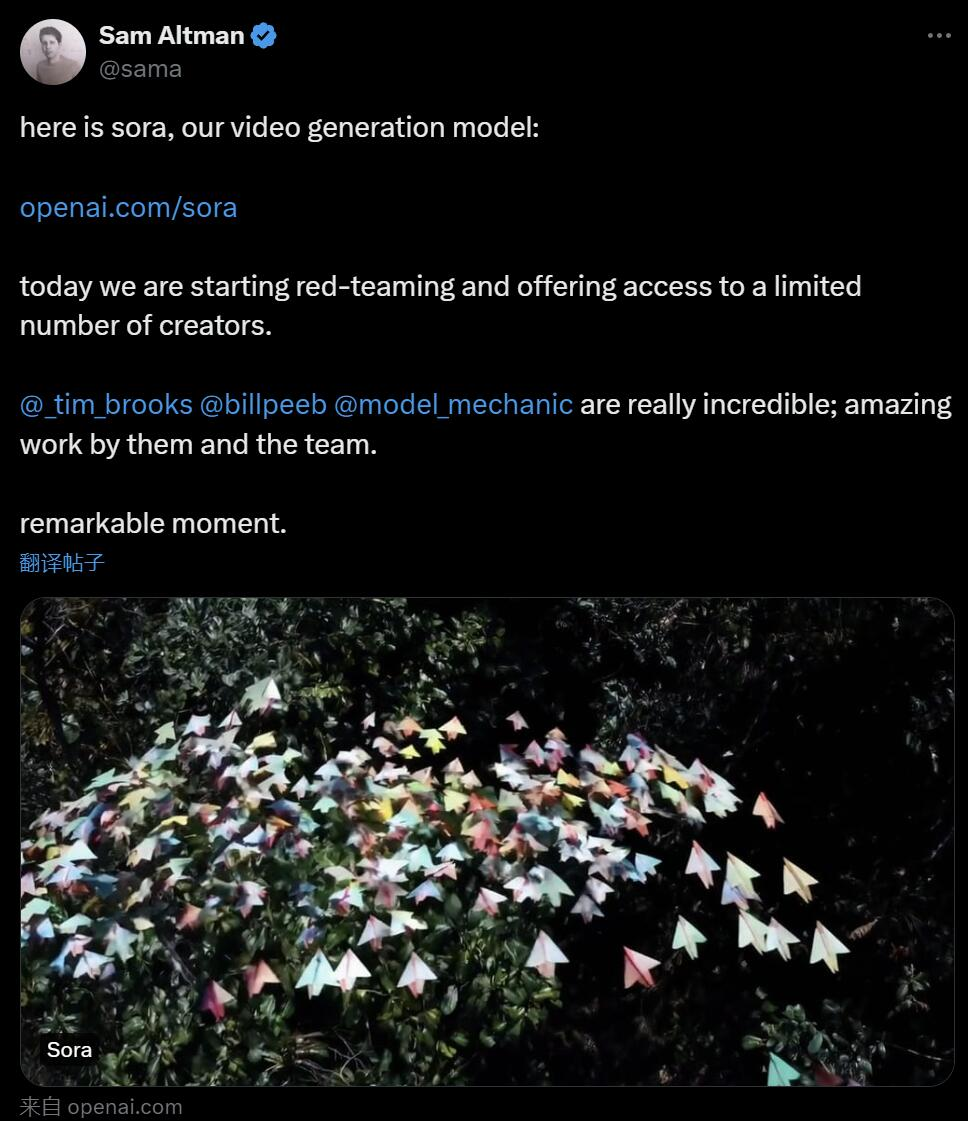
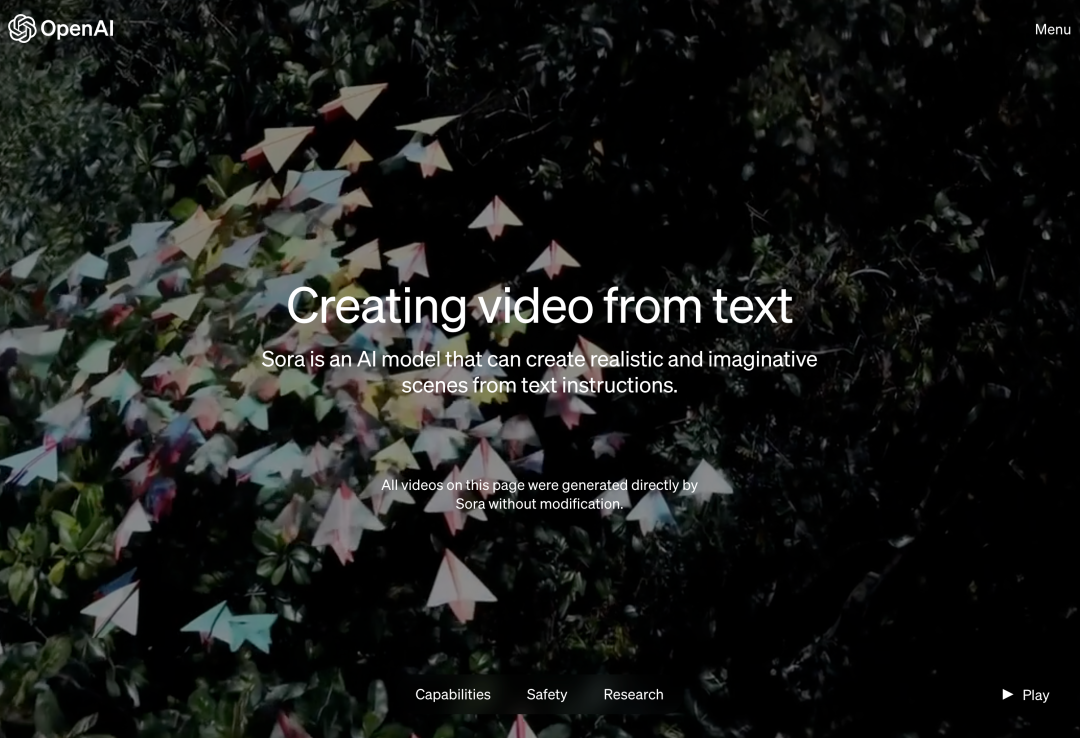
오늘 오전 베이징 시간, OpenAI는 텍스트-비디오 세대 모델인 Sora를 공식 출시했습니다. Runway, Pika, Google, Meta에 이어 OpenAI가 마침내 비디오 세대 전쟁에 뛰어들었습니다. 울트라맨 샘의 소식이 공개된 후, 사람들은 OpenAI 엔지니어들이 시연한 AI 생성 비디오 효과를 처음으로 보았습니다. 사람들은 “할리우드 시대는 끝났는가?”라고 한탄했습니다. OpenAI는 짧거나 자세한 설명 또는 정적 이미지가 제공되면 Sora가 여러 캐릭터, 다양한 유형의 동작 및 배경 세부 정보가 포함된 영화와 같은 1080p 장면을 생성할 수 있다고 주장합니다. 소라의 특별한 점은 무엇인가요? 언어에 대한 깊은 이해를 바탕으로 프롬프트를 정확하게 해석하고 생생한 감정을 표현하는 매력적인 캐릭터를 생성할 수 있습니다. 동시에 Sora는 프롬프트에서 사용자의 요청을 이해할 수 있을 뿐만 아니라 실제 세계에 존재하는 방식도 파악할 수 있습니다. 공식 블로그에서 OpenAI는 Sora가 생성한 비디오의 많은 예를 제공하며, 적어도 이전의 텍스트 생성 비디오 기술과 비교할 때 인상적인 결과를 보여줍니다. 우선 Sora는 대부분의 텍스트-비디오 모델보다 훨씬 긴 최대 1분 길이의 다양한 스타일(예: 사실적, 애니메이션, 흑백)로 비디오를 생성할 수 있습니다. 동영상은 합리적인 일관성을 유지하며 물체가 물리적으로 불가능한 방향으로 움직이는 소위 "AI 기이함"에 항상 굴복하지 않습니다. 먼저 소라가 중국 용의 해에 용 춤을 추는 동영상을 생성하게 하세요. 
예를 들어 프롬프트: 캘리포니아 골드러시의 역사적 영상을 입력하세요. 
프롬프트 입력: 내부에 젠 정원이 있는 유리 공의 클로즈업 보기. 구체 내부에는 모래에 패턴을 만드는 드워프가 있습니다. 
프롬프트 입력: 매직 아워 동안 마라케시에 서서 눈을 깜박이는 24세 여성의 극단적인 클로즈업, 70mm로 촬영된 영화, 피사계 심도, 생생한 색상, 영화적. 
프롬프트 입력: 도쿄 교외를 지나가는 기차 창문에 비친 모습. 
Enter 프로모션: 사이버펑크 환경에서 펼쳐지는 로봇의 삶의 이야기. 
사진이 너무 현실적이면서 동시에 너무 이상합니다하지만 OpenAI는 현재 모델에도 약점이 있음을 인정합니다. 복잡한 시나리오에서 물리적 현상을 정확하게 시뮬레이션하는 데 어려움이 있을 수 있으며, 구체적인 원인과 결과 관계를 이해하지 못할 수도 있습니다. 모델은 또한 왼쪽과 오른쪽과 같은 단서의 공간적 세부 사항을 혼동할 수 있으며 특정 카메라 궤적을 따르는 것과 같이 시간이 지남에 따라 이벤트를 정확하게 설명하는 데 어려움을 겪을 수 있습니다. 예를 들어, 생성 과정에서 특히 많은 개체가 포함된 장면에서 동물과 사람이 자연스럽게 나타나는 것을 발견했습니다. 아래 예에서 프롬프트는 원래 "5마리의 회색 늑대 새끼들이 풀로 둘러싸인 외딴 자갈길에서 서로 놀고 쫓고 있었습니다. 새끼들은 달리고, 뛰고, 쫓고, 물고, 서로 놀고 있었습니다."였습니다. 그런데 생성된 "복사하여 붙여넣기" 사진은 신비한 유령 전설을 매우 연상시킵니다. 
다음 예도 있습니다. 촛불을 끄기 전후에 불꽃이 전혀 변하지 않은 것이 이상합니다. : 
우리는 소라 뒤에 있는 모델의 세부 사항에 대해 거의 알지 못합니다. OpenAI 블로그에 따르면, 후속 기술 문서에서 더 많은 정보가 공개될 예정입니다. 블로그에 공개된 몇 가지 기본 정보: Sora는 처음에는 정적 노이즈처럼 보이는 동영상을 생성한 다음 여러 단계를 거쳐 노이즈를 제거하여 점차적으로 동영상을 변형시키는 확산 모델입니다. Midjourney 및 Stable Diffusion의 이미지 및 비디오 생성기도 확산 모델을 기반으로 합니다. 하지만 OpenAI Sora가 생성한 비디오의 품질이 훨씬 더 좋다는 것을 알 수 있습니다. Sora는 실제 비디오를 만드는 것처럼 느껴지지만, 경쟁사의 이전 모델은 AI 생성 이미지의 스톱모션 애니메이션처럼 느껴졌습니다. 소라는 전체 동영상을 한 번에 생성하거나 생성된 동영상을 확장하여 더 길게 만들 수 있습니다. OpenAI는 모델이 한 번에 여러 프레임을 예측하도록 함으로써 피사체가 일시적으로 시야에서 벗어나더라도 피사체가 그대로 유지되도록 보장하는 어려운 문제를 해결합니다. GPT 모델과 유사하게 Sora도 트랜스포머 아키텍처를 사용하여 뛰어난 확장성 성능을 달성합니다. OpenAI는 비디오와 이미지를 패치라고 하는 작은 데이터 단위의 모음으로 표현하며, 각 패치는 GPT의 토큰과 유사합니다. OpenAI는 데이터 표현을 통합함으로써 다양한 기간, 해상도, 종횡비를 포함하여 이전보다 더 광범위한 시각적 데이터에 대해 확산 변환기를 훈련할 수 있습니다. Sora는 DALL・E 및 GPT 모델에 대한 과거 연구를 기반으로 구축되었습니다. DALL・E 3의 요약 기술을 사용하여 시각적 교육 데이터를 위한 매우 설명적인 자막을 생성합니다. 결과적으로 모델은 생성된 비디오에서 사용자의 텍스트 단서를 더욱 충실하게 따를 수 있습니다. 모델은 텍스트 설명만을 기반으로 동영상을 생성할 수 있을 뿐만 아니라 기존 정적 이미지를 기반으로 동영상을 생성하고 이미지 콘텐츠에 정확하고 세심하게 애니메이션을 적용할 수 있습니다. 모델은 기존 비디오를 추출하여 확장하거나 누락된 프레임을 채울 수도 있습니다. 참조링크: https://openai.com/sora위 내용은 춘절 선물 패키지! OpenAI, 네티즌 감동시킨 60초 고화질 명작, 첫 동영상 세대 모델 출시의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!