
Windows에서 tesseract-ocr 4.00을 설치하고 구성하는 방법은 무엇입니까?

- 零下一度원래의
- 2017-06-23 14:09:144998검색
최근에는 텍스트 인식도 해야하고, 타인의 인터페이스를 직접 사용하는 것도 금지되어 오픈소스 라이브러리만 사용해보려고 합니다. tesseract-ocr은 HP의 오픈 소스 텍스트 인식 프로젝트로, 이미지 및 텍스트 인식 시스템을 신속하게 구축하고 이미지를 인식할 수 있는 OCR 시스템을 개발하는 데 도움이 됩니다. Windows 환경에서 개발하기 때문에 Windows 환경에 시스템을 설치해야 합니다.
1단계: 설치 패키지 다운로드
이에 따라 비공식 설치 패키지를 찾았는데 http://digi.bib.uni-mannheim.de/tesseract/ 64비트 설치 패키지만 본 것 같습니다. tesseract-ocr -setup-4.00.00dev.exe, 다운로드 후 직접 설치할 수 있지만 설치 디렉터리를 기억해 두세요. 환경 변수는 나중에 구성하겠습니다.
영어 이미지 및 텍스트 인식을 하지 않는 경우, 다른 언어의 인식 패키지도 다운로드해야 합니다.
간체 한자 인식 패키지:
번체 한자 인식 패키지:
2단계: 설치
다운받은 tesseract-ocr-setup-4.00.00dev.exe를 직접 실행하여 다음 단계, 다음 단계로 설치합니다.
3단계: 환경 변수 구성
참고: 내 시스템은 win7이고 다른 시스템도 Java 변수 구성과 마찬가지로 비슷해야 합니다.
설치 주소를 복사하세요. 내 시스템은 C:Program Files (x86)Tesseract -OCR에 설치되어 있습니다. 인터페이스는 다음과 같습니다:
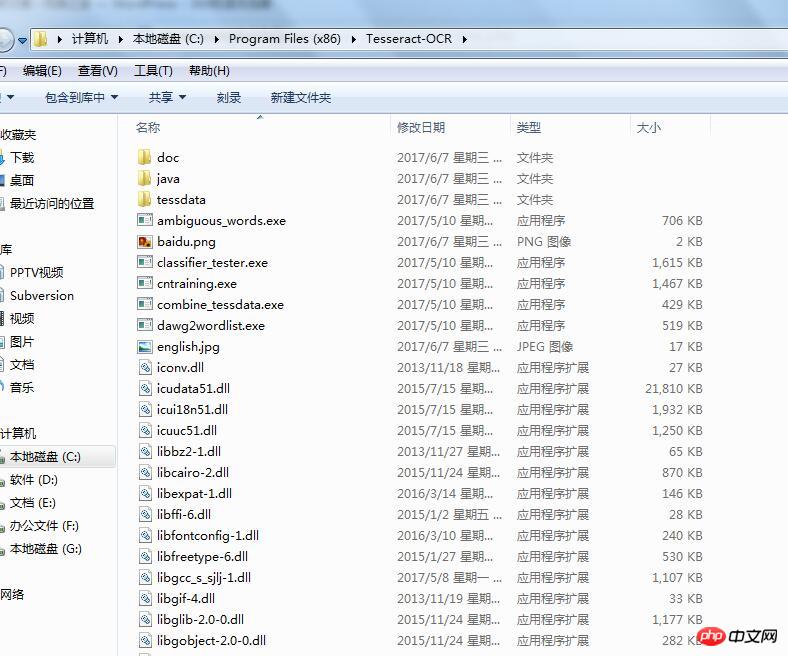
설치 경로 "C:Program Files (x86)Tesseract-OCR"을 복사하고 "제어판 시스템 및 보안 시스템"을 입력한 후
"시스템 보호"

를 클릭합니다. 다음 인터페이스로 이동하십시오.
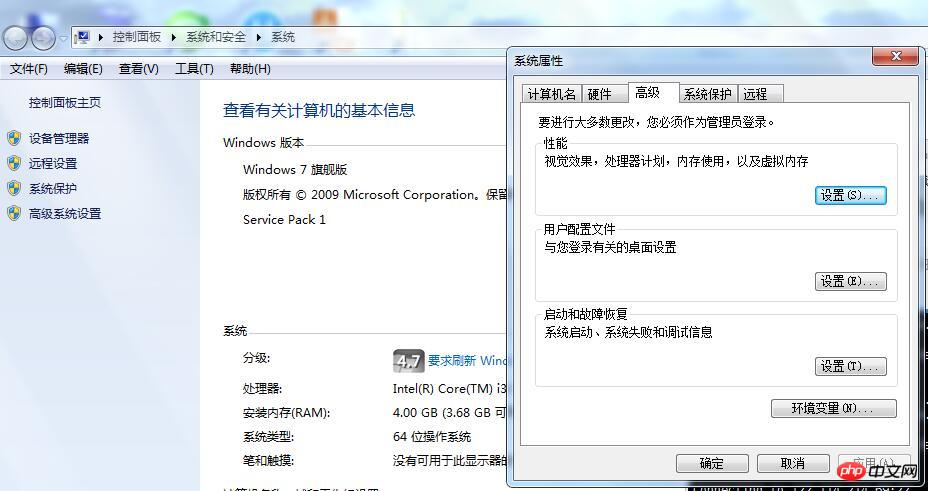
환경 변수를 클릭하여 아래 구성 인터페이스를 입력하십시오.
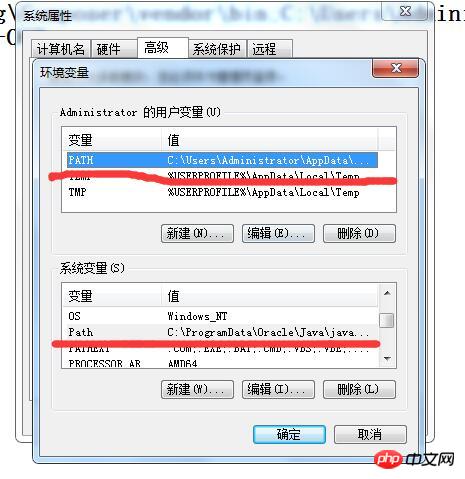
지금 설치 경로 "C:Program Files (x86)Tesseract-OCR"을 추가하십시오. PATH 및 Path는 빨간색으로 밑줄이 그어져 있습니다. 참고로, 추가할 때는 처음에 ";"로 이전 변수와 구분하고 끝에는 ";"로 끝냅니다. 다음은 내 구성 정보의 샘플입니다.
C:UsersAdministratorAppDataRoamingComposevendorbin;C:UsersAdministratorAppDataRoamingnpm;C:Program Files (x86)Tesseract-OCR;
구성 후 저장을 클릭합니다.
명령 터미널을 열고 tesseract -v를 입력하면 버전 정보를 볼 수 있습니다

오류가 발생한다면 환경 변수가 제대로 구성되지 않았기 때문일 수 있습니다.
이 시점에서 설치를 완료하더라도 시스템은 여전히 중국어를 인식할 수 없습니다. 중국어 간체 및 중국어 번체 언어 팩을 다운로드해야 합니다(주소는 위에 나와 있음). tessconfigs 디렉토리로 이동하세요.
보충: 구성된 전역 변수가 없기 때문에 디스크 간에 데이터 변환을 수행할 수 없습니다. 여기서 환경 변수에 구성 정보를 추가합니다
시스템 변수 --> 신규:

TESSDATA_PREFIX 변수 이름을 추가하고 변수 값 또는 내 설치 경로 C:Program Files (x86)Tesseract-OCR;
위 내용은 Windows에서 tesseract-ocr 4.00을 설치하고 구성하는 방법은 무엇입니까?의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!