


1.3ms는 1.3ms가 걸립니다! Tsinghua의 최신 오픈 소스 모바일 신경망 아키텍처 RepViT


문서 주소: https://arxiv.org/abs/2307.09283
코드 주소: https://github.com/THU-MIG/RepViT

RepViT 모바일 측면 ViT 아키텍처의 탁월한 성능으로 상당한 이점을 보여줍니다. 다음으로, 본 연구의 기여를 살펴보겠습니다.
- 기사에서는 주로 다중 헤드 self-attention 모듈로 인해 시각적 작업에서 가벼운 ViT가 가벼운 CNN보다 일반적으로 더 나은 성능을 발휘한다고 언급합니다(
MSHA) 표현. 그러나 경량 ViT와 경량 CNN 간의 아키텍처 차이점은 완전히 연구되지 않았습니다. - 在这项研究中,作者们通过整合轻量级 ViTs 的有效架构选择,逐步提升了标准轻量级 CNN(特别是
MobileNetV3的移动友好性。这便衍生出一个新的纯轻量级 CNN 家族的诞生,即RepViT。值得注意的是,尽管 RepViT 具有 MetaFormer 结构,但它完全由卷积组成。 - 实验结果表明,
RepViT超越了现有的最先进的轻量级 ViTs,并在各种视觉任务上显示出优于现有最先进轻量级ViTs的性能和效率,包括 ImageNet 分类、COCO-2017 上的目标检测和实例分割,以及 ADE20k 上的语义分割。特别地,在ImageNet上,RepViT在iPhone 12上达到了近乎 1ms 的延迟和超过 80% 的Top-1 准确率,这是轻量级模型的首次突破。
MSHA)可以让模型学习全局表示。然而,轻量级 ViTs 和轻量级 CNNs 之间的架构差异尚未得到充分研究。好了,接下来大家应该关心的应该时“如何设计到如此低延迟但精度还很6的模型”出来呢?
方法
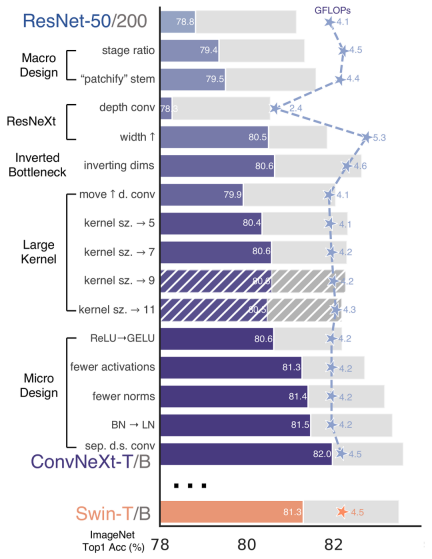
再 ConvNeXt 中,作者们是基于 ResNet50 架构的基础上通过严谨的理论和实验分析,最终设计出一个非常优异的足以媲美 Swin-Transformer 的纯卷积神经网络架构。同样地,RepViT也是主要通过将轻量级 ViTs 的架构设计逐步整合到标准轻量级 CNN,即MobileNetV3-L이 연구에서 저자는 표준 경량 CNN(특히 MobileNetV3의 모바일 친화성은 새로운 순수 경량 CNN 제품군의 탄생을 가져옵니다. 색상: rgb(231, 243, 237); 패딩: 1px 3px; border-radius: 4px; break-word; text-indent: 0px; 디스플레이: inline-block; RepViT는 MetaFormer 구조를 가지고 있지만 전체적으로 컨볼루션으로 구성되어 있다는 점은 주목할 가치가 있습니다.
RepViT 기존의 최첨단 경량 ViT를 능가하며 뛰어난 성능을 보여줍니다. ImageNet 분류, COCO-2017 객체 감지 및 인스턴스 분할, ADE20k의 의미론적 분할을 포함한 다양한 비전 작업에서 기존의 최첨단 경량 ViT에 비해 효율성이 높습니다. 특히 RepViT 코드> iPhone 12는 거의 1ms에 달하는 지연 시간과 80% 이상의 Top-1 정확도를 달성했는데, 이는 경량 모델로서는 최초로 획기적인 성과입니다. 🎜자, 모두가 다음으로 고민해야 할 것은 "이렇게 낮은 지연 시간과 높은 정확도를 갖는 모델을 설계하는 방법"입니까? 🎜방법
🎜🎜🎜again ConvNeXt, 작성자는 ResNet50 엄격한 이론과 실험을 통해, 우리는 마침내 Swin-Transformer의 순수 컨볼루션 신경망 아키텍처. 마찬가지로, RepViT는 또한 경량 ViT의 아키텍처 설계를 표준 경량 CNN, 즉 MobileNetV3-L, 대상 변환(마법 수정)을 수행합니다. 이 과정에서 저자는 다양한 수준의 세분성에서 디자인 요소를 고려하고 일련의 단계를 통해 최적화 목표를 달성했습니다. 🎜
훈련 레시피 정렬
문서에서는 모바일 장치의 대기 시간을 측정하고 훈련 전략이 현재 인기 있는 경량 ViT와 일치하는지 확인하기 위한 새로운 측정항목이 도입되었습니다. 이 이니셔티브의 목적은 지연 측정과 훈련 전략 조정이라는 두 가지 주요 개념을 포함하는 모델 훈련의 일관성을 보장하는 것입니다.
Latency Metric
실제 모바일 디바이스에서 모델의 성능을 보다 정확하게 측정하기 위해 저자는 디바이스에서 모델의 실제 레이턴시를 기준 메트릭으로 직접 측정하기로 결정했습니다. 이 측정 방법은 FLOP 또는 모델 크기와 같은 측정항목은 모델의 추론 속도를 최적화하며 이러한 측정항목은 항상 모바일 애플리케이션의 실제 대기 시간을 잘 반영하지 않습니다. FLOPs或模型大小等指标优化模型的推理速度,这些指标并不总能很好地反映在移动应用中的实际延迟。
训练策略的对齐
这里,将 MobileNetV3-L 的训练策略调整以与其他轻量级 ViTs 模型对齐。这包括使用 AdamW 优化器【ViTs 模型必备的优化器】,进行 5 个 epoch 的预热训练,以及使用余弦退火学习率调度进行 300 个 epoch 的训练。尽管这种调整导致了模型准确率的略微下降,但可以保证公平性。
块设计的优化
接下来,基于一致的训练设置,作者们探索了最优的块设计。块设计是 CNN 架构中的一个重要组成部分,优化块设计有助于提高网络的性能。
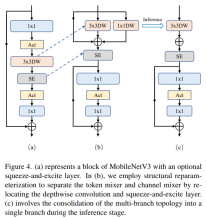
分离 Token 混合器和通道混合器
这块主要是对 MobileNetV3-L훈련 전략 정렬
여기서 MobileNetV3-L의 훈련 전략은 다른 경량 ViTs 모델과 일치하도록 조정됩니다. 여기에는 AdamW 최적화 도구 [ViTs 모델의 필수 최적화 도구]는 5개의 에포크 워밍업 훈련을 수행하고 300개의 에포크 훈련에 대해 코사인 어닐링 학습 속도 스케줄링을 사용합니다. 이러한 조정으로 인해 모델 정확도가 약간 감소하지만 공정성은 보장됩니다.
별도의 토큰 믹서와 채널 믹서
이 부분은 주로MobileNetV3-L의 블록 구조가 토큰 믹서와 채널 믹서를 분리하도록 개선되었습니다. 원래 MobileNetV3 블록 구조는 1x1 확장 컨볼루션, 깊이별 컨볼루션 및 1x1 프로젝션 레이어로 구성되며, 잔차 연결을 통해 입력과 출력을 연결합니다. 이를 기반으로 RepViT는 채널 믹서와 토큰 믹서가 분리될 수 있도록 깊이 컨볼루션을 진행합니다. 성능을 향상시키기 위해 훈련 중 심층 필터를 위한 다중 분기 토폴로지를 도입하는 구조적 재매개변수화 도 도입되었습니다. 마지막으로 저자는 MobileNetV3 블록에서 토큰 믹서와 채널 믹서를 분리하는 데 성공하고 이러한 블록을 RepViT 블록으로 명명했습니다.
도 도입되었습니다. 마지막으로 저자는 MobileNetV3 블록에서 토큰 믹서와 채널 믹서를 분리하는 데 성공하고 이러한 블록을 RepViT 블록으로 명명했습니다.
ViTs는 일반적으로 입력 이미지를 줄기처럼 겹치지 않는 패치로 분할하는 "패치화" 작업을 사용합니다. 그러나 이 접근 방식은 훈련 최적화와 훈련 레시피 민감도에 문제가 있습니다. 따라서 저자는 많은 경량 ViT에서 채택한 접근 방식인 초기 컨볼루션을 대신 채택했습니다. 이와 대조적으로 MobileNetV3-L은 4배 다운샘플링을 위해 더 복잡한 스템을 사용합니다. 그 결과, 초기 필터 수는 24개로 늘어났지만 전체 지연 시간은 0.86ms로 감소하고, 상위 1개 정확도는 73.9%로 증가했다.
더 깊은 다운샘플링 레이어
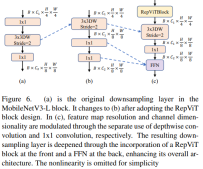
ViT에서 공간 다운샘플링은 일반적으로 별도의 패치 병합 레이어를 통해 구현됩니다. 따라서 여기서는 네트워크 깊이를 늘리고 해상도 감소로 인한 정보 손실을 줄이기 위해 별도의 더 깊은 다운샘플링 레이어를 채택할 수 있습니다. 구체적으로, 저자는 먼저 1x1 컨볼루션을 사용하여 채널 크기를 조정한 다음 잔차를 통해 두 개의 1x1 컨볼루션의 입력과 출력을 연결하여 피드포워드 네트워크를 형성했습니다. 또한 다운샘플링 레이어를 더욱 심화시키기 위해 앞에 RepViT 블록을 추가했는데, 이는 0.96ms의 대기 시간으로 상위 1 정확도를 75.4%로 향상시키는 단계였습니다.
간단한 분류기
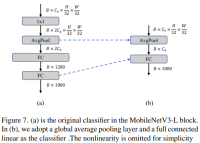
경량 ViT에서 분류기는 일반적으로 전역 평균 풀링 레이어와 선형 레이어로 구성됩니다. 이와 대조적으로 MobileNetV3-L은 더 복잡한 분류자를 사용합니다. 이제 최종 단계에 더 많은 채널이 있으므로 작성자는 이를 간단한 분류기, 전역 평균 풀링 레이어 및 선형 레이어로 대체했습니다. 이 단계는 상위 1위 정확도를 유지하면서 지연 시간을 0.77ms로 줄였습니다.
전체 스테이지 비율
스테이지 비율은 여러 스테이지의 블록 수 비율을 나타내며, 각 스테이지의 계산 분포를 나타냅니다. 논문에서는 보다 최적의 스테이지 비율인 1:1:7:1을 선택한 다음 네트워크 깊이를 2:2:14:2로 늘려 더 깊은 레이아웃을 구현합니다. 이 단계는 1.02ms의 대기 시간으로 상위 1 정확도를 76.9%로 증가시킵니다.
마이크로 설계 조정
다음으로 RepViT는 적절한 컨볼루션 커널 크기 선택 및 SE(압착 및 자극) 레이어 위치 최적화를 포함하는 레이어별 마이크로 디자인을 통해 경량 CNN을 조정합니다. 두 방법 모두 모델 성능을 크게 향상시킵니다.
컨볼루션 커널 크기 선택
CNN의 성능과 지연 시간은 일반적으로 컨볼루션 커널의 크기에 영향을 받는 것으로 알려져 있습니다. 예를 들어 MHSA와 같은 장거리 컨텍스트 종속성을 모델링하기 위해 ConvNeXt는 대규모 컨벌루션 커널을 사용하여 성능을 크게 향상시킵니다. 그러나 대규모 컨볼루션 커널은 계산 복잡성과 메모리 액세스 비용으로 인해 모바일 친화적이지 않습니다. MobileNetV3-L은 주로 3x3 컨볼루션을 사용하며 일부 블록에서는 5x5 컨볼루션을 사용합니다. 저자는 이를 3x3 컨볼루션으로 대체하여 76.9%의 상위 1 정확도를 유지하면서 지연 시간을 1.00ms로 줄였습니다.
SE 레이어의 위치
컨볼루션에 비해 self-attention 모듈의 한 가지 장점은 입력에 따라 가중치를 조정할 수 있다는 것인데, 이를 데이터 기반 속성이라고 합니다. 채널 주의 모듈로서 SE 계층은 데이터 기반 속성이 부족한 컨볼루션의 한계를 보완하여 더 나은 성능을 제공할 수 있습니다. MobileNetV3-L은 일부 블록에 SE 레이어를 추가하며 주로 마지막 두 단계에 중점을 둡니다. 그러나 저해상도 단계는 고해상도 단계보다 SE에서 제공하는 전역 평균 풀링 작업에서 더 작은 정확도 이득을 얻습니다. 저자는 가장 작은 지연 증분으로 정확도 향상을 극대화하기 위해 모든 단계에서 교차 블록 방식으로 SE 레이어를 사용하는 전략을 설계했습니다. 이 단계에서는 지연이 0.87ms로 감소하면서 top-1 정확도가 77.4%로 향상되었습니다. [사실 바이두는 이 점에 대해 이미 오래 전부터 실험과 비교를 해왔고 이런 결론에 이르렀습니다. SE 레이어는 딥 레이어에 가깝게 위치할 때 더 효과적입니다.]
Network Architecture
마지막으로 위의 개선 전략을 통합하여 모델RepViT的整体架构,该模型有多个变种,例如RepViT-M1/M2/M3을 얻습니다. 마찬가지로, 다양한 변형은 주로 스테이지당 채널 및 블록 수로 구별됩니다.
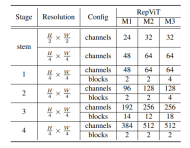
실험
이미지 분류

탐지 및 분할

요약
이 문서에서는 경량 ViT의 아키텍처 선택을 소개하여 경량 CNN의 효율적인 설계를 재검토합니다. 이로 인해 리소스가 제한된 모바일 장치를 위해 설계된 새로운 경량 CNN 제품군인 RepViT가 탄생했습니다. RepViT는 다양한 비전 작업에서 기존의 최첨단 경량 ViT 및 CNN보다 성능이 뛰어나며 뛰어난 성능과 대기 시간을 보여줍니다. 이는 모바일 장치를 위한 순수 경량 CNN의 잠재력을 강조합니다.
위 내용은 1.3ms는 1.3ms가 걸립니다! Tsinghua의 최신 오픈 소스 모바일 신경망 아키텍처 RepViT의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 요리 혁신 요리 : 인공 지능이 식품 서비스를 변화시키는 방법Apr 12, 2025 pm 12:09 PM
요리 혁신 요리 : 인공 지능이 식품 서비스를 변화시키는 방법Apr 12, 2025 pm 12:09 PMAI 식품 준비 여전히 초기 사용 중이지만 AI 시스템은 음식 준비에 점점 더 많이 사용되고 있습니다. AI 구동 로봇은 부엌에서 햄버거를 뒤집기, 피자 만들기 또는 SA 조립과 같은 음식 준비 작업을 자동화하는 데 사용됩니다
 파이썬 네임 스페이스 및 가변 범위에 대한 포괄적 인 안내서Apr 12, 2025 pm 12:00 PM
파이썬 네임 스페이스 및 가변 범위에 대한 포괄적 인 안내서Apr 12, 2025 pm 12:00 PM소개 파이썬 기능에서 변수의 네임 스페이스, 범위 및 동작을 이해하는 것은 효율적으로 작성하고 런타임 오류 또는 예외를 피하는 데 중요합니다. 이 기사에서는 다양한 ASP를 탐구 할 것입니다
 비전 언어 모델 (VLMS)에 대한 포괄적 인 안내서Apr 12, 2025 am 11:58 AM
비전 언어 모델 (VLMS)에 대한 포괄적 인 안내서Apr 12, 2025 am 11:58 AM소개 생생한 그림과 조각으로 둘러싸인 아트 갤러리를 걷는 것을 상상해보십시오. 이제 각 작품에 질문을하고 의미있는 대답을 얻을 수 있다면 어떨까요? “어떤 이야기를하고 있습니까?
 Mediatek은 Kompanio Ultra 및 Dimensity 9400으로 프리미엄 라인업을 향상시킵니다.Apr 12, 2025 am 11:52 AM
Mediatek은 Kompanio Ultra 및 Dimensity 9400으로 프리미엄 라인업을 향상시킵니다.Apr 12, 2025 am 11:52 AM제품 케이던스를 계속하면서 이번 달 Mediatek은 새로운 Kompanio Ultra and Dimensity 9400을 포함한 일련의 발표를했습니다. 이 제품은 스마트 폰 용 칩을 포함하여 Mediatek 비즈니스의 전통적인 부분을 채우고 있습니다.
 이번 주 AI : Walmart는 패션 트렌드를 설정하기 전에 패션 트렌드를 설정합니다.Apr 12, 2025 am 11:51 AM
이번 주 AI : Walmart는 패션 트렌드를 설정하기 전에 패션 트렌드를 설정합니다.Apr 12, 2025 am 11:51 AM#1 Google은 Agent2agent를 시작했습니다 이야기 : 월요일 아침입니다. AI 기반 채용 담당자로서 당신은 더 똑똑하지 않고 더 똑똑하지 않습니다. 휴대 전화에서 회사의 대시 보드에 로그인합니다. 세 가지 중요한 역할이 공급되고, 검증되며, 예정된 FO가 있음을 알려줍니다.
 생성 AI는 사이코브블을 만난다Apr 12, 2025 am 11:50 AM
생성 AI는 사이코브블을 만난다Apr 12, 2025 am 11:50 AM나는 당신이되어야한다고 생각합니다. 우리 모두는 Psychobabble이 다양한 심리적 용어를 혼합하고 종종 이해할 수 없거나 완전히 무의미한 모듬 채터로 구성되어 있다는 것을 알고 있습니다. 당신이 fo를 뿌리기 위해해야 할 일
 프로토 타입 : 과학자들은 종이를 플라스틱으로 바꿉니다Apr 12, 2025 am 11:49 AM
프로토 타입 : 과학자들은 종이를 플라스틱으로 바꿉니다Apr 12, 2025 am 11:49 AM이번 주 발표 된 새로운 연구에 따르면 2022 년에 제조 된 플라스틱의 9.5%만이 재활용 재료로 만들어졌습니다. 한편, 플라스틱은 계속해서 매립지와 생태계에 전 세계에 쌓이고 있습니다. 그러나 도움이 진행 중입니다. 엥인 팀
 AI 분석가의 부상 : AI 혁명에서 이것이 가장 중요한 일이 될 수있는 이유Apr 12, 2025 am 11:41 AM
AI 분석가의 부상 : AI 혁명에서 이것이 가장 중요한 일이 될 수있는 이유Apr 12, 2025 am 11:41 AM최근 Enterprise Analytics 플랫폼 Alteryx의 CEO 인 Andy MacMillan과의 대화는 AI 혁명 에서이 비판적이면서도 저평가 된 역할을 강조했습니다. MacMillan에서 설명했듯이 원시 비즈니스 데이터와 AI-Ready Informat의 격차


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

SublimeText3 Mac 버전
신 수준의 코드 편집 소프트웨어(SublimeText3)

DVWA
DVWA(Damn Vulnerable Web App)는 매우 취약한 PHP/MySQL 웹 애플리케이션입니다. 주요 목표는 보안 전문가가 법적 환경에서 자신의 기술과 도구를 테스트하고, 웹 개발자가 웹 응용 프로그램 보안 프로세스를 더 잘 이해할 수 있도록 돕고, 교사/학생이 교실 환경 웹 응용 프로그램에서 가르치고 배울 수 있도록 돕는 것입니다. 보안. DVWA의 목표는 다양한 난이도의 간단하고 간단한 인터페이스를 통해 가장 일반적인 웹 취약점 중 일부를 연습하는 것입니다. 이 소프트웨어는

SublimeText3 중국어 버전
중국어 버전, 사용하기 매우 쉽습니다.

mPDF
mPDF는 UTF-8로 인코딩된 HTML에서 PDF 파일을 생성할 수 있는 PHP 라이브러리입니다. 원저자인 Ian Back은 자신의 웹 사이트에서 "즉시" PDF 파일을 출력하고 다양한 언어를 처리하기 위해 mPDF를 작성했습니다. HTML2FPDF와 같은 원본 스크립트보다 유니코드 글꼴을 사용할 때 속도가 느리고 더 큰 파일을 생성하지만 CSS 스타일 등을 지원하고 많은 개선 사항이 있습니다. RTL(아랍어, 히브리어), CJK(중국어, 일본어, 한국어)를 포함한 거의 모든 언어를 지원합니다. 중첩된 블록 수준 요소(예: P, DIV)를 지원합니다.

에디트플러스 중국어 크랙 버전
작은 크기, 구문 강조, 코드 프롬프트 기능을 지원하지 않음

