
Tsinghua University와 Zhejiang University는 오픈 소스 시각적 모델의 폭발적인 증가를 주도하고 GPT-4V, LLaVA, CogAgent 및 기타 플랫폼은 혁신적인 변화를 가져옵니다.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB앞으로
- 2024-01-04 08:10:581351검색
현재 GPT-4 Vision은 언어 이해 및 시각적 처리 분야에서 놀라운 기능을 보여줍니다.
그러나 성능 저하 없이 비용 효율적인 대안을 찾는 사람들에게 오픈 소스 옵션은 무한한 잠재력을 지닌 옵션입니다.
Youssef Hosni는 GPT-4V를 대체할 수 있는 접근성이 절대적으로 보장된 세 가지 오픈 소스 대안을 제공하는 외국 개발자입니다.
세 가지 오픈 소스 시각적 언어 모델 LLaVa, CogAgent 및 BakLLaVA는 시각적 처리 분야에서 큰 잠재력을 갖고 있으며 심층적으로 이해할 가치가 있습니다. 이러한 모델의 연구 및 개발은 우리에게 보다 효율적이고 정확한 시각 처리 솔루션을 제공할 수 있습니다. 이러한 모델을 사용하면 이미지 인식, 대상 감지 및 이미지 생성과 같은 작업의 정확성과 효율성을 향상시킬 수 있으며,
 pictures
pictures
LLaVa
LLaVA는 다음과 같은 분야의 다중 모드 연구 및 응용 프로그램을 제공합니다. 위스콘신대학교 매디슨대학교, 마이크로소프트 리서치, 컬럼비아대학교 연구자들의 협력으로 개발된 시각적 처리 대형 모델. 첫 버전은 4월에 출시됐다.
비주얼 인코더와 Vicuna(일반적인 시각적 및 언어 이해용)를 결합하여 매우 우수한 채팅 기능을 보여줍니다.
 Pictures
Pictures
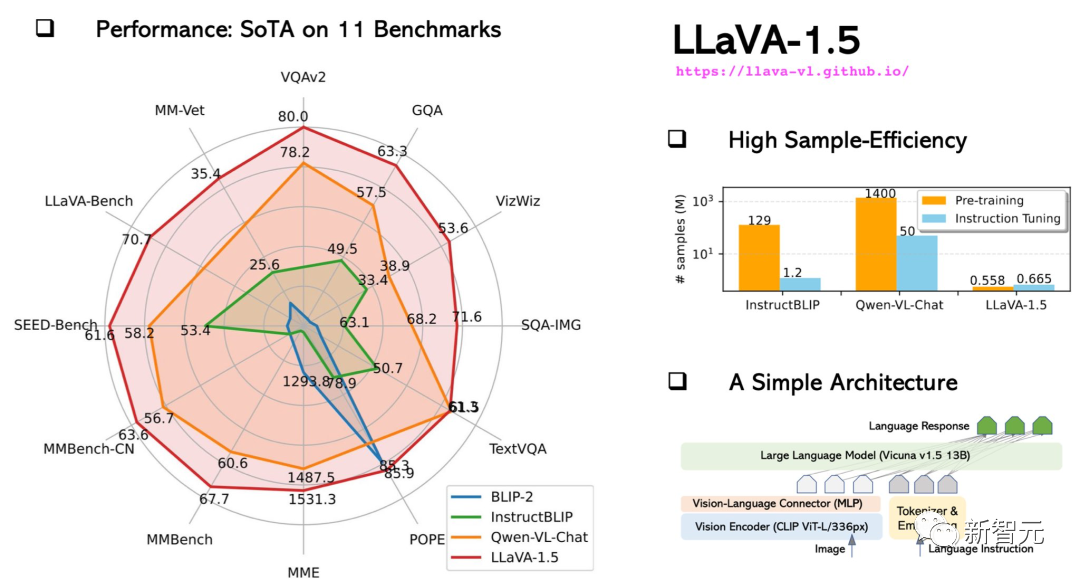
10월에 업그레이드된 LLaVA-1.5는 성능이 멀티모달 GPT-4에 가까웠으며 과학 QA 데이터세트에서 최첨단 결과(SOTA)를 달성했습니다.
 Pictures
Pictures
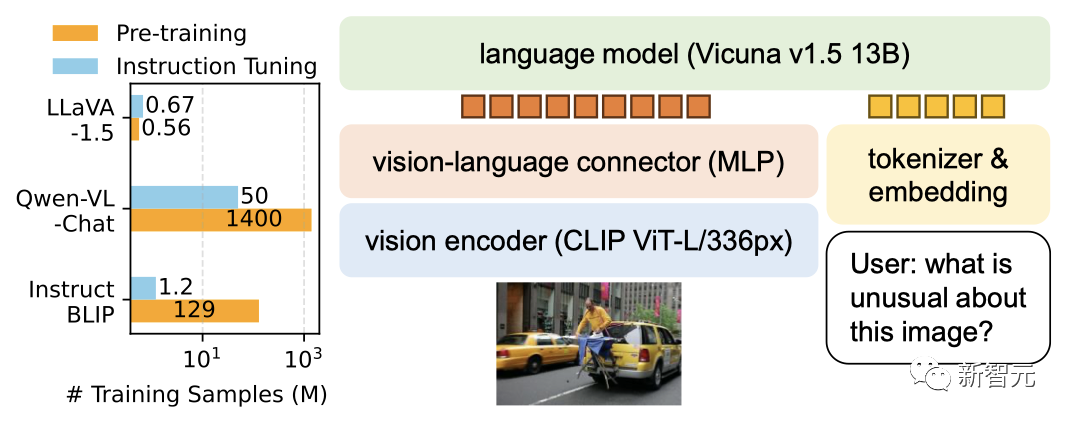
13B 모델의 훈련은 A100 8대만으로 하루 만에 완료할 수 있습니다.
 Pictures
Pictures
보시다시피 LLaVA는 모든 종류의 질문을 처리할 수 있으며 생성된 답변은 포괄적이고 논리적입니다.
LLaVA는 시각적 채팅 측면에서 GPT-4 상대 점수가 85%로 GPT-4 수준에 가까운 일부 다중 모드 기능을 보여줍니다.
추론 질문과 답변 측면에서 LLaVA는 다중 모드 사고 체인을 물리치고 새로운 SoTA-92.53%에 도달했습니다.
 Pictures
Pictures
시각적 추론 측면에서 그 성능은 매우 눈길을 끕니다.
 Pictures
Pictures
 Pictures
Pictures
질문: "사실에 오류가 있는 경우 지적해 주세요. 그렇지 않은 경우 사막에서 무슨 일이 일어나고 있는지 알려주세요."
LLaVA는 답변할 수 없습니다. 아직 완전히 정확해요.
업그레이드된 LLaVA-1.5는 완벽한 답변을 제공했습니다. "사진에는 사막이 전혀 없으며 야자수, 해변, 도시 스카이라인 및 넓은 물이 있습니다."
 사진
사진
, LLaVA-1.5는 OK 그래프에서 정보를 추출하고 JSON 형식으로 출력하는 등 필요한 형식으로 답변합니다.
 Pictures
Pictures
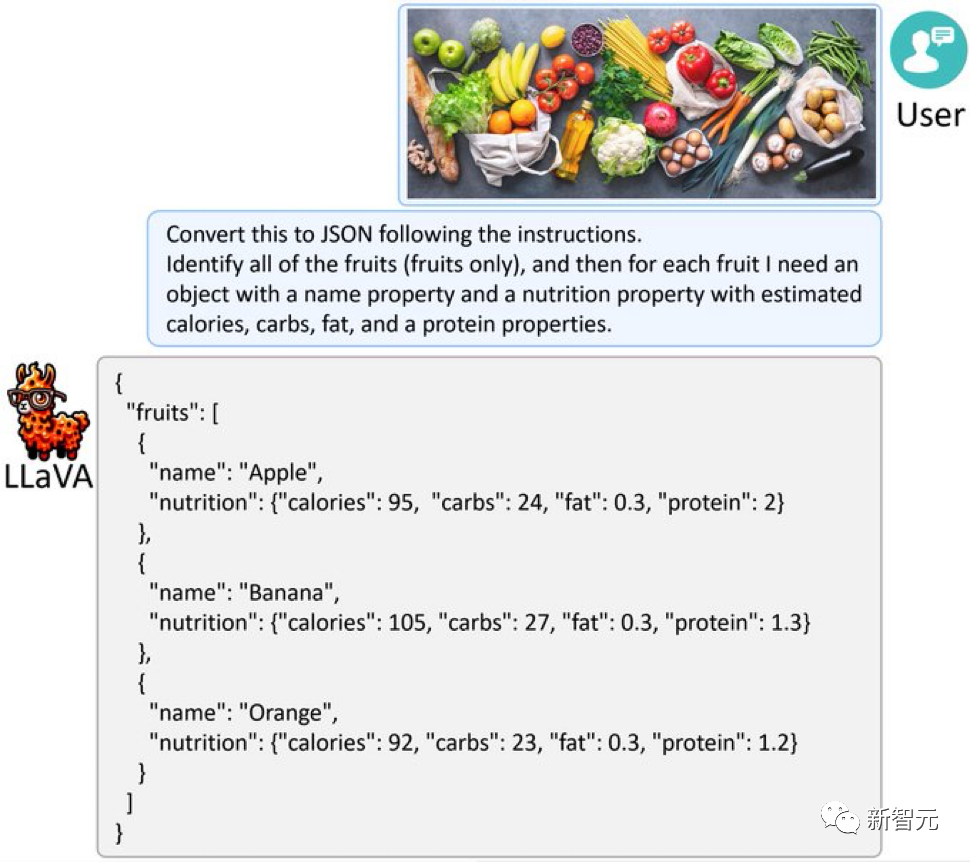
LLaVA-1.5에 과일과 채소가 가득한 사진을 제공하고, GPT-4V처럼 사진을 JSON으로 변환할 수도 있습니다.
 사진
사진
아래 사진은 무슨 뜻인가요?
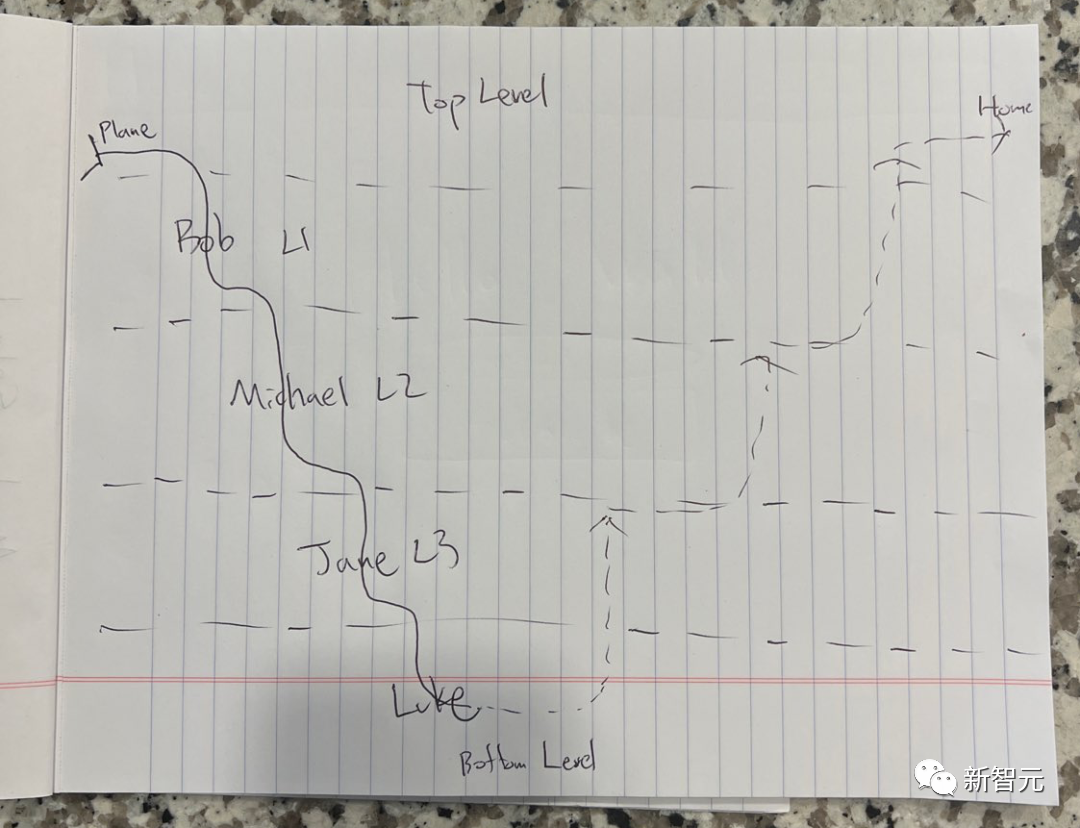 Picture
Picture
놀란의 "인셉션"을 기반으로 한 단순화된 스케치입니다. 난이도를 높이기 위해 캐릭터 이름을 가명으로 변경했습니다.
LLaVA-1.5는 놀랍게도 이렇게 대답했습니다. "영화 '인셉션'에 관한 사진입니다. 꿈의 세계의 다양한 레벨을 보여주고, 각 레벨은 선으로 표시됩니다. 그림이 종이에 적혀 있습니다. "
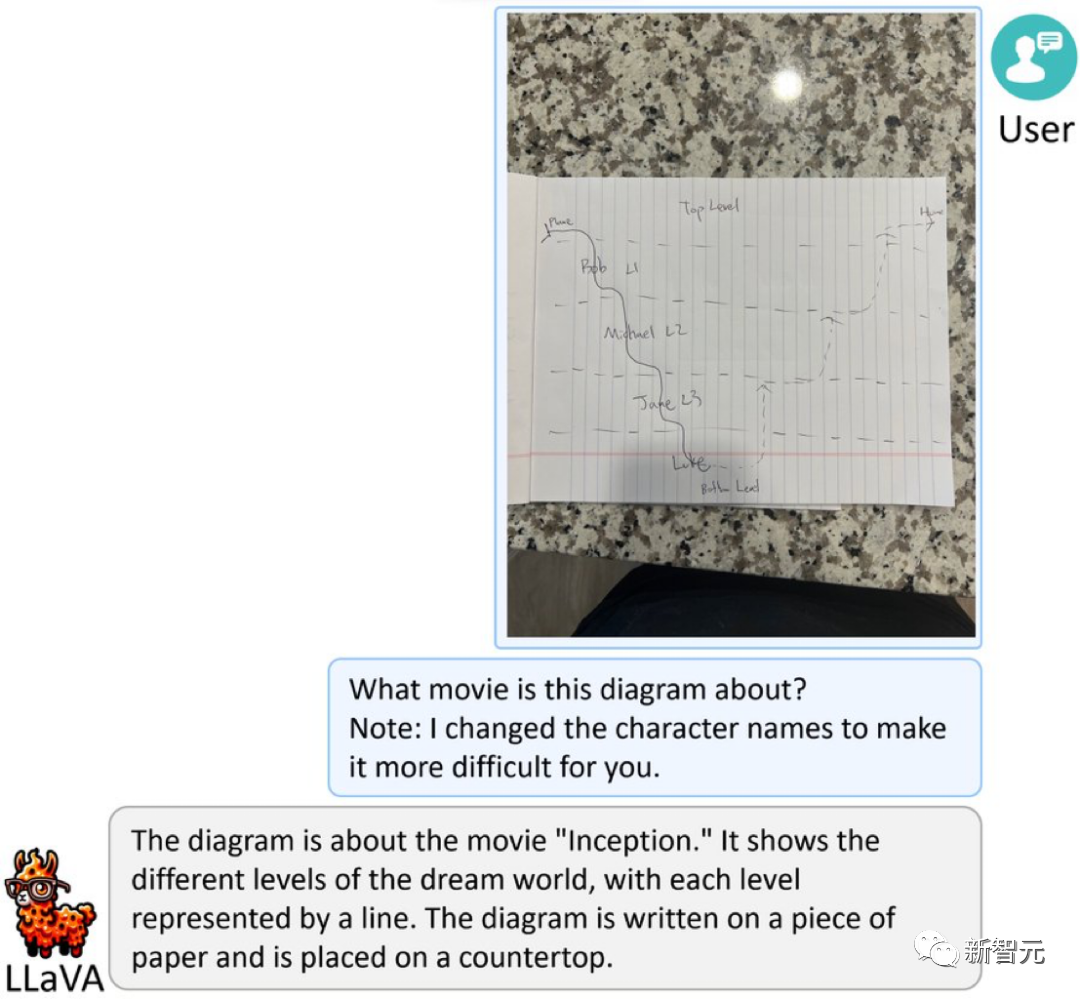 Pictures
Pictures
음식 사진을 LLaVA-1.5에 직접 보내면 빠르게 레시피가 생성됩니다.
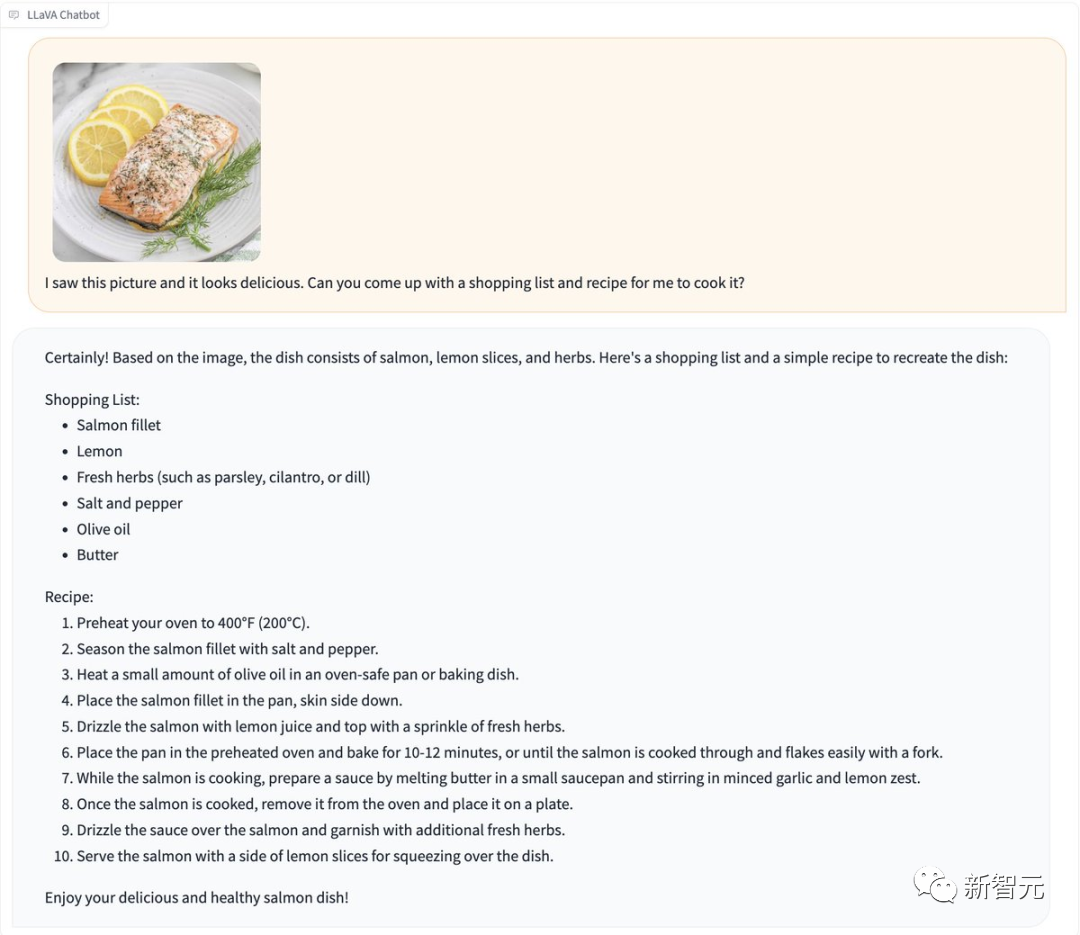 Pictures
Pictures
게다가 LLaVA-1.5는 "탈옥" 없이 인증 코드를 인식할 수 있습니다.
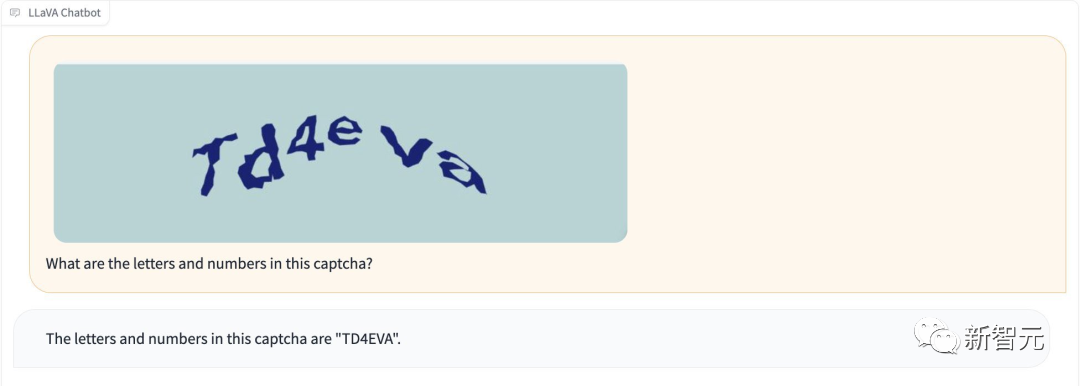 사진
사진
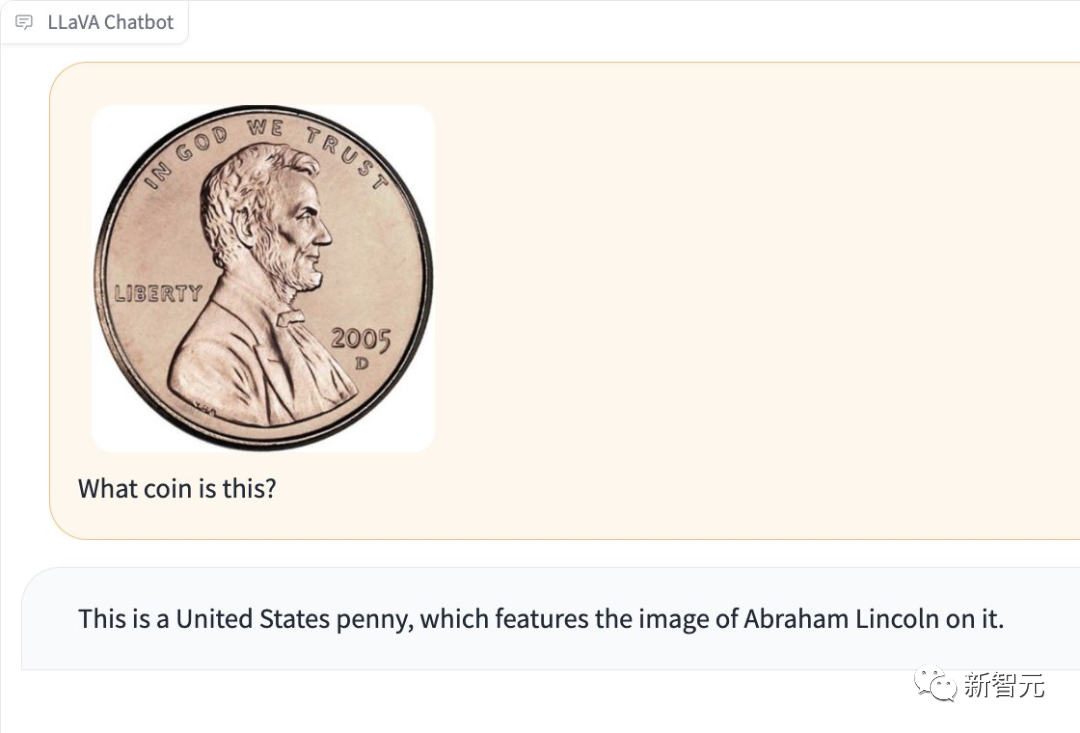
사진에 어떤 종류의 동전이 있는지 감지할 수도 있습니다.
 Pictures
Pictures
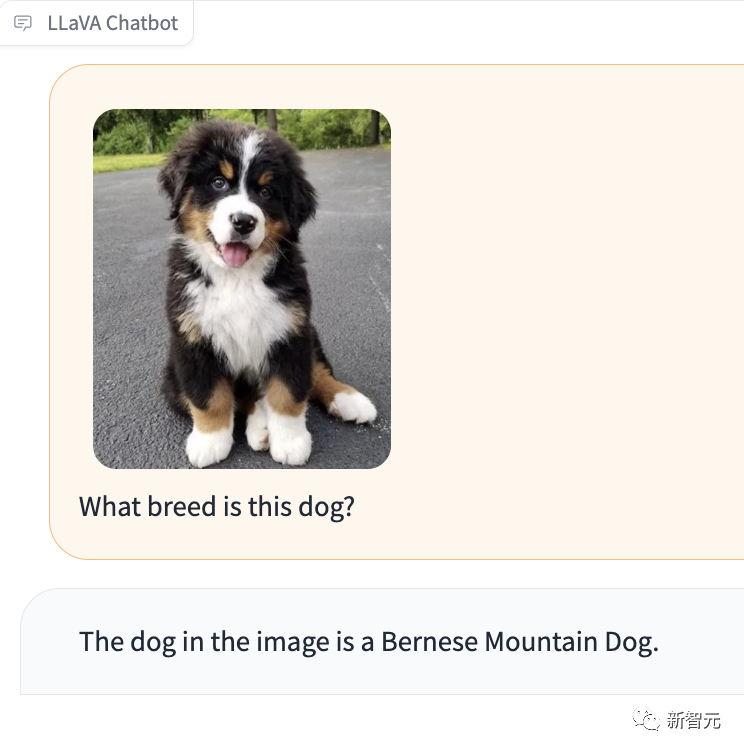
특히 인상적인 점은 LLaVA-1.5가 사진 속 강아지의 품종을 알려줄 수도 있다는 것입니다.
 Picture
Picture
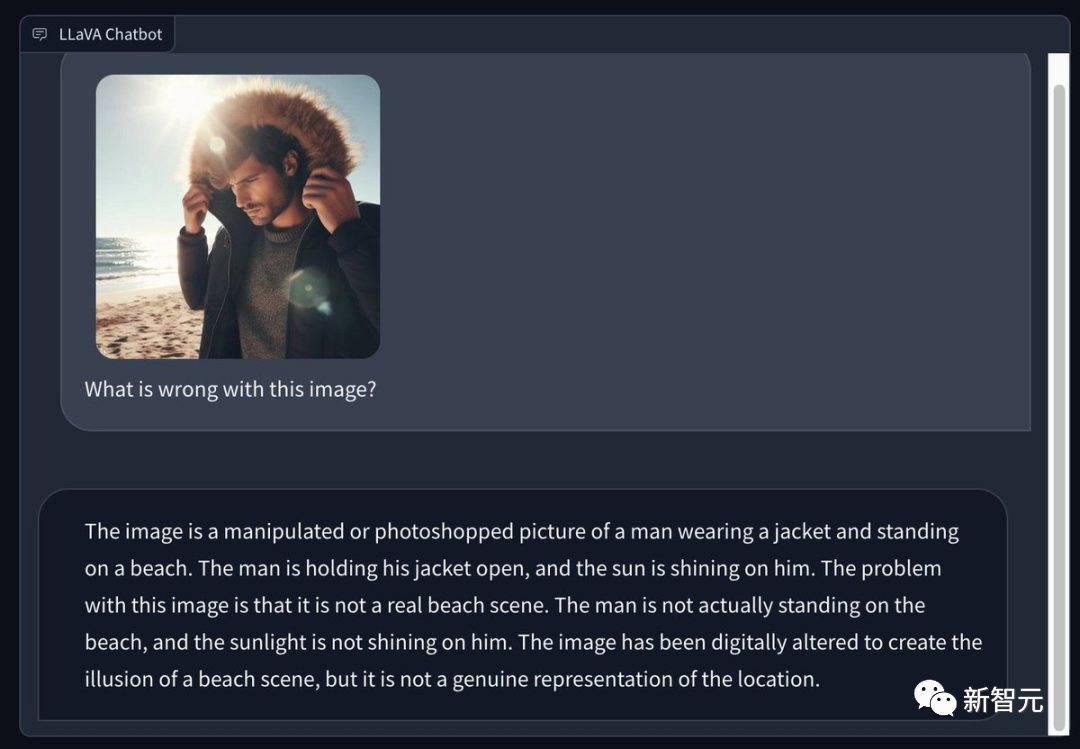
일부 네티즌들은 Bing을 사용해 화창한 여름 해변에서 겨울 코트를 입은 남자의 사진을 생성하고, LLaVA 1.5에게 사진의 문제점을 지적해 달라고 요청했습니다. 눈빛이 참 날카롭네요 -
가공 또는 포토샵 처리한 사진입니다. 남성이 재킷을 입고 해변에 서 있는 모습입니다. 그 남자는 코트를 열었고 태양이 그에게 비췄습니다. 이 이미지의 문제는 실제 해변 장면이 아니라는 점입니다. 그 남자는 실제로 해변에 서 있지도 않았고 태양도 그에게 비치지 않았습니다. 이 이미지는 해변 장면의 환상을 만들기 위해 포토샵으로 처리되었지만 실제로 장면을 표현하지는 않습니다.
 Pictures
Pictures
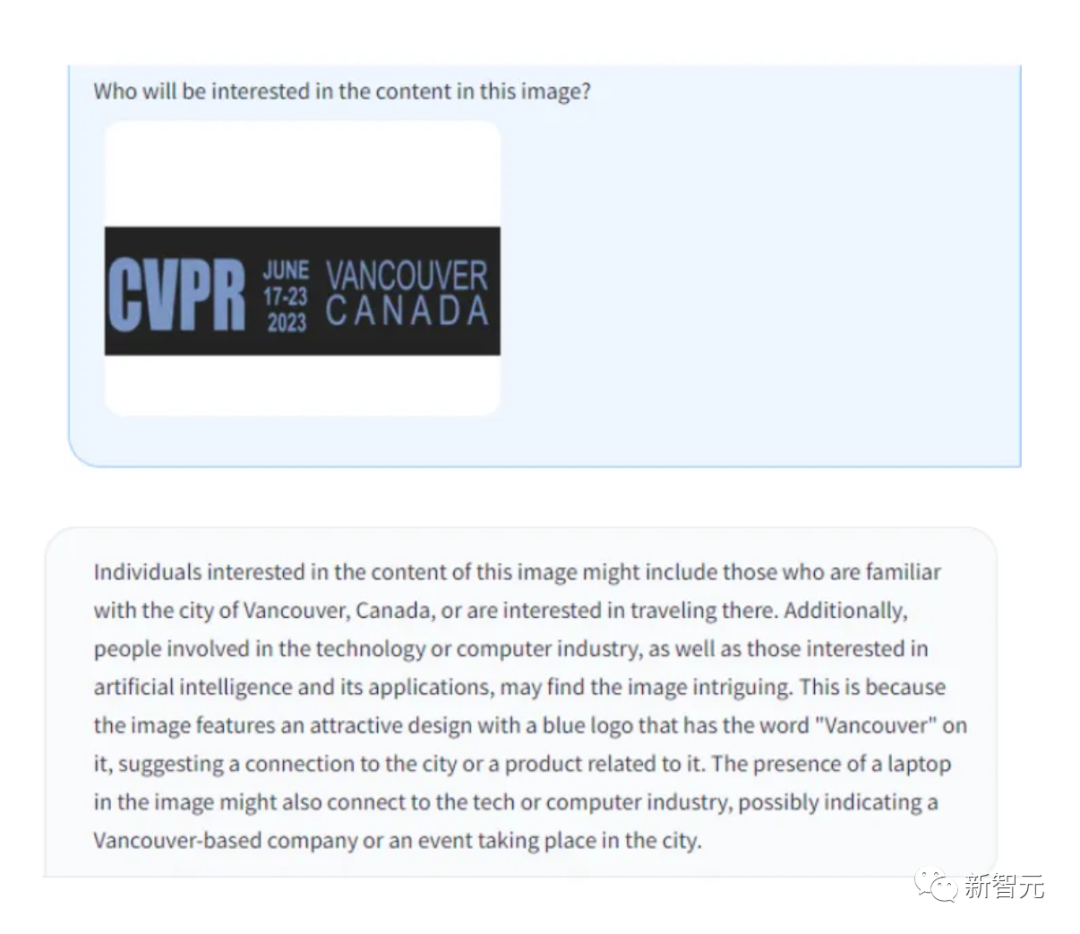
OCR 인식, LLaVA의 성능도 매우 강력합니다.
 Pictures
Pictures
 Pictures
Pictures
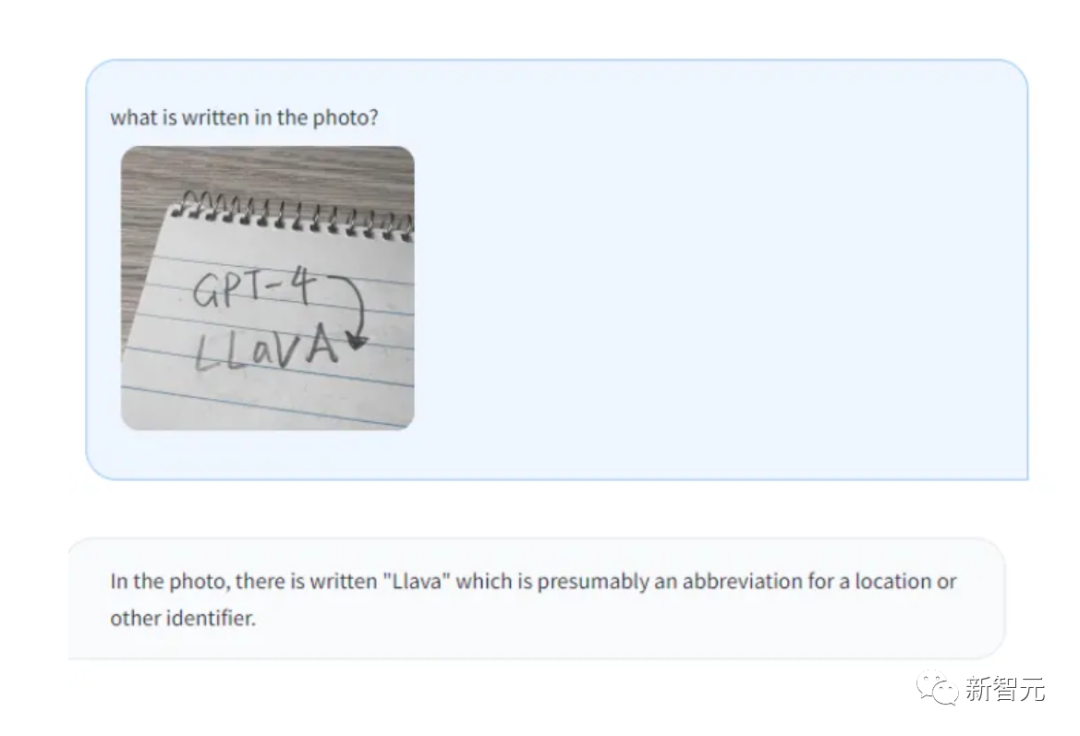 Pictures
Pictures
CogAgent
CogAgent는 칭화대학교 연구원인 CogVLM을 기반으로 개선된 오픈 소스 시각 언어 모델입니다.
CogAgent-18B에는 110억 개의 시각적 매개변수와 70억 개의 언어 매개변수가 있습니다.
 Pictures
Pictures
문서 주소: https://arxiv.org/pdf/2312.08914.pdf
CogAgent-18B는 9개의 클래식 크로스 모달 벤치마크(VQAv2, OK-VQ, TextVQA, ST-VQA, ChartQA, infoVQA, DocVQA, MM-Vet 및 POPE 포함)에서 최첨단 일반 성능을 달성합니다.
AITW 및 Mind2Web과 같은 GUI 조작 데이터 세트에서 기존 모델보다 훨씬 뛰어난 성능을 발휘합니다.
CogVLM(시각화된 다중 회전 대화, 시각적 접지)의 모든 기존 기능 외에도 CogAgent.NET은 더 많은 기능을 제공합니다.
1. 더 높은 해상도의 시각적 입력 및 대화 응답을 지원합니다. 1120x1120의 초고해상도 이미지 입력을 지원합니다.
2. 에이전트를 시각화하는 기능이 있으며 그래픽 사용자 인터페이스 스크린샷에서 주어진 작업에 대한 좌표와 함께 계획, 다음 작업 및 특정 작업을 반환할 수 있습니다.
3. 웹 페이지, PC 애플리케이션, 모바일 애플리케이션 등 모든 GUI의 스크린샷과 관련된 문제를 처리할 수 있도록 GUI 관련 질문 답변 기능이 향상되었습니다.
4. 향상된 사전 훈련 및 미세 조정을 통해 OCR 관련 작업 기능이 향상되었습니다.
GUI Agent
CogAgent를 사용하면 CVPR23의 최고의 논문을 단계별로 찾는 데 도움이 될 수 있습니다.
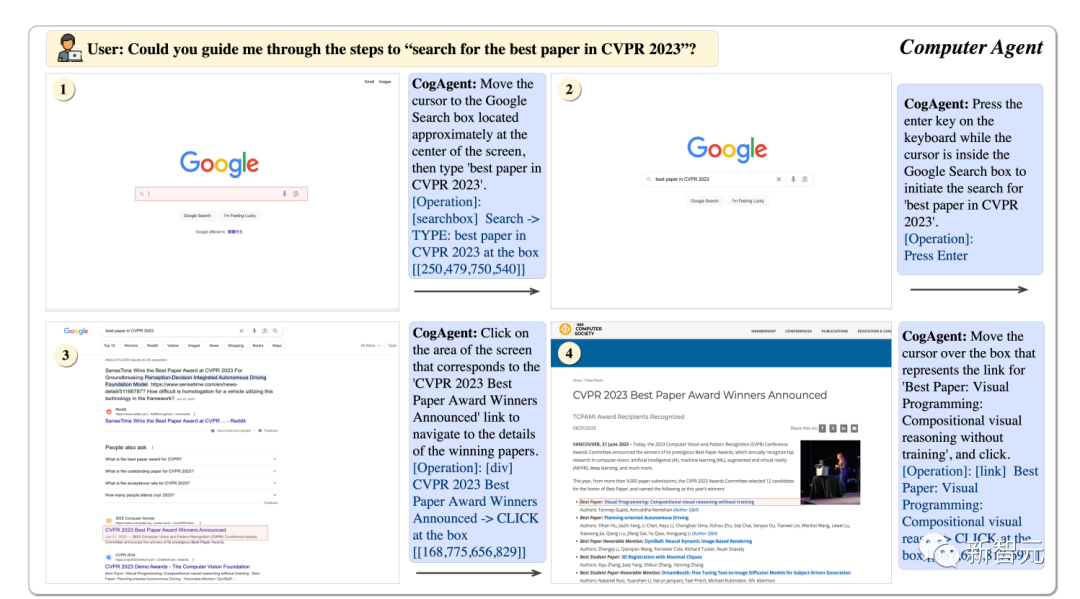 Pictures
Pictures
를 사용하면 휴대전화 디스플레이를 밝은 모드로 전환할 수 있습니다.
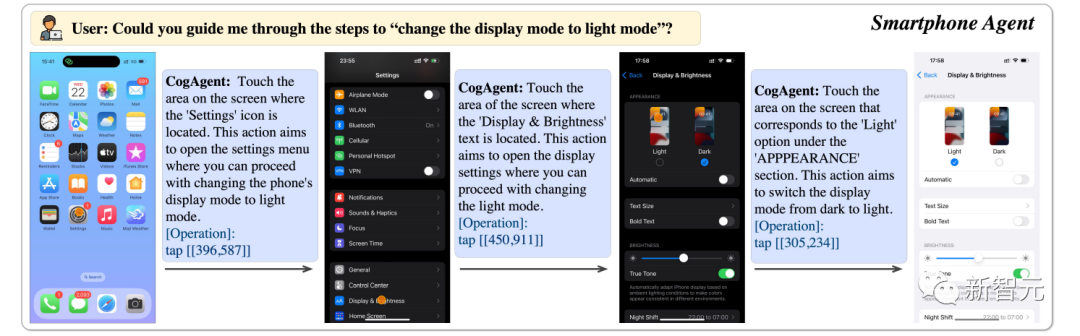 Pictures
Pictures
이 트윗의 좋아요와 리트윗 수, 그리고 이 트윗이 인기 있는 이유는 CogAgent에서 분석할 수 있으며 "Brilliant"라고 답장할 수도 있습니다.
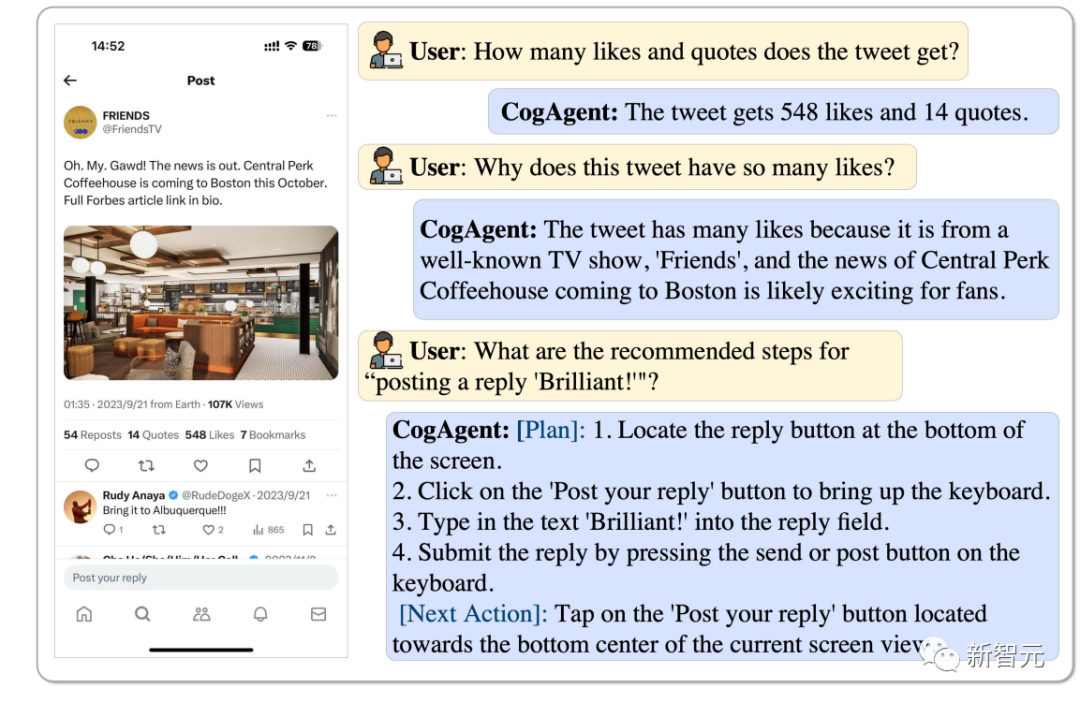 Pictures
Pictures
플로리다 대학교에서 할리우드까지 가장 빠른 경로를 선택하는 방법은 무엇인가요? 오전 8시에 시작한다면 얼마나 걸릴지 어떻게 추정하나요? CogAgent가 모두 답변해 드립니다.
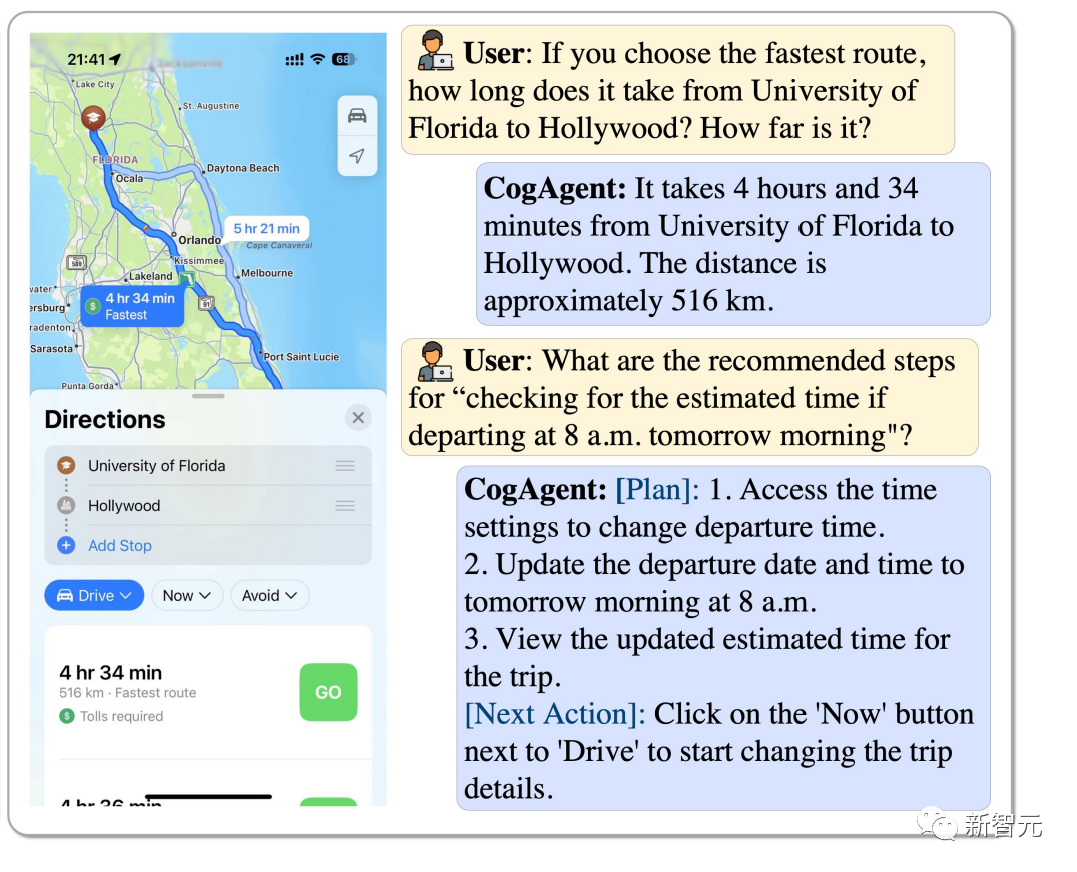 Pictures
Pictures
특정 테마를 설정하고 CogAgent가 지정된 사서함으로 이메일을 보내도록 할 수 있습니다.
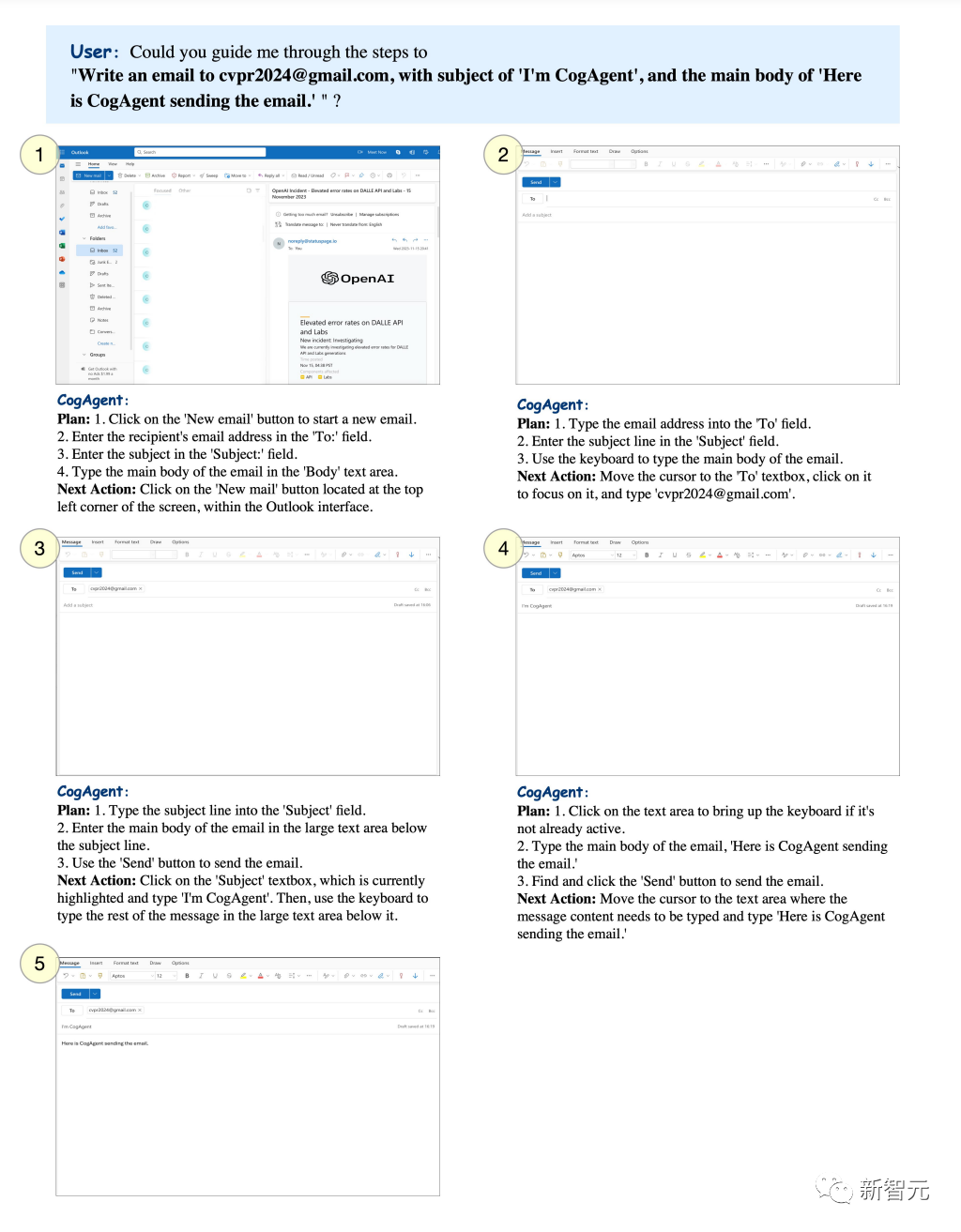 Pictures
Pictures
"You raise me up"이라는 노래를 듣고 싶다면 CogAgent에서 단계별로 단계를 나열할 수 있습니다.
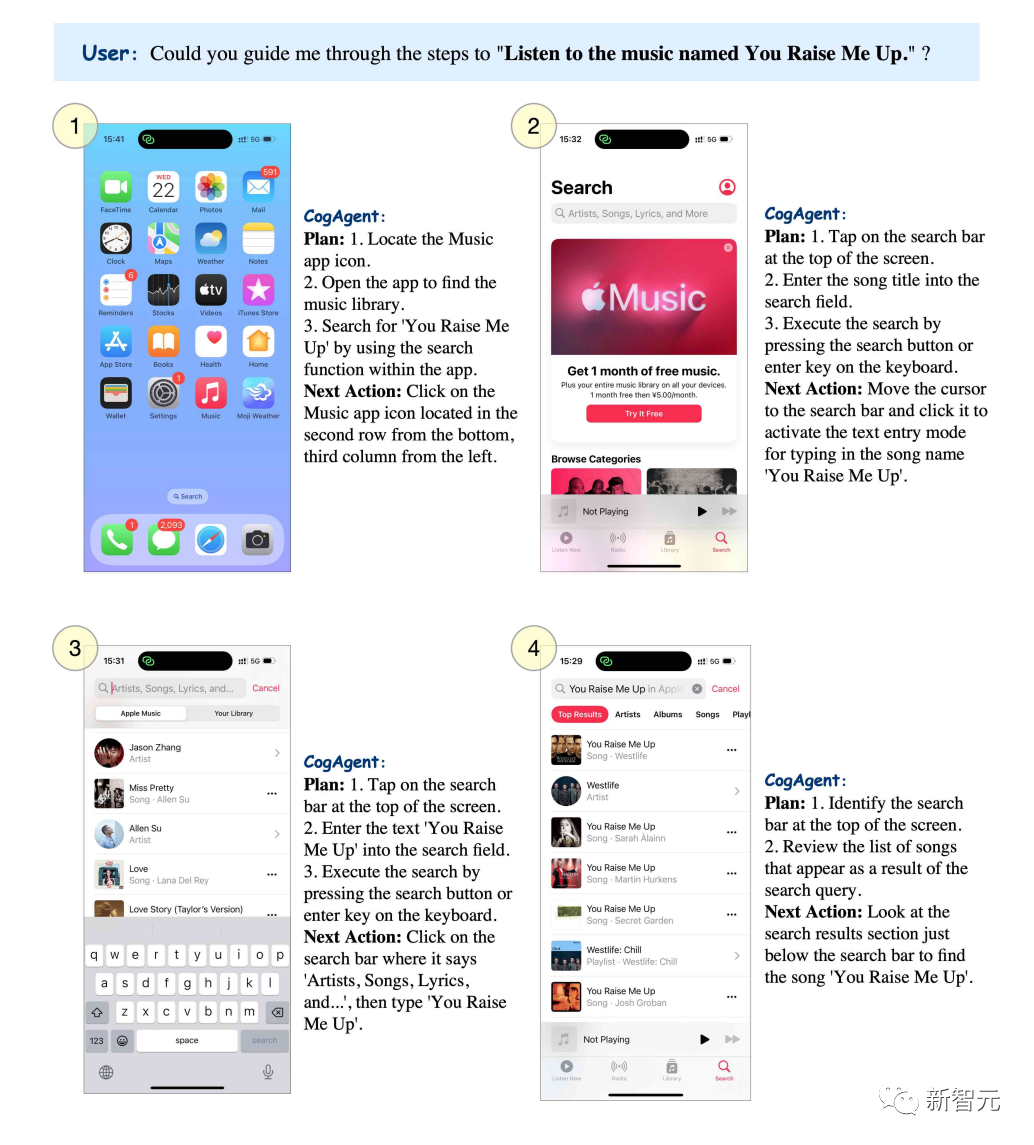 Pictures
Pictures
CogAgent는 "원신임팩트"의 장면을 정확하게 설명할 수 있으며 순간이동 지점으로 이동하는 방법도 안내할 수 있습니다.
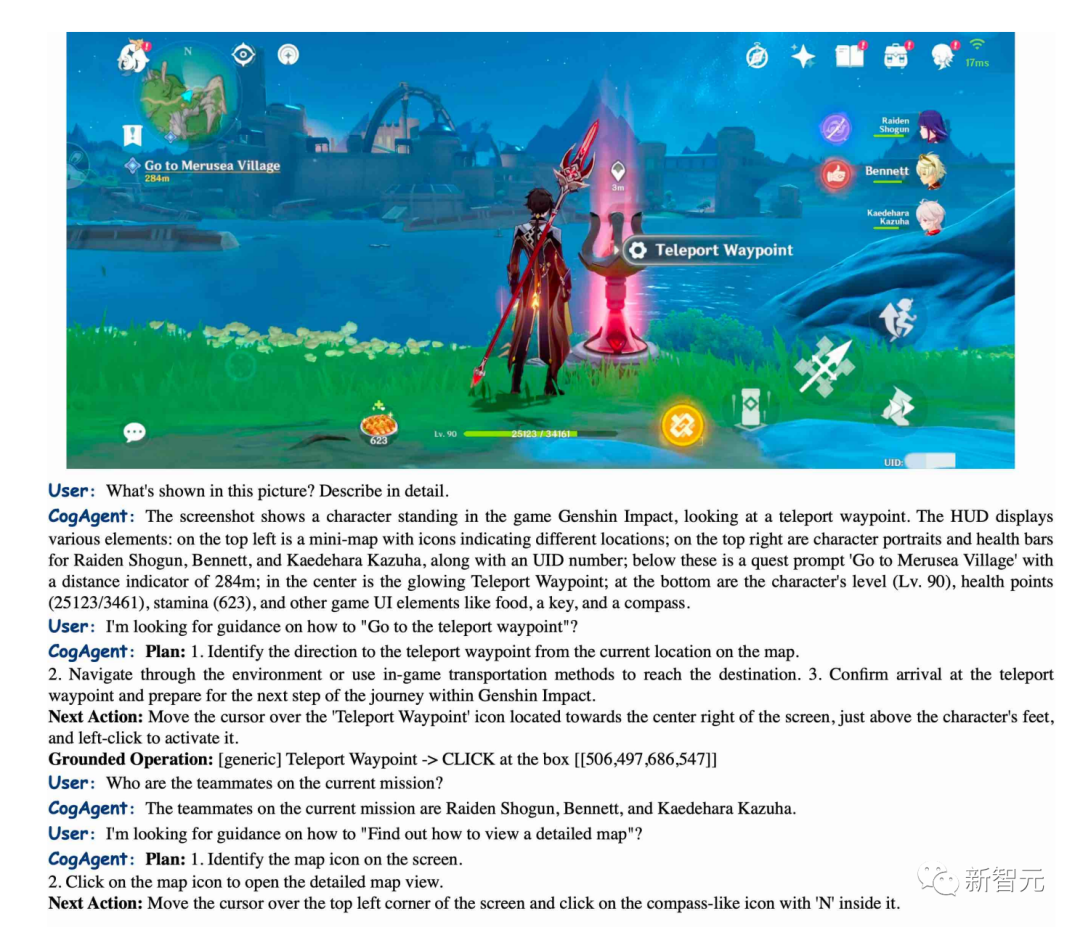 Pictures
Pictures
BakLLaVA
BakLLaVA1은 LLaVA 1.5 아키텍처로 향상된 Mistral 7B 기본 모델입니다.
첫 번째 버전에서는 Mistral 7B 기본 모델이 여러 벤치마크에서 Llama 2 13B보다 성능이 뛰어났습니다.
해당 저장소에서 BakLLaVA-1을 실행할 수 있습니다. 페이지는 미세 조정과 추론을 용이하게 하기 위해 지속적으로 업데이트됩니다. (https://github.com/SkunkworksAI/BakLLaVA)
BakLLaVA-1은 완전한 오픈 소스이지만 LLaVA의 코퍼스를 포함한 일부 데이터에 대해 훈련되었으므로 상업적인 사용이 허용되지 않습니다.
BakLLaVA 2는 더 큰 데이터 세트와 업데이트된 아키텍처를 사용하여 현재 LLaVa 방법을 능가합니다. BakLLaVA는 BakLLaVA-1의 한계를 없애고 상업적으로 사용될 수 있습니다.
참조:
https://yousefhosni.medium.com/discover-4-open-source-alternatives-to-gpt-4-vision-82be9519dcc5
위 내용은 Tsinghua University와 Zhejiang University는 오픈 소스 시각적 모델의 폭발적인 증가를 주도하고 GPT-4V, LLaVA, CogAgent 및 기타 플랫폼은 혁신적인 변화를 가져옵니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!