본래의 의미를 바꾸지 않고 내용을 다시 작성하려면 언어를 중국어로 다시 작성해야 하며, 원래 문장이 나타날 필요는 없습니다
본 사이트 편집부
PowerInfer의 출현으로 소비자급 하드웨어에서 AI 실행이 더욱 효율적이 되었습니다
Shanghai Jiao Tong University 팀은 막 강력한 CPU/GPU LLM 고속 추론인 PowerInfer를 출시했습니다. 엔진. 
프로젝트 주소: https://github.com/SJTU-IPADS/PowerInfer
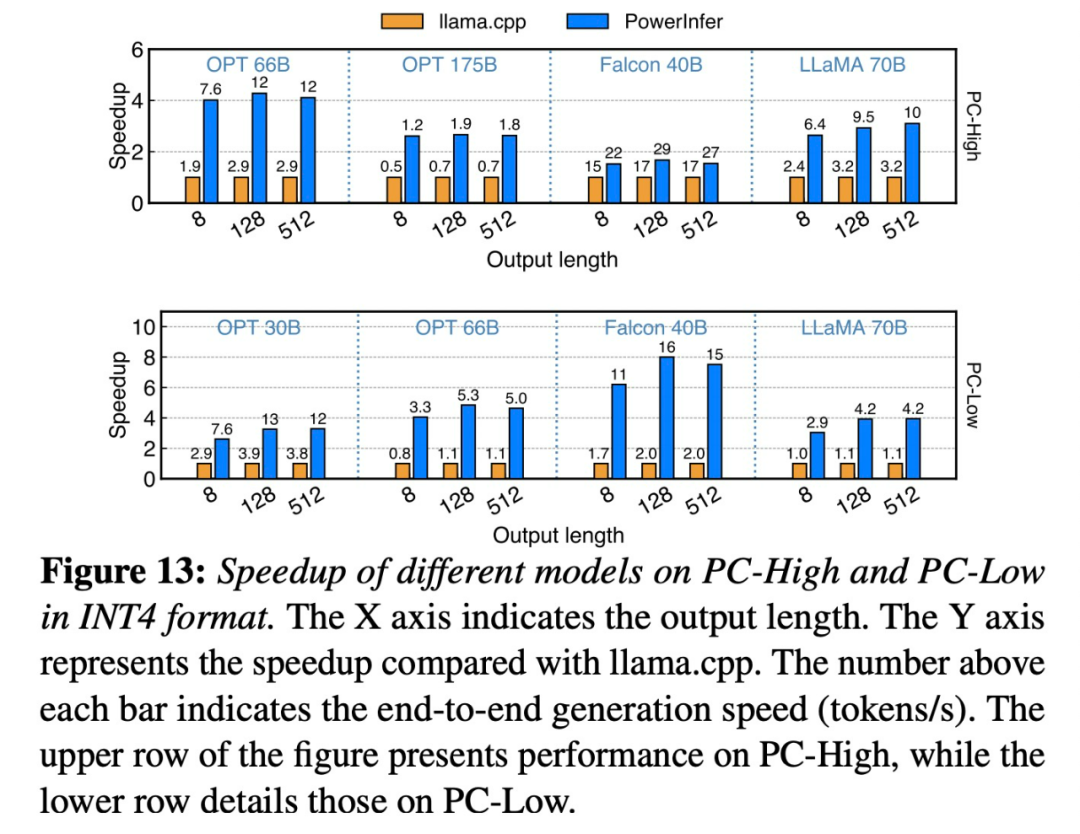
논문 주소: https://ipads.se. sj tu .edu.cn/_media/publications/powerinfer-20231219.pdfFalcon(ReLU)-40B-FP16을 실행하는 단일 RTX 4090(24G)에서 PowerInfer는 llama.cpp에 비해 11배의 속도 향상을 달성했습니다!
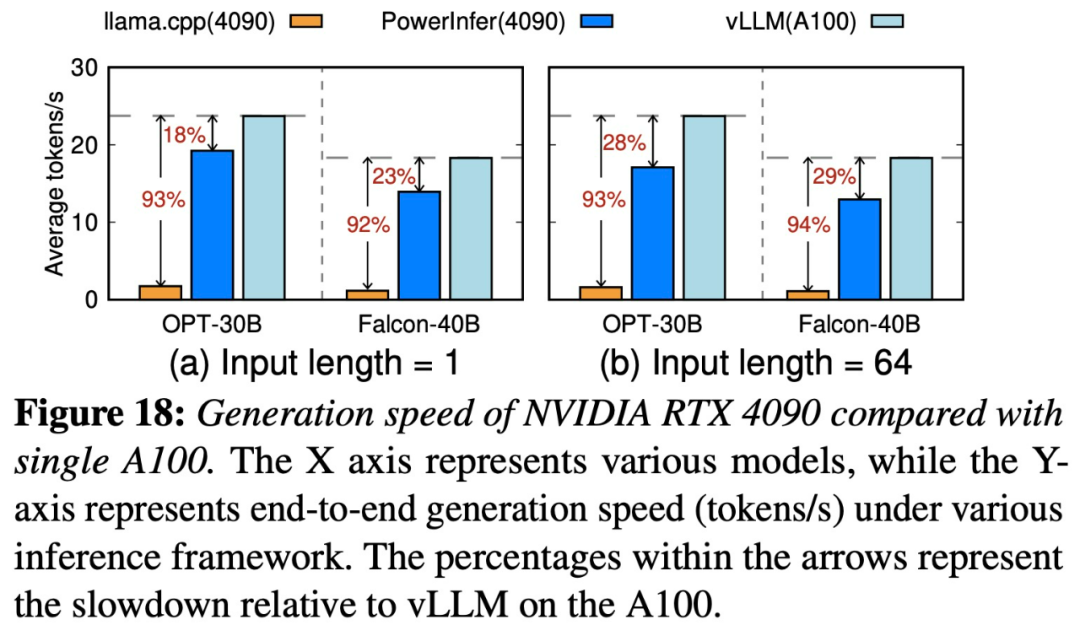
PowerInfer와 llama.cpp는 모두 동일한 하드웨어에서 실행되며 RTX 4090의 VRAM을 최대한 활용합니다. 단일 NVIDIA RTX 4090 GPU의 다양한 LLM 전반에 걸쳐 PowerInfer의 평균 토큰 생성 속도는 초당 13.20개 토큰이며, 최고치는 초당 29.08개 토큰으로, 이는 최고 서버급 A100보다 18%만 낮습니다. GPU.
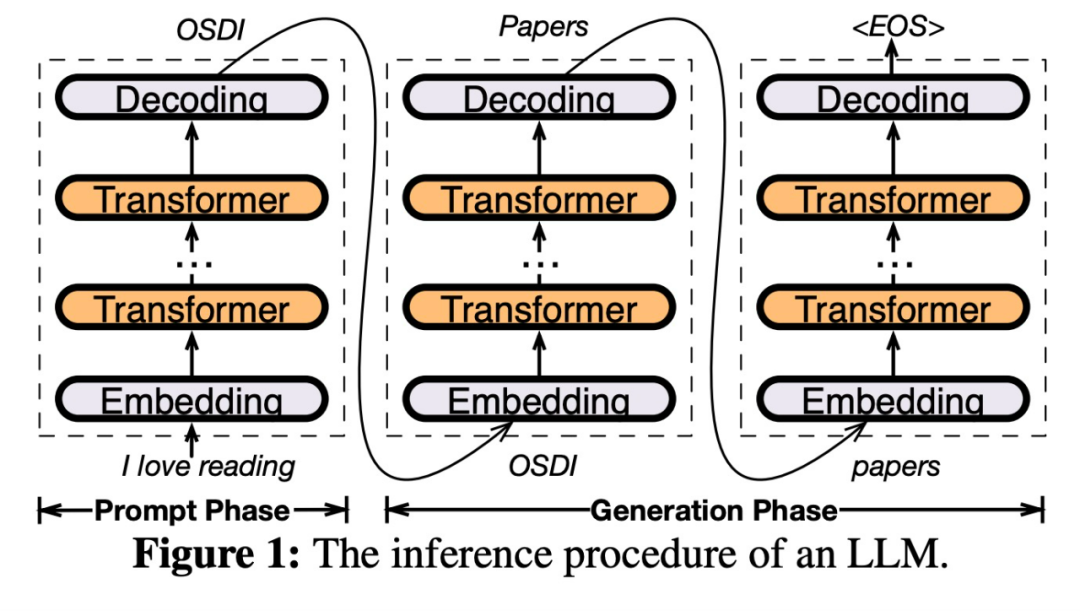
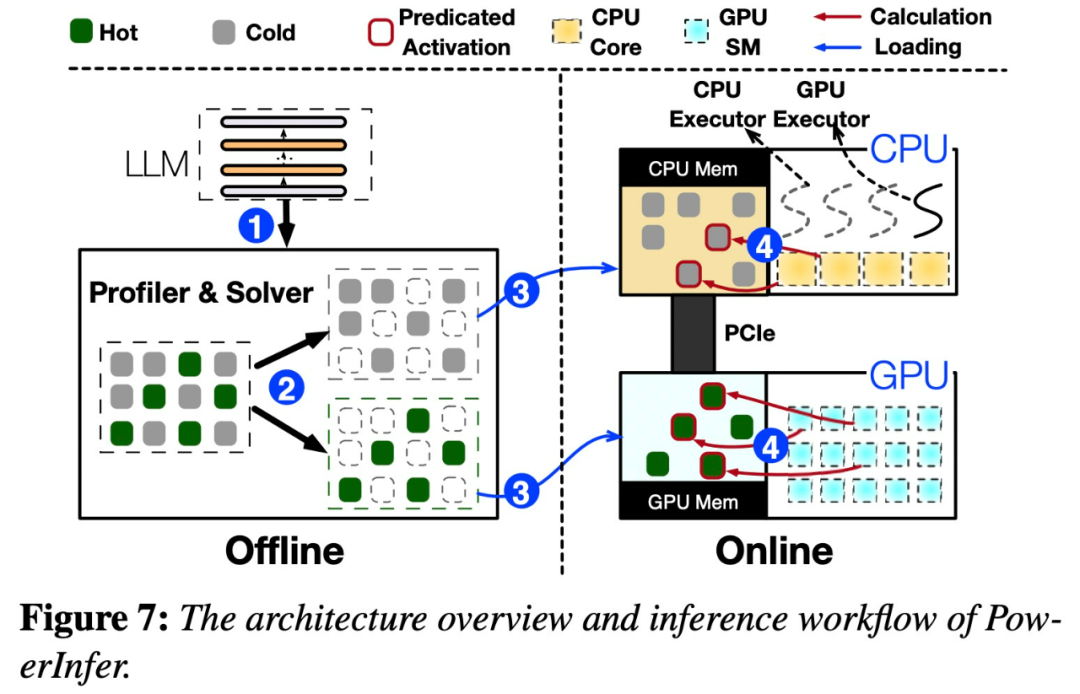
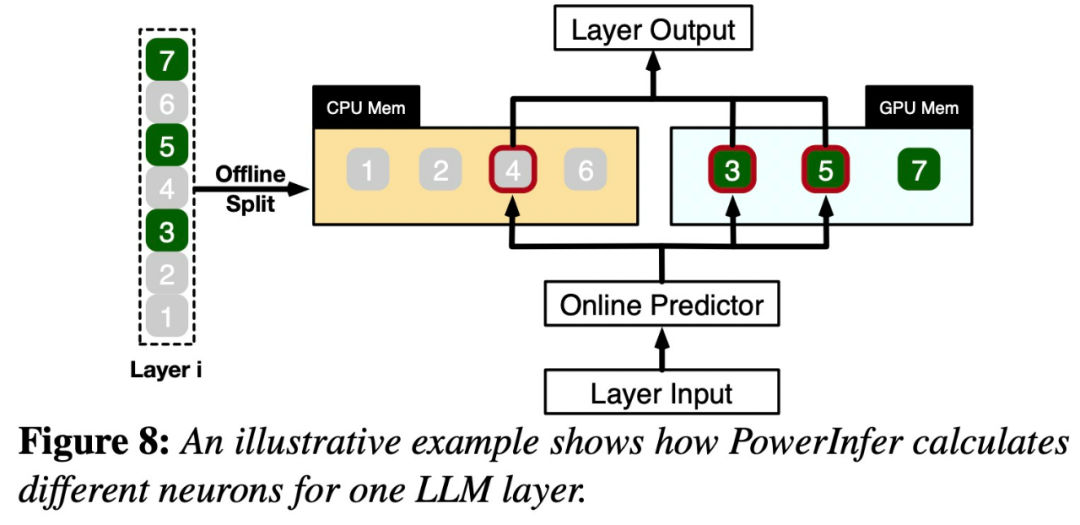
특히 PowerInfer는 로컬에 배포된 LLM을 위한 고속 추론 엔진입니다. GPU-CPU 하이브리드 추론 엔진을 설계하기 위해 LLM 추론의 높은 지역성을 활용합니다. 핫 활성화 뉴런은 빠른 액세스를 위해 GPU에 사전 로드되는 반면, 콜드 활성화 뉴런은 (대부분) CPU에서 계산됩니다. 이 접근 방식은 GPU 메모리 요구 사항과 CPU-GPU 데이터 전송을 크게 줄입니다. PowerInfer는 단일 소비자급 GPU가 장착된 개인용 컴퓨터(PC)에서 대규모 언어 모델(LLM)을 고속으로 실행할 수 있습니다. 이제 사용자는 Llama 2 및 Faclon 40B와 함께 PowerInfer를 사용할 수 있으며 Mistral-7B도 곧 지원될 예정입니다. PowerInfer 설계의 핵심은 신경 활성화의 거듭제곱 법칙 분포를 특징으로 하는 LLM 추론에 내재된 높은 수준의 지역성을 활용하는 것입니다.
아래 그림 7은 오프라인 및 온라인 구성 요소를 포함한 PowerInfer의 아키텍처 개요를 보여줍니다.
이 분포는 핫 뉴런이라고 하는 뉴런의 작은 하위 집합이 입력 전반에 걸쳐 일관되게 활성화되는 반면, 콜드 뉴런의 대부분은 특정 입력에 따라 달라짐을 보여줍니다. PowerInfer는 이 메커니즘을 활용하여 GPU-CPU 하이브리드 추론 엔진을 설계합니다.
PowerInfer는 적응형 예측 변수와 뉴런 인식 희소 연산자를 추가로 통합하여 뉴런 활성화 및 계산 희소성의 효율성을 최적화합니다. 이 연구를 본 네티즌들은 "4090 카드 한 장으로 175B 대형 모델을 달리는 건 더 이상 꿈이 아니다"라며 신이 났다.
위 내용은 Shanghai Jiao Tong University는 추론 엔진 PowerInfer를 출시했습니다. 토큰 생성률은 A100보다 18% 낮습니다. A100을 대체할 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!