



최근 몇 년 동안 사람들은 기계 학습 데이터(ML 데이터)에 대한 심층적인 이해의 중요성에 대해 더 깊은 이해를 얻었습니다. 그러나 대규모 데이터 세트를 탐지하려면 일반적으로 많은 인적, 물적 투자가 필요하므로 컴퓨터 비전 분야에 널리 적용하려면 여전히 추가 개발이 필요합니다.
일반적으로 객체 감지(컴퓨터 비전의 하위 집합)에서는 경계 상자를 정의하여 이미지의 객체를 배치합니다. 객체를 식별할 수 있을 뿐만 아니라 객체의 컨텍스트, 크기 및 컨텍스트도 확인할 수 있습니다. 장면의 다른 요소와의 관계를 이해합니다. 동시에 클래스 분포, 객체 크기의 다양성, 클래스가 나타나는 공통 환경에 대한 포괄적인 이해는 평가 및 디버깅 중에 훈련 모델의 오류 패턴을 발견하는 데 도움이 됩니다. 더 많은 타겟을 선택하세요.
실제로 저는 다음과 같은 접근 방식을 취하는 경향이 있습니다.
- 사전 훈련된 모델이나 기본 모델의 개선 사항을 사용하여 데이터에 구조를 추가합니다. 예를 들어 다양한 이미지 임베딩을 생성하고 t-SNE 또는 UMAP와 같은 차원 축소 기술을 사용합니다. 이는 데이터 검색을 용이하게 하기 위해 유사성 맵을 생성할 수 있습니다. 또한 감지를 위해 사전 훈련된 모델을 사용하면 상황 추출도 용이해질 수 있습니다.
- 이러한 구조를 원시 데이터의 통계 및 검토 기능과 통합할 수 있는 시각화 도구를 사용하세요.
아래에서는 Renomics Spotlight을 사용하여 대화형 객체 감지 시각화를 만드는 방법을 소개하겠습니다. 예를 들어 다음을 시도하겠습니다.
- 이미지에서 사람 감지기에 대한 시각화를 구축합니다.
- 시각화에는 유사성 맵, 필터 및 통계가 포함되어 있어 데이터를 쉽게 탐색할 수 있습니다.
- Ground Truth 및 Ultralytics YOLOv8 감지를 통해 모든 이미지를 자세히 볼 수 있습니다.
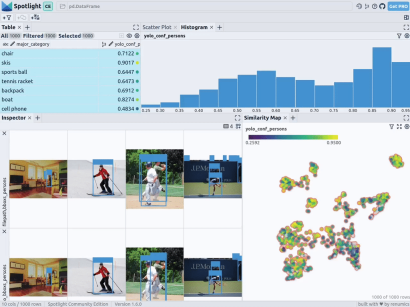 Renomics Spotlight의 목표 시각화. 출처: 작성자 작성
Renomics Spotlight의 목표 시각화. 출처: 작성자 작성
먼저 다음 명령을 통해 필요한 패키지를 설치합니다.
!pip install fiftyone ultralytics renumics-spotlight
의 재개 가능한 다운로드 기능을 활용하세요. COCO 데이터세트에서 다양한 이미지를 다운로드할 수 있습니다. 간단한 매개변수 설정으로 한 명 이상의 인물이 포함된 이미지 1,000개를 다운로드할 수 있습니다. 구체적인 코드는 다음과 같습니다.
importpandasaspdimportnumpyasnpimportfiftyone.zooasfoz# 从 COCO 数据集中下载 1000 张带人的图像dataset = foz.load_zoo_dataset( "coco-2017"、split="validation"、label_types=[ "detections"、],classes=["person"]、 max_samples=1000、dataset_name="coco-2017-person-1k-validations"、)그런 다음 다음 코드를 사용할 수 있습니다.
def xywh_too_xyxyn(bbox): "" convert from xywh to xyxyn format """ return[bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3]].行 = []fori, samplein enumerate(dataset):labels = [detection.labelfordetectioninsample.ground_truth.detections] bboxs = [...bboxs = [xywh_too_xyxyn(detection.bounding_box) fordetectioninsample.ground_truth.detections]bboxs_persons = [bboxforbbox, labelin zip(bboxs, labels)iflabel =="person"] 行。row.append([sample.filepath, labels, bboxs, bboxs_persons])df = pd.DataFrame(row, columns=["filepath","categories", "bboxs", "bboxs_persons"])df["major_category"] = df["categories"].apply( lambdax:max(set(x) -set(["person"]), key=x.count) if len(set(x)) >1 else "only person"。)데이터를 Pandas DataFrame으로 준비합니다. 열에는 파일 경로, 경계 상자 범주, 테두리가 포함됩니다. 상자, 테두리 상자에 포함된 사람 및 이미지에 있는 사람의 컨텍스트를 지정하는 기본 카테고리(사람이 있더라도):

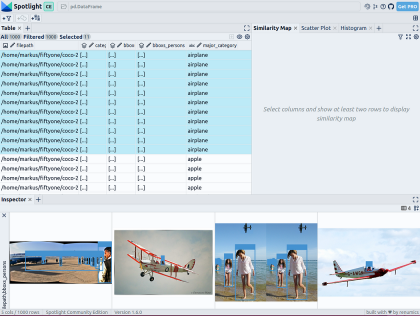
From renumics import spotlightspotlight.show(df)Inspector 보기에서 보기 추가 버튼을 사용하고 테두리 보기에서 bboxs_persons 및 파일 경로를 선택하여 이미지와 함께 해당 테두리를 표시할 수 있습니다.
구조 제공 데이터에 다양한 기본 모델(예: 조밀한 벡터 표현)의 이미지 임베딩을 채택할 수 있습니다. 이를 위해 UMAP 또는 t-SNE와 같은 추가 차원 축소 기술을 사용하여 전체 이미지의 ViT(Vision Transformer) 임베딩을 데이터 세트의 구조화에 적용하여 이미지의 2D 유사성 맵을 제공할 수 있습니다. 또한 사전 훈련된 객체 감지기의 출력을 사용하여 포함된 객체의 크기나 수에 따라 데이터를 분류함으로써 데이터를 구조화할 수 있습니다. COCO 데이터 세트는 이미 이 정보를 제공하므로 직접 사용할 수 있습니다.
Spotl
ight는 google/vit-base-patch16-224-in21k(ViT) 모델 및 UMAP 에 대한 지원을 통합하므로 파일 경로를 사용하여 다양한 삽입을 생성하면 자동으로 적용됩니다.
spotlight.show(df, embed=["filepath"])
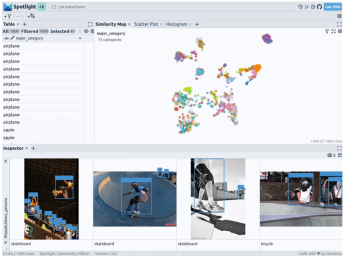
通过上述代码,Spotlight 将各种嵌入进行计算,并应用 UMAP 在相似性地图中显示结果。其中,不同的颜色代表了主要的类别。据此,您可以使用相似性地图来浏览数据:
预训练YOLOv8的结果
可用于快速识别物体的Ultralytics YOLOv8,是一套先进的物体检测模型。它专为快速图像处理而设计,适用于各种实时检测任务,特别是在被应用于大量数据时,用户无需浪费太多的等待时间。
为此,您可以首先加载预训练模型:
From ultralytics import YOLOdetection_model = YOLO("yolov8n.pt")并执行各种检测:
detections = []forfilepathindf["filepath"].tolist():detection = detection_model(filepath)[0]detections.append({ "yolo_bboxs":[np.array(box.xyxyn.tolist())[0]forboxindetection.boxes]、 "yolo_conf_persons": np.mean([np.array(box.conf.tolist())[0]. forboxindetection.boxes ifdetection.names[int(box.cls)] =="person"]), np.mean(]), "yolo_bboxs_persons":[np.array(box.xyxyn.tolist())[0] forboxindetection.boxes ifdetection.names[int(box.cls)] =="person],"yolo_categories": np.array([np.array(detection.names[int(box.cls)])forboxindetection.boxes], "yolo_categories": np.array(),})df_yolo = pd.DataFrame(detections)在12gb的GeForce RTX 4070 Ti上,上述过程在不到20秒的时间内便可完成。接着,您可以将结果包含在DataFrame中,并使用Spotlight将其可视化。请参考如下代码:
df_merged = pd.concat([df, df_yolo], axis=1)spotlight.show(df_merged, embed=["filepath"])
下一步,Spotlight将再次计算各种嵌入,并应用UMAP到相似度图中显示结果。不过这一次,您可以为检测到的对象选择模型的置信度,并使用相似度图在置信度较低的集群中导航检索。毕竟,鉴于这些图像的模型是不确定的,因此它们通常有一定的相似度。
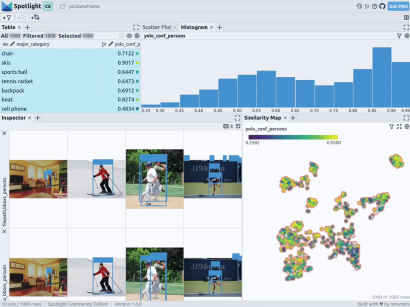
当然,上述简短的分析也表明了,此类模型在如下场景中会遇到系统性的问题:
- 由于列车体积庞大,站在车厢外的人显得非常渺小
- 对于巴士和其他大型车辆而言,车内的人员几乎看不到
- 有人站在飞机的外面
- 食物的特写图片上有人的手或手指
您可以判断这些问题是否真的会影响您的人员检测目标,如果是的话,则应考虑使用额外的训练数据,来增强数据集,以优化模型在这些特定场景中的性能。
小结
综上所述,预训练模型和 Spotlight 等工具的使用,可以让我们的对象检测可视化过程变得更加容易,进而增强数据科学的工作流程。您可以使用自己的数据去尝试和体验上述代码。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:How to Explore and Visualize ML-Data for Object Detection in Images,作者:Markus Stoll
链接:https://itnext.io/how-to-explore-and-visualize-ml-data-for-object-detection-in-images-88e074f46361。
위 내용은 이미지의 객체 감지를 위한 ML 데이터를 탐색하고 시각화하는 방법의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

 Gemma Scope : AI의 사고 과정으로 들여다 보는 Google의 현미경Apr 17, 2025 am 11:55 AM
Gemma Scope : AI의 사고 과정으로 들여다 보는 Google의 현미경Apr 17, 2025 am 11:55 AM젬마 범위로 언어 모델의 내부 작업 탐색 AI 언어 모델의 복잡성을 이해하는 것은 중요한 도전입니다. 포괄적 인 툴킷 인 Gemma Scope의 Google 릴리스는 연구원에게 강력한 강력한 방법을 제공합니다.
 비즈니스 인텔리전스 분석가는 누구이며 하나가되는 방법은 무엇입니까?Apr 17, 2025 am 11:44 AM
비즈니스 인텔리전스 분석가는 누구이며 하나가되는 방법은 무엇입니까?Apr 17, 2025 am 11:44 AM비즈니스 성공 잠금 해제 : 비즈니스 인텔리전스 분석가가되는 가이드 원시 데이터를 조직의 성장을 이끌어내는 실행 가능한 통찰력으로 바꾸는 것을 상상해보십시오. 이것은 비즈니스 인텔리전스 (BI) 분석가의 힘 - GU에서 중요한 역할입니다.
 SQL에서 열을 추가하는 방법? - 분석 VidhyaApr 17, 2025 am 11:43 AM
SQL에서 열을 추가하는 방법? - 분석 VidhyaApr 17, 2025 am 11:43 AMSQL의 Alter Table 문 : 데이터베이스에 열을 동적으로 추가 데이터 관리에서 SQL의 적응성이 중요합니다. 데이터베이스 구조를 즉시 조정해야합니까? Alter Table 문은 솔루션입니다. 이 안내서는 Colu를 추가합니다
 비즈니스 분석가 대 데이터 분석가Apr 17, 2025 am 11:38 AM
비즈니스 분석가 대 데이터 분석가Apr 17, 2025 am 11:38 AM소개 두 전문가가 중요한 프로젝트에 대해 협력하는 번화 한 사무실을 상상해보십시오. 비즈니스 분석가는 회사의 목표, 개선 영역을 식별하며 시장 동향과의 전략적 조정을 보장합니다. 시무
 Excel의 Count와 Counta는 무엇입니까? - 분석 VidhyaApr 17, 2025 am 11:34 AM
Excel의 Count와 Counta는 무엇입니까? - 분석 VidhyaApr 17, 2025 am 11:34 AMExcel 데이터 계산 및 분석 : 카운트 및 카운트 기능에 대한 자세한 설명 정확한 데이터 계산 및 분석은 특히 큰 데이터 세트로 작업 할 때 Excel에서 중요합니다. Excel은이를 달성하기위한 다양한 기능을 제공하며, 카운트 및 카운타 기능은 다른 조건에서 셀 수를 계산하기위한 핵심 도구입니다. 두 기능 모두 셀을 계산하는 데 사용되지만 설계 목표는 다른 데이터 유형을 대상으로합니다. Count 및 Counta 기능의 특정 세부 사항을 파고 고유 한 기능과 차이점을 강조하고 데이터 분석에 적용하는 방법을 배우겠습니다. 핵심 포인트 개요 수를 이해하고 쿠션하십시오
 Chrome은 AI와 함께 여기에 있습니다 : 매일 새로운 것을 경험하고 있습니다 !!Apr 17, 2025 am 11:29 AM
Chrome은 AI와 함께 여기에 있습니다 : 매일 새로운 것을 경험하고 있습니다 !!Apr 17, 2025 am 11:29 AMChrome 's AI Revolution : 개인화되고 효율적인 탐색 경험 인공 지능 (AI)은 우리의 일상 생활을 빠르게 변화시키고 있으며 Chrome은 웹 브라우징 경기장에서 요금을 주도하고 있습니다. 이 기사는 흥분을 탐구합니다
 AI '의 인간 측면 : 웰빙과 4 배의 결론Apr 17, 2025 am 11:28 AM
AI '의 인간 측면 : 웰빙과 4 배의 결론Apr 17, 2025 am 11:28 AM재구성 영향 : 4 배의 결론 너무 오랫동안 대화는 AI의 영향에 대한 좁은 견해로 인해 주로 이익의 결론에 중점을 두었습니다. 그러나보다 전체적인 접근 방식은 BU의 상호 연결성을 인식합니다.
 5 게임 변화 양자 컴퓨팅 사용 사례에 대해 알아야합니다.Apr 17, 2025 am 11:24 AM
5 게임 변화 양자 컴퓨팅 사용 사례에 대해 알아야합니다.Apr 17, 2025 am 11:24 AM상황이 그 시점을 꾸준히 움직이고 있습니다. 양자 서비스 제공 업체와 신생 기업에 쏟아지는 투자는 업계의 중요성을 이해하고 있음을 보여줍니다. 그리고 점점 더 많은 실제 사용 사례가 그 가치를 보여주기 위해 떠오르고 있습니다.


핫 AI 도구

Undresser.AI Undress
사실적인 누드 사진을 만들기 위한 AI 기반 앱

AI Clothes Remover
사진에서 옷을 제거하는 온라인 AI 도구입니다.

Undress AI Tool
무료로 이미지를 벗다

Clothoff.io
AI 옷 제거제

AI Hentai Generator
AI Hentai를 무료로 생성하십시오.

인기 기사
뜨거운 도구

메모장++7.3.1
사용하기 쉬운 무료 코드 편집기

Atom Editor Mac 버전 다운로드
가장 인기 있는 오픈 소스 편집기

Eclipse용 SAP NetWeaver 서버 어댑터
Eclipse를 SAP NetWeaver 애플리케이션 서버와 통합합니다.

SecList
SecLists는 최고의 보안 테스터의 동반자입니다. 보안 평가 시 자주 사용되는 다양한 유형의 목록을 한 곳에 모아 놓은 것입니다. SecLists는 보안 테스터에게 필요할 수 있는 모든 목록을 편리하게 제공하여 보안 테스트를 더욱 효율적이고 생산적으로 만드는 데 도움이 됩니다. 목록 유형에는 사용자 이름, 비밀번호, URL, 퍼징 페이로드, 민감한 데이터 패턴, 웹 셸 등이 포함됩니다. 테스터는 이 저장소를 새로운 테스트 시스템으로 간단히 가져올 수 있으며 필요한 모든 유형의 목록에 액세스할 수 있습니다.

VSCode Windows 64비트 다운로드
Microsoft에서 출시한 강력한 무료 IDE 편집기

