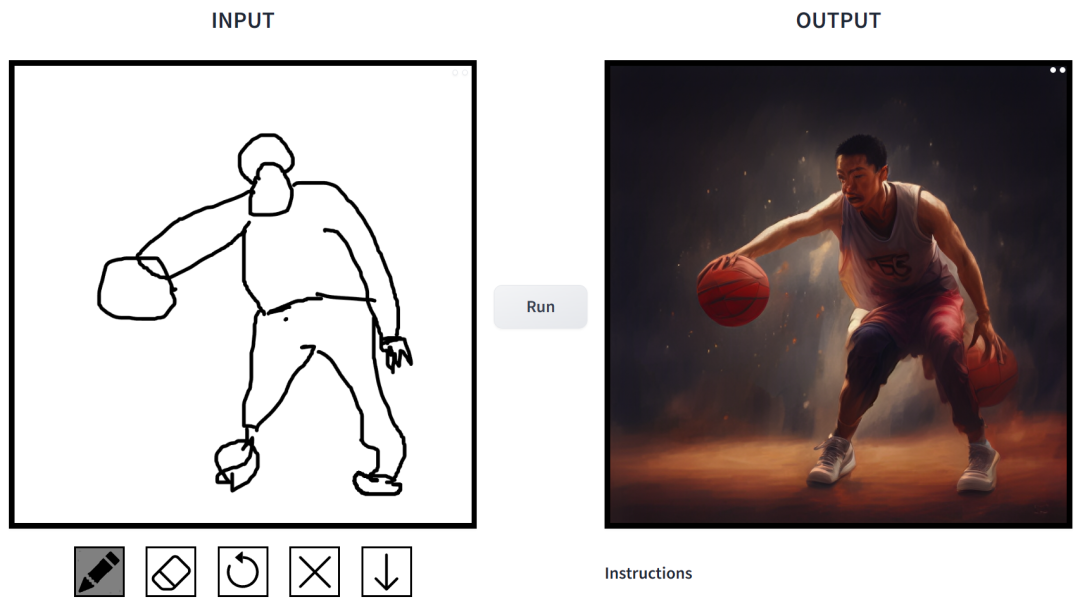
프롬프트는 "농구하는 중국 소년들"입니다.
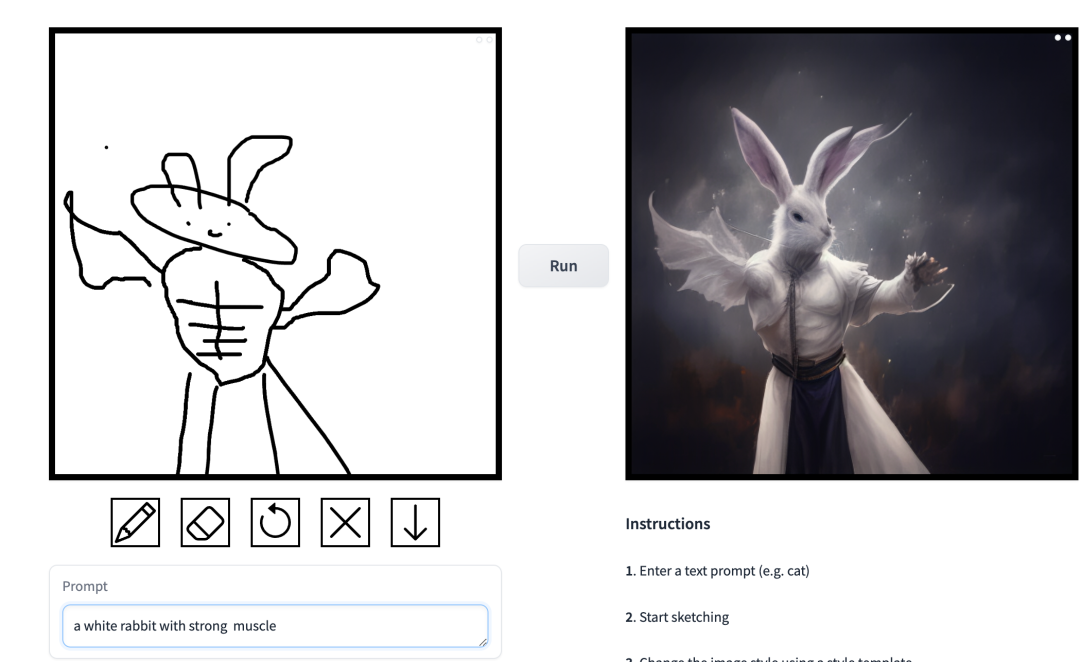
프롬프트는 "근육맨 토끼"입니다. 이 연구에서 연구원들은 이미지 합성 애플리케이션의 조건부 확산 모델에 존재하는 문제를 목표로 개선했습니다. 이러한 모델을 통해 사용자는 공간 조건과 텍스트 프롬프트를 기반으로 이미지를 생성하고 장면 레이아웃, 사용자 스케치 및 인간 포즈를 정밀하게 제어할 수 있습니다.
그러나 문제는 확산 모델의 반복으로 인해 추론 속도가 느려지고 대화형 Sketch2Photo와 같은 실시간 응용 프로그램이 제한된다는 것입니다. 또한 모델 교육에는 일반적으로 대규모 쌍을 이루는 데이터 세트가 필요하므로 많은 애플리케이션에 막대한 비용이 발생하고 일부 다른 애플리케이션에서는 실현 가능하지 않습니다. 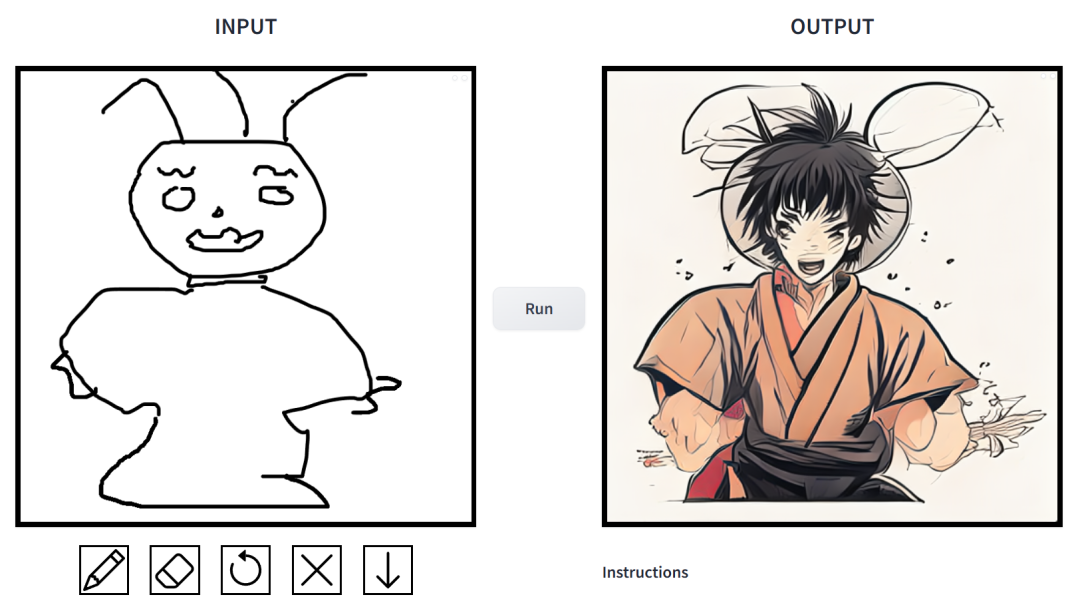
조건부 확산 모델의 문제를 해결하기 위해 연구자들은 적대적 학습 목표를 사용하여 단일 단계 확산 모델을 새로운 작업과 새로운 분야에 적용하는 일반적인 방법을 도입했습니다. 구체적으로, 바닐라 잠재 확산 모델의 개별 모듈을 훈련 가능한 작은 가중치를 갖는 단일 엔드 투 엔드 생성기 네트워크에 통합하여 과적합을 줄이면서 입력 이미지의 구조를 보존하는 모델의 능력을 향상시킵니다.
연구원들이 CycleGAN-Turbo 모델을 출시했습니다. 이 모델은 페어링되지 않은 설정에서 주야간 변환, 안개와 눈 추가 또는 제거 비 및 기타 날씨와 같은 다양한 장면 변환 작업에서 기존 GAN 및 확산 기반 방법보다 성능이 뛰어납니다. 효과. 
동시에 연구원들은 자체 아키텍처의 다양성을 검증하기 위해 쌍을 이루는 설정에 대한 실험을 수행했습니다. 결과는 해당 모델 pix2pix-Turbo가 Edge2Image 및 Sketch2Photo에 필적하는 시각적 효과를 달성하고 추론 단계를 1단계로 줄인다는 것을 보여줍니다.
요약하자면, 이 작업은 사전 훈련된 1단계 텍스트-이미지 모델이 많은 다운스트림 이미지 생성 작업을 위한 강력하고 다양한 백본 역할을 할 수 있음을 보여줍니다.
방법 소개
본 연구에서는 적대적 학습을 통해 단일 단계 확산 모델(예: SD-Turbo)을 새로운 작업과 도메인에 적용하는 일반적인 방법을 제안합니다. 이는 사전 훈련된 확산 모델의 내부 지식을 활용하는 동시에 효율적인 추론을 가능하게 합니다(예: 512x512 이미지의 경우 A6000에서 0.29초, A100에서 0.11초).
또한 단일 단계 조건부 모델인 CycleGAN-Turbo 및 pix2pix-Turbo는 pairwise 및 non-pairwise 설정 모두에 적합한 다양한 이미지-이미지 변환 작업을 수행할 수 있습니다. CycleGAN-Turbo는 기존 GAN 기반 및 확산 기반 방법을 능가하는 반면, pix2pix-Turbo는 Sketch2Photo 및 Edge2Image용 ControlNet과 같은 최근 작업과 동등하지만 단일 단계 추론의 장점이 있습니다.
조건부 입력 추가
텍스트-이미지 모델을 이미지-이미지 모델로 변환하기 위해 가장 먼저 해야 할 일은 입력 이미지 x를 통합하는 효율적인 방법을 찾는 것입니다. 모델에.
조건부 입력을 확산 모델에 통합하기 위한 일반적인 전략은 그림 3과 같이 추가 어댑터 분기를 도입하는 것입니다.
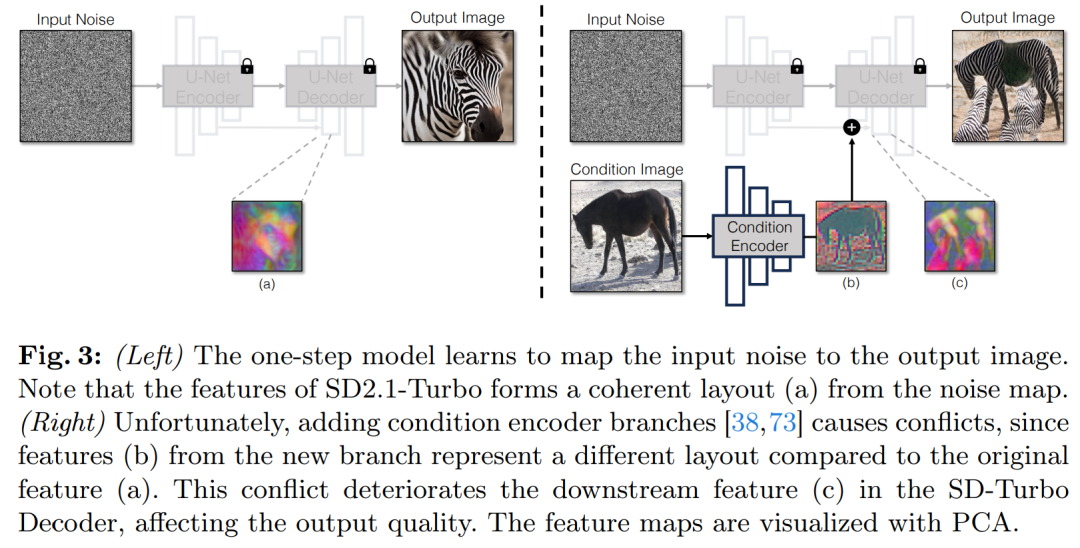
구체적으로, 본 연구에서는 두 번째 인코더를 초기화하고 이를 조건 인코더로 라벨링합니다. Control Encoder는 입력 이미지 x를 받아들이고 잔여 연결을 통해 사전 훈련된 Stable Diffusion 모델에 대한 여러 해상도의 특징 맵을 출력합니다. 이 방법은 확산 모델 제어에 있어 놀라운 결과를 달성합니다.
그림 3에서 볼 수 있듯이 이 연구에서는 단일 단계 모델에서 두 개의 인코더(U-Net 인코더와 조건부 인코더)를 사용하여 잡음이 있는 이미지와 입력 이미지에서 발생하는 문제를 처리합니다. 다단계 확산 모델과 달리 단일 단계 모델의 노이즈 맵은 생성된 이미지의 레이아웃과 포즈를 직접 제어하는데, 이는 종종 입력 이미지의 구조와 모순됩니다. 따라서 디코더는 서로 다른 구조를 나타내는 두 개의 잔차 특징 세트를 수신하므로 훈련 과정이 더욱 어려워집니다.
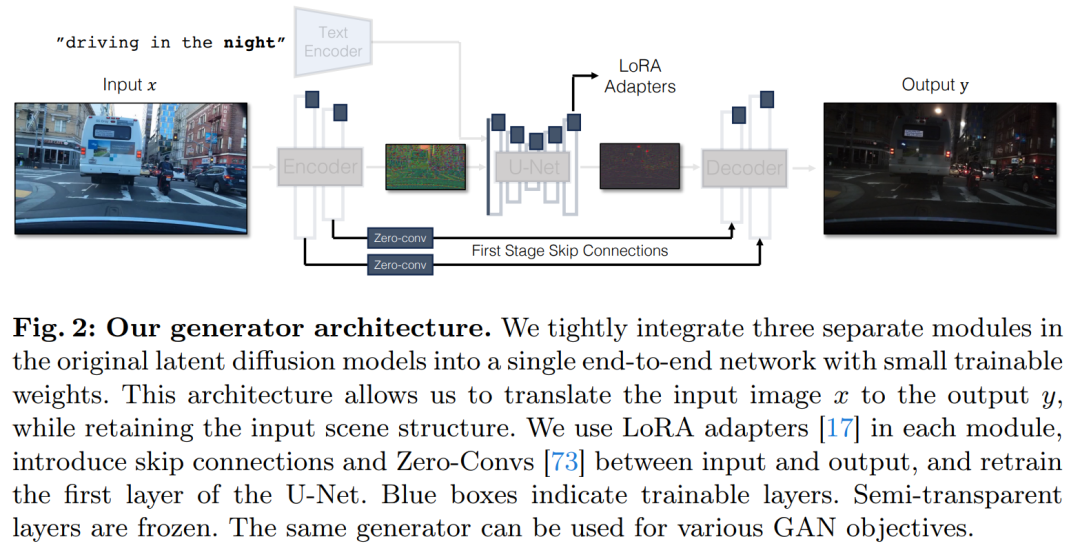
직접 조건부 입력. 그림 3은 또한 사전 훈련된 모델에 의해 생성된 이미지 구조가 노이즈 맵 z에 의해 크게 영향을 받는다는 것을 보여줍니다. 이 통찰력을 바탕으로 연구에서는 조건부 입력을 네트워크에 직접 공급할 것을 권장합니다. 백본 모델을 새로운 조건에 적응시키기 위해 연구에서는 U-Net의 다양한 레이어에 여러 LoRA 가중치를 추가했습니다(그림 2 참조).
입력 세부 정보 보존
잠재 확산 모델(LDM)용 이미지 인코더는 입력 이미지의 공간 해상도를 8배로 압축하는 동시에 채널 수를 늘려 확산 모델 학습을 가속화합니다. 3~4. 추론 과정. 이 설계는 훈련 및 추론 속도를 높일 수 있지만 입력 이미지의 세부 정보를 보존해야 하는 이미지 변환 작업에는 적합하지 않을 수 있습니다. 그림 4는 이 문제를 보여줍니다. 여기서는 주간 운전의 입력 이미지(왼쪽)를 가져와 스킵 연결을 사용하지 않는 아키텍처(가운데)를 사용하여 이를 야간 운전의 해당 이미지로 변환합니다. 텍스트, 거리 표지판, 멀리 있는 자동차 등 세밀한 세부 정보가 보존되지 않는 것을 볼 수 있습니다. 대조적으로, 건너뛰기 연결을 포함하는 아키텍처를 사용하여 변환된 결과 이미지(오른쪽)는 이러한 복잡한 세부 사항을 더 잘 보존합니다.

입력 이미지의 세밀한 시각적 세부 정보를 캡처하기 위해 연구에서는 인코더와 디코더 네트워크 사이에 스킵 연결을 추가했습니다(그림 2 참조). 구체적으로, 이 연구는 인코더 내의 각 다운샘플링 블록 이후에 4개의 중간 활성화를 추출하고 이를 1×1 제로 컨벌루션 레이어를 통해 처리한 다음 이를 디코더의 해당 업샘플링 블록에 공급합니다. 이 접근 방식을 사용하면 이미지 변환 중에 복잡한 세부 정보가 보존됩니다.
실험
이 연구에서는 CycleGAN-Turbo를 이전 GAN 기반 비쌍별 이미지 변환 방법과 비교했습니다. 질적 분석에서 그림 5와 그림 6은 GAN 기반 방법이나 확산 기반 방법 모두 출력 이미지 현실성과 구조 유지 간의 균형을 달성할 수 없음을 보여줍니다.


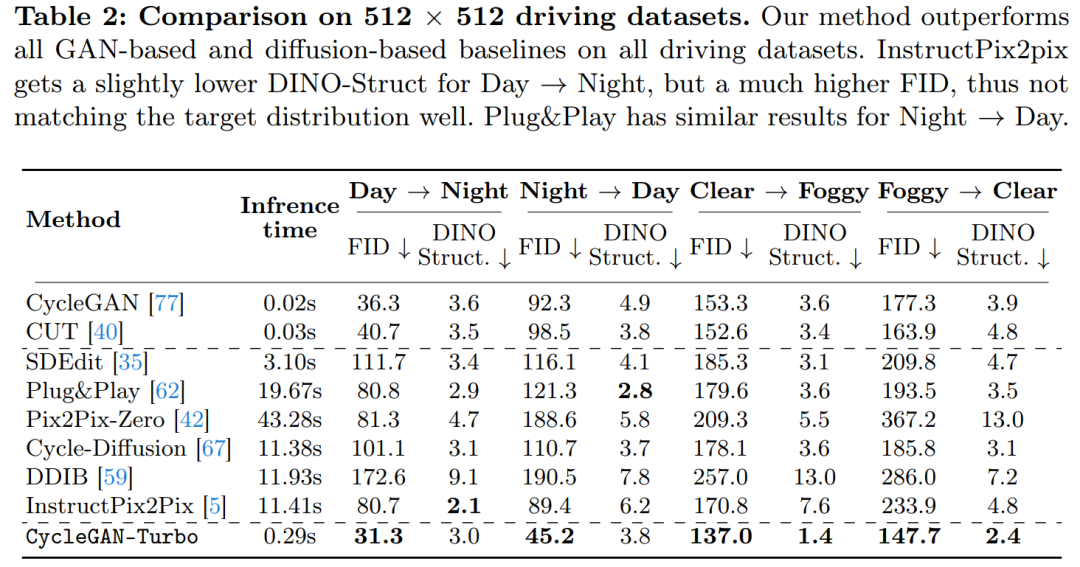
이 연구에서는 CycleGAN-Turbo를 CycleGAN 및 CUT과도 비교했습니다. 표 1과 2는 8개의 페어링되지 않은 스위칭 작업에 대한 정량적 비교 결과를 나타냅니다.
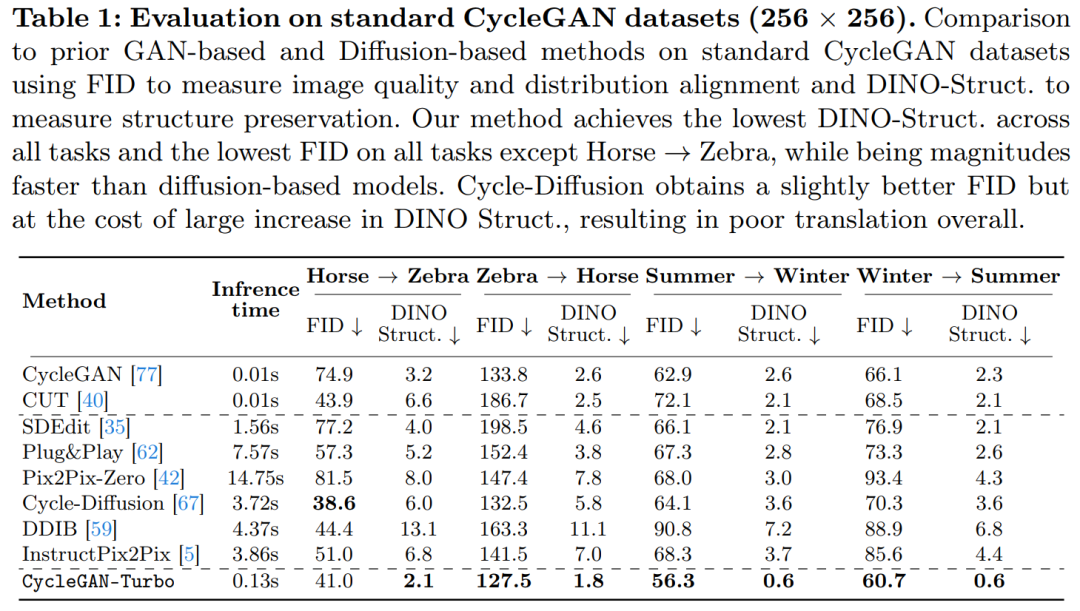
CycleGAN 및 CUT는 말 → 얼룩말(그림 13)과 같은 더 간단하고 객체 중심 데이터 세트에서 효과적인 성능을 보여 낮은 FID 및 DINO 구조 점수를 달성합니다. 우리의 방법은 FID 및 DINO-Structure 거리 측정법에서 이러한 방법보다 약간 성능이 뛰어납니다.

표 1과 그림 14에 표시된 것처럼 객체 중심 데이터세트(예: 말 → 얼룩말)에서 이러한 방법은 사실적인 얼룩말을 생성할 수 있지만 정확하게 일치하는 객체로 인해 어려움을 겪습니다.
운전 데이터 세트에서 이러한 편집 방법은 세 가지 이유로 인해 훨씬 더 나쁜 성능을 발휘합니다. (1) 모델이 여러 개체가 포함된 복잡한 장면을 생성하는 데 어려움이 있습니다. (2) 이러한 방법(Instruct-pix2pix 제외)은 먼저 이미지가 (3) 사전 훈련된 모델은 운전 데이터 세트에서 캡처한 것과 유사한 스트리트 뷰 이미지를 합성할 수 없습니다. 표 2와 그림 16은 네 가지 구동 전환 작업 모두에서 이러한 방법이 품질이 좋지 않은 이미지를 출력하고 입력 이미지의 구조를 따르지 않음을 보여줍니다.


위 내용은 CMU Zhu Junyan과 Adobe의 새로운 작업: 512x512 이미지 추론, A100은 0.11초만 소요의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!