
PyTorch 배치 훈련 및 옵티마이저 비교에 대한 자세한 설명

- 不言원래의
- 2018-04-28 09:46:385620검색
이 글은 주로 PyTorch 배치 트레이닝과 옵티마이저 비교에 대한 자세한 설명을 소개합니다. PyTorch 배치 트레이닝과 PyTorch의 옵티마이저 옵티마이저가 무엇인지 자세히 소개합니다. 도움이 필요한 친구들이 참고할 수 있습니다.
1. PyTorch 배치 훈련
1. 개요
PyTorch는 배치 훈련을 위해 데이터를 패키징하는 도구인 DataLoader를 제공합니다. 이를 사용할 때 먼저 데이터를 토치의 텐서 형식으로 변환한 다음 토치가 인식할 수 있는 데이터 세트 형식으로 변환한 다음 데이터 세트를 DataLoader에 넣으면 됩니다.
import torch
import torch.utils.data as Data
torch.manual_seed(1) # 设定随机数种子
BATCH_SIZE = 5
x = torch.linspace(1, 10, 10)
y = torch.linspace(0.5, 5, 10)
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(
dataset=torch_dataset,
batch_size=BATCH_SIZE, # 批大小
# 若dataset中的样本数不能被batch_size整除的话,最后剩余多少就使用多少
shuffle=True, # 是否随机打乱顺序
num_workers=2, # 多线程读取数据的线程数
)
for epoch in range(3):
for step, (batch_x, batch_y) in enumerate(loader):
print('Epoch:', epoch, '|Step:', step, '|batch_x:',
batch_x.numpy(), '|batch_y', batch_y.numpy())
'''''
shuffle=True
Epoch: 0 |Step: 0 |batch_x: [ 6. 7. 2. 3. 1.] |batch_y [ 3. 3.5 1. 1.5 0.5]
Epoch: 0 |Step: 1 |batch_x: [ 9. 10. 4. 8. 5.] |batch_y [ 4.5 5. 2. 4. 2.5]
Epoch: 1 |Step: 0 |batch_x: [ 3. 4. 2. 9. 10.] |batch_y [ 1.5 2. 1. 4.5 5. ]
Epoch: 1 |Step: 1 |batch_x: [ 1. 7. 8. 5. 6.] |batch_y [ 0.5 3.5 4. 2.5 3. ]
Epoch: 2 |Step: 0 |batch_x: [ 3. 9. 2. 6. 7.] |batch_y [ 1.5 4.5 1. 3. 3.5]
Epoch: 2 |Step: 1 |batch_x: [ 10. 4. 8. 1. 5.] |batch_y [ 5. 2. 4. 0.5 2.5]
shuffle=False
Epoch: 0 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 0 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 1 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 1 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
Epoch: 2 |Step: 0 |batch_x: [ 1. 2. 3. 4. 5.] |batch_y [ 0.5 1. 1.5 2. 2.5]
Epoch: 2 |Step: 1 |batch_x: [ 6. 7. 8. 9. 10.] |batch_y [ 3. 3.5 4. 4.5 5. ]
'''
2. TensorDataset
classtorch.utils.data.TensorDataset(data_tensor, target_tensor)
TensorDataset 클래스는 샘플과 해당 레이블을 토치로 패키징하는 데 사용됩니다. Dataset, data_tensor 및 target_tensor는 모두 텐서입니다.
3.DataLoader
코드 복사 코드는 다음과 같습니다.
classtorch.utils.data.DataLoader(dataset,atch_size=1,shuffle=False,sampler=None,num_workers=0, collate_fn=< ;function default_collate>, pin_memory=False, drop_last=False)
dataset는 Torch의 데이터 세트 형식의 객체입니다. 배치_크기는 각 훈련 배치에 대한 샘플 수이며, 기본값은 무작위 샘플이 필요한지 여부를 나타냅니다. num_workers는 읽을 샘플 수를 나타냅니다. 스레드 수입니다.
2. PyTorch의 Optimizer
이 실험에서는 먼저 데이터 세트 세트를 구성하고 형식을 변환한 후 나중에 사용할 수 있도록 DataLoader에 배치합니다. 고정된 구조로 기본 신경망을 정의한 후 각 옵티마이저마다 신경망을 구축합니다. 각 신경망의 차이점은 옵티마이저뿐입니다. 학습 과정에서 손실 값을 기록함으로써 각 옵티마이저의 최적화 과정이 최종적으로 이미지에 나타납니다.
코드 구현:
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
torch.manual_seed(1) # 设定随机数种子
# 定义超参数
LR = 0.01 # 学习率
BATCH_SIZE = 32 # 批大小
EPOCH = 12 # 迭代次数
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1*torch.normal(torch.zeros(*x.size()))
#plt.scatter(x.numpy(), y.numpy())
#plt.show()
# 将数据转换为torch的dataset格式
torch_dataset = Data.TensorDataset(data_tensor=x, target_tensor=y)
# 将torch_dataset置入Dataloader中
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE,
shuffle=True, num_workers=2)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20)
self.predict = torch.nn.Linear(20, 1)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
# 为每个优化器创建一个Net
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam]
# 初始化优化器
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
# 定义损失函数
loss_function = torch.nn.MSELoss()
losses_history = [[], [], [], []] # 记录training时不同神经网络的loss值
for epoch in range(EPOCH):
print('Epoch:', epoch + 1, 'Training...')
for step, (batch_x, batch_y) in enumerate(loader):
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net, opt, l_his in zip(nets, optimizers, losses_history):
output = net(b_x)
loss = loss_function(output, b_y)
opt.zero_grad()
loss.backward()
opt.step()
l_his.append(loss.data[0])
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(losses_history):
plt.plot(l_his, label=labels[i])
plt.legend(loc='best')
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()
실험 결과:
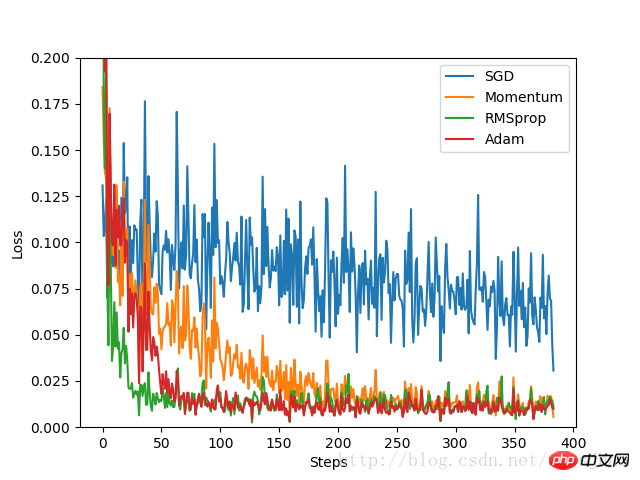
SGD의 개선된 버전으로서 최적화 효과가 가장 나쁘고 속도도 매우 느린 것을 실험 결과에서 알 수 있습니다. , Momentum은 RMSprop 및 Adam과 비교하여 훨씬 더 나은 성능을 발휘합니다. 최적화 속도는 매우 좋습니다. 실험에서는 다양한 최적화 문제에 대해 어떤 최적화 도구를 사용할지 결정하기 전에 다양한 최적화 도구의 효과를 비교했습니다.
3. 기타 보충
1. Python의 zip 함수
zip 함수는 0과 1을 포함한 임의의 시퀀스를 매개변수로 받아들이고 튜플 목록을 반환합니다.
x = [1, 2, 3] y = [4, 5, 6] z = [7, 8, 9] xyz = zip(x, y, z) print xyz [(1, 4, 7), (2, 5, 8), (3, 6, 9)] x = [1, 2, 3] x = zip(x) print x [(1,), (2,), (3,)] x = [1, 2, 3] y = [4, 5, 6, 7] xy = zip(x, y) print xy [(1, 4), (2, 5), (3, 6)]
관련 추천:
위 내용은 PyTorch 배치 훈련 및 옵티마이저 비교에 대한 자세한 설명의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!