
A800은 Llama2 추론 RTX3090 및 4090을 크게 능가하여 뛰어난 대기 시간과 처리량을 수행합니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-01-04 13:05:001344검색
대규모 언어 모델(LLM)은 학계와 산업 모두에서 엄청난 발전을 이루었습니다. 그러나 LLM 교육 및 배포에는 비용이 많이 들고 컴퓨팅 리소스와 메모리가 많이 필요하므로 연구자들은 LLM 사전 교육, 미세 조정 및 추론을 가속화하기 위한 많은 오픈 소스 프레임워크와 방법을 개발했습니다. 그러나 다양한 하드웨어 및 소프트웨어 스택의 런타임 성능은 크게 다를 수 있으므로 최상의 구성을 선택하기가 어렵습니다.
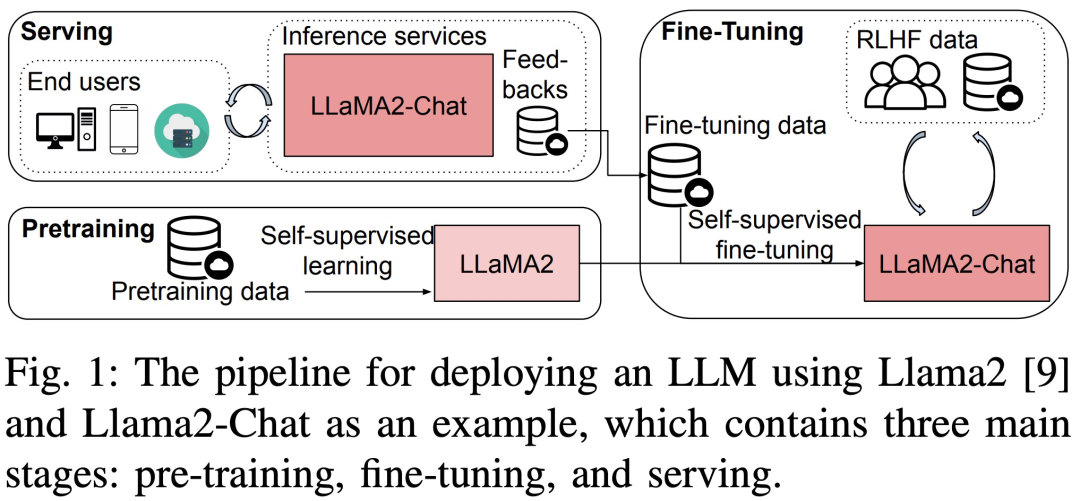
최근 "대형 언어 모델의 학습, 미세 조정 및 추론의 런타임 성능 분석"이라는 제목의 새 논문에서는 LLM 학습, 미세 조정 및 추론의 런타임 성능을 자세히 분석합니다.

논문을 보려면 다음 링크를 클릭하세요: https://arxiv.org/pdf/2311.03687.pdf
구체적으로, 이 연구는 서로 다른 규모의 3개의 8-GPU에서 처음 수행되었습니다( 7B , 13B 및 70B 매개변수) LLM은 사전 훈련, 미세 조정 및 서비스에 대한 원래 의미를 변경하지 않고 전체 성능 벤치마크 테스트를 수행했습니다. 테스트에서는 ZeRO, Quantize, Recalculate 및 FlashAttention을 포함한 개별 최적화 기술이 포함된 플랫폼과 포함되지 않은 플랫폼을 다루었습니다. 그런 다음 연구에서는 LLM
방법 소개
에서 계산 및 통신 연산자의 하위 모듈에 대한 자세한 런타임 분석을 추가로 제공합니다. 연구의 벤치마크는 Llama2를 3가지로 다루는 하향식 접근 방식을 채택합니다. 8-GPU 하드웨어 플랫폼의 단계 시간 성능, 모듈 수준 시간 성능 및 운영자 시간 성능은 그림 3에 나와 있습니다.
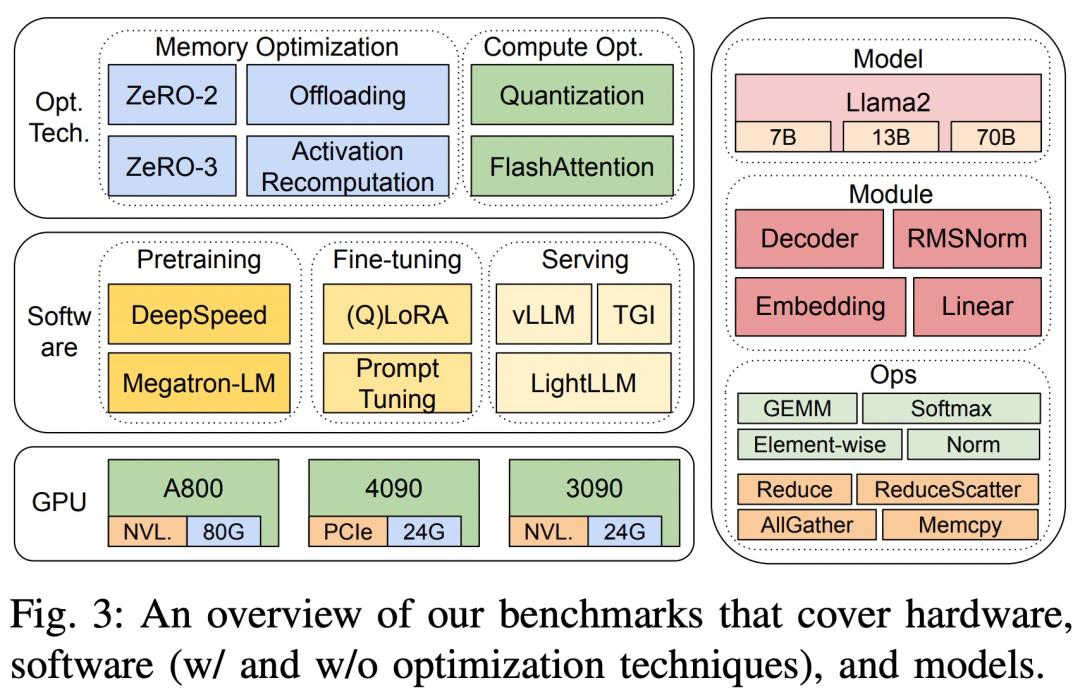
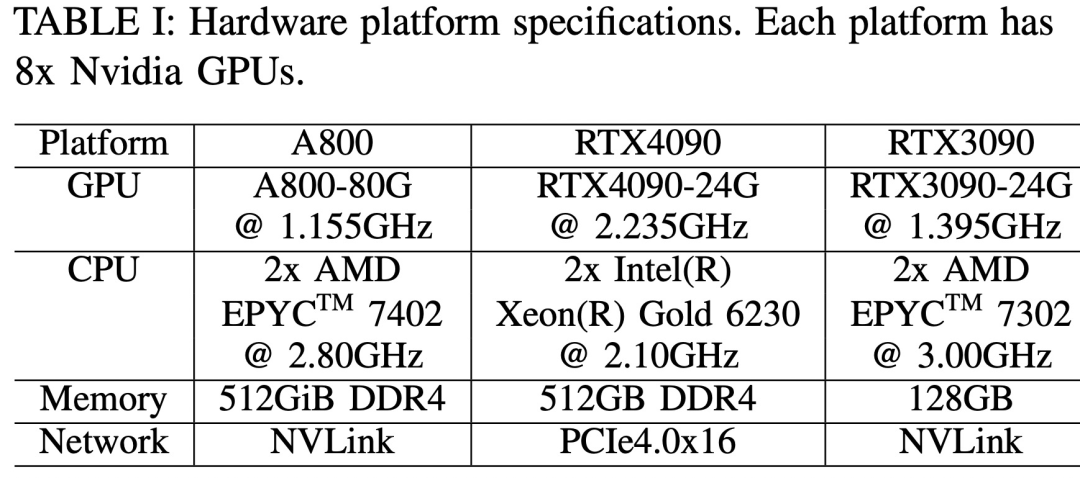
세 가지 하드웨어 플랫폼은 RTX4090, RTX3090 및 A800입니다. 구체적인 사양은 아래 표 1에 나와 있습니다.
소프트웨어 측면에서 사전 훈련 및 미세 조정 측면에서 DeepSpeed와 Megatron-LM의 엔드투엔드 단계 시간을 비교했습니다. 최적화 기술을 평가하기 위해 연구에서는 DeepSpeed를 사용하여 ZeRO-2, ZeRO-3, 오프로딩, 활성화 재계산, 양자화, FlashAttention 등의 최적화를 하나씩 활성화하여 성능 향상과 시간 및 메모리 소비 감소를 측정했습니다.
LLM 서비스에는 vLLM, LightLLM, TGI라는 세 가지 고도로 최적화된 시스템이 있으며, 본 연구에서는 세 가지 테스트 플랫폼에서 성능(대기 시간 및 처리량)을 비교합니다.
본 연구에서는 결과의 정확성과 재현성을 보장하기 위해 LLM 공통 데이터 세트 알파카의 명령, 입력 및 출력의 평균 길이, 즉 샘플당 350개의 토큰과 도달하기 위해 무작위로 생성된 문자열을 계산했습니다. 350 시퀀스 길이.
추론 서비스에서는 컴퓨팅 리소스를 종합적으로 활용하고 프레임워크의 견고성과 효율성을 평가하기 위해 모든 요청이 버스트 모드로 예약됩니다. 실험 데이터 세트는 1000개의 합성 문장으로 구성되며 각 문장에는 512개의 입력 토큰이 포함됩니다. 이 연구에서는 결과의 일관성과 비교 가능성을 보장하기 위해 동일한 GPU 플랫폼의 모든 실험에서 항상 "최대 생성 토큰 길이" 매개변수를 유지합니다.
원래 의미를 변경할 필요 없음, 완전한 성능
이 연구에서는 다양한 Llama2 모델의 사전 훈련, 미세 조정 및 단계 시간 추론, 처리량 및 메모리 소비와 같은 지표를 사용합니다. 크기(7B, 13B 및 70B) - 원래 의미를 변경하지 않고 세 가지 테스트 플랫폼에서 전체 성능을 측정합니다. 널리 사용되는 세 가지 추론 제공 시스템인 TGI, vLLM 및 LightLLM도 지연 시간, 처리량, 메모리 소비와 같은 지표에 중점을 두고 평가됩니다.
모듈 수준 성능
LLM은 일반적으로 고유한 컴퓨팅 및 통신 특성을 가질 수 있는 일련의 모듈(또는 레이어)로 구성됩니다. 예를 들어 Llama2 모델을 구성하는 주요 모듈은 Embedding, LlamaDecoderLayer, Linear, SiLUActivation 및 LlamaRMSNorm입니다.
사전 교육 결과
사전 교육 실험 세션에서 연구원들은 먼저 세 가지 테스트에서 다양한 크기 모델(7B, 13B 및 70B)의 사전 교육 성능(반복 시간 또는 처리량, 메모리 소비)을 분석했습니다. 그런 다음 모듈 및 운영 수준에서 마이크로 벤치마크가 수행되었습니다.
원래 의미를 바꿀 필요 없이 완전한 성능
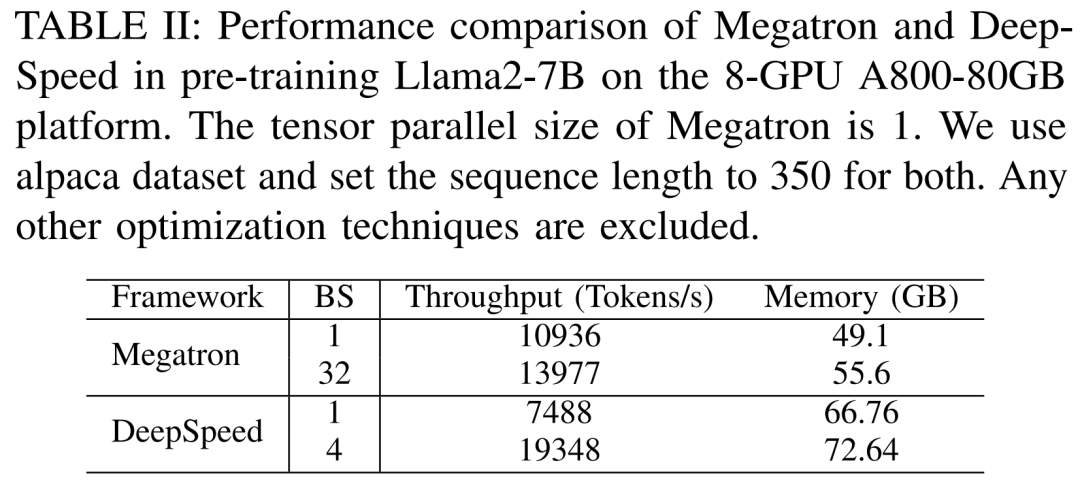
연구원들은 먼저 Llama2-7B를 사전 훈련할 때 사용하지 않았던 Megatron-LM과 DeepSpeed의 성능을 비교하는 실험을 진행했습니다. A800-80GB 서버. 모든 메모리 최적화 기술(예: ZeRO)
그들은 350의 시퀀스 길이를 사용했으며 Megatron-LM 및 DeepSpeed에 대해 1부터 최대 배치 크기까지 두 세트의 배치 크기를 제공했습니다. 결과는 훈련 처리량(토큰/초) 및 소비자 GPU 메모리(GB)에 대해 벤치마킹된 아래 표 II에 나와 있습니다.
결과에 따르면 배치 크기가 둘 다 1인 경우 Megatron-LM이 DeepSpeed보다 약간 빠릅니다. 그러나 DeepSpeed는 배치 크기가 최대에 도달했을 때 훈련 속도가 가장 빠릅니다. 배치 크기가 동일한 경우 DeepSpeed는 텐서 병렬 기반 Megatron-LM보다 GPU 메모리를 더 많이 소비합니다. 배치 크기가 작더라도 두 시스템 모두 상당한 양의 GPU 메모리를 소비하여 RTX4090 또는 RTX3090 GPU 서버에서 메모리 오버플로가 발생했습니다.
Llama2-7B(시퀀스 길이 350, 배치 크기 2)를 훈련할 때 연구원들은 양자화와 함께 DeepSpeed를 사용하여 다양한 하드웨어 플랫폼에서의 스케일링 효율성을 연구했습니다. 결과는 아래 그림 4에 나와 있습니다. A800은 거의 선형적으로 확장되며 RTX4090과 RTX3090의 확장 효율성은 각각 90.8%와 85.9%로 약간 낮습니다. RTX3090 플랫폼에서 NVLink 연결은 NVLink가 없을 때보다 10% 더 효율적입니다.
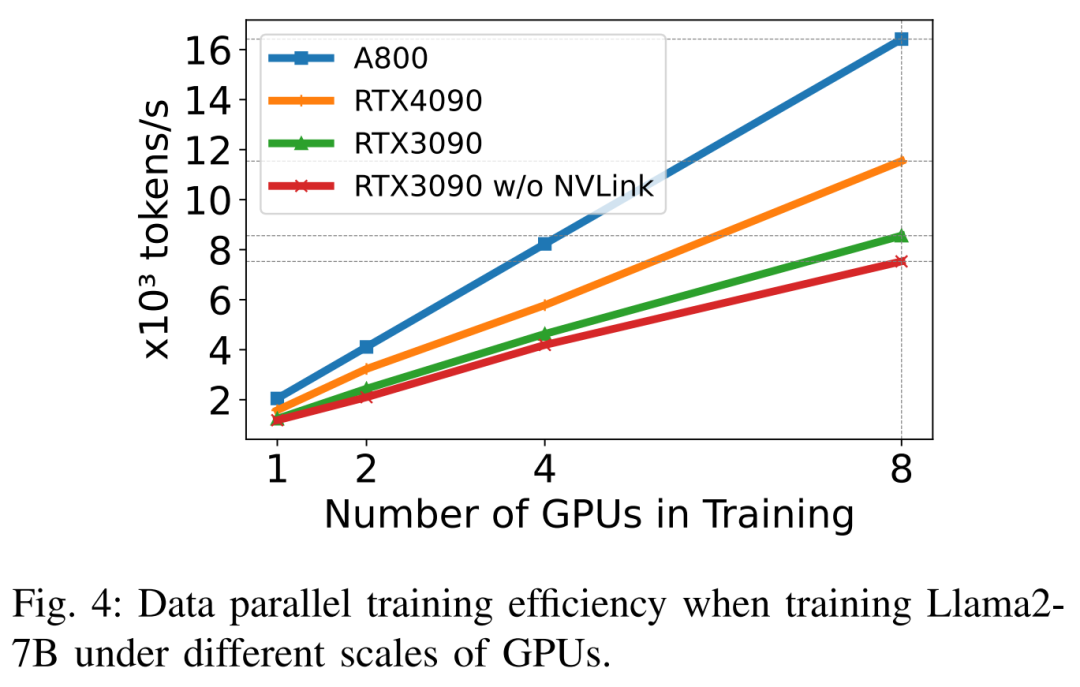
연구원들은 DeepSpeed를 사용하여 다양한 메모리와 계산적으로 효율적인 방법으로 훈련 성능을 평가합니다. 공정성을 위해 모든 평가는 시퀀스 길이 350, 배치 크기 1, 기본 로드 모델 가중치 bf16으로 설정됩니다.
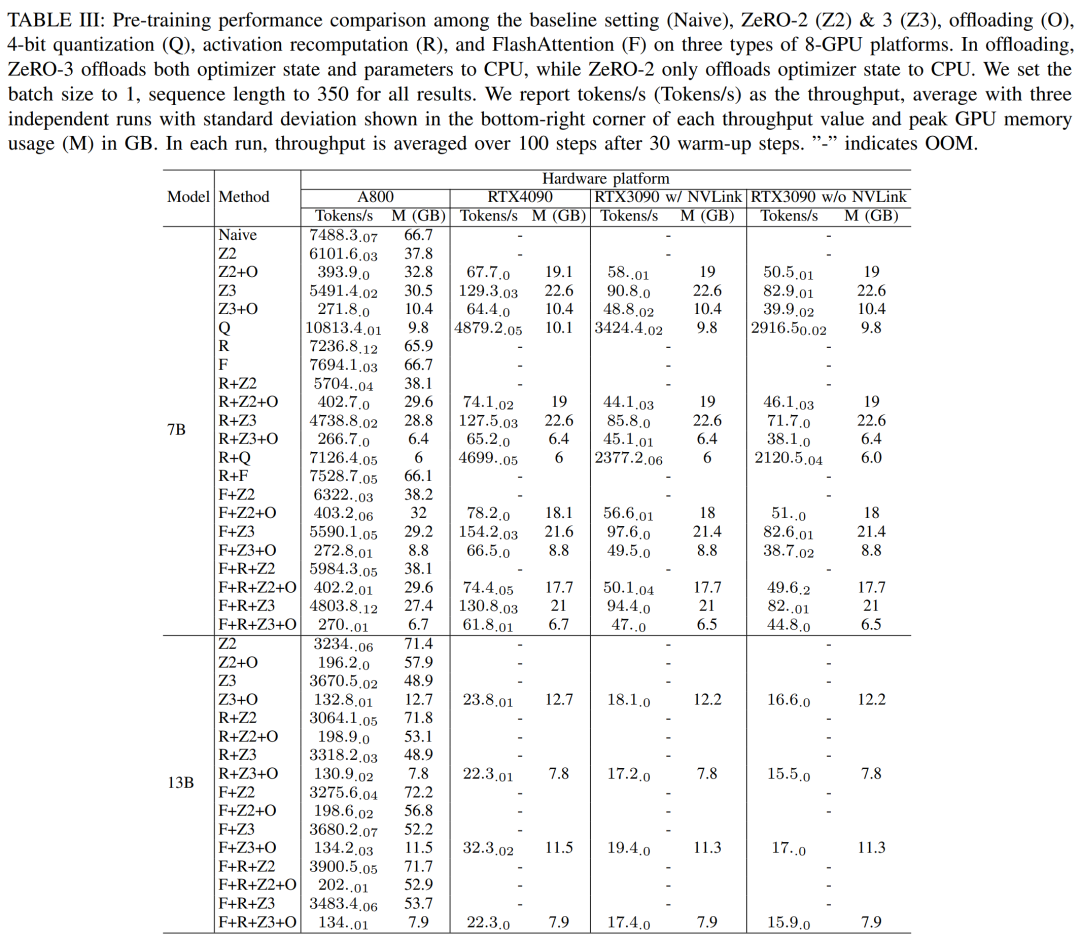
오프로드 기능이 있는 ZeRO-2 및 ZeRO-3의 경우 최적화 상태 및 최적화 상태 + 모델을 각각 CPU RAM으로 오프로드합니다. 양자화를 위해 이중 양자화를 갖춘 4비트 구성을 사용했습니다. 또한 NVLink가 비활성화된 경우(즉, 모든 데이터가 PCIe 버스를 통해 전송되는 경우) RTX3090의 성능도 보고됩니다. 결과를 하기 표 III에 나타내었다.
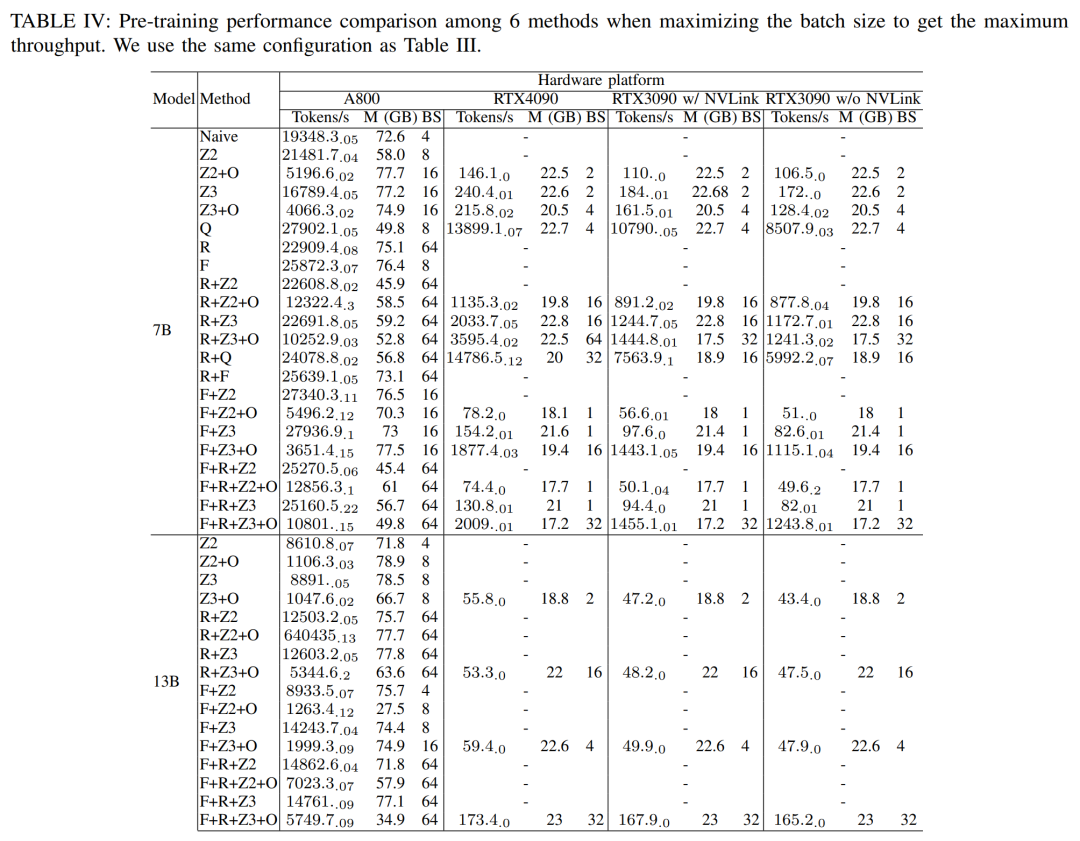
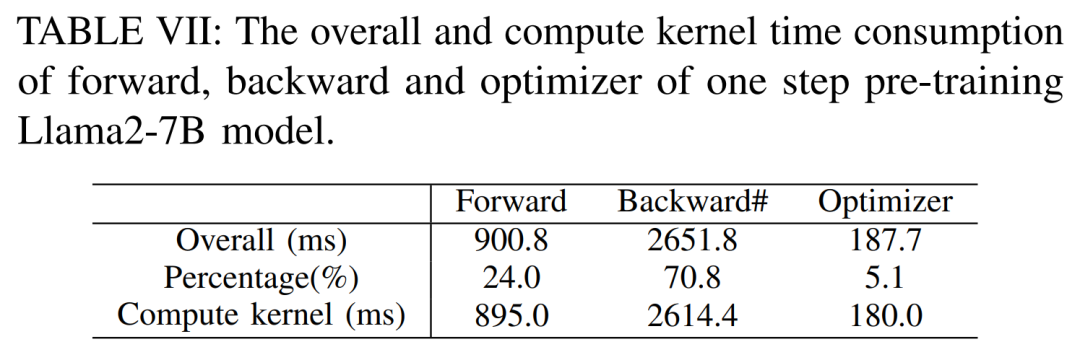
최대 처리량을 얻기 위해 연구원들은 각 방법의 배치 크기를 최대화하여 다양한 GPU 서버의 컴퓨팅 성능을 더욱 활용했습니다. 결과는 표 IV에 나와 있으며, 배치 크기를 늘리면 훈련 프로세스가 쉽게 향상될 수 있음을 보여줍니다. 따라서 높은 대역폭과 대용량 메모리를 갖춘 GPU 서버는 소비자급 GPU 서버보다 전체 매개변수 혼합 정밀도 교육에 더 적합합니다. Llama2-7B 모델의 순방향, 역방향 및 최적화 프로그램을 교육하는 데 드는 전체 및 계산 코어 시간 비용입니다. 역방향 단계의 경우 총 시간에는 겹치지 않는 시간이 포함되므로 계산 코어 시간은 순방향 단계 및 최적화 프로그램보다 훨씬 작습니다. 역방향 위상에서 겹치지 않는 시간을 제거하면 값은 94.8이 됩니다.
FlashAttention의 영향을 다시 계산하고 재평가해야 합니다
사전 학습을 가속화하는 기술은 대략 메모리 절약, 배치 크기 증가, 컴퓨팅 가속화의 두 가지 범주로 나눌 수 있습니다. 코어. 아래 그림 5에서 볼 수 있듯이 GPU는 순방향, 역방향 및 최적화 단계에서 유휴 시간의 5~10%를 소비합니다.
연구원들은 이 유휴 시간이 더 작은 배치 크기로 인해 발생한다고 믿었기 때문에 사용 가능한 가장 큰 배치 크기로 모든 기술을 테스트했습니다. 마지막으로 배치 크기를 늘리기 위해 재계산을 채택하고 핵심 분석 계산 속도를 높이기 위해 FlashAttention을 활용했습니다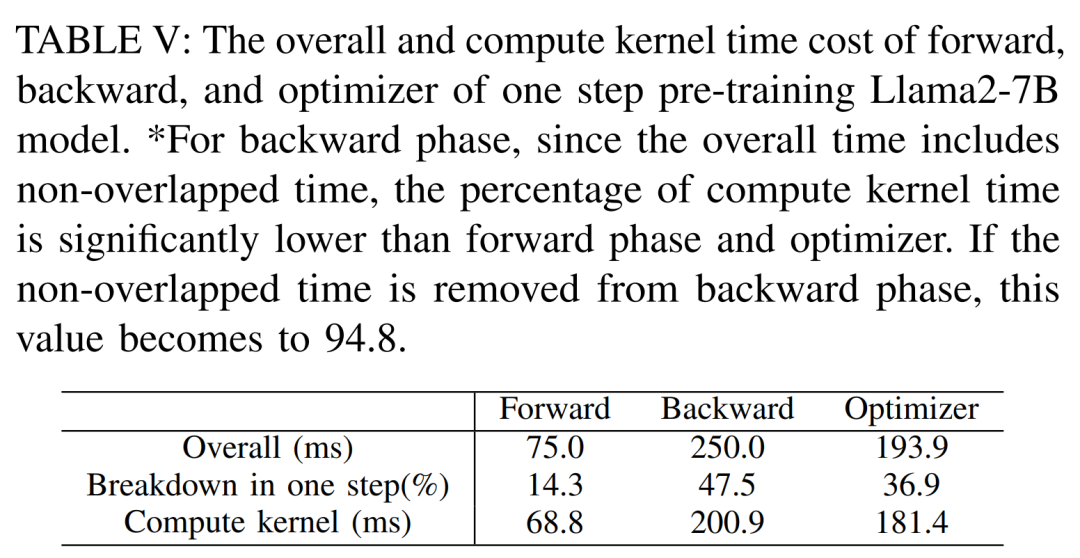
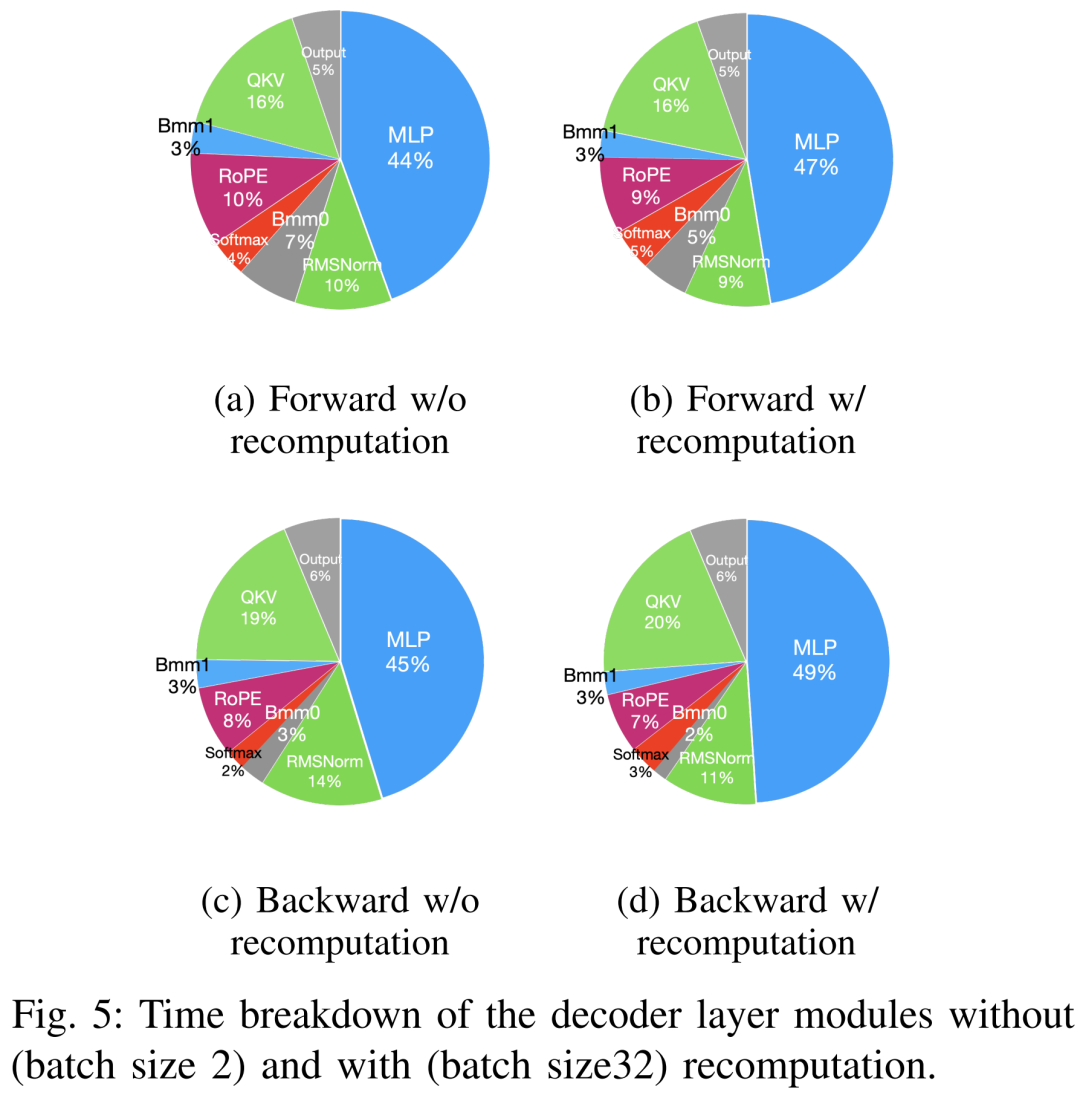
아래 표 VII에서 볼 수 있듯이 배치 크기가 증가함에 따라 순방향 및 역방향 단계 시간이 크게 증가하여 GPU 유휴 시간이 거의 발생하지 않습니다.
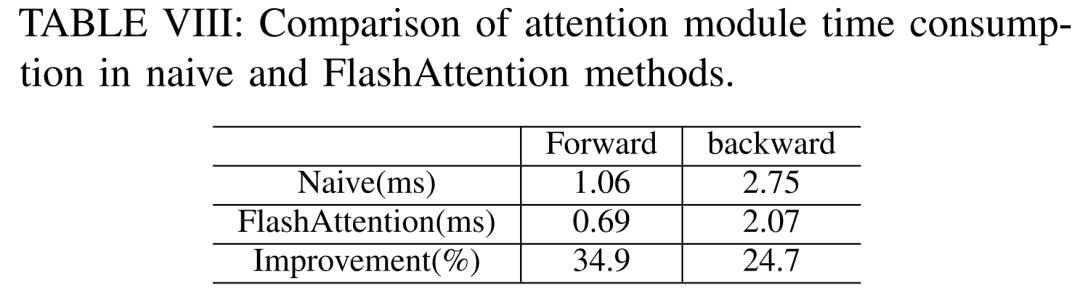
아래 표 VIII에 따르면 FlashAttention은 전방 및 후방 주의 모듈을 각각 34.9% 및 24.7% 가속화할 수 있습니다.
미세 조정 결과
미세 조정 과정에서 연구진은 다양한 모델 크기와 하드웨어 설정에서 LoRA와 QLoRA의 미세 조정 성능을 입증하기 위해 PEFT(Parameter Efficient Fine-tuning Method)가 주로 논의됩니다. 시퀀스 길이 350, 배치 크기 1을 사용하고 기본적으로 모델 가중치를 bf16에 로드합니다.
아래 표 IX의 결과에 따르면 LoRA와 QLoRA를 사용하여 Llama2-13B를 미세 조정한 후의 성능 추세는 Llama2-7B와 일치합니다. Llama2-7B와 비교하여 미세 조정된 Llama2-13B의 처리량은 약 30% 감소했습니다
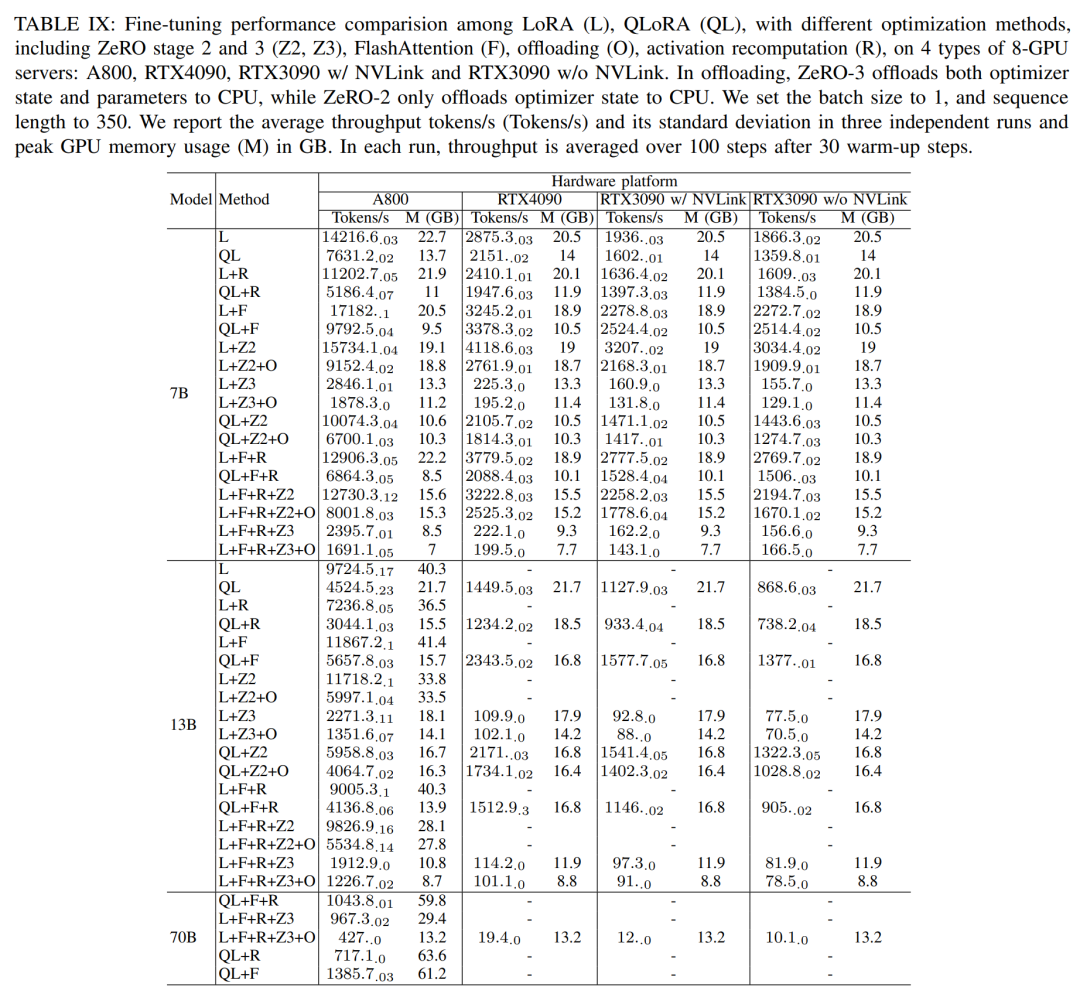
그러나 모든 최적화 기술을 결합하면 RTX4090 및 RTX3090에서도 Llama2-70B를 미세 조정하여 200을 달성할 수 있습니다. 토큰/초 총 처리량.
추론 결과
원래 의미를 변경할 필요 없음, 완전한 성능
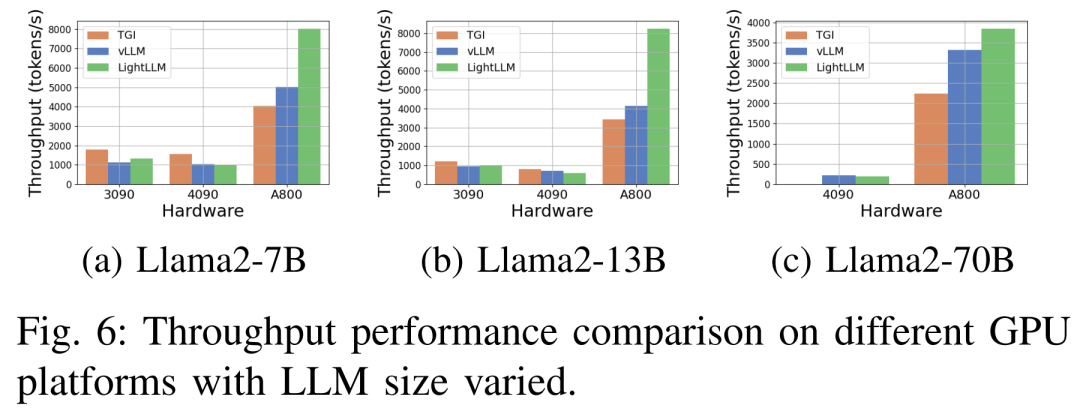
아래 그림 6은 Llama2-70B를 생략한 다양한 하드웨어 플랫폼 및 추론 프레임워크에서의 처리량에 대한 포괄적인 분석을 보여줍니다. 관련 추론 데이터. 그 중 TGI 프레임워크는 특히 RTX3090, RTX4090 등 24GB 메모리를 탑재한 GPU에서 뛰어난 처리량을 보여줬다. 또한 LightLLM은 A800 GPU 플랫폼에서 TGI 및 vLLM보다 성능이 훨씬 뛰어나며 처리량이 거의 두 배로 늘어납니다.
이러한 실험 결과는 TGI 추론 프레임워크가 24GB 메모리 GPU 플랫폼에서 뛰어난 성능을 보이는 반면, LightLLM 추론 프레임워크는 A800 80GB GPU 플랫폼에서 가장 높은 처리량을 나타냄을 보여줍니다. 이 결과는 LightLLM이 A800/A100 시리즈 고성능 GPU에 특별히 최적화되어 있음을 시사합니다.
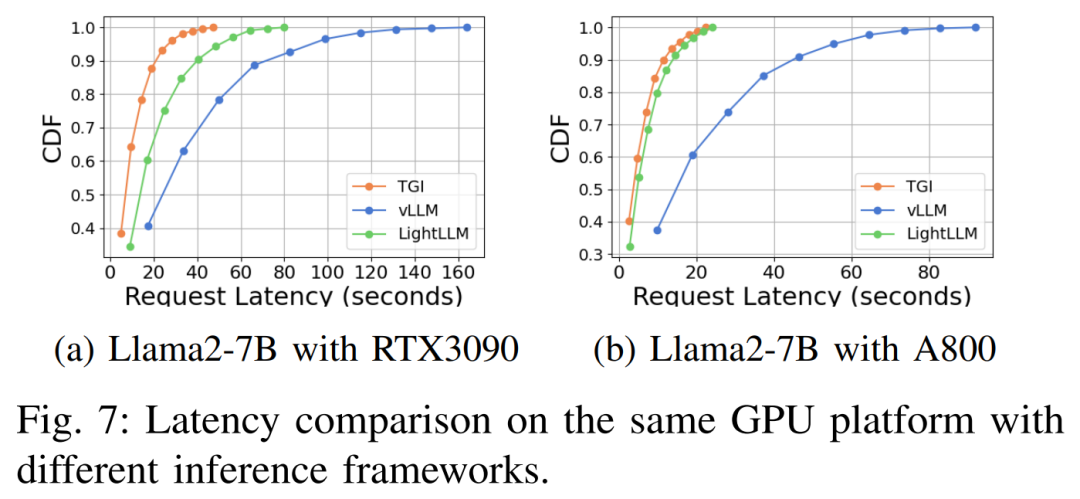
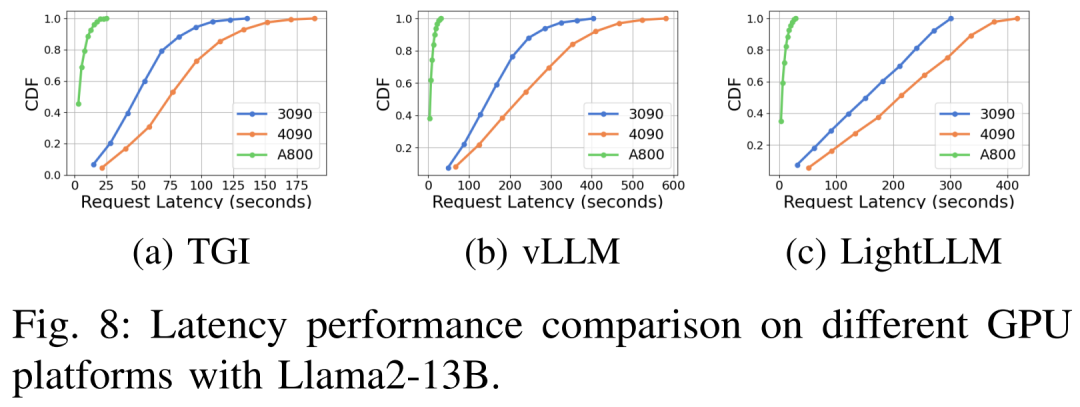
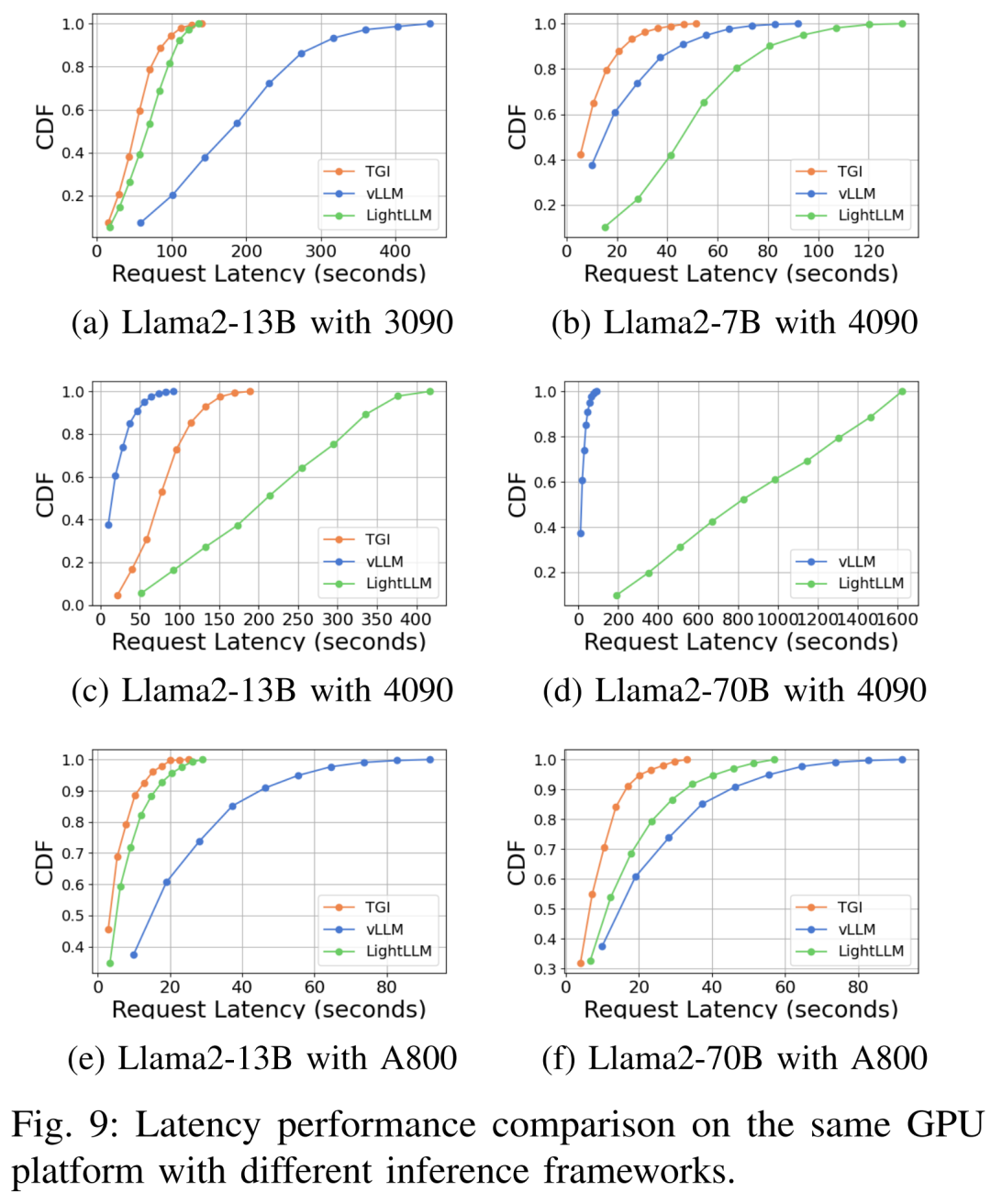
다양한 하드웨어 플랫폼 및 추론 프레임워크에서의 지연 시간 성능은 그림 7, 8, 9 및 10
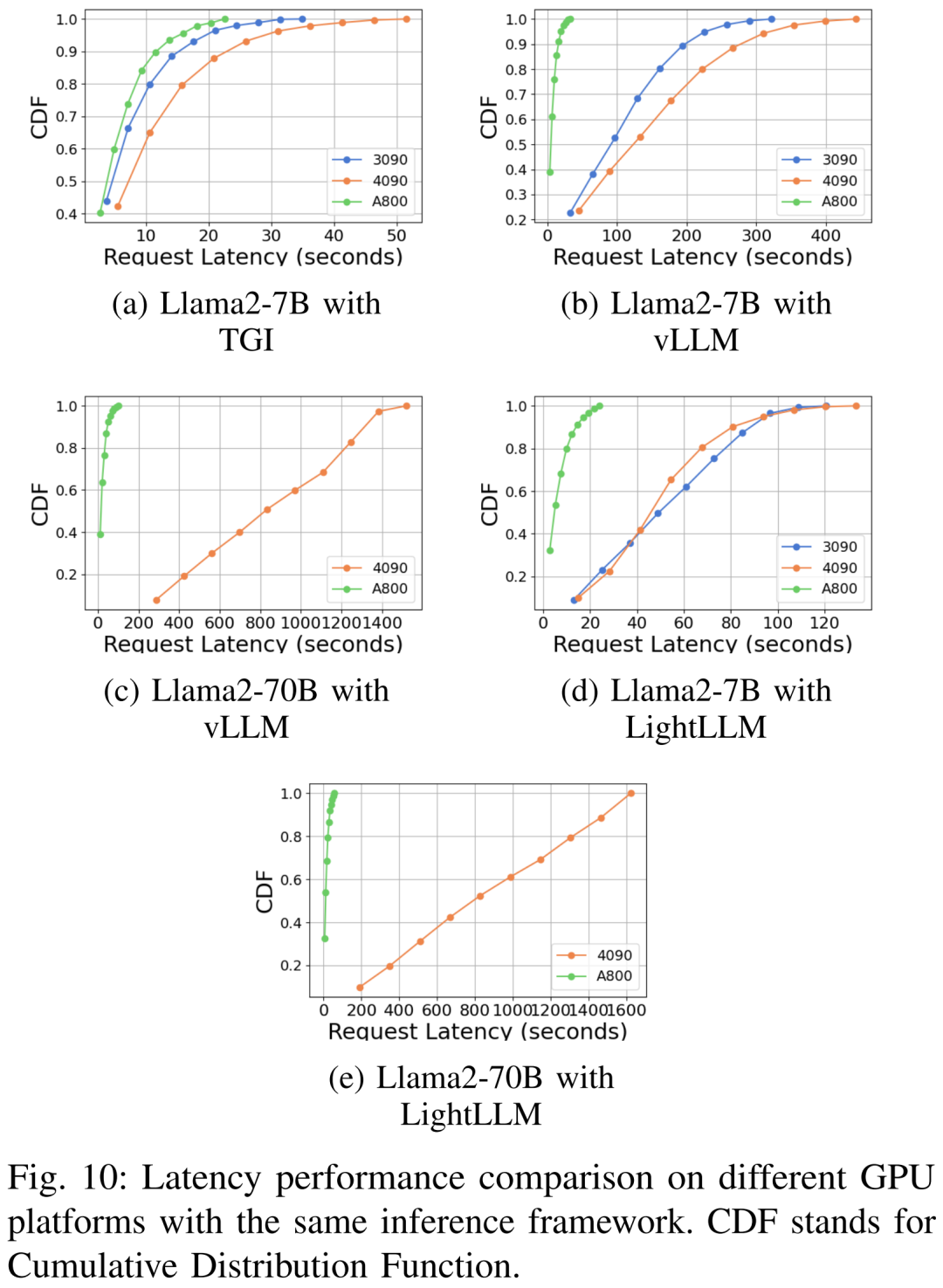 에 나와 있습니다.
에 나와 있습니다.
포괄적 위에서 볼 수 있듯이 A800 플랫폼은 처리량 및 대기 시간 측면에서 두 소비자 플랫폼 RTX4090 및 RTX3090보다 훨씬 뛰어납니다. 그리고 두 가지 소비자급 플랫폼 중에서 RTX3090은 RTX4090에 비해 약간의 이점이 있습니다. 세 가지 추론 프레임워크인 TGI, vLLM 및 LightLLM은 소비자급 플랫폼에서 실행될 때 처리량에 큰 차이가 없습니다. 이에 비해 TGI는 대기 시간 측면에서 지속적으로 다른 두 가지보다 성능이 뛰어납니다. A800 GPU 플랫폼에서 LightLLM은 처리량 측면에서 최고의 성능을 발휘하며 대기 시간도 TGI 프레임워크와 매우 유사합니다.
더 많은 실험 결과는 원문을 참고해주세요
위 내용은 A800은 Llama2 추론 RTX3090 및 4090을 크게 능가하여 뛰어난 대기 시간과 처리량을 수행합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!