
OCR 인식의 원리와 응용 시나리오 살펴보기

- 王林앞으로
- 2024-01-14 22:36:051470검색

Labs Introduction
텍스트 인식 분야에서 매우 중요한 기술인 OCR(Optical Character Recognition) 기술은 일상생활에서 스크린샷 추출, 사진 검색 질문 등이 널리 사용되고 있습니다
Part 01, OCR이란 무엇입니까
OCR(광학 문자 인식)은 광학 및 컴퓨터 기술을 사용하여 인쇄되거나 손으로 쓴 텍스트 이미지를 컴퓨터에서 정확하고 읽을 수 있는 텍스트 형식으로 변환하는 컴퓨터 텍스트 인식 방법입니다. 인식과 적용. OCR 인식 기술은 현대 생활의 다양한 산업에서 점점 더 널리 사용되고 있습니다.
Part 02, OCR 기술의 원리
주요 내용은 다음과 같습니다. OCR 기술 전통적인 OCR과 딥 러닝 OCR에는 두 가지 학파가 있습니다.
OCR 기술 개발 초기에 기술자들은 이진화, 연결된 도메인 분석, 프로젝션 분석과 같은 이미지 처리 기술을 통계적 기계 학습(예: Adaboost 및 SVM)과 결합하여 이미지 텍스트 콘텐츠를 추출했습니다. 우리는 전통적인 OCR로 분류됩니다. 주요 특징은 이미지의 노이즈를 수정하고 줄이기 위해 복잡한 데이터 전처리 작업에 의존한다는 것입니다. 복잡한 장면에 대한 적응성의 중요성은 무시할 수 없습니다. 적응성은 변화하는 환경에서 중요한 능력입니다. 적응력이 좋은 사람은 새로운 상황과 요구 사항에 적응하고 변화에 빠르게 적응하며 문제에 대한 해결책을 찾을 수 있습니다. 적응성은 또한 개인 생활과 직업 생활에서 성공을 위한 핵심 요소 중 하나입니다. 그러므로 우리는 정확성과 응답속도가 떨어지는 변화하는 세상에 대처할 수 있는 적응력을 기르고 향상시키기 위해 노력해야 합니다.
AI 기술의 지속적인 발전에 힘입어 엔드투엔드 딥러닝 기반의 OCR 기술은 점차 성숙해졌습니다. 이 방식의 장점은 이미지 미리보기에 텍스트 자르기 링크를 명시적으로 도입할 필요가 없다는 점입니다. - 처리 단계이지만 텍스트 인식을 시퀀스 학습으로 변환 문제, 텍스트 분할을 딥러닝에 통합하는 것은 OCR 기술 향상과 향후 개발 방향에 큰 의미가 있습니다.
2.1 기존 OCR 인식 프로세스
전통적인 OCR 기술 처리 흐름도는 다음과 같습니다. 장치 , 종이의 매끄러움과 인쇄 품질, 화면의 명암 등 다양한 텍스트 매체에 간섭 요인이 있어 텍스트 왜곡이 발생하므로 전처리 단계에 들어갑니다. 이미지에 대한 밝기 조정, 이미지 향상, 노이즈 필터링 등의 전처리 방법을 사용합니다.

텍스트 및 이미지 수정
: 기울어진 텍스트를 수정하여 수평성을 보장합니다. 수정 방법에는 주로 수평 수정과 원근 수정이 포함됩니다.행과 열의 단일 단어 분할
: 전통적인 텍스트 인식은 단일 문자 인식을 기반으로 하며 분할 방법은 주로 연결된 도메인 윤곽선과 수직 투영 절단을 사용합니다.분류자 문자 인식
: HOG 및 Sift와 같은 특징 추출 알고리즘을 사용하여 문자에서 벡터 정보를 추출하고 SVM 알고리즘, 로지스틱 회귀, 지원 벡터 머신 등을 사용하여 훈련합니다.후처리
: 분류자의 분류가 반드시 완전히 정확하지는 않거나 문자 자르기 과정에 오류가 있으므로 통계적 언어 모델(예: 숨겨진 마르코프 체인, HMM) 또는 인공 추출 규칙 텍스트 결과에 대한 의미 오류 수정을 수행하는 언어 규칙 모델을 설계합니다.2.2 딥 러닝 OCR
Pictures현재 주류 딥 러닝 OCR 알고리즘은 텍스트 감지와 텍스트 인식의 두 단계를 별도로 모델링합니다.
텍스트 감지는 회귀 기반 방법과 분할 기반 방법으로 나눌 수 있습니다. 회귀 방법에는 이미지의 방향성 텍스트를 감지할 수 있지만 텍스트 영역의 불규칙성에 의해 영향을 받는 CTPN, Textbox 및 EAST와 같은 알고리즘이 포함됩니다. PSENet 알고리즘과 같은 분할 방법은 다양한 모양과 크기의 텍스트를 처리할 수 있지만 텍스트가 가까울수록 달라붙는 문제가 발생하기 쉽습니다. 다양한 방법에는 장단점이 있습니다
텍스트 인식 단계에서는 주로 CRNN과 ATTENTION이라는 두 가지 주요 기술을 사용하여 텍스트 인식을 시퀀스 학습 문제로 변환합니다. 두 기술 모두 특징 학습 단계에서 CNN+RNN 네트워크를 사용합니다. 구조상 차이점은 최종 출력 레이어(번역 레이어), 즉 네트워크가 학습한 시퀀스 특징 정보를 최종 인식 결과로 어떻게 변환하느냐에 있습니다. 또한 텍스트 감지와 텍스트 인식을 학습용 단일 네트워크 모델에 직접 통합하는 최신 엔드 투 엔드 알고리즘이 있습니다. 예를 들어 FOTS 및 Mask TextSpotter와 같은 알고리즘이 있습니다. 독립적인 텍스트 감지 및 텍스트 인식 방법에 비해 이 알고리즘은 인식 속도는 빠르지만 상대 정확도는 낮습니다 전통적인 인식 인공지능 딥러닝 인식 기술 기본 알고리즘 텍스트 감지 및 인식은 여러 단계와 하위 프로세스로 나누어져 있으며, 서로 다른 알고리즘을 조합하여 사용 이 모델의 목표는 탐지와 인식 프로세스를 융합하여 엔드투엔드를 달성하는 것입니다 stability 다단계 전체 안정성이 낮습니다 엔드 투 엔드 최적화 후 시스템 안정성이 크게 향상되었습니다 Recognition Accuracy 기존 시나리오에서는 정확도가 낮습니다. 장점 정확도가 높을수록 융합도가 깊을수록 정확도는 점차 감소합니다 인식 속도 Rec 인식 속도가 느려집니다 빠른 인식 Scenario 적응성의 중요성은 무시할 수 없습니다. 적응성은 변화하는 환경에서 중요한 능력입니다. 적응력이 좋은 사람은 새로운 상황과 요구 사항에 적응하고 변화에 빠르게 적응하며 문제에 대한 해결책을 찾을 수 있습니다. 적응성은 또한 개인 생활과 직업 생활에서 성공을 위한 핵심 요소 중 하나입니다. 그러므로 우리는 끊임없이 변화하는 세상에 대처할 수 있는 적응력을 기르고 향상시키기 위해 노력해야 합니다. 약함, 표준 인쇄 형식에 적합 강력함, 복잡한 시나리오와 호환 가능, 모델 훈련에 의존 간섭 방지 입력 이미지에 대한 약하고 높은 요구 사항 강하고 모델 교육에 따라 다름 재현률: OCR 시스템이 올바르게 인식한 문자 수 대비 실제 문자 수의 비율을 말하며 시스템이 일부 문자를 인식하지 못했는지 여부를 측정하는 데 사용됩니다. 값이 높을수록 시스템의 문자 처리 능력이 향상됩니다. 정확도: OCR 시스템이 올바르게 인식한 문자 수와 시스템이 인식한 전체 문자 수의 비율을 말하며 시스템의 인식 결과가 실제로 몇 개나 맞는지 측정하는 데 사용됩니다. 값이 높을수록 시스템 성능이 더 좋아집니다. F1 값: 재현율과 정밀도를 결합한 평가 지표입니다. F1 값은 0에서 1 사이입니다. 값이 높을수록 시스템이 정밀도와 재현율 간의 균형을 더 잘 이룬 것입니다. Average Edit Distance(Average Edit Distance)는 OCR 인식 결과와 실제 텍스트 간의 차이 정도를 평가하는 데 사용되는 지표입니다. OCR as text 인식 이 분야의 주요 분야 중 하나이며, 앞으로도 여전히 광범위한 연구 방향과 개발 공간이 있습니다. 인식 정확도 측면에서는 더 스마트한 이미지 처리 기술과 더 강력한 딥러닝 모델을 연구하는 것이 여전히 시급합니다. 여러 언어와 글꼴을 포괄하는 인식이 더 보편적이고 복잡한 장면에 적응하는 능력을 향상시키는 것이 필요합니다. 한편, AR 번역, 자동 오류 정정, 텍스트 데이터의 데이터 정정 등 가상현실 기술과 증강현실 기술을 결합한 적용점을 더 많이 찾고 있다. 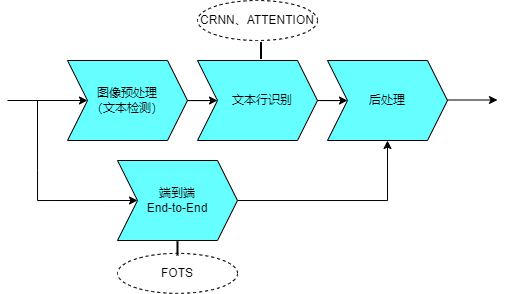
2.3 체계 비교
파트 03, 공통 OCR 평가 지표
Part 04, Application and Outlook
위 내용은 OCR 인식의 원리와 응용 시나리오 살펴보기의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!