
Google은 AI가 오류 수정 기능을 개선하는 데 도움이 되는 BIG-Bench Mistake 데이터 세트를 출시했습니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-01-16 18:57:16759검색
Google Research는 최근 자체 BIG-Bench 벤치마크와 새로 구축된 "BIG-Bench Mistake" 데이터 세트를 사용하여 인기 있는 언어 모델에 대한 평가 연구를 수행했습니다. 그들은 주로 언어 모델의 오류 확률과 오류 수정 능력에 중점을 두었습니다. 이 연구는 시장에서 언어 모델의 성능을 더 잘 이해하는 데 유용한 데이터를 제공합니다.
Google 연구원들은 대규모 언어 모델의 '오류 확률'과 '자기 수정 능력'을 평가하기 위해 'BIG-Bench Mistake'라는 특별한 벤치마크 데이터 세트를 만들었다고 밝혔습니다. 이는 과거에 이러한 주요 지표를 효과적으로 평가하고 테스트할 수 있는 해당 데이터 세트가 부족했기 때문입니다.
연구원들은 PaLM 언어 모델을 사용하여 자체 BIG-Bench 벤치마크 작업에서 5가지 작업을 실행하고, 생성된 "사고 사슬" 궤적을 "논리 오류" 부분에 추가하여 모델 정확도를 다시 테스트했습니다.
데이터 세트의 정확성을 높이기 위해 Google 연구원들은 위 과정을 반복하여 마침내 "BIG-Bench Mistake"라고 불리는 255개의 논리적 오류가 포함된 평가용 벤치마크 데이터 세트를 만들었습니다.
연구원들은 "BIG-Bench Mistake" 데이터 세트의 논리적 오류가 매우 명백하므로 언어 모델 테스트의 좋은 표준으로 사용될 수 있다고 지적했습니다. 이 데이터 세트는 모델이 단순한 오류로부터 학습하고 오류를 식별하는 능력을 점진적으로 향상시키는 데 도움이 됩니다.
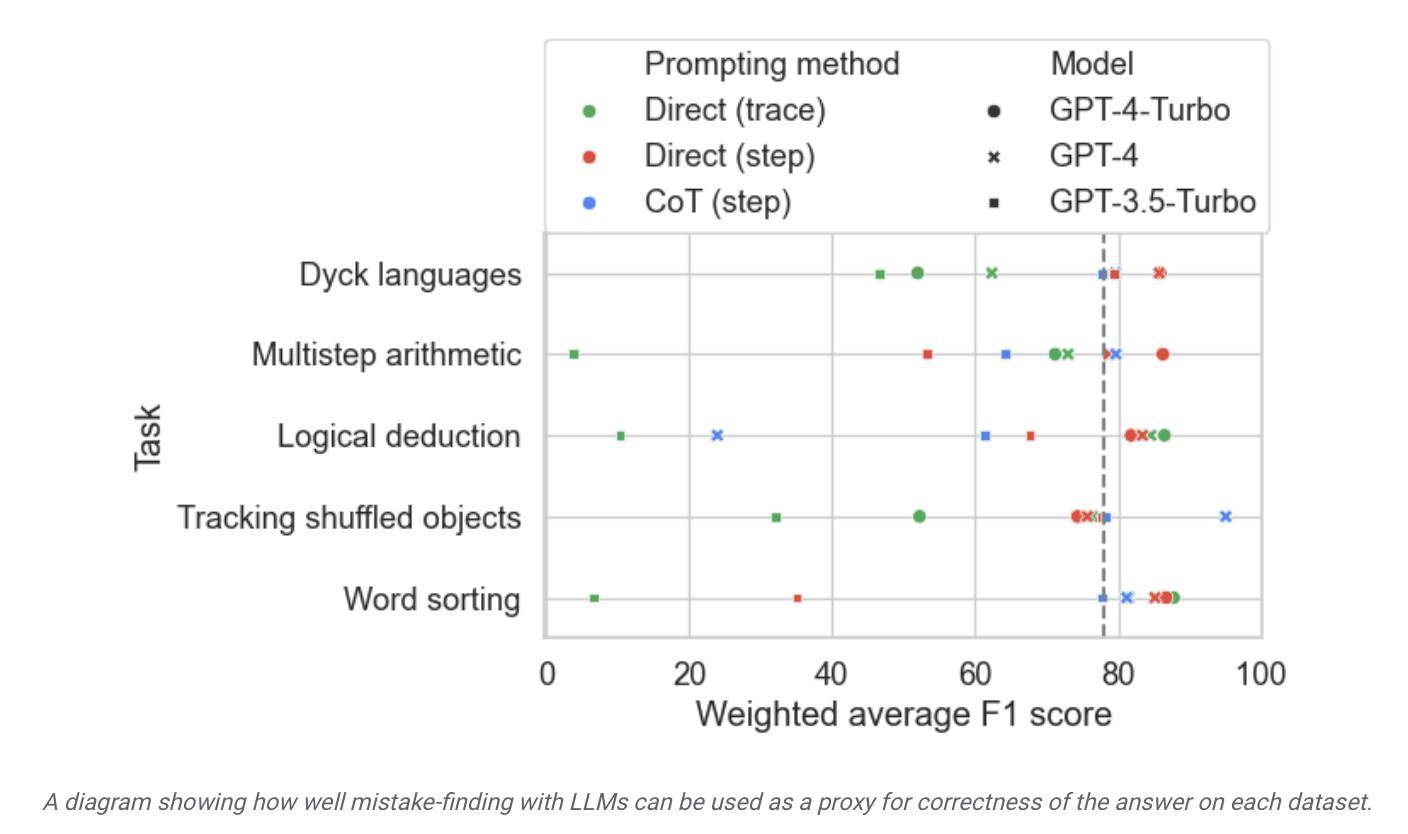
연구원들은 이 데이터 세트를 사용하여 시장에서 모델을 테스트한 결과 대부분의 언어 모델이 추론 과정에서 논리적 오류를 식별하고 스스로 수정할 수 있지만 이 과정은 그리 이상적이지 않다는 것을 발견했습니다. 모델이 출력하는 내용을 수정하려면 사람의 개입이 필요한 경우도 많습니다.
▲ 사진 출처 구글리서치 보도자료
보고서에 따르면 Google은 현재 가장 발전된 대형 언어 모델로 간주되지만 자체 수정 능력이 상대적으로 제한적이라고 주장합니다. 테스트에서 가장 성능이 좋은 모델은 논리적 오류의 52.9%만을 발견했습니다.

Google 연구자들은 또한 이 BIG-Bench Mistake 데이터 세트가 모델의 자체 수정 능력을 향상시키는 데 도움이 된다고 주장했습니다. 관련 테스트 작업에 대해 모델을 미세 조정한 후에는 "작은 모델이라도 일반적으로 샘플 프롬프트가 없는 대형 모델보다 더 나은 성능을 발휘합니다." " ".
이에 따르면 Google은 모델 오류 수정 측면에서 대규모 언어 모델이 '자체 오류 수정'을 학습하도록 하는 것과 비교하여 감독 전용 소규모 전용 모델을 배포하는 데 독점 소형 모델을 사용할 수 있다고 믿습니다. 대형 모델은 효율성을 향상하고 관련 AI 배포 비용을 줄이며 미세 조정을 더 쉽게 만드는 데 도움이 됩니다.
위 내용은 Google은 AI가 오류 수정 기능을 개선하는 데 도움이 되는 BIG-Bench Mistake 데이터 세트를 출시했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!