
OpenAI를 물리치고 가중치, 데이터, 코드까지 모두 오픈소스로 완벽하게 재현할 수 있는 임베딩 모델인 노믹 임베드(Nomic Embed)가 나왔습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-02-04 09:54:151547검색
일주일 전, OpenAI가 사용자들에게 혜택을 주었습니다. 그들은 GPT-4가 게으르게 되는 문제를 해결하고 더 작고 효율적인 텍스트 임베딩-3-소형 임베딩 모델을 포함하여 5개의 새로운 모델을 도입했습니다.
임베딩은 자연어, 코드 등의 개념을 표현하는 데 사용되는 일련의 숫자입니다. 이는 기계 학습 모델 및 기타 알고리즘이 콘텐츠가 어떻게 관련되어 있는지 더 잘 이해하고 클러스터링 또는 검색과 같은 작업을 더 쉽게 수행하는 데 도움이 됩니다. NLP 분야에서는 임베딩이 매우 중요한 역할을 합니다.
그러나 OpenAI의 임베딩 모델은 모든 사람이 무료로 사용할 수 있는 것은 아닙니다. 예를 들어 text-embedding-3-small은 1,000개 토큰당 $0.00002를 청구합니다.
이제 text-embedding-3-small보다 더 나은 임베딩 모델이 무료로 제공됩니다.
AI 스타트업 노믹 AI(Nomic AI)는 최근 오픈 소스, 오픈 데이터, 오픈 가중치, 오픈 트레이닝 코드인 최초의 임베딩 모델인 노믹 임베드(Nomic Embed)를 출시했습니다. 모델은 8192의 컨텍스트 길이로 완전히 재현 가능하고 감사 가능합니다. Nomic Embed는 단기 및 장기 컨텍스트 벤치마크 모두에서 OpenAI의 text-embeding-3-small 및 text-embedding-ada-002 모델을 능가했습니다. 이번 성과는 임베디드 모델 분야에서 Nomic AI의 중요한 진전을 의미합니다.

텍스트 임베딩은 최신 NLP 애플리케이션의 핵심 구성 요소로, LLM 및 의미 체계 검색을 지원하는 RAG(Retrieval Augmentation Generation) 기능을 제공합니다. 문장이나 문서의 의미 정보를 저차원 벡터로 인코딩하고 이를 데이터 시각화, 분류, 정보 검색을 위한 클러스터링 등 다운스트림 애플리케이션에 적용해 보다 효율적인 처리가 가능하게 하는 기술이다. 현재 OpenAI의 text-embedding-ada-002는 가장 널리 사용되는 긴 컨텍스트 텍스트 임베딩 모델 중 하나이며 최대 8192개의 컨텍스트 길이를 지원합니다. 그러나 불행하게도 Ada는 비공개 소스이며 교육 데이터를 감사할 수 없으므로 신뢰성이 제한됩니다. 그럼에도 불구하고 이 모델은 여전히 널리 사용되고 있으며 많은 NLP 작업에서 잘 수행됩니다. 앞으로는 더욱 투명하고 감사 가능한 텍스트 임베딩 모델을 개발하여 신뢰도를 높일 수 있기를 바랍니다. 이는 NLP 분야의 발전을 촉진하고 다양한 애플리케이션에 보다 효율적이고 정확한 텍스트 처리 기능을 제공하는 데 도움이 될 것입니다.
E5-Mistral 및 jina-embeddings-v2-base-en과 같은 최고 성능의 오픈 소스 긴 컨텍스트 텍스트 임베딩 모델에는 몇 가지 제한 사항이 있을 수 있습니다. 한편, 모델의 크기가 크기 때문에 일반적인 사용에는 적합하지 않을 수 있습니다. 반면에 이러한 모델은 OpenAI 대응 모델의 성능 수준을 능가하지 못할 수도 있습니다. 따라서 특정 작업에 적합한 모델을 선택할 때 이러한 요소를 고려해야 합니다.
Nomic-embed의 출시로 인해 이러한 상황이 바뀌었습니다. 모델에는 1억 3700만 개의 매개변수만 있어서 배포가 매우 쉽고 5일 안에 학습할 수 있습니다.

논문 주소: https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf
논문 제목: Nomic Embed: 재현 가능한 긴 컨텍스트 텍스트 임베더 훈련
프로젝트 주소: https://github.com/nomic-ai/contrastors
How to build nomic-embed
기존 텍스트 인코더의 주요 단점 중 하나는 시퀀스 길이가 제한된다는 것입니다. 512 토큰으로 제한됩니다. 더 긴 시퀀스에 대한 모델을 훈련하려면 가장 먼저 해야 할 일은 긴 시퀀스 길이를 수용할 수 있도록 BERT를 조정하는 것입니다. 이 연구의 목표 시퀀스 길이는 8192입니다.
컨텍스트 길이가 2048인 BERT 교육
이 연구는 노믹 임베드를 교육하기 위해 다단계 대조 학습 파이프라인을 따릅니다. 먼저, 연구에서는 BERT 초기화를 수행했습니다. bert-base는 최대 512개의 토큰의 컨텍스트 길이만 처리할 수 있기 때문에 연구에서는 2048개의 토큰(nomic-bert-2048)으로 자체 BERT를 훈련하기로 결정했습니다.
MosaicBERT에서 영감을 받아 연구팀은 다음을 포함하여 BERT의 교육 프로세스를 일부 수정했습니다.
- 회전된 위치 임베딩을 사용하여 컨텍스트 길이 추정을 허용합니다.
- 모델 성능을 향상시키기 위해 SwiGLU 활성화를 사용합니다.
- 드롭아웃을 0으로 설정합니다.
다음과 같은 교육 최적화를 수행했습니다.
- Deepspeed 및 FlashAttention을 사용하여 교육합니다.
- BF16 정확도로 교육합니다.
- 어휘(vocab) 크기를 64의 배수로 늘립니다. ;
- 훈련용 배치 크기는 4096입니다.
- 마스킹 언어 모델링 과정에서 마스킹 비율은 15%가 아닌 30%입니다.
- 다음 문장 예측 대상은 사용되지 않습니다.
학습 시 이 연구에서는 모든 단계를 최대 시퀀스 길이 2048로 학습하고, 추론 중에 동적 NTK 보간법을 사용하여 시퀀스 길이 8192로 확장합니다.
Experiments
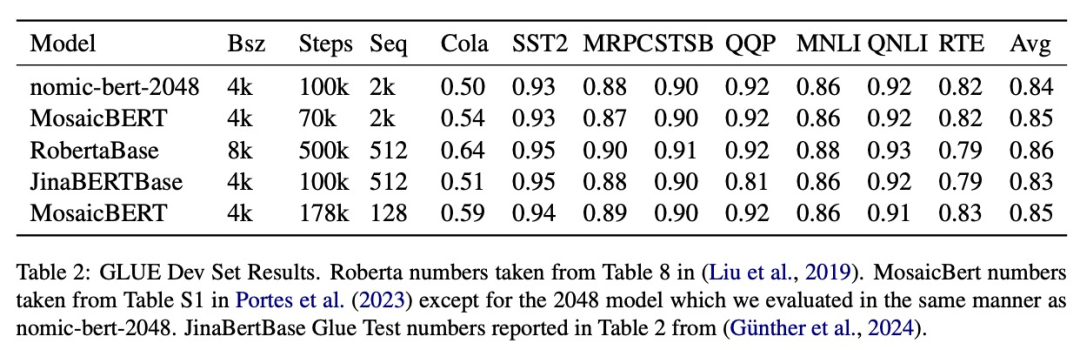
이 연구는 표준 GLUE 벤치마크에서 nomic-bert-2048의 품질을 평가하고 다른 BERT 모델과 동등한 성능을 발휘하지만 컨텍스트 길이가 훨씬 더 길다는 장점이 있음을 발견했습니다.
Nomic-embed의 비교 훈련
이 연구에서는 nomic-bert-2048을 사용하여 nomic-embed의 훈련을 초기화합니다. 비교 데이터 세트는 약 2억 3,500만 개의 텍스트 쌍으로 구성되어 있으며, 수집 과정에서 Nomic Atlas를 사용하여 품질을 광범위하게 검증했습니다.
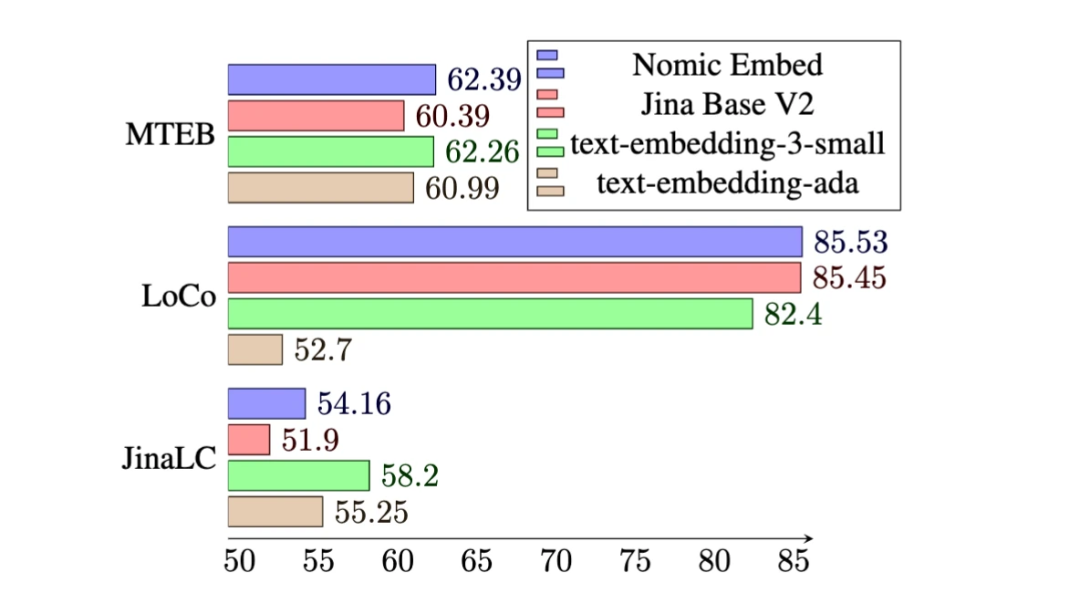
MTEB 벤치마크에서 nomic-embed는 text-embedding-ada-002 및 jina-embeddings-v2-base-en보다 성능이 뛰어납니다.
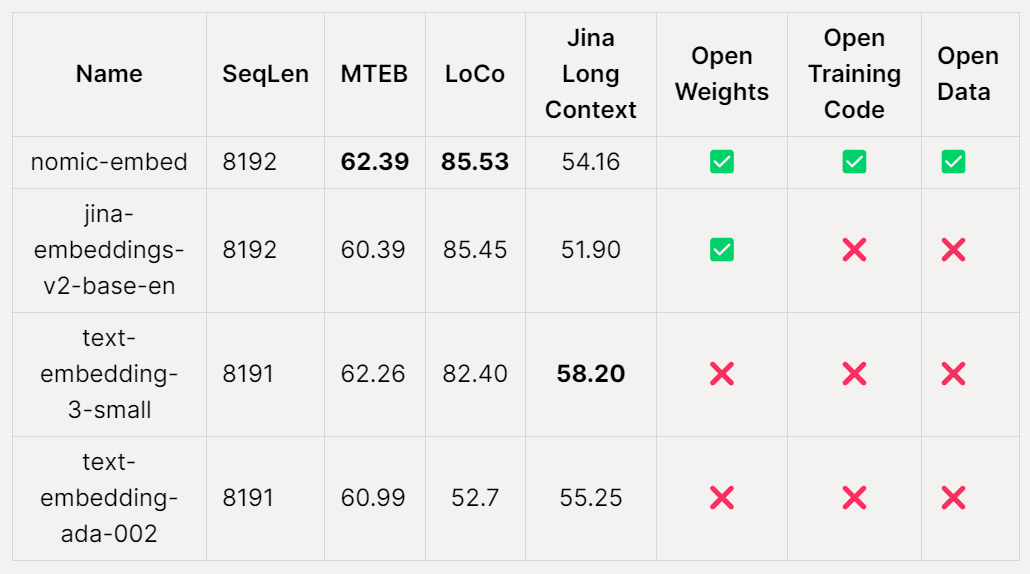
그러나 MTEB는 긴 컨텍스트 작업을 평가할 수 없습니다. 따라서 본 연구에서는 최근 출시된 LoCo 벤치마크와 Jina Long Context 벤치마크를 대상으로 nomic-embed를 평가하였다.
LoCo 벤치마크의 경우 연구는 매개변수 범주와 감독 환경 또는 비지도 환경에서 평가가 수행되는지 여부에 따라 별도로 평가됩니다.
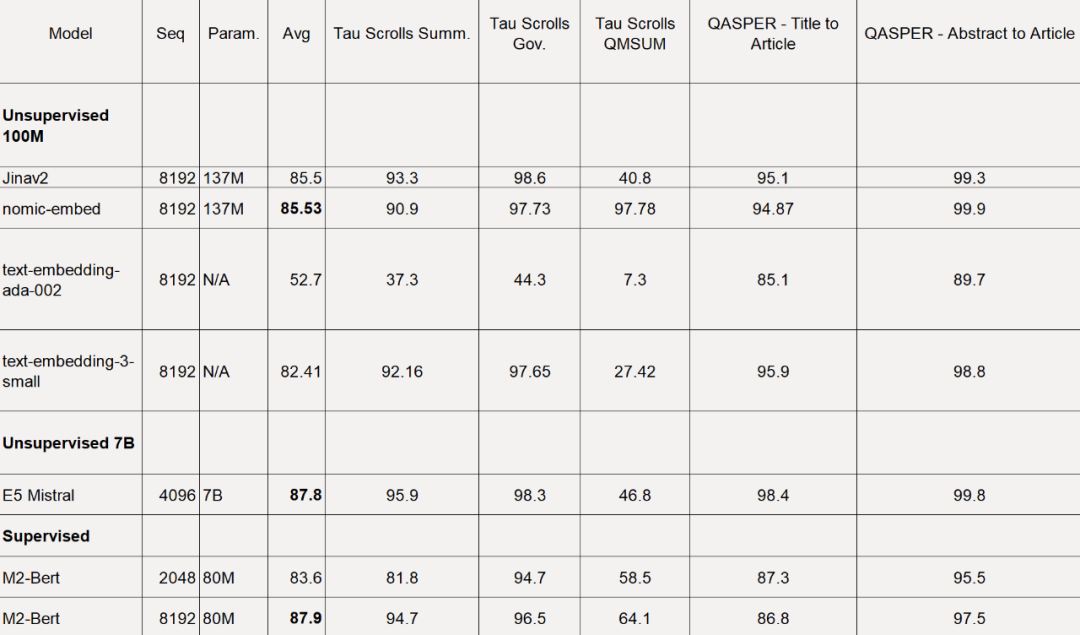
아래 표에서 볼 수 있듯이 Nomic Embed는 100M 매개변수 비지도 모델 중 가장 성능이 좋은 모델입니다. 특히, Nomic Embed는 7B 매개변수 범주에서 최고 성능을 발휘하는 모델뿐만 아니라 특히 LoCo 벤치마크를 위해 감독 환경에서 훈련된 모델과 비슷합니다.
Jina Long Context 벤치마크에서 전반적인 Nomic Embed의 성능도 수행합니다. jina-embeddings-v2-base-en보다 우수하지만 Nomic Embed는 이 벤치마크에서 OpenAI ada-002 또는 text-embedding-3-small보다 성능이 좋지 않습니다.
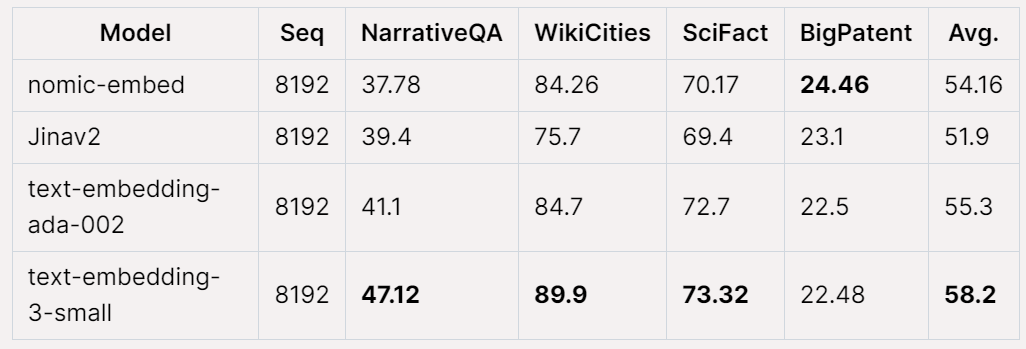
전체적으로 Nomic Embed 2/3 벤치마크에서 OpenAI Ada-002 및 text-embedding-3-small을 능가합니다.
연구에 따르면 Nomic Embed를 사용하는 가장 좋은 옵션은 Nomic Embedding API이며 API를 얻는 방법은 다음과 같습니다.

마지막으로 데이터 액세스: 전체 데이터에 액세스하기 위해 연구에서는 사용자에게 Cloudflare R2(AWS S3와 유사한 개체 스토리지 서비스) 액세스 키를 제공했습니다. 액세스 권한을 얻으려면 사용자는 먼저 Nomic Atlas 계정을 만들고 대조 저장소의 지침을 따라야 합니다.
콘트라스터 주소: https://github.com/nomic-ai/contrastors?tab=readme-ov-file#data-access
위 내용은 OpenAI를 물리치고 가중치, 데이터, 코드까지 모두 오픈소스로 완벽하게 재현할 수 있는 임베딩 모델인 노믹 임베드(Nomic Embed)가 나왔습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!