
4090 생성기: A100 플랫폼과 비교하면 토큰 생성 속도는 18% 미만이며 추론 엔진에 제출하는 것이 뜨거운 논의를 불러일으켰습니다.

- 王林앞으로
- 2023-12-21 15:25:411869검색
PowerInfer는 소비자급 하드웨어에서 AI 실행 효율성을 향상시킵니다.
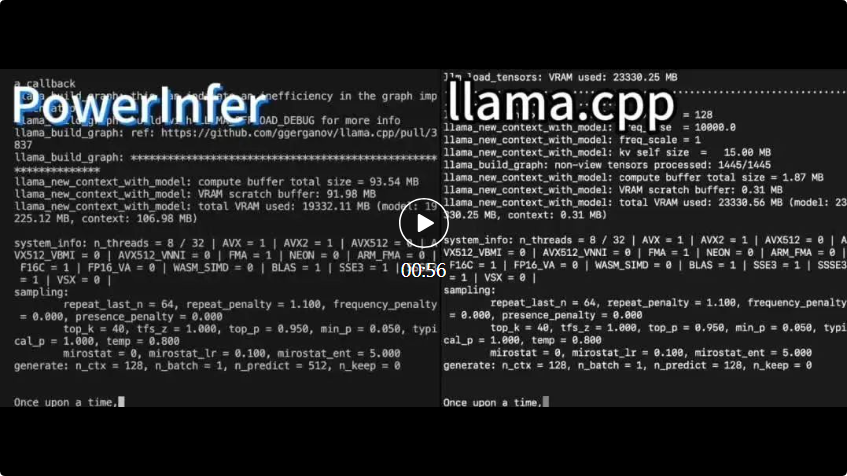 PowerInfer 및 라마. cpp는 둘 다 동일한 하드웨어에서 실행되며 RTX 4090의 VRAM을 최대한 활용합니다.
PowerInfer 및 라마. cpp는 둘 다 동일한 하드웨어에서 실행되며 RTX 4090의 VRAM을 최대한 활용합니다. PowerInfer 로컬 고급 LLM 추론 프레임워크 llama.cpp와 비교하여 단일 RTX 4090(24G)에서 Falcon(ReLU)-40B-FP16 모델을 실행하면 11배 이상의 가속을 달성할 뿐만 아니라 모델 정확도도 유지됩니다
PowerInfer는 LLM의 온프레미스 배포를 위해 설계된 고속 추론 엔진입니다. 다중 전문가 시스템(MoE)과 달리 PowerInfer는 LLM 추론의 높은 지역성을 완전히 활용하는 GPU-CPU 하이브리드 추론 엔진을 교묘하게 설계했습니다.
자주 활성화되는 뉴런(예: 핫 활성화)을 GPU에 미리 로드합니다. 빠른 액세스를 위해 자주 활성화되지 않는 뉴런 (즉, 콜드 활성화)는 CPU에서 계산됩니다. 작동 방식은 다음과 같습니다
이 방법을 사용하면 GPU 메모리 요구 사항과 CPU와 GPU 간의 데이터 전송량을 크게 줄일 수 있습니다

프로젝트 링크: https://github.com/SJTU-IPADS/ PowerInfer
-
문서 링크: https://ipads.se.sjtu.edu.cn/_media/publications/powerinfer-20231219.pdf
PowerInfer는 단일 소비자급 GPU가 장착된 PC에서 LLM을 고속으로 실행할 수 있습니다. 이제 사용자는 Llama 2 및 Faclon 40B와 함께 PowerInfer를 사용할 수 있으며 Mistral-7B도 곧 지원될 예정입니다.
PowerInfer는 하루 만에 2K 별을 획득했습니다
이 연구를 본 후 네티즌들은 흥분을 표현했습니다. 이제 단일 카드 4090으로 더 이상 꿈이 아닌 175B의 대형 모델을 실행할 수 있습니다.
PowerInfer 아키텍처
PowerInfer 설계의 핵심은 뉴런 활성화의 거듭제곱 법칙 분포를 특징으로 하는 LLM 추론에 내재된 높은 수준의 지역성을 활용하는 것입니다. 이 분포는 핫 뉴런이라고 불리는 뉴런의 작은 하위 집합이 입력 전반에 걸쳐 일관되게 활성화되는 반면, 콜드 뉴런의 대부분은 특정 입력에 따라 달라짐을 나타냅니다. PowerInfer는 이 메커니즘을 활용하여 GPU-CPU 하이브리드 추론 엔진을 설계합니다.
오프라인 및 온라인 구성 요소를 포함하여 PowerInfer의 아키텍처 개요를 보여주는 아래 그림 7을 참조하세요. 오프라인 구성 요소는 핫 뉴런과 콜드 뉴런을 구별하면서 LLM의 활성화 희소성을 처리하는 역할을 합니다. 온라인 단계에서 추론 엔진은 두 가지 유형의 뉴런을 모두 GPU와 CPU에 로드하고 런타임에 짧은 대기 시간으로 LLM 요청을 처리합니다
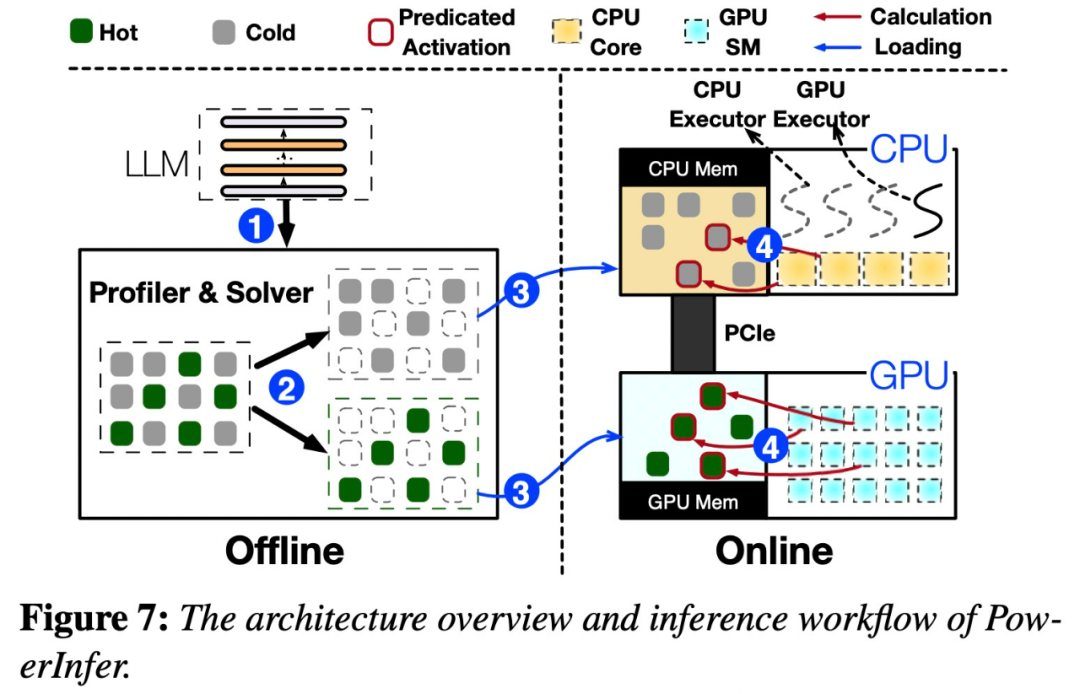
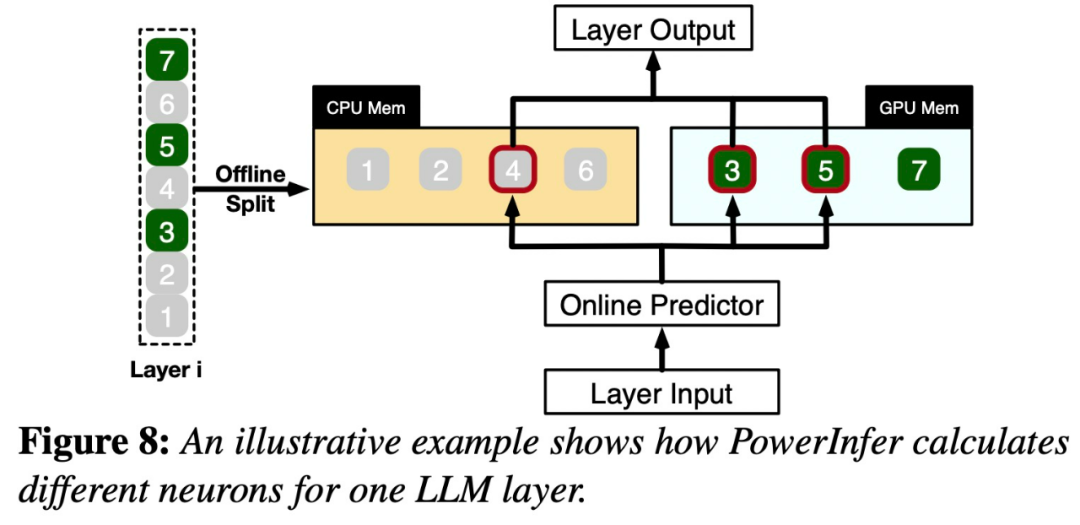
그림 8은 PowerInfer의 작동 방식을 보여줍니다. 이는 GPU와 CPU 처리 뉴런 간의 레이어를 조정합니다. PowerInfer는 오프라인 데이터를 통해 뉴런을 분류하여 활성 뉴런(예: 인덱스 3, 5, 7)을 GPU 메모리에 할당하고 기타 뉴런을 CPU 메모리에 할당합니다
입력이 수신되면 예측기는 현재 계층에서 활성화될 가능성이 있는 뉴런을 식별합니다. 오프라인 통계 분석을 통해 식별된 열 활성화 뉴런은 런타임 시 실제 활성화 동작과 일치하지 않을 수 있다는 점에 유의해야 합니다. 예를 들어, 뉴런 7은 열적으로 활성화된 것으로 표시되어 있지만 실제로는 그렇지 않습니다. 그런 다음 CPU와 GPU는 이미 활성화된 뉴런을 처리하고 그렇지 않은 뉴런은 무시합니다. GPU는 뉴런 3과 5를 계산하는 역할을 하고, CPU는 뉴런 4를 처리합니다. 뉴런 4의 계산이 완료되면 결과 통합을 위해 출력이 GPU로 전송됩니다.
원래 의미를 변경하지 않고 콘텐츠를 다시 작성하려면 언어를 중국어로 다시 작성해야 합니다. 원래 문장이 나타날 필요는 없습니다
이 연구는 다양한 매개변수를 사용하여 OPT 모델을 사용하여 수행되었습니다. 원래 의미를 변경하지 않고 내용을 다시 작성하려면 언어를 중국어로 다시 작성해야 합니다. 원문을 제시할 필요가 없으며 매개변수 범위는 6.7B ~ 175B이며 Falcon(ReLU)-40B 및 LLaMA(ReGLU)-70B 모델도 포함되어 있습니다. 175B 매개변수 모델의 크기가 GPT-3 모델과 비슷하다는 점은 주목할 가치가 있습니다.
이 기사에서는 PowerInfer를 최첨단 기본 LLM 추론 프레임워크인 llama.cpp와 비교합니다. 비교를 용이하게 하기 위해 이 연구에서는 llama.cpp를 확장하여 OPT 모델을 지원했습니다
이 기사의 초점이 낮은 대기 시간 설정에 있다는 점을 고려하면 평가 지표는 수 측면에서 엔드투엔드 생성 속도를 채택합니다. 정량화를 위해 초당 생성된 토큰(토큰/초)
이 연구에서는 먼저 배치 크기 1
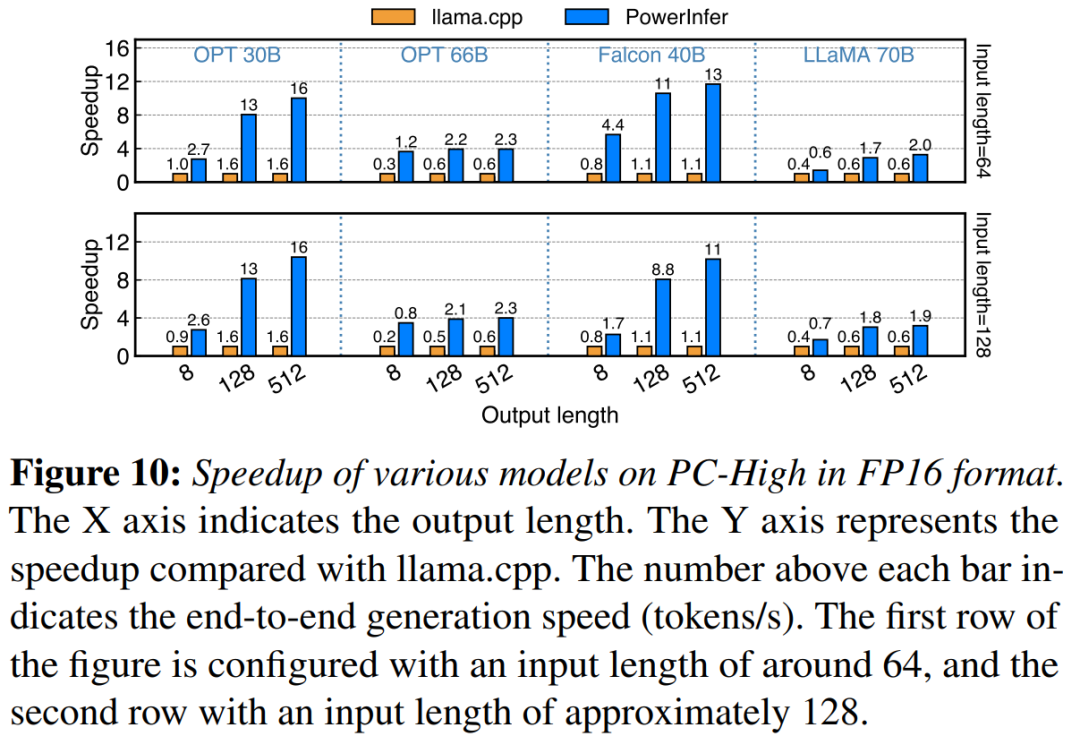
NVIDIA RTX 4090을 사용하는 PC-High에서 PowerInfer와 llama.cpp의 엔드투엔드 추론 성능을 비교합니다. 그림 10 다양한 모델과 입력 및 출력 구성의 생성 속도를 보여줍니다. 평균적으로 PowerInfer는 8.32 토큰/초, 최대 16.06 토큰/초의 생성 속도를 달성합니다. 이는 llama.cpp보다 훨씬 우수하고, llama.cpp보다 7.23배 더 높으며, Falcon-40B
보다 11.69배 더 높습니다. 후속 출력 토큰 수가 증가함에 따라 생성 단계가 전체 추론 시간에서 더 중요한 역할을 하기 때문에 PowerInfer의 성능 이점이 더욱 분명해집니다. 이 단계에서는 CPU와 GPU 모두에서 소수의 뉴런이 활성화되므로 llama.cpp에 비해 불필요한 계산이 줄어듭니다. 예를 들어 OPT-30B의 경우 생성된 토큰당 약 20%의 뉴런만 활성화되며, 대부분은 GPU에서 처리됩니다. 이는 그림에서 PowerInfer 뉴런 인식 추론
의 이점입니다. 11 그림에서 볼 수 있듯이 PowerInfer는 PC-Low에서 실행했음에도 불구하고 평균 5.01배, 최대 7.06배의 속도 향상으로 상당한 성능 향상을 달성했습니다. 그러나 이러한 개선 사항은 주로 PC-Low의 11GB GPU 메모리 제한으로 인해 PC-High에 비해 작습니다. 이 제한은 특히 약 30B 이상의 매개변수가 있는 모델의 경우 GPU에 할당할 수 있는 뉴런 수에 영향을 미치므로 많은 수의 활성화된 뉴런을 처리하기 위해 CPU에 대한 의존도가 높아집니다.
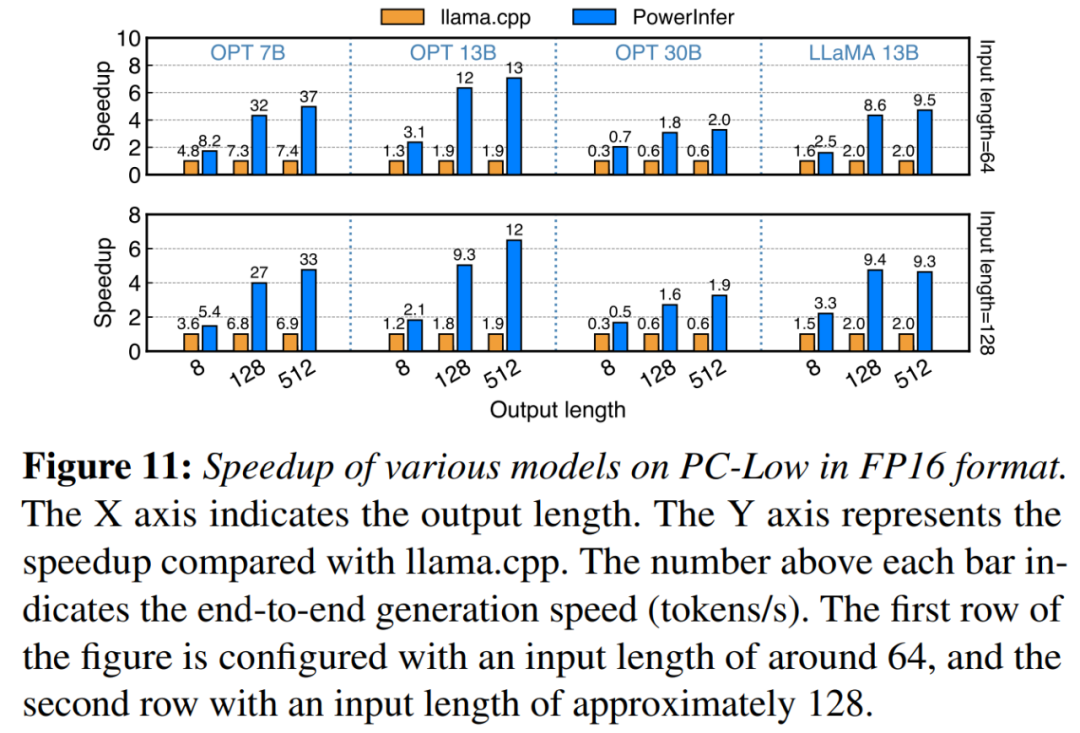
그림 12는 PowerInfer 및 뉴런을 보여줍니다. llama.cpp 사이의 CPU와 GPU 간의 부하 분산. 특히 PC-High에서 PowerInfer는 GPU의 뉴런 로드 점유율을 평균 20%에서 70%로 크게 늘렸습니다. 이는 GPU가 활성화된 뉴런의 70%를 처리한다는 것을 보여줍니다. 그러나 11GB 2080Ti GPU에서 60GB 모델을 실행하는 등 모델의 메모리 요구 사항이 GPU 용량을 훨씬 초과하는 경우 GPU의 뉴런 부하가 42%로 감소합니다. 이러한 감소는 활성화된 모든 뉴런을 수용하기에는 충분하지 않은 GPU의 제한된 메모리로 인해 발생합니다. 따라서 CPU는 뉴런의 하위 집합을 계산해야 합니다.

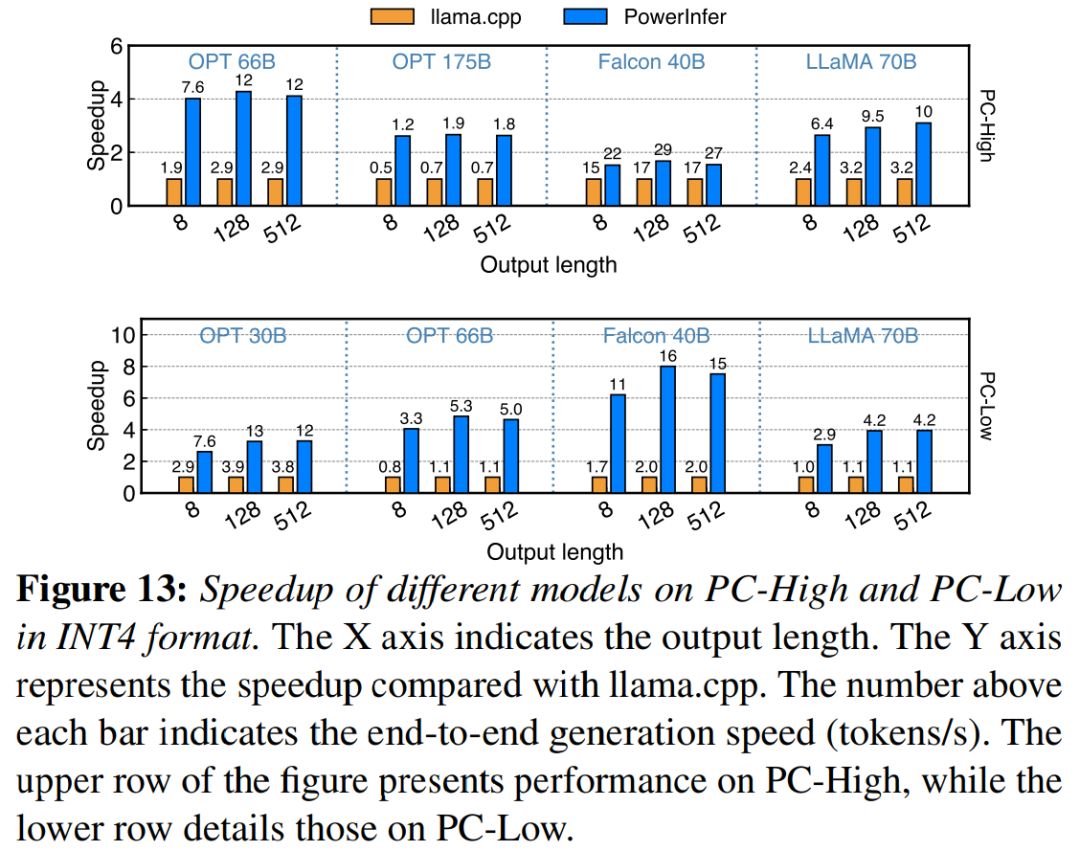
그림 13은 PowerInfer가 INT4 양자화 압축을 사용하여 LLM을 효과적으로 지원한다는 것을 보여줍니다. PC-High에서 PowerInfer의 평균 응답 속도는 13.20 토큰/초이며, 최대 응답 속도는 29.08 토큰/초입니다. llama.cpp와 비교하면 평균 속도 향상은 2.89배이고 최대 속도 향상은 4.28배입니다. PC-Low에서 평균 속도 향상은 5.01x이고 최대 속도 향상은 8.00x입니다. 양자화로 인해 메모리 요구 사항이 줄어들기 때문에 PowerInfer는 더 큰 모델을 보다 효율적으로 관리할 수 있습니다. 예를 들어 PC-High에서 OPT-175B 모델을 사용하려면 원래 의미를 변경하지 않고 내용을 다시 작성하기 위해 언어를 중국어로 다시 작성해야 했습니다. 원래 문장에 나타날 필요 없이 PowerInfer는 초당 거의 두 개의 토큰에 도달하여 llama.cpp를 2.66배 초과합니다.
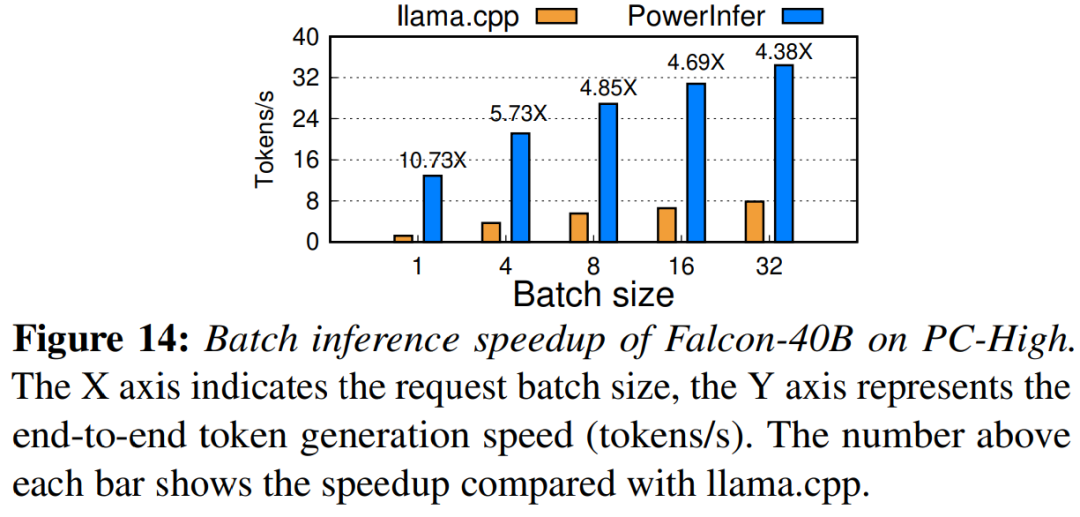
마지막으로 이 연구에서는 다양한 배치 크기에서 PowerInfer의 엔드투엔드 추론 성능도 평가합니다. 그림 14에서 볼 수 있듯이 배치 크기가 32 미만인 경우 PowerInfer는 라마에 비해 평균 6.08배의 성능 향상을 보이는 등 상당한 이점을 보여줍니다. 배치 크기가 증가하면 PowerInfer가 제공하는 속도 향상은 감소합니다. 그러나 배치 크기를 32로 설정하더라도 PowerInfer는 여전히 상당한 속도 향상을 유지합니다
참조 링크: https://weibo.com/1727858283/NxZ0Ttdnz
원본 논문을 확인하여 알아보십시오. 더 많은 콘텐츠
위 내용은 4090 생성기: A100 플랫폼과 비교하면 토큰 생성 속도는 18% 미만이며 추론 엔진에 제출하는 것이 뜨거운 논의를 불러일으켰습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!