Cassie라는 이름의 이 로봇은 한때 100미터 달리기에서 세계 기록을 세웠습니다. 최근 캘리포니아 대학교 버클리 연구진은 이를 위한 새로운 심층 강화 학습 알고리즘을 개발하여 급회전과 같은 기술을 익히고 다양한 간섭에 저항할 수 있게 했습니다.
 2족 보행 로봇에 대한 연구는 수십 년 동안 진행되어 왔지만 아직까지 아무 것도 수행하지 못했습니다. 다양한 이동 기술 강력한 제어를 위한 일반적인 프레임워크입니다. 문제는 이족 보행 로봇의 제대로 작동되지 않는 역학의 복잡성과 각 운동 기술과 관련된 다양한 계획으로 인해 발생합니다.
2족 보행 로봇에 대한 연구는 수십 년 동안 진행되어 왔지만 아직까지 아무 것도 수행하지 못했습니다. 다양한 이동 기술 강력한 제어를 위한 일반적인 프레임워크입니다. 문제는 이족 보행 로봇의 제대로 작동되지 않는 역학의 복잡성과 각 운동 기술과 관련된 다양한 계획으로 인해 발생합니다.
연구원들이 해결하고자 하는 핵심 질문은 고차원 인간 크기의 이족 보행 로봇을 위한 솔루션을 어떻게 개발할 것인가입니다. 걷기, 달리기, 점프 등 다양하고 민첩하며 견고한 다리 움직임 기술을 어떻게 제어할 수 있나요?
최근 연구에 따르면 좋은 해결책이 제공될 수 있습니다.
이 연구에서 Berkeley 및 기타 기관의 연구원들은 강화 학습(RL)을 사용하여 현실 세계의 고차원 비선형 이족 보행 로봇용 컨트롤러를 만들어 위의 과제를 해결합니다. 이러한 컨트롤러는 로봇의 고유 감각 정보를 활용하여 시간이 지남에 따라 변하는 불확실한 역학에 적응하는 동시에 새로운 환경과 설정에 적응할 수 있으며 이족 보행 로봇의 민첩성을 활용하여 예상치 못한 상황에서 강력한 동작을 나타낼 수 있습니다. 또한, 우리의 프레임워크는 다양한 이족 보행 기술을 재현하기 위한 일반적인 방법을 제공합니다. 논문 제목: 다목적, 동적 및 견고한 이족 보행 제어를 위한 강화 학습논문 링크: https://arxiv.org/pdf/2401.16889.pdf
문서 세부 정보
토크 제어 인간 크기의 이족 보행 로봇의 고차원성과 비선형성은 처음에는 컨트롤러에 장애물로 보일 수 있지만 이러한 특성은 고차원 역학을 통해 복잡한 구현을 가능하게 하는 장점이 있습니다. 민첩한 작업.
안정된 서기, 걷기, 달리기, 점프 등 이 컨트롤러가 로봇에 제공하는 기술은 그림 1에 나와 있습니다. 이러한 기술은 실제 배치 중에 견고성을 유지하면서 다양한 속도와 높이로 걷기, 다양한 속도와 방향으로 달리기, 다양한 대상으로 점프 등 다양한 작업을 수행하는 데에도 사용할 수 있습니다. 이를 위해 연구자들은 모델이 없는 RL을 사용하여 로봇이 시스템의 전체 순서 역학에 대한 시행착오를 통해 학습할 수 있도록 합니다. 실제 실험 외에도 다리 움직임 제어에 RL을 사용하는 이점을 심층적으로 분석하고 적응성 및 견고성과 같은 이러한 이점을 활용하기 위해 학습 프로세스를 효과적으로 구성하는 방법을 자세히 검토합니다. 범용 이족 보행 모션 제어를 위한 RL 시스템은 그림 2에 나와 있습니다. 섹션 4에서는 먼저 모션 제어에서 로봇 I/O 기록 활용의 중요성을 소개합니다. 이 섹션은 제어 및 RL 관점에서 볼 수 있습니다. , 로봇의 장기간 I/O 이력을 통해 실시간 제어 프로세스에서 시스템 식별 및 상태 추정을 달성할 수 있음이 입증되었습니다.
5장에서는 연구의 핵심인 이족 보행 로봇의 장단기 I/O 이중 이력을 활용하는 새로운 제어 아키텍처를 소개합니다. 특히 이 제어 아키텍처는 로봇의 장기 이력뿐만 아니라 단기 이력도 활용합니다. 이 이중 이력 구조에서 장기 이력은 적응성을 가져오며(섹션 8에서 확인) 단기 이력은 활용도가 더 좋습니다. 장기 이력은 실시간 제어로 보완됩니다(섹션 7에서 검증됨).
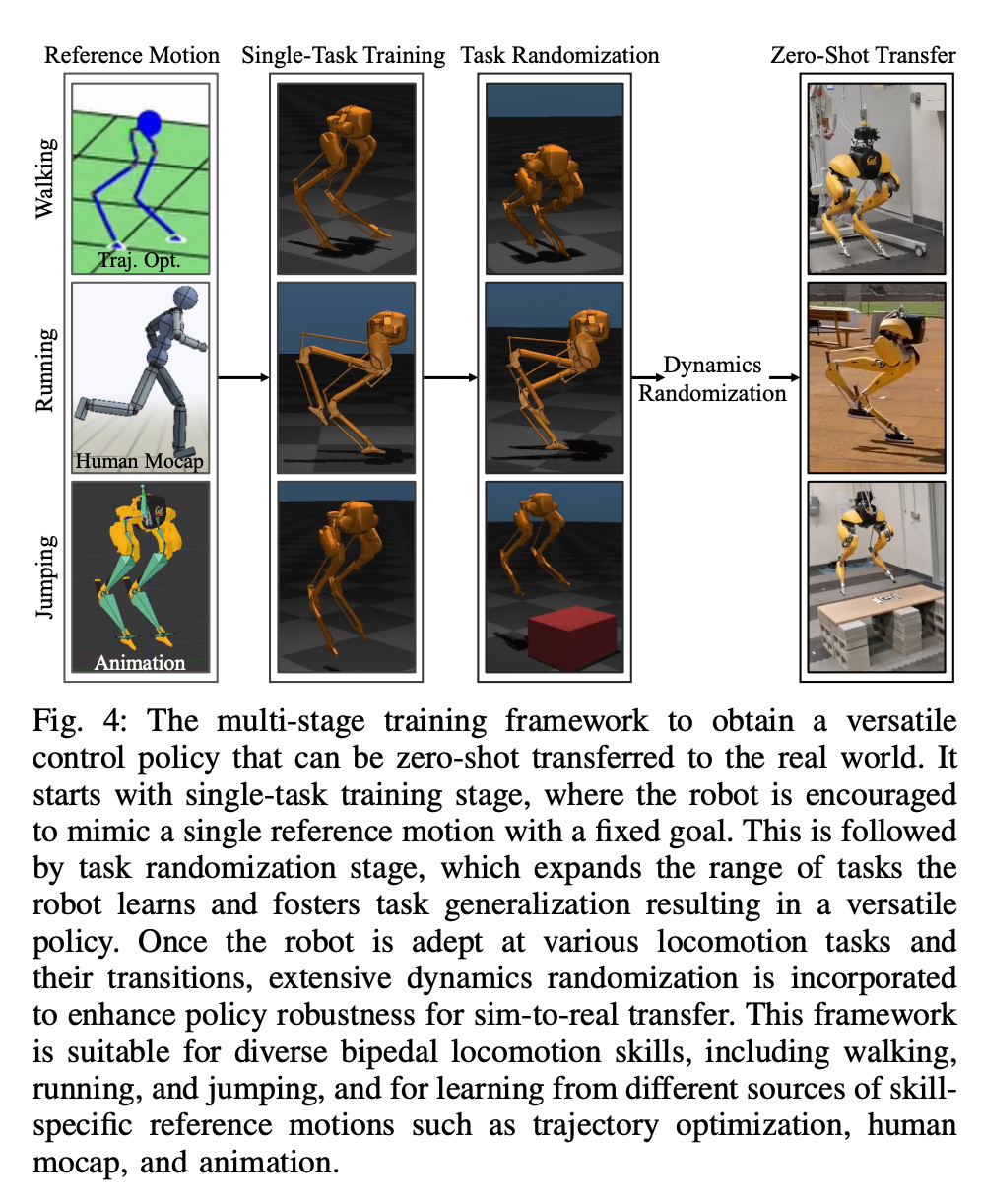
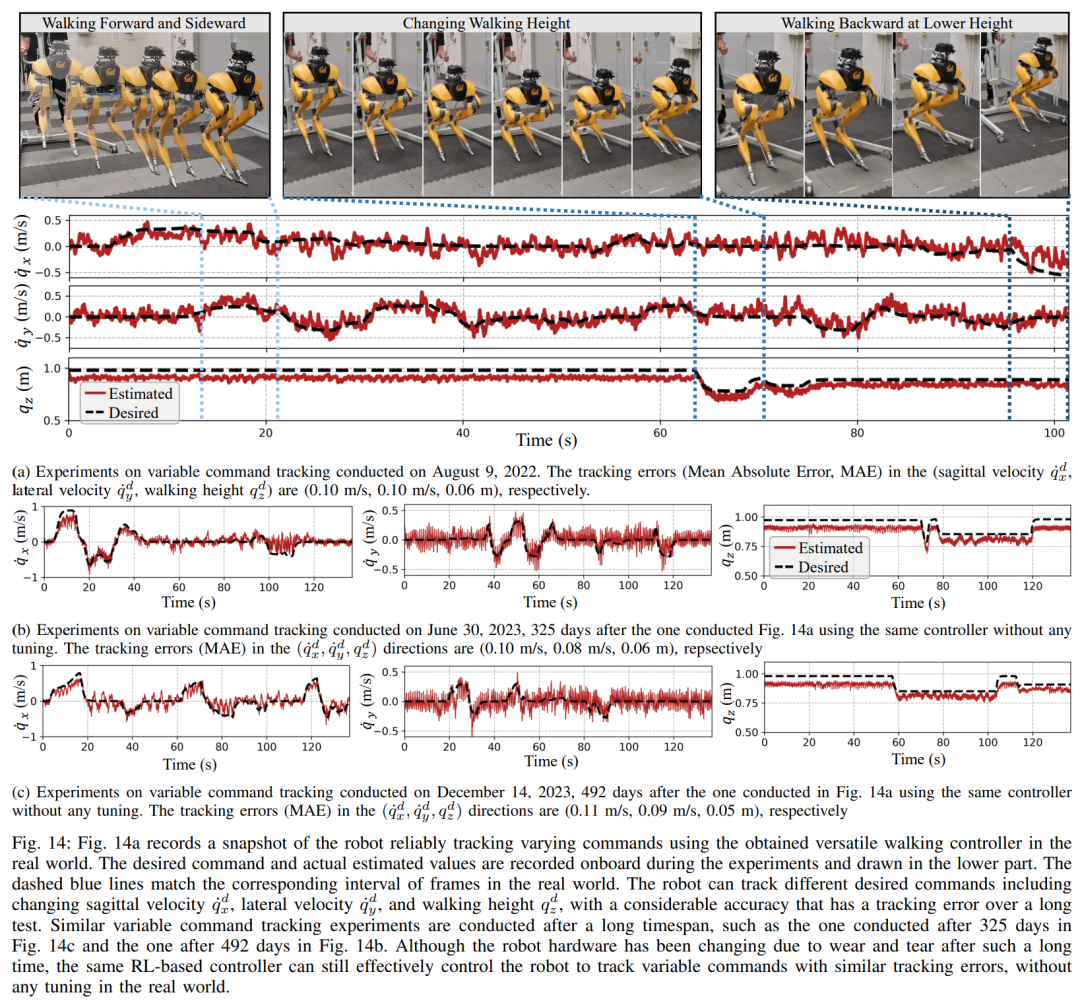
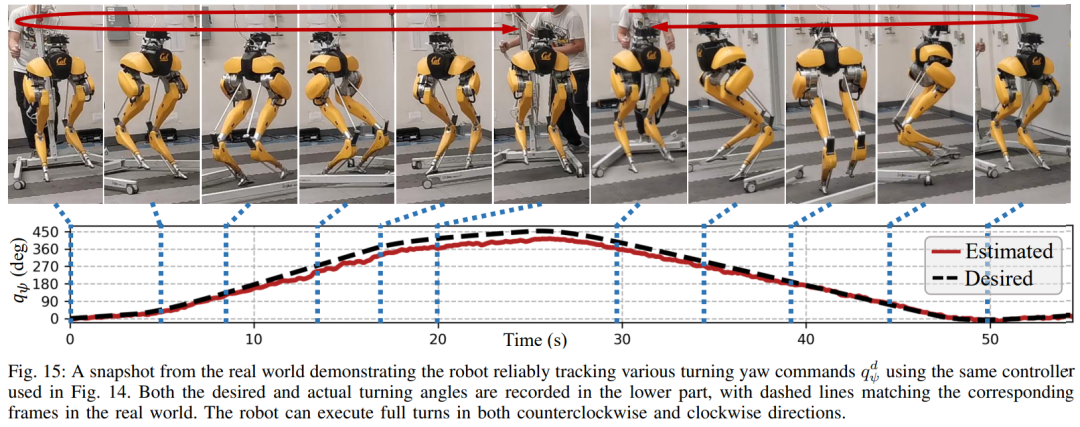
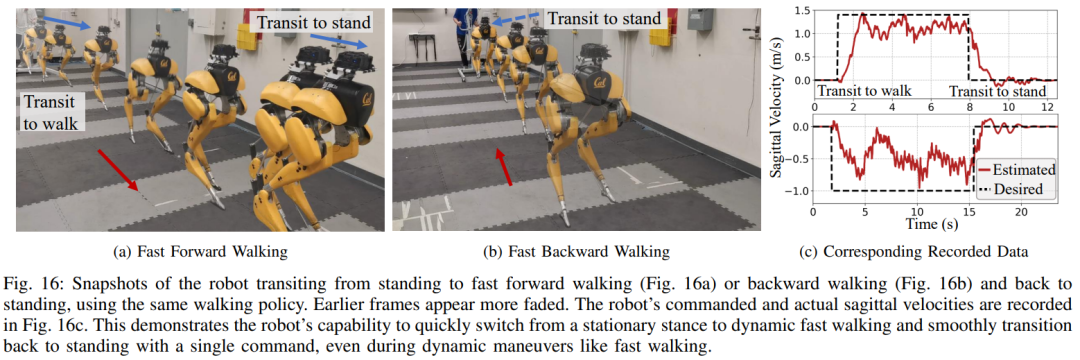
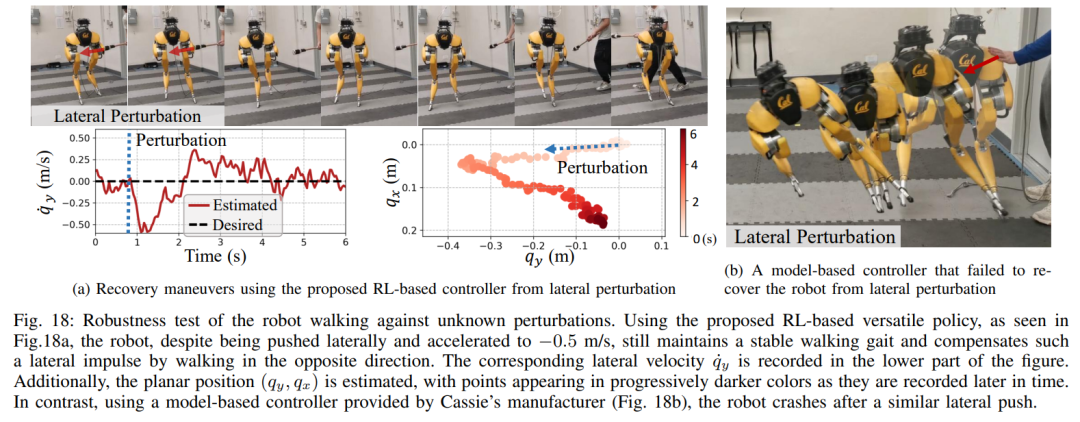
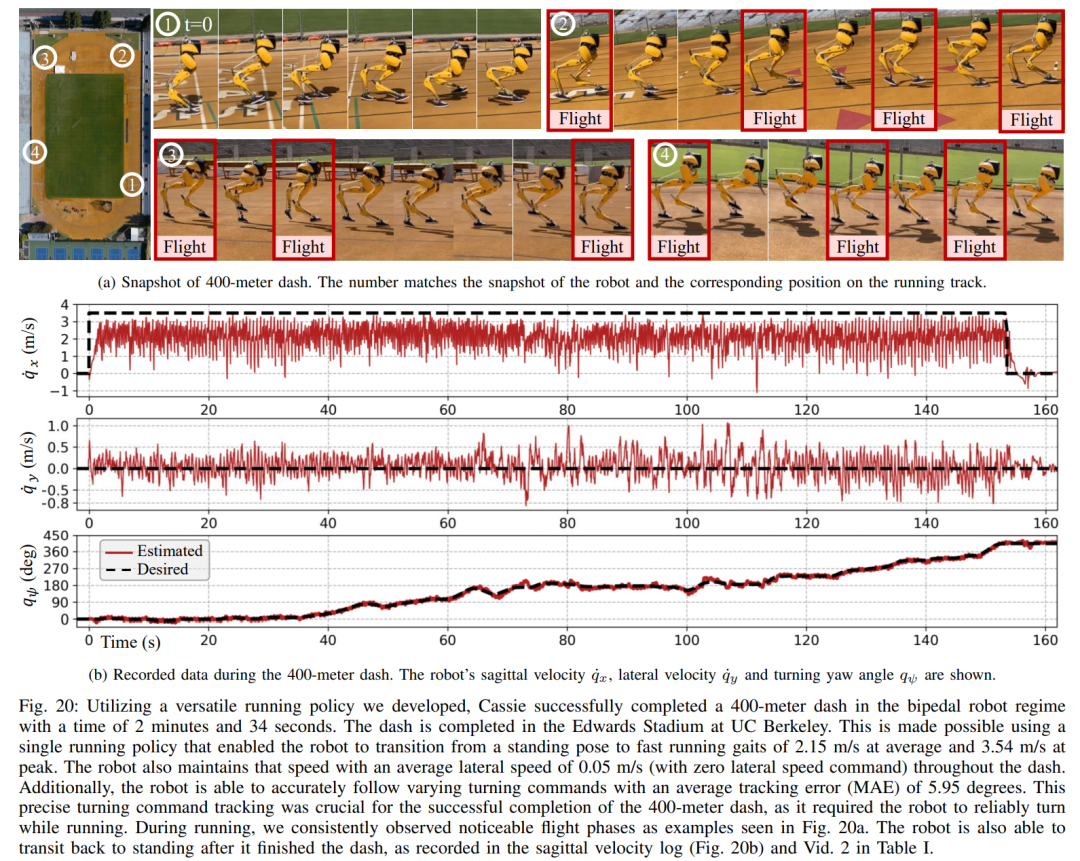
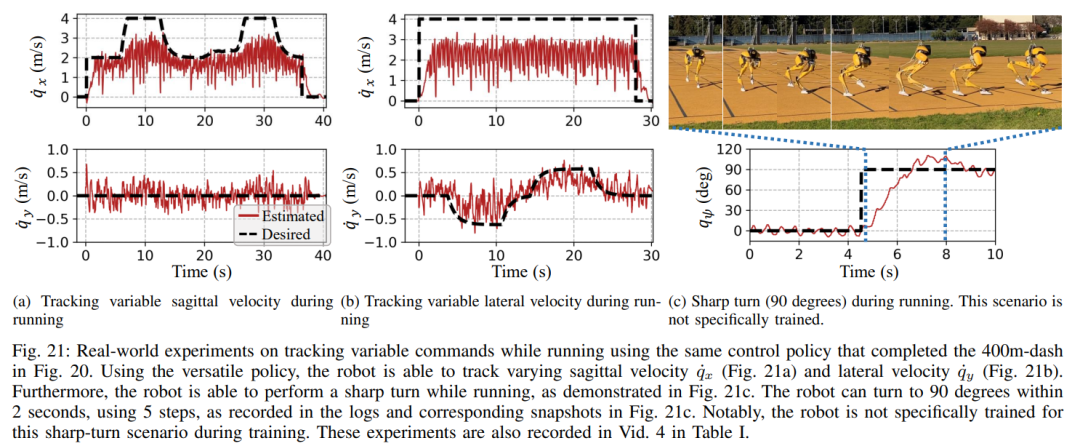
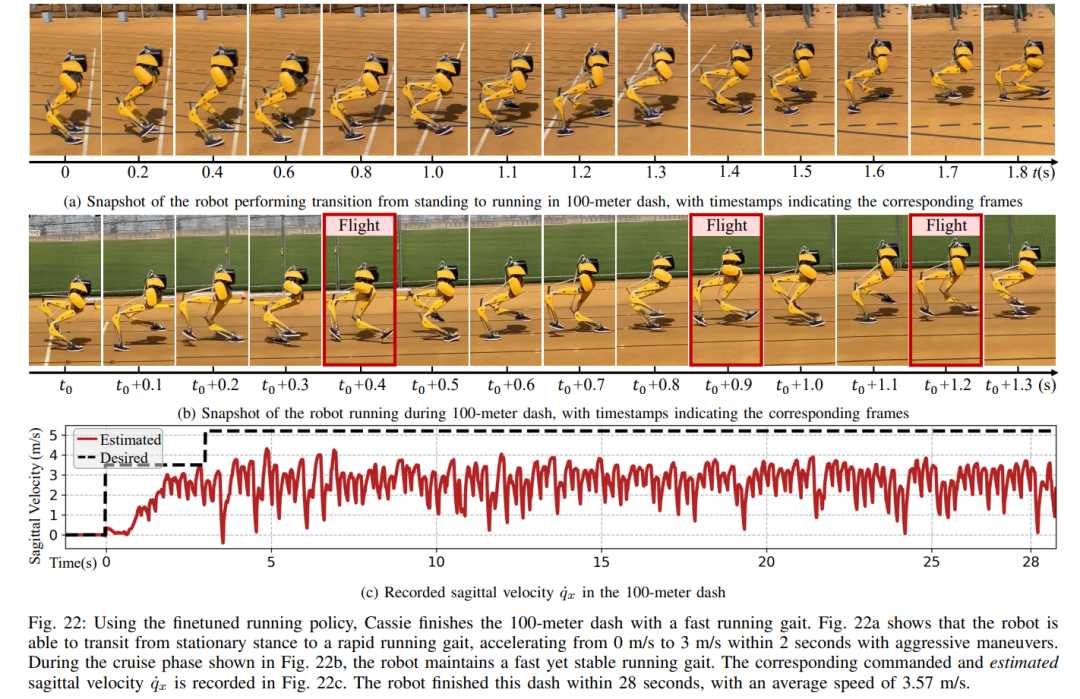
섹션 6에서는 심층 신경망으로 표현되는 제어 전략이 모델 없는 RL을 통해 최적화될 수 있는 방법을 소개합니다. 연구원들이 다양한 작업을 수행하기 위해 매우 역동적인 운동 기술을 활용할 수 있는 컨트롤러를 개발하는 것을 목표로 했다는 점을 고려할 때 이 섹션의 교육은 다단계 시뮬레이션 교육이 특징입니다. 이 훈련 전략은 로봇이 고정된 작업에 초점을 맞추는 단일 작업 훈련부터 시작하여 로봇이 받는 훈련 작업을 다양화하는 작업 무작위화, 마지막으로 로봇 동적 매개변수를 변경하는 동적 무작위화로 구성된 구조화된 과정을 제공합니다. 이 훈련 전략은 다양한 작업을 수행하고 로봇 하드웨어의 제로 샘플 마이그레이션을 달성할 수 있는 다목적 제어 전략을 제공할 수 있습니다. 또한 작업 무작위화는 다양한 학습 작업을 일반화하여 결과 정책의 견고성을 향상시킵니다. 연구에 따르면 이러한 견고성 덕분에 로봇은 동적 무작위화로 인한 교란과 "직교"하는 교란에 순응하여 행동할 수 있습니다. 이는 9절에서 확인됩니다. 이 프레임워크를 사용하여 연구원들은 이족 보행 로봇 Cassie의 걷기, 달리기 및 점프 기술에 대한 다기능 전략을 얻었습니다. 10장에서는 현실 세계에서 이러한 제어 전략의 효율성을 평가합니다. 연구원들은 현실 세계에서 걷기, 달리기, 점프 등 다양한 능력을 테스트하는 등 로봇에 대한 광범위한 실험을 수행했습니다. 사용된 전략은 모두 시뮬레이션 훈련 후 추가 조정 없이 실제 로봇을 효과적으로 제어할 수 있습니다. 그림 14a에 표시된 것처럼 걷기 전략은 전체 테스트 프로세스 동안 다양한 지침에 따라 로봇을 효과적으로 제어하는 것을 보여줍니다. 추적 오류는 매우 낮습니다. 평가할 MAE 값에 따라 결정됨). 또한 로봇 전략은 각각 그림 14c와 그림 14b에 표시된 것처럼 325일과 492일 후에도 가변 명령 추적을 유지할 수 있어 장기간에 걸쳐 일관되게 잘 수행됩니다. 이 기간 동안 로봇 역학의 상당한 누적 변화에도 불구하고 그림 14a의 동일한 컨트롤러는 추적 오류의 저하를 최소화하면서 다양한 걷기 작업을 효과적으로 관리합니다. 그림 15에서 볼 수 있듯이 이 연구에서 사용된 전략은 로봇의 안정적인 제어를 보여주었으며 로봇이 시계 방향 또는 시계 반대 방향으로 다양한 회전 명령을 정확하게 추적할 수 있도록 했습니다. 빠른 걷기 실험. 적당한 보행 속도 외에도 실험에서는 그림 16과 같이 앞뒤로 빠른 보행 동작을 수행하도록 로봇을 제어하는 데 사용된 전략의 능력도 보여줍니다. 로봇은 정지 상태에서 빠르게 전진 보행 속도를 달성할 수 있으며, 평균 속도는 1.14m/s(추적 명령에 필요한 1.4m/s)입니다. 로봇은 명령에 따라 빠르게 서 있는 자세로 돌아올 수도 있습니다. , 도 16a에 도시된 바와 같이, 데이터 기록은 도 16c에 있다. 고르지 못한 지형(훈련 없이)에서 로봇은 아래 그림과 같이 계단이나 내리막길에서도 효과적으로 뒤로 걸을 수 있습니다. 방해 방지. 예를 들어 펄스 교란의 경우, 연구자들은 로봇이 걷는 동안 모든 방향에서 로봇에 단기적인 외부 교란을 도입합니다. 그림 18a에 기록된 바와 같이, 최대 측면 속도가 0.5m/s인 제자리에서 걷는 동안 상당한 측면 교란 힘이 로봇에 적용됩니다. 교란에도 불구하고 로봇은 측면 이탈에서 빠르게 회복되었습니다. 그림 18a에 표시된 것처럼 로봇은 전문적으로 반대쪽 측면 방향으로 이동하여 교란을 효과적으로 보상하고 안정적인 제자리 걷기 보행을 복원합니다. 연속 교란 테스트 동안 인간은 로봇 베이스에 외란력을 가하고 로봇이 제자리에서 걷도록 명령하면서 로봇을 임의의 방향으로 끌었습니다. 그림 19a에서 볼 수 있듯이 로봇이 정상적으로 걸을 때 Cassie의 베이스에는 지속적인 측면 항력이 가해집니다. 결과는 로봇이 균형을 잃지 않고 방향을 따라가면서 이러한 외부 힘을 준수한다는 것을 보여줍니다. 이는 또한 안전한 인간-로봇 상호 작용을 달성하기 위해 이족 보행 로봇을 제어하는 것과 같은 잠재적인 응용 분야에서 본 논문에서 제안된 강화 학습 기반 전략의 장점을 보여줍니다. 로봇이 이족 보행 전략을 사용했을 때 400미터 달리기를 2분 34초에, 100미터 달리기를 27.06초에 달성했습니다. 최대 10°의 경사 등 400미터 달리기: 이 연구에서는 먼저 그림 20에 표시된 것처럼 표준 실외 트랙에서 400미터 달리기를 완료하기 위한 일반적인 달리기 전략을 평가했습니다.테스트 전반에 걸쳐 로봇은 3.5m/s의 속도로 작업자가 내리는 다양한 회전 명령에 동시에 응답하라는 명령을 받았습니다. 로봇은 선 자세에서 달리기 보행으로 원활하게 전환할 수 있습니다(그림 20a 1). 그림 20b에 표시된 것처럼 로봇은 평균 예상 작동 속도 2.15m/s까지 가속하여 최대 예상 속도 3.54m/s에 도달했습니다. 이 전략을 통해 로봇은 다양한 회전 명령을 정확하게 따르면서 전체 400미터 주행 동안 원하는 속도를 성공적으로 유지할 수 있었습니다. 제안된 달리기 전략에 따라 Cassie는 2분 34초 만에 400m 달리기를 성공적으로 완주했으며 이후 서 있는 자세로 전환할 수 있었습니다. 그림 21c에 기록된 대로 로봇에 요 명령이 0도에서 90도까지 단계적으로 변경되는 급격한 회전 테스트를 통해 연구가 추가로 수행되었습니다. 로봇은 이러한 스텝 명령에 반응해 2초 5걸음 만에 날카로운 90도 회전을 완료할 수 있다. 100미터 달리기: 그림 22에서 볼 수 있듯이 제안된 달리기 전략을 전개하여 로봇은 약 28초 만에 100미터 달리기를 완료하여 가장 빠른 달리기 시간인 27.06초를 달성했습니다. 실험을 통해 연구원들은 로봇이 높은 플랫폼으로 점프하면서 회전하도록 훈련시키는 것이 어렵다는 것을 알았지만 제안된 점프 전략은 로봇의 다양한 이족 보행을 달성했습니다. , 1.4m 점프와 0.44m 높이의 플랫폼으로 점프하는 것을 포함합니다. 점프 및 회전: 그림 25a에 표시된 것처럼 단일 점프 전략을 사용하여 로봇은 60° 회전 시 제자리 점프, 뒤로 점프, 0.3m 뒤에서 착지하는 등 다양한 주어진 목표 점프를 수행할 수 있습니다. . 높은 플랫폼으로 점프: 그림 25b에 표시된 것처럼 로봇은 전방 1m 또는 전방 1.4m 등 다양한 위치의 대상으로 정확하게 점프할 수 있습니다. 또한 다음을 포함하여 다양한 높이의 위치로 점프할 수도 있습니다. 0.44m 높이까지 점프합니다(로봇 자체의 키가 1.1m에 불과하다는 점을 고려하면). 위 내용은 당신과 함께 달리는 것은 빠르고 안정적입니다. 로봇 러닝 파트너가 여기 있습니다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


 2족 보행 로봇에 대한 연구는 수십 년 동안 진행되어 왔지만 아직까지 아무 것도 수행하지 못했습니다. 다양한 이동 기술 강력한 제어를 위한 일반적인 프레임워크입니다. 문제는 이족 보행 로봇의 제대로 작동되지 않는 역학의 복잡성과 각 운동 기술과 관련된 다양한 계획으로 인해 발생합니다.
2족 보행 로봇에 대한 연구는 수십 년 동안 진행되어 왔지만 아직까지 아무 것도 수행하지 못했습니다. 다양한 이동 기술 강력한 제어를 위한 일반적인 프레임워크입니다. 문제는 이족 보행 로봇의 제대로 작동되지 않는 역학의 복잡성과 각 운동 기술과 관련된 다양한 계획으로 인해 발생합니다. 
 범용 이족 보행 모션 제어를 위한 RL 시스템은 그림 2에 나와 있습니다.
범용 이족 보행 모션 제어를 위한 RL 시스템은 그림 2에 나와 있습니다. 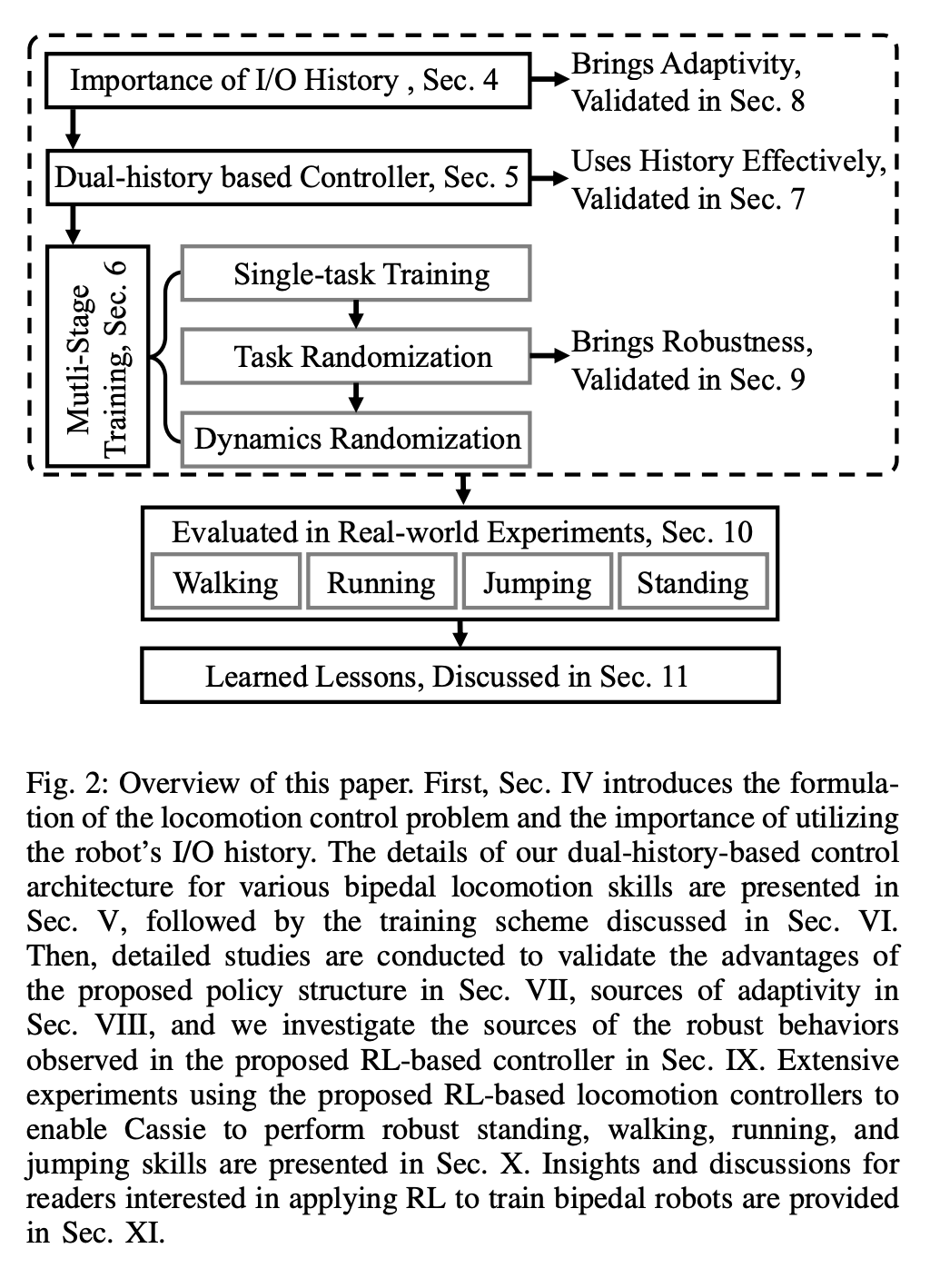 섹션 4에서는 먼저 모션 제어에서 로봇 I/O 기록 활용의 중요성을 소개합니다. 이 섹션은 제어 및 RL 관점에서 볼 수 있습니다. , 로봇의 장기간 I/O 이력을 통해 실시간 제어 프로세스에서 시스템 식별 및 상태 추정을 달성할 수 있음이 입증되었습니다.
섹션 4에서는 먼저 모션 제어에서 로봇 I/O 기록 활용의 중요성을 소개합니다. 이 섹션은 제어 및 RL 관점에서 볼 수 있습니다. , 로봇의 장기간 I/O 이력을 통해 실시간 제어 프로세스에서 시스템 식별 및 상태 추정을 달성할 수 있음이 입증되었습니다. 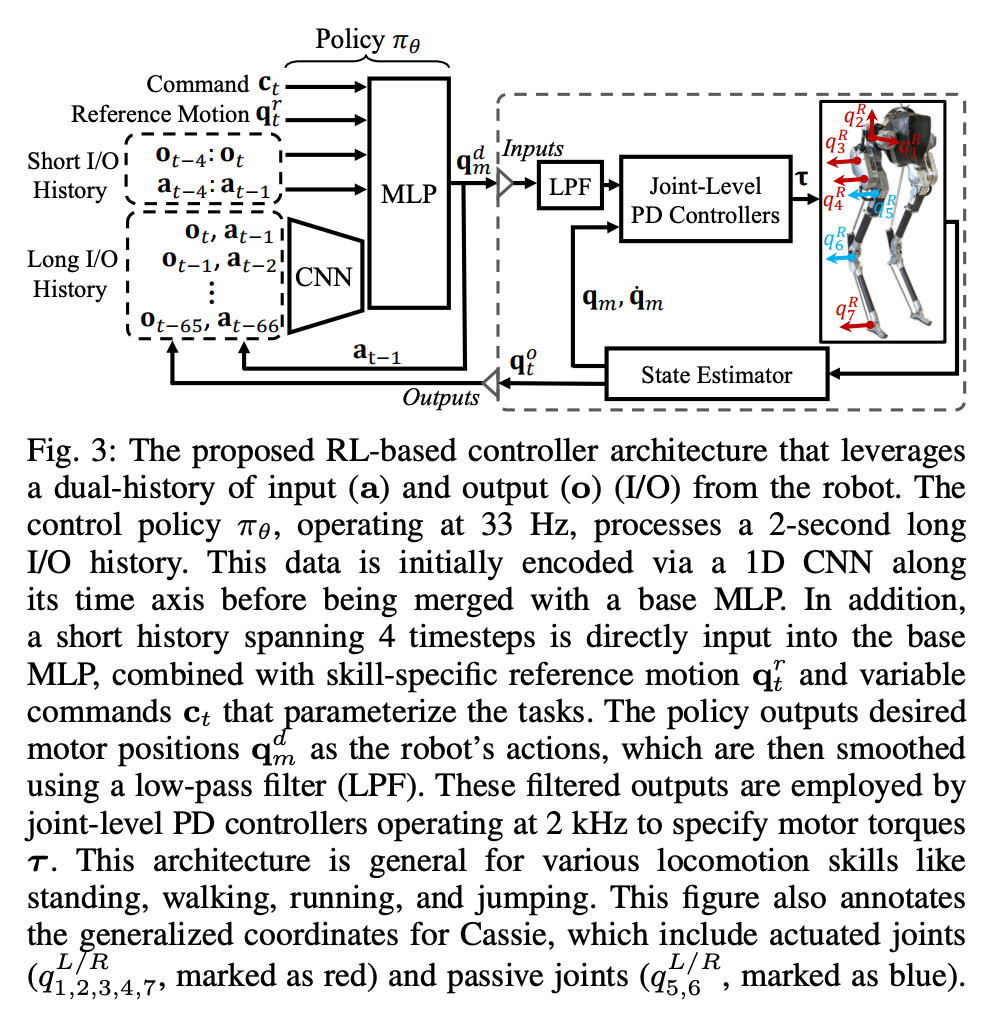 이 이중 이력 구조에서 장기 이력은 적응성을 가져오며(섹션 8에서 확인) 단기 이력은 활용도가 더 좋습니다. 장기 이력은 실시간 제어로 보완됩니다(섹션 7에서 검증됨).
이 이중 이력 구조에서 장기 이력은 적응성을 가져오며(섹션 8에서 확인) 단기 이력은 활용도가 더 좋습니다. 장기 이력은 실시간 제어로 보완됩니다(섹션 7에서 검증됨).