대규모 언어 모델(LLM)의 성공은 "인간 피드백 기반 강화 학습(RLHF)"과 떼려야 뗄 수 없습니다. RLHF는 대략 두 단계로 나눌 수 있습니다. 첫째, 선호하는 행동과 선호하지 않는 행동의 쌍이 주어지면 목표를 분류하여 전자에 더 높은 점수를 할당하도록 보상 모델이 훈련됩니다. 이 보상 기능은 일종의 강화 학습 알고리즘을 통해 최적화됩니다. 그러나 보상 모델의 핵심 요소는 바람직하지 않은 영향을 미칠 수 있습니다. Carnegie Mellon University(CMU)의 연구원과 Google Research는 간단하고 이론적으로 엄격하며 실험적으로 효과적인 새로운 RLHF 방법인 자가 게임 선호도 최적화(Self-Play Preference Optimization(SPO))를 공동으로 제안했습니다. 이 접근 방식은 보상 모델을 제거하고 적대적 교육이 필요하지 않습니다. 
논문: 인간 피드백을 통한 강화 학습에 대한 Minimaximalist 접근 방식논문 주소: https://arxiv.org/abs/2401.04056 SPO 더 방법에는 주로 두 가지 측면이 포함됩니다. 첫째, 이 연구는 RLHF를 제로섬 게임으로 구성하여 실제로 보상 모델을 제거하여 실제로 자주 나타나는 시끄러운 비마코브 선호도를 더 잘 처리할 수 있도록 합니다. 둘째, 게임의 대칭성을 활용함으로써 본 연구는 단일 에이전트가 자체 게임 방식으로 간단하게 훈련될 수 있음을 보여줌으로써 불안정한 적 훈련의 필요성을 제거합니다. 실제로 이는 에이전트에서 여러 궤적을 샘플링하고, 평가자 또는 선호 모델에 각 궤적 쌍을 비교하도록 요청하고, 궤적의 승률에 대한 보상을 설정하는 것과 같습니다. SPO는 보상 모델링, 복합 오류 및 적대적 훈련을 방지합니다. 사회적 선택 이론에서 최소최대 승자의 개념을 확립함으로써 본 연구는 RLHF를 2인 제로섬 게임으로 구성하고 게임 보상 매트릭스의 대칭성을 활용하여 단일 에이전트가 자신에 대해 간단하게 훈련될 수 있음을 보여줍니다.
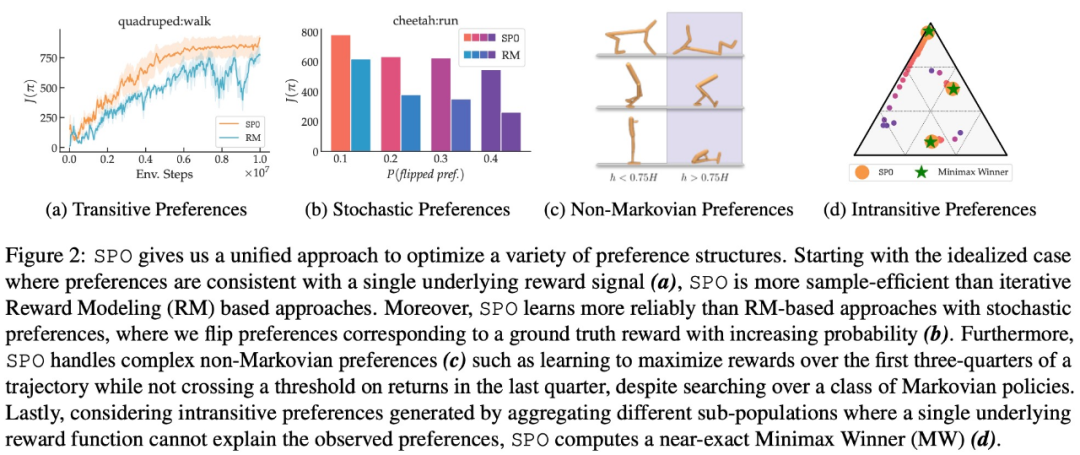
이 연구는 또한 SPO의 수렴 특성을 분석하고 잠재적인 보상 함수가 존재할 때 SPO가 표준 방법에 필적하는 빠른 속도로 최적의 정책으로 수렴할 수 있음을 증명합니다. 이 연구는 SPO가 현실적인 선호 기능을 갖춘 일련의 연속 제어 작업에서 보상 모델 기반 방법보다 더 나은 성능을 발휘한다는 것을 보여줍니다. SPO는 아래 그림 2와 같이 다양한 기본 설정에서 보상 모델 기반 방법보다 더 효율적으로 샘플을 학습할 수 있습니다.
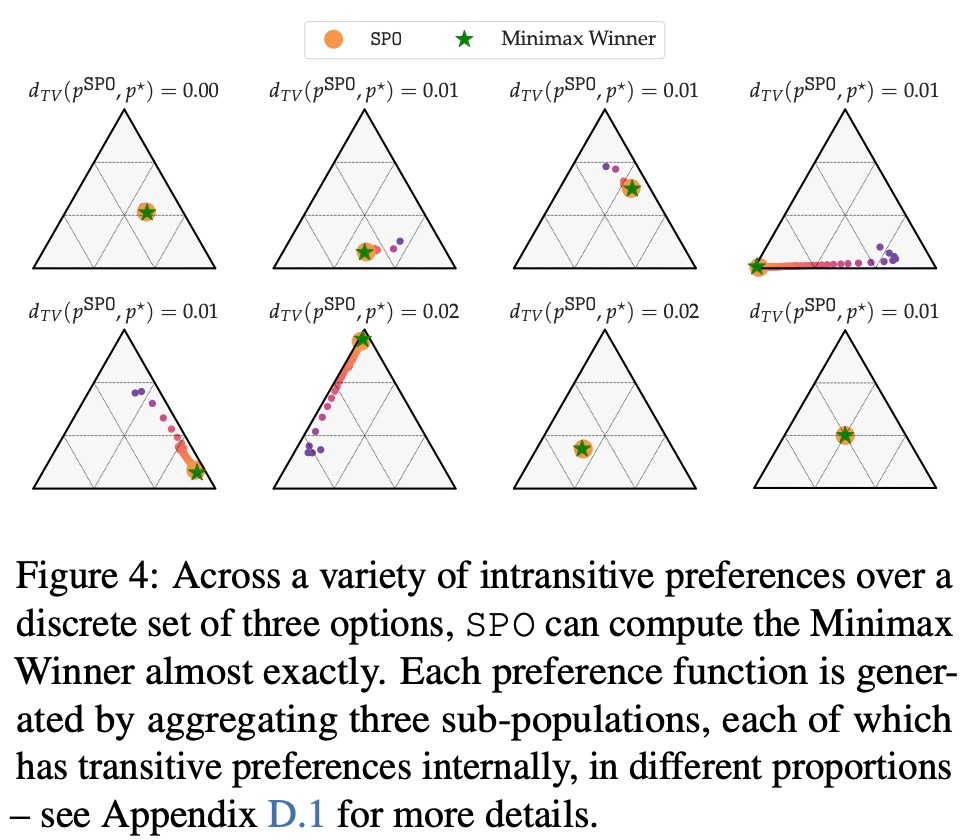
이 연구는 SPO를 다차원의 반복 보상 모델링(RM) 방법과 비교하여 4가지 질문에 답하는 것을 목표로 합니다. MW? 독특한 Copeland 우승자/최적 전략 문제에 대해 SPO가 RM 샘플 효율성과 일치하거나 초과할 수 있습니까?
-
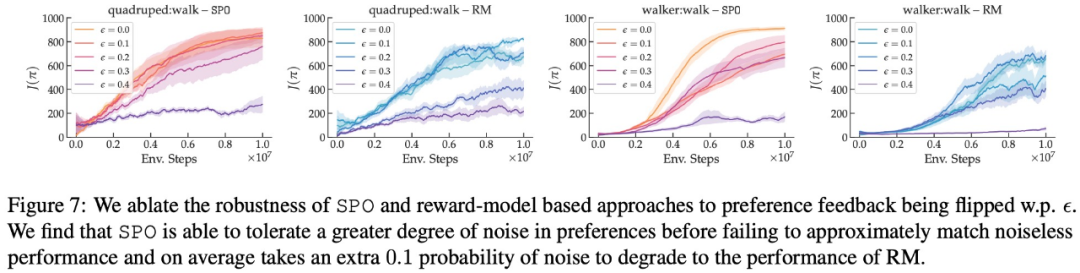
SPO는 무작위 선호도에 얼마나 강력합니까?
-
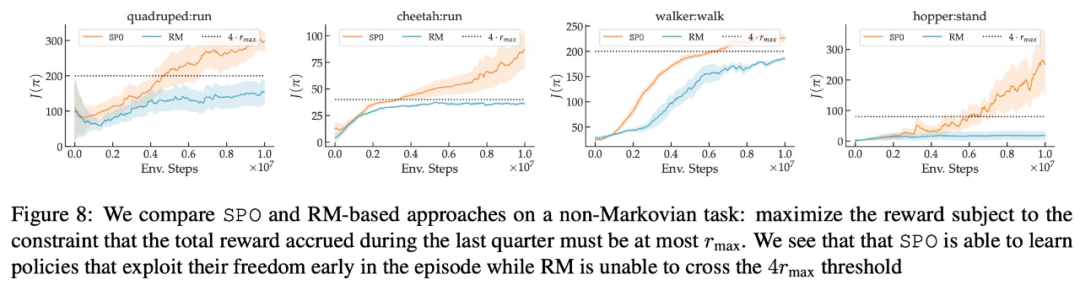
SPO가 비마코비안 기본 설정을 처리할 수 있나요?
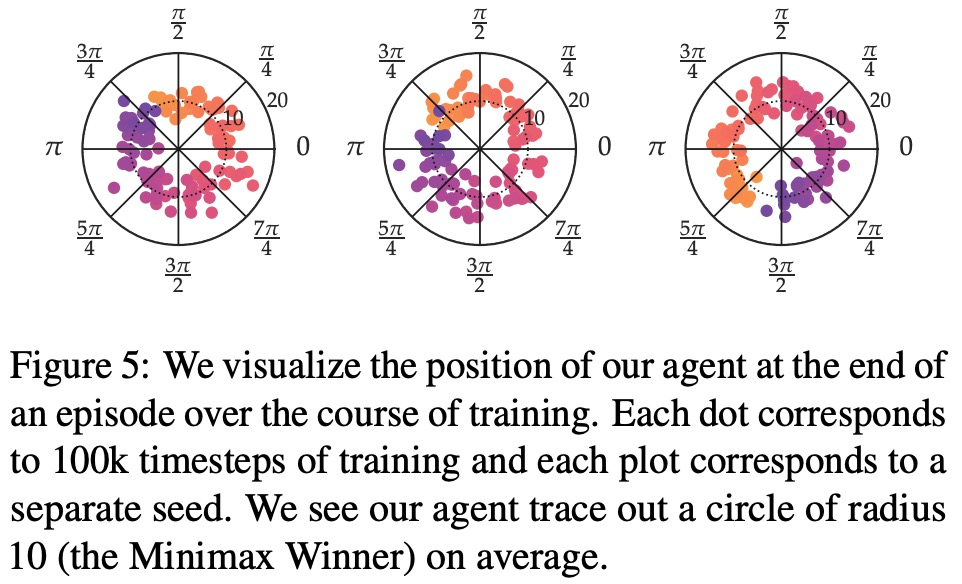
- 최대 보상 선호도, 잡음 선호도, 비마르코프 선호도 측면에서 본 연구의 실험 결과는 각각 그림 6, 7, 8에 나와 있습니다.
관심 있는 독자는 논문 원문을 읽고 연구 내용에 대해 자세히 알아볼 수 있습니다. 위 내용은 Google은 보상 모델을 제거하고 적대적 훈련의 필요성을 제거하는 새로운 RLHF 방법을 제안합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!