
여러 개의 이기종 대형 모델을 융합하면 놀라운 결과가 나옵니다.

- PHPz앞으로
- 2024-01-29 09:12:281236검색
LLaMA, Mistral 등 대규모 언어 모델의 성공으로 많은 기업에서 자체적인 대규모 언어 모델을 만들기 시작했습니다. 그러나 처음부터 새 모델을 훈련하는 것은 비용이 많이 들고 중복된 기능이 있을 수 있습니다.
최근 쑨원대학교와 Tencent AI Lab의 연구원들은 "다수의 이종 대형 모델을 융합"하는 데 사용되는 FuseLLM을 제안했습니다.
기존의 모델 통합 및 가중치 병합 방법과 달리 FuseLLM은 여러 이질적인 대규모 언어 모델에 대한 지식을 융합하는 새로운 방법을 제공합니다. 여러 대형 언어 모델을 동시에 배포하거나 모델 결과를 병합해야 하는 대신 FuseLLM은 경량 연속 교육 방법을 사용하여 개별 모델의 지식과 기능을 융합된 대형 언어 모델로 전송합니다. 이 접근 방식의 독특한 점은 추론 시 여러 이질적인 대규모 언어 모델을 사용하고 해당 지식을 융합 모델로 외부화할 수 있는 능력입니다. 이러한 방식으로 FuseLLM은 모델의 성능과 효율성을 효과적으로 향상시킵니다.
이 논문은 최근 arXiv에 게재되었으며 네티즌들로부터 많은 관심과 전달을 받았습니다.

누군가 다른 언어로 모델을 훈련시키는 것이 재미있을 것이라고 생각했고 저도 그것에 대해 생각해 왔습니다.
현재 이 논문은 ICLR 2024에 승인되었습니다.

- 논문 제목: Knowledge Fusion of Large Language Models
- 논문 주소: https://arxiv.org/abs/2401.10491
- 종이 창고: https://github.com/fanqiwan/FuseLLM
방법 소개
FuseLLM의 핵심은 동일한 입력에 대해 확률 분포 표현의 관점에서 대규모 언어 모델의 융합을 탐색하는 것입니다. 텍스트, 저자 다양한 대규모 언어 모델에 의해 생성된 표현은 이러한 텍스트를 이해하는 데 있어 고유한 지식을 반영하는 것으로 생각됩니다. 따라서 FuseLLM은 먼저 여러 소스 대규모 언어 모델을 사용하여 표현을 생성하고, 집단적 지식과 각각의 장점을 외부화한 다음, 생성된 여러 표현을 통합하여 서로 보완하고, 마지막으로 경량 연속 학습을 통해 대상 대규모 언어 모델로 마이그레이션합니다. 아래 그림은 FuseLLM 방법의 개요를 보여줍니다.
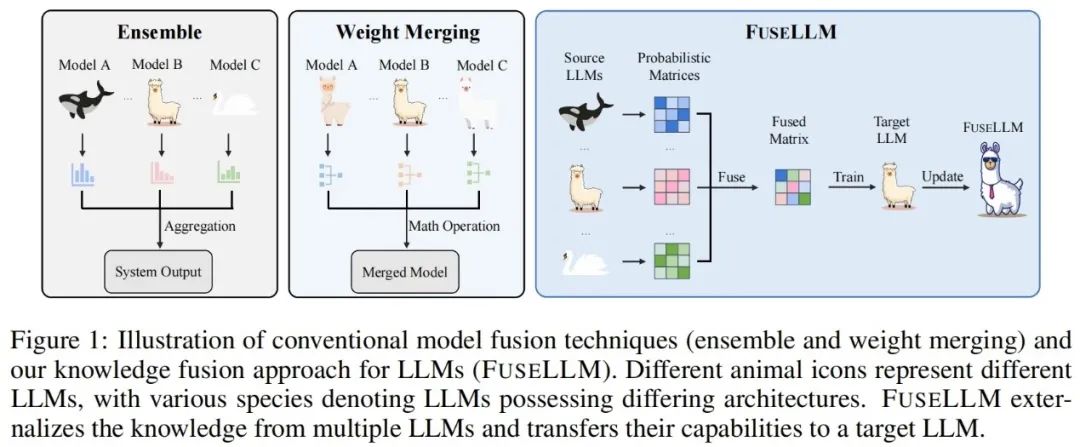
여러 이기종 대형 언어 모델의 토크나이저 및 어휘 목록의 차이점을 고려할 때 단어 분할 결과를 정렬하는 방법은 여러 표현을 융합할 때 핵심입니다. FuseLLM은 토큰 수준의 완전한 일치를 기반으로 합니다. 최소 편집 거리를 기반으로 한 정렬은 표현에서 사용 가능한 정보를 최대한 유지하도록 추가로 설계되었습니다.
각각의 장점을 유지하면서 여러 대규모 언어 모델의 집단적 지식을 결합하려면 융합된 모델 생성 표현 전략을 신중하게 설계해야 합니다. 특히 FuseLLM은 생성된 표현과 레이블 텍스트 간의 교차 엔트로피를 계산하여 다양한 대형 언어 모델이 이 텍스트를 얼마나 잘 이해하는지 평가한 다음 두 가지 교차 엔트로피 기반 융합 함수를 도입합니다.
- MinCE: 입력 다중 대형 모델은 현재 텍스트에 대한 표현을 생성하고 가장 작은 교차 엔트로피로 표현을 출력합니다.
- AvgCE: 현재 텍스트에 대해 여러 대형 모델에서 생성된 표현을 입력하고 교차에서 얻은 가중치를 기반으로 가중 평균 표현을 출력합니다.
연속 학습 단계에서 FuseLLM은 융합 표현을 목표로 사용하여 융합 손실을 계산하는 동시에 언어 모델 손실도 유지합니다. 최종 손실 함수는 융합 손실과 언어 모델 손실의 합입니다.
실험 결과
실험 부분에서 저자는 소스 모델이 구조나 기능 면에서 사소한 공통점을 갖는 일반적이지만 도전적인 대규모 언어 모델 융합 시나리오를 고려합니다. 구체적으로 7B 규모로 실험을 진행했으며, 융합할 대형 모델로 Llama-2, OpenLLaMA, MPT 등 대표적인 오픈소스 모델 3개를 선정했다.
저자는 일반 추론, 상식 추론, 코드 생성, 텍스트 생성, 명령 따르기 등의 시나리오에서 FuseLLM을 평가한 결과, 모든 소스 모델 및 지속적인 기준 모델 학습에 비해 상당한 성능 향상을 달성한 것으로 나타났습니다.
General Reasoning & Common Sense Reasoning
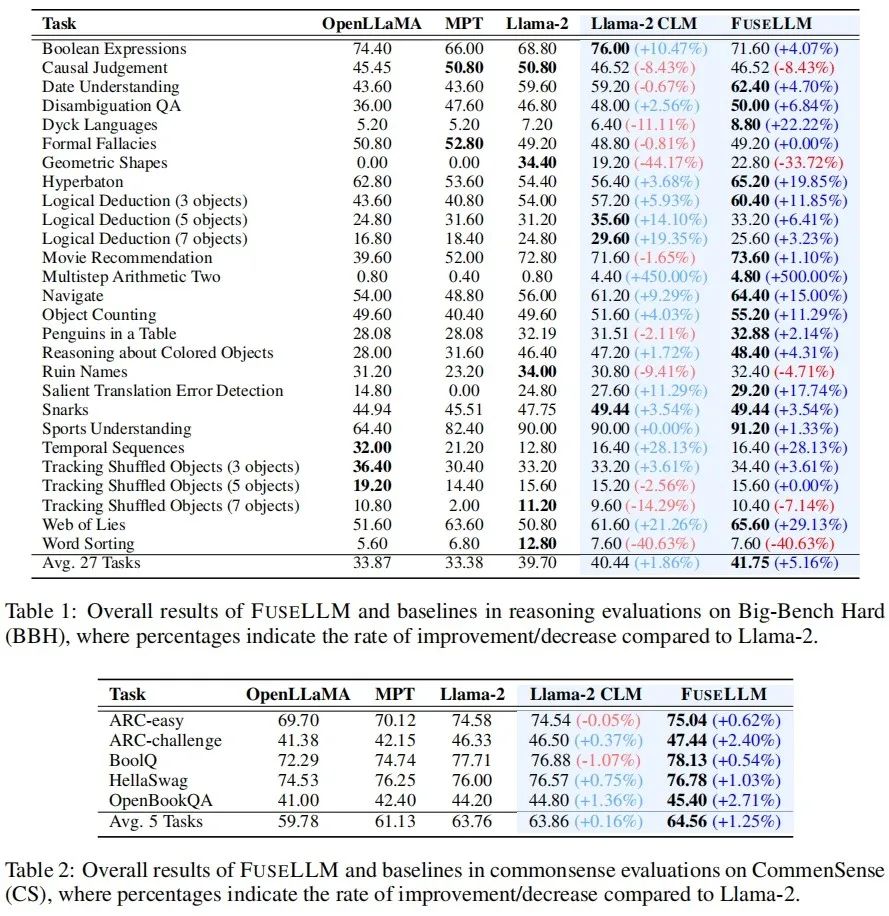
일반 추론 능력을 테스트하는 Big-Bench Hard Benchmark에서 지속적인 훈련 후 Llama-2 CLM을 27일 Llama-2와 비교합니다. 각 작업에서 평균 1.86%의 개선이 달성된 반면 FuseLLM은 Llama-2에 비해 5.16%의 개선을 달성했습니다. 이는 Llama-2 CLM보다 훨씬 더 나은 수준입니다. 이는 FuseLLM이 여러 대형 언어 모델의 장점을 결합하여 다음을 수행할 수 있음을 나타냅니다. 성능 향상을 달성합니다.
상식 추론 능력을 테스트하는 Common Sense Benchmark에서 FuseLLM은 모든 소스 모델과 기준 모델을 능가하며 모든 작업에서 최고의 성능을 달성했습니다.
코드 생성 및 텍스트 생성

코드 생성 기능을 테스트하는 MultiPL-E 벤치마크에서 FuseLLM은 10개 작업 중 9개 작업에서 Llama-2를 능가하여 6.36%. FuseLLM이 MPT와 OpenLLaMA를 능가하지 못한 이유는 Llama-2를 대상 대형 언어 모델로 사용했기 때문일 수 있습니다. 이 모델은 코드 생성 기능이 약하고 연속 학습 코퍼스에서 코드 데이터의 비율이 낮아 약 7.59%.
지식 질문 답변(TrivialQA), 독해력(DROP), 콘텐츠 분석(LAMBADA), 기계 번역(IWSLT2017) 및 정리 응용 프로그램(SciBench)을 측정하는 여러 텍스트 생성 벤치마크에서도 FuseLLM은 모든 작업에서 모든 소스를 능가했습니다. 80%의 작업에서 Llama-2 CLM을 능가했습니다.
지침 따르기

FuseLLM은 융합을 위해 여러 소스 모델의 표현만 추출한 다음 대상 모델을 지속적으로 학습하면 되므로 대규모 미세 조정에도 사용할 수 있습니다. 지침이 포함된 언어 모델. 지시 따르기 능력을 평가하는 Vicuna 벤치마크에서도 FuseLLM은 모든 소스 모델과 CLM을 능가하는 뛰어난 성능을 달성했습니다.
FuseLLM 대 지식 증류 & 모델 통합 & 가중치 병합
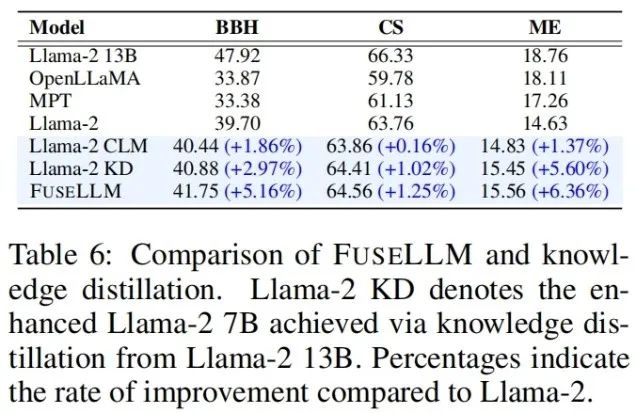
지식 증류도 대규모 언어 모델의 성능을 향상하기 위해 표현을 사용하는 방법이라는 점을 고려하여 저자는 FuseLLM을 결합합니다. 및 Llama-2 13B 증류된 Llama-2 KD를 비교하였다. 결과에 따르면 FuseLLM은 세 가지 7B 모델을 서로 다른 아키텍처와 융합하여 단일 13B 모델의 증류 성능을 능가하는 것으로 나타났습니다.

FuseLLM을 기존 융합 방법(예: 모델 앙상블 및 가중치 병합)과 비교하기 위해 저자는 여러 소스 모델이 동일한 구조의 기본 모델에서 나왔지만 서로 다른 말뭉치에 대해 지속적으로 훈련되는 시나리오를 시뮬레이션했습니다. , 다양한 테스트 벤치마크에서 다양한 방법의 복잡성을 테스트했습니다. 모든 융합 기술이 여러 소스 모델의 장점을 결합할 수 있지만 FuseLLM은 가장 낮은 평균 복잡도를 달성할 수 있음을 알 수 있습니다. 이는 FuseLLM이 모델 앙상블 및 가중치 병합 방법보다 소스 모델의 집단적 지식을 더 효과적으로 결합할 수 있는 잠재력이 있음을 나타냅니다.
마지막으로, 커뮤니티는 현재 대형 모델의 융합에 주목하고 있지만 현재 접근 방식은 대부분 가중치 병합을 기반으로 하며 다양한 구조와 크기의 모델 융합 시나리오로 확장될 수 없습니다. FuseLLM은 이종 모델 융합에 대한 예비 연구일 뿐이지만, 현재 기술 커뮤니티에 다양한 구조와 크기의 언어, 시각, 청각 및 다중 모드 대형 모델이 많이 있다는 점을 고려하면 이러한 이종 모델의 융합은 어떻게 될까요? 미래에 놀라운 성능이 터지나요? 기다려 보자!
위 내용은 여러 개의 이기종 대형 모델을 융합하면 놀라운 결과가 나옵니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!