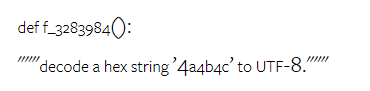Google Gemini의 무게는 얼마나 되나요? OpenAI의 GPT 모델과 어떻게 비교됩니까? 이 CMU 논문에는 명확한 측정 결과가 있습니다
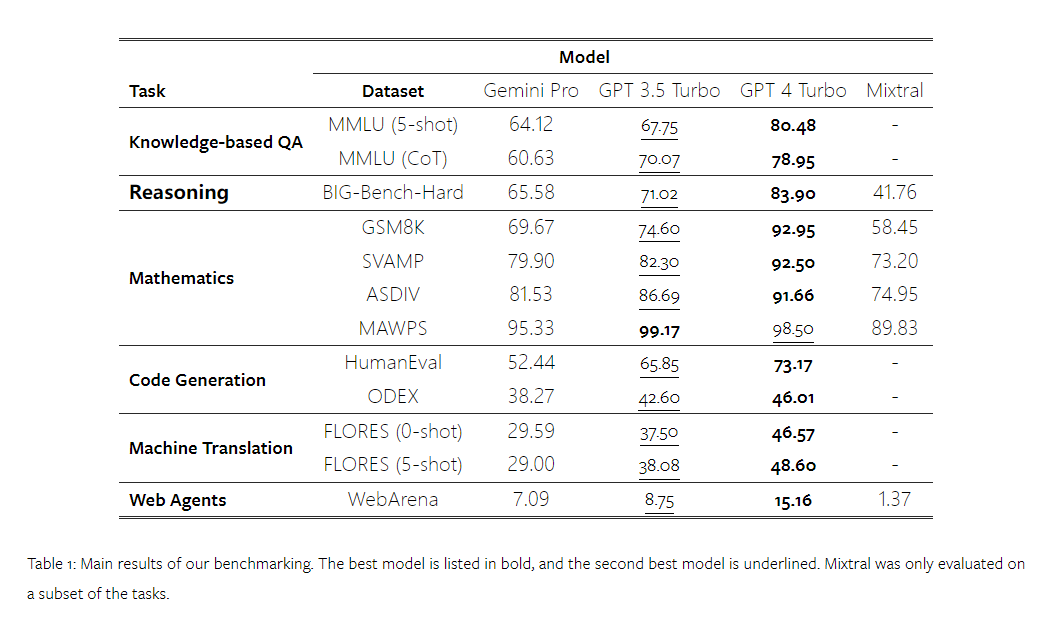
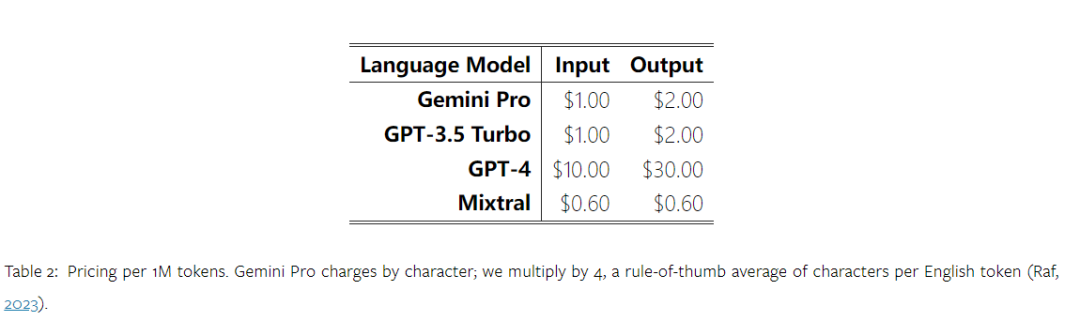
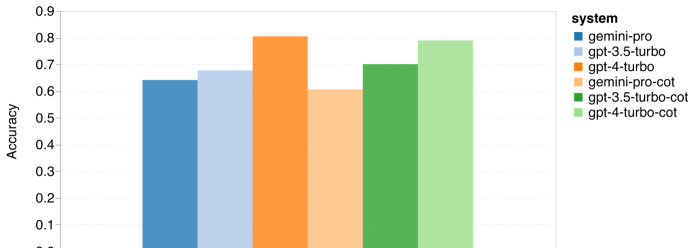
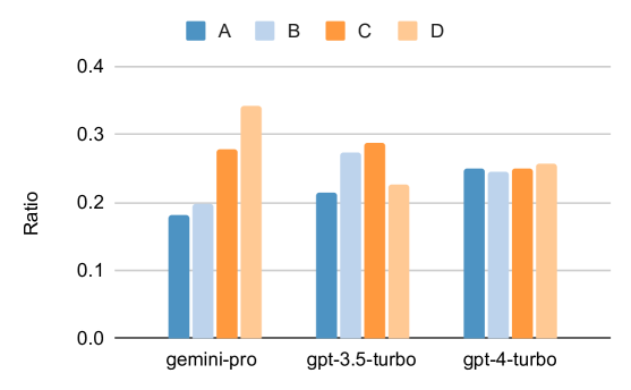
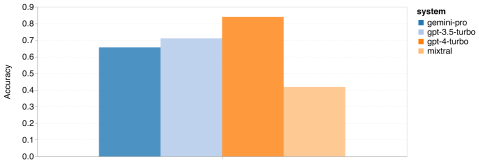
얼마 전 Google은 OpenAI GPT 모델의 경쟁자인 Gemini를 출시했습니다. 이 대형 모델은 Ultra(가장 뛰어난 기능), Pro 및 Nano의 세 가지 버전으로 제공됩니다. 연구팀이 발표한 테스트 결과에 따르면 Ultra 버전은 여러 작업에서 GPT4보다 성능이 뛰어난 반면 Pro 버전은 GPT-3.5와 동등한 성능을 보였습니다. 이러한 비교 결과는 대규모 언어 모델 연구에 큰 의미가 있지만 아직 정확한 평가 내용과 모델 예측이 공개되지 않았기 때문에 이로 인해 테스트 결과의 재현 및 탐지가 제한되어 어렵습니다. 암시적인 세부 사항을 추가로 분석합니다. Gemini의 진정한 강점을 이해하기 위해 Carnegie Mellon University와 BerriAI의 연구원들은 모델의 언어 이해 및 생성 기능에 대한 심층적인 탐색을 수행했습니다. 그들은 10개의 데이터 세트에서 Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo 및 Mixtral의 텍스트 이해 및 생성 기능을 테스트했습니다. 구체적으로 그들은 MMLU에 대한 지식 기반 질문에 답하는 모델의 능력, BigBenchHard에 대한 모델의 추론 능력, GSM8K와 같은 데이터 세트의 수학적 질문에 답하는 모델의 능력, 다음과 같은 데이터 세트에 있는 수학적 질문에 답하는 모델의 능력을 테스트했습니다. FLORES. 모델의 코드 생성 능력은 HumanEval과 같은 데이터 세트에서 테스트되었습니다. 지침을 따르는 모델의 능력은 WebArena에서 테스트되었습니다. 아래 표 1은 주요 비교 결과를 보여줍니다. 전반적으로, 논문 출판일 기준으로 Gemini Pro는 모든 작업에서 정확도가 OpenAI GPT 3.5 Turbo에 가깝지만 여전히 약간 열등합니다. 또한 오픈소스 경쟁 모델인 Mixtral보다 Gemini와 GPT가 더 나은 성능을 발휘한다는 사실도 발견했습니다. 논문에서 저자는 각 작업에 대한 심층적인 설명과 분석을 제공합니다. 모든 결과와 재현 가능한 코드는 https://github.com/neulab/gemini-benchmark문서 링크: https://arxiv.org/pdf/2312.11444.pdf저자는 Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo, Mixtral의 4개 모델을 테스트 대상으로 선택했습니다. 기존 연구에서는 평가 시 실험 설정의 차이로 인해 공정한 테스트를 보장하기 위해 저자는 정확히 동일한 프롬프트 단어와 평가 프로토콜을 사용하여 실험을 다시 실행했습니다. 대부분의 평가에서는 표준 저장소의 프롬프트 단어와 루브릭을 사용했습니다. 이러한 테스트 리소스는 모델 릴리스 및 평가 도구 Eleuther 등과 함께 제공되는 데이터 세트에서 제공됩니다. 그 중 프롬프트 단어에는 일반적으로 쿼리, 입력, 소수의 예, 사고 연쇄 추론 등이 포함됩니다. 일부 특별 평가에서 저자는 표준 관행에 대한 사소한 조정이 필요하다는 사실을 발견했습니다. 바이어스 조정은 해당 코드 저장소에서 수행되었습니다. 원본 논문을 참조하세요. 1 재현 가능한 코드와 완전히 투명한 결과를 통해 OpenAI GPT 및 Google Gemini 모델의 기능에 대한 제3자 객관적인 비교를 제공합니다. 2. 평가 결과를 심층적으로 연구하고 두 모델이 어떤 분야에서 더 두드러지는지 분석해 보세요. 저자는 MMLU 데이터 세트에서 STEM, 인문학, 사회과학 등 주제를 다루는 57개의 지식 기반 객관식 문답 과제를 선택했습니다. MMLU는 총 14,042개의 테스트 샘플을 보유하고 있으며 대규모 언어 모델의 지식 기능에 대한 전반적인 평가를 제공하는 데 널리 사용되었습니다. 저자는 MMLU에 대한 4가지 테스트 개체의 전체 성능(아래 그림 참조)과 하위 작업 성능, 출력 길이가 성능에 미치는 영향을 비교 분석했습니다. 그림 1: 5개의 샘플 프롬프트와 사고 체인 프롬프트를 사용한 MMLU의 각 모델의 전반적인 정확도. 그림에서 볼 수 있듯이 Gemini Pro의 정확도는 GPT 3.5 Turbo보다 낮고 GPT 4 Turbo보다 훨씬 낮습니다.사고체인 프롬프트를 사용할 경우 각 모델의 성능에는 거의 차이가 없습니다. 저자는 이것이 MMLU가 주로 지식 기반 질문 및 답변 작업을 포착한다는 사실 때문이라고 추측하며, 이는 더 강력한 추론 지향 프롬프트에서 큰 이점을 얻지 못할 수 있습니다. MMLU의 모든 질문은 A부터 D까지 4개의 잠재적 답변이 순서대로 배열된 객관식 질문이라는 점에 주목할 가치가 있습니다. 아래 그래프는 각 모델이 선택한 각 답변 옵션의 비율을 보여줍니다. 그림에서 Gemini의 답변 분포가 마지막 옵션 D를 선택하는 쪽으로 매우 치우쳐 있음을 알 수 있습니다. 이는 GPT 버전에서 제공되는 보다 균형 잡힌 결과와 대조됩니다. 이는 Gemini가 객관식 질문과 관련된 광범위한 지침 조정을 받지 못해 모델의 답변 순위에 편향이 발생했음을 나타낼 수 있습니다. 그림 2: 테스트된 모델에서 예측한 객관식 질문에 대한 답변 비율.
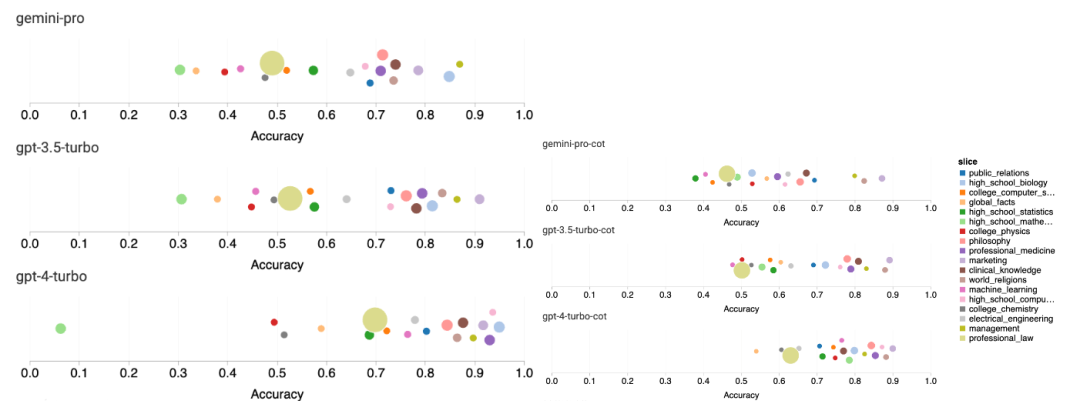
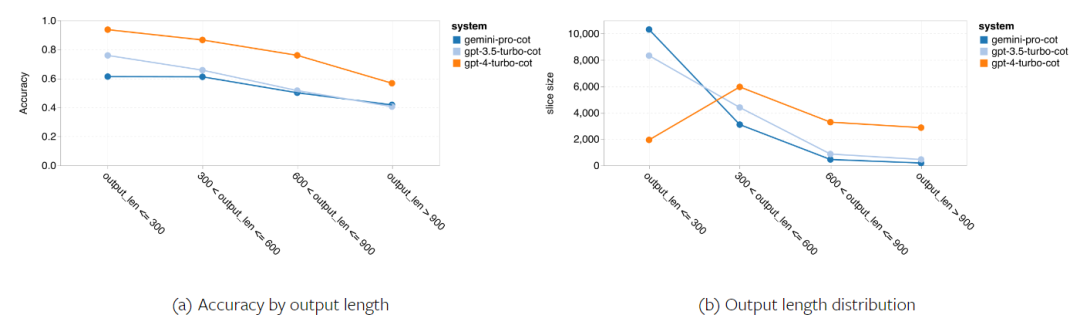
다음 그림은 MMLU 테스트 세트의 하위 작업에 대한 테스트 모델의 성능을 보여줍니다. Gemini Pro는 GPT 3.5에 비해 대부분의 작업에서 성능이 저하됩니다. 사고 사슬 프롬프트는 하위 작업 간의 차이를 줄입니다. 그림 3: 각 하위 작업에 대해 테스트된 모델의 정확도. 저자는 Gemini Pro의 강점과 약점을 심층적으로 살펴봅니다. 그림 4에서 볼 수 있듯이 Gemini Pro는 인간 성별(사회 과학), 형식 논리(인문학), 초등 수학(STEM) 및 전문 의학(전문 분야) 작업에서 GPT 3.5보다 뒤떨어집니다. Gemini Pro가 더 잘하는 두 가지 작업에서도 리드가 미미합니다. 그림 4: MMLU 작업에 대한 Gemini Pro 및 GPT 3.5의 장점. Gemini Pro의 특정 작업 성능이 저조한 것은 두 가지 이유 때문일 수 있습니다. 첫째, Gemini가 답변을 할 수 없는 상황이 있습니다. 대부분의 MMLU 하위 작업에서 API 응답률이 95%를 넘지만, 도덕성(응답률 85%)과 인간 성별(응답률 28%) 두 가지 작업에서는 해당 비율이 현저히 낮습니다. 이는 일부 작업에서 Gemini의 낮은 성능이 입력 콘텐츠 필터로 인한 것일 수 있음을 시사합니다. 둘째, Gemini Pro는 형식 논리 및 기본 수학 문제를 해결하는 데 필요한 기본 수학적 추론에서 약간 더 나쁩니다. 저자는 또한 그림 5와 같이 사고 사슬 프롬프트의 출력 길이가 모델 성능에 어떤 영향을 미치는지 분석했습니다. 일반적으로 더 강력한 모델은 더 복잡한 추론을 수행하는 경향이 있으므로 더 긴 답변을 출력합니다. Gemini Pro는 "상대"에 비해 주목할 만한 장점이 있습니다. 즉, 정확도가 출력 길이의 영향을 덜 받습니다. Gemini Pro는 출력 길이가 900을 초과할 때 GPT 3.5보다 성능이 뛰어납니다. 그러나 GPT 4 Turbo에 비해 Gemini Pro 및 GPT 3.5 Turbo는 긴 추론 체인을 거의 출력하지 않습니다. 그림 5: MMLU에서 테스트한 모델의 출력 길이 분석.
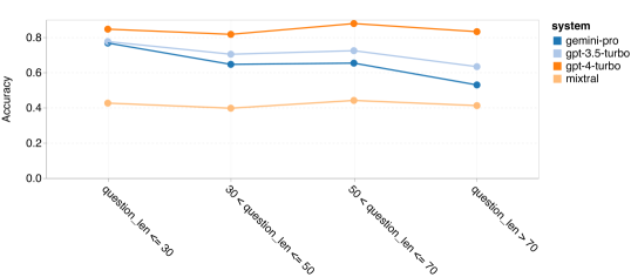
BIG-Bench Hard 테스트 세트에서 저자는 테스트 대상자의 범용 추론 능력을 평가했습니다. BIG-Bench Hard에는 산술, 기호 및 다중 언어 추론, 사실 지식 이해 등 27가지 다양한 추론 작업이 포함되어 있습니다. 대부분의 작업은 250개의 질문-답변 쌍으로 구성되며 일부 작업에는 질문 수가 약간 적습니다. 그림 6은 테스트된 모델의 전반적인 정확도를 보여줍니다. Gemini Pro의 정확도는 GPT 3.5 Turbo보다 약간 낮고 GPT 4 Turbo보다 훨씬 낮다는 것을 알 수 있습니다. 이에 비해 Mixtral 모델의 정확도는 훨씬 낮습니다. 그림 6: BIG-Bench-Hard에서 테스트한 모델의 전반적인 정확도.
저자는 Gemini 일반 추론이 전반적으로 저조한 이유에 대해 더 자세히 설명합니다. 먼저, 질문 길이에 따른 정확성을 조사했습니다. 그림 7에서 볼 수 있듯이 Gemini Pro는 더 길고 복잡한 문제에서는 제대로 수행되지 않습니다. 그리고 GPT 모델, 특히 GPT 4 Turbo는 매우 긴 문제에서도 GPT 4 Turbo의 회귀가 매우 작습니다. 이는 강력하고 더 길고 복잡한 질문과 쿼리를 이해할 수 있음을 보여줍니다. GPT 3.5 Turbo의 견고성은 평균 수준입니다. Mixtral은 질문 길이 측면에서 안정적인 성능을 보였지만 전반적인 정확도는 낮았습니다.그림 7: BIG-Bench-Hard에서 테스트한 모델의 질문 길이별 정확도.
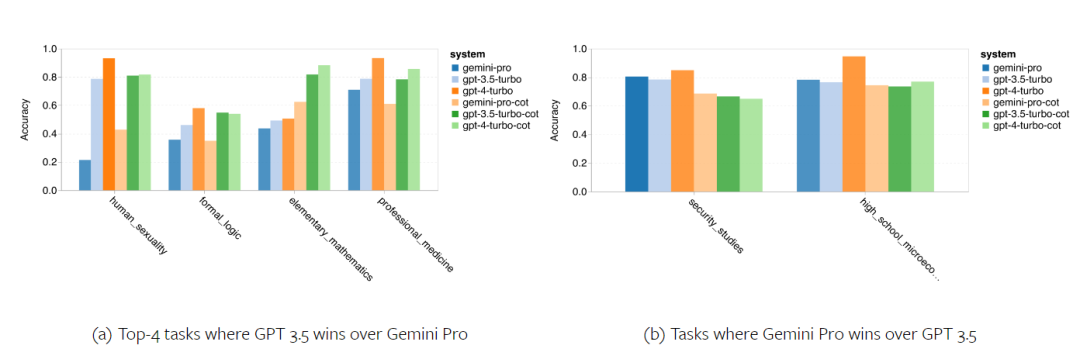
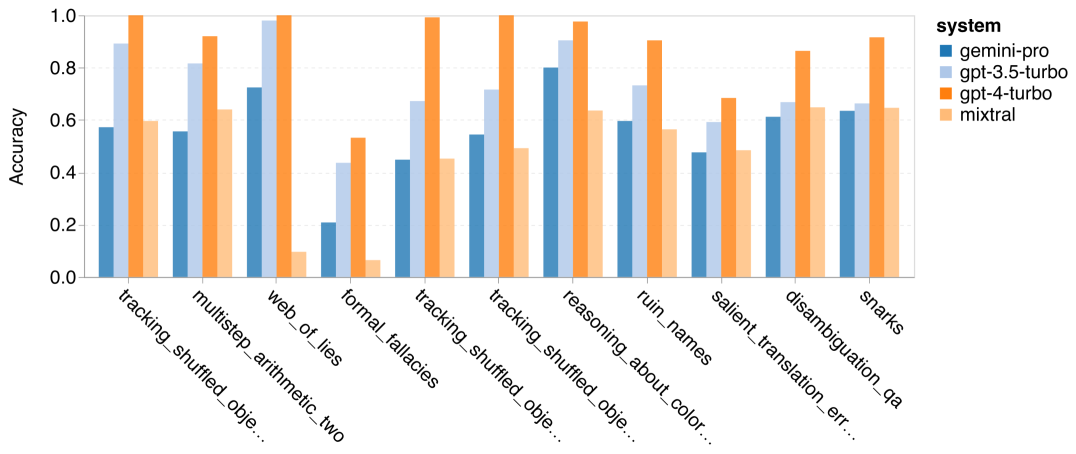
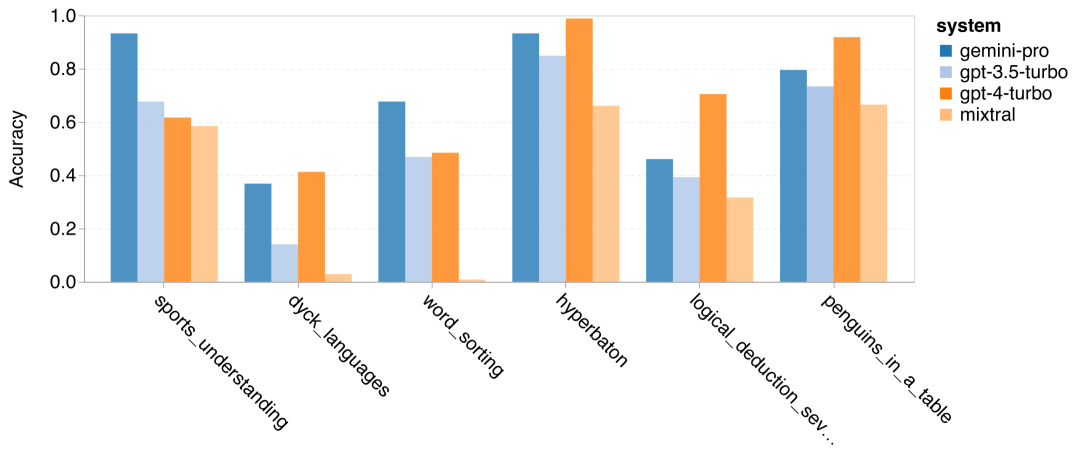
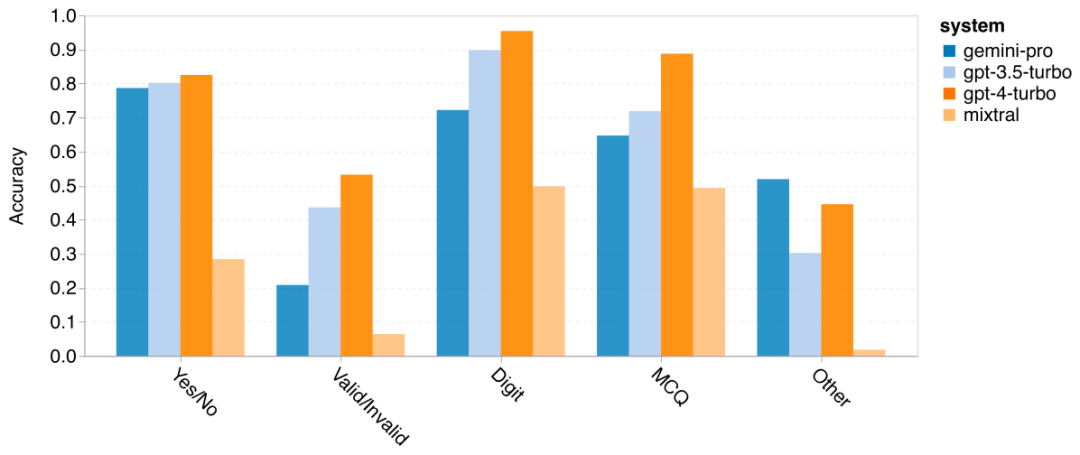
저자는 특정 BIG-Bench-Hard 작업에서 테스트한 모델의 정확도에 차이가 있는지 분석했습니다. 그림 8은 GPT 3.5 Turbo가 Gemini Pro보다 더 잘 수행하는 작업을 보여줍니다. "변형된 개체의 위치 추적" 작업에서 Gemini Pro는 특히 저조한 성능을 보였습니다. 이러한 작업에는 사람들이 물건을 교환하고 물건을 소유한 사람을 추적하는 것이 포함되지만 Gemini Pro는 주문을 올바르게 유지하는 데 종종 어려움을 겪었습니다. 그림 8: GPT 3.5 Turbo는 BIG-Bench-Hard 하위 작업에서 Gemini Pro보다 성능이 뛰어납니다. Gemini Pro는 다단계 솔루션이 필요한 산술 문제, 번역 오류 찾기 등과 같은 작업에서 Mixtral보다 열등합니다. GPT 3.5 Turbo보다 Gemini Pro가 더 나은 작업도 있습니다. 그림 9는 Gemini Pro가 GPT 3.5 Turbo를 가장 큰 차이로 앞서는 6가지 작업을 보여줍니다. 작업은 이질적이며 세계 지식(sports_understanding), 기호 스택 조작(dyck_langes), 알파벳순으로 단어 정렬(word_sorting) 및 테이블 구문 분석(penguins_in_a_table)이 필요한 작업을 포함합니다. 그림 9: Gemini Pro는 BIG-Bench-Hard 하위 작업에서 GPT 3.5보다 성능이 뛰어납니다. 저자는 그림 10과 같이 다양한 답변 유형에서 테스트된 모델의 견고성을 추가로 분석했습니다. Gemini Pro는 형식적 오류 작업에 속하는 "유효/무효" 답변 유형에서 최악의 결과를 보였습니다. 흥미롭게도 이 과제의 질문 중 68.4%는 응답이 없었습니다. 그러나 다른 답변 유형(단어 정렬 및 dyck_언어 작업으로 구성)에서는 Gemini Pro가 모든 GPT 모델 및 Mixtral보다 성능이 뛰어납니다. 즉, Gemini Pro는 단어를 재배열하고 기호를 올바른 순서로 생성하는 데 특히 능숙합니다. 또한 MCQ 답변의 경우 4.39%의 질문이 Gemini Pro에 의해 응답이 차단되었습니다. GPT 모델은 이 분야에서 탁월하며 Gemini Pro는 이들과 경쟁하기 위해 고군분투하고 있습니다. 그림 10: BIG-Bench-Hard의 답변 유형별 테스트된 모델의 정확도.
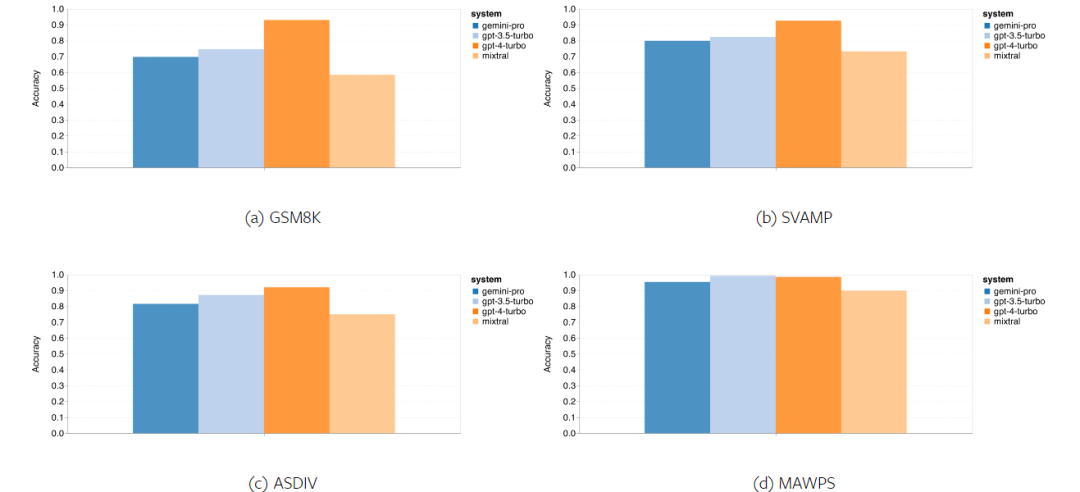
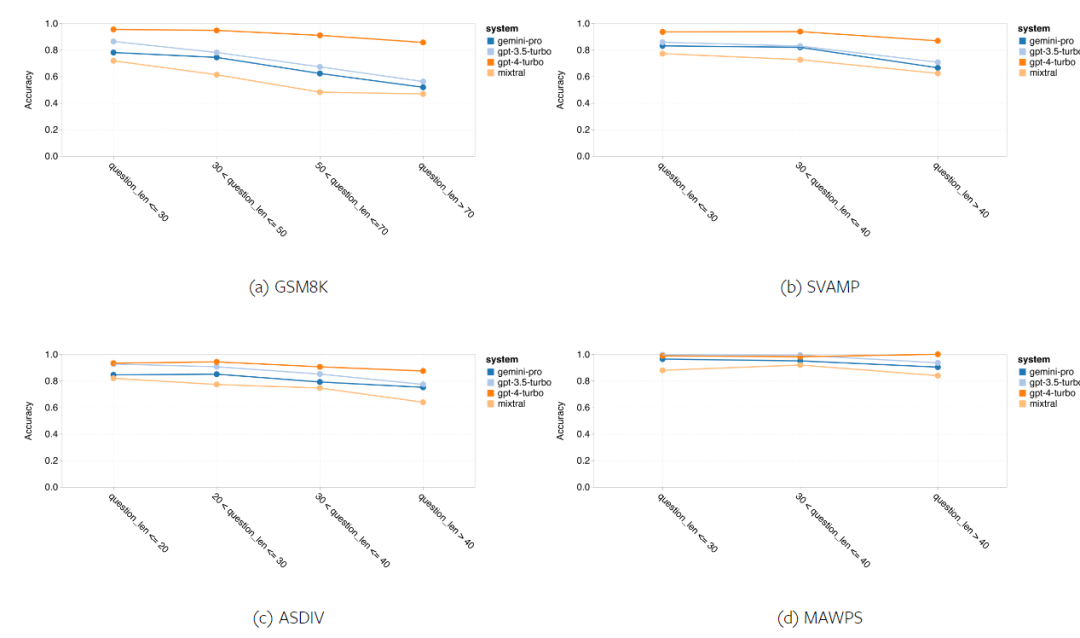
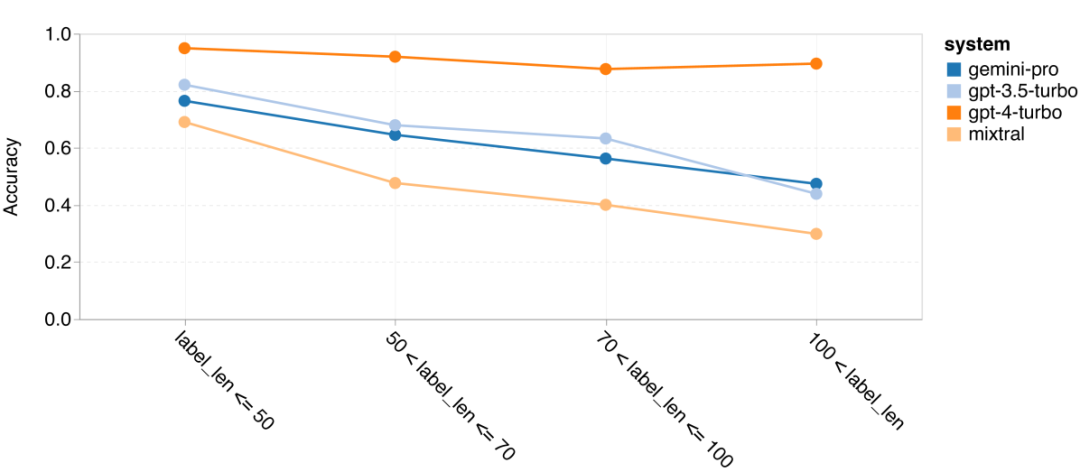
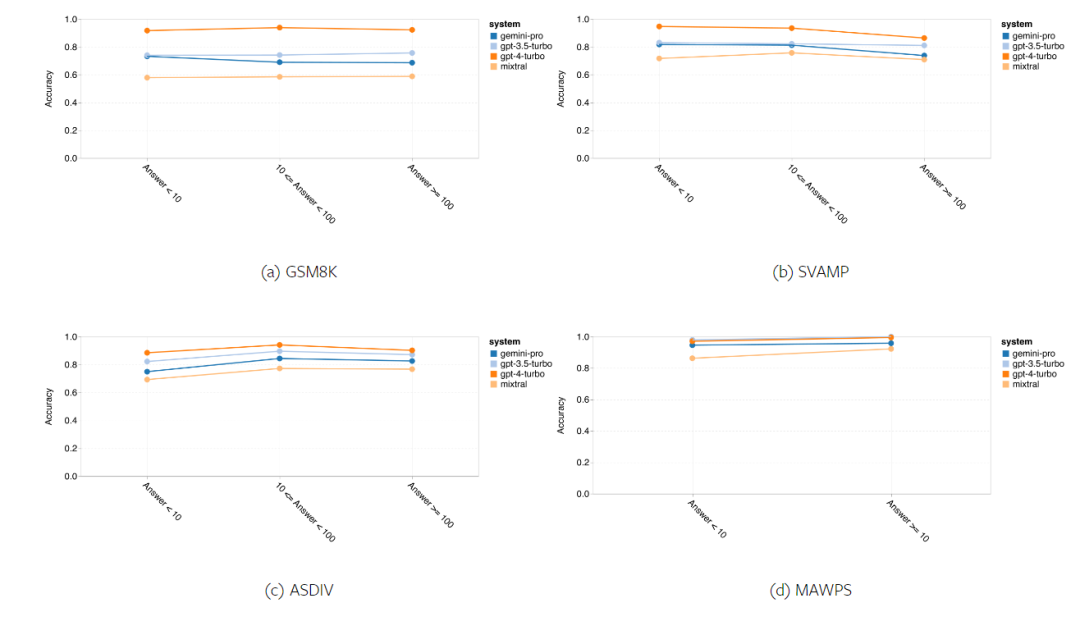
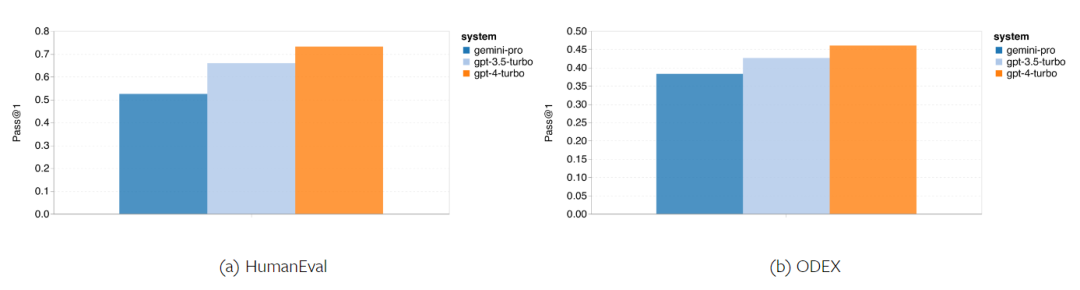
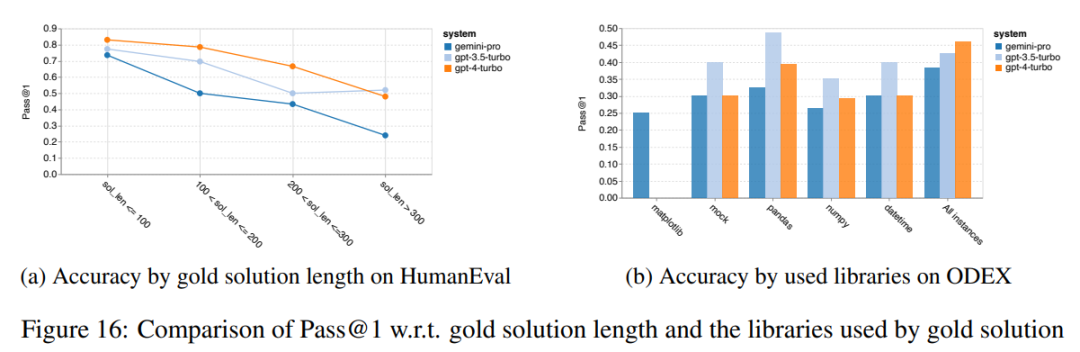
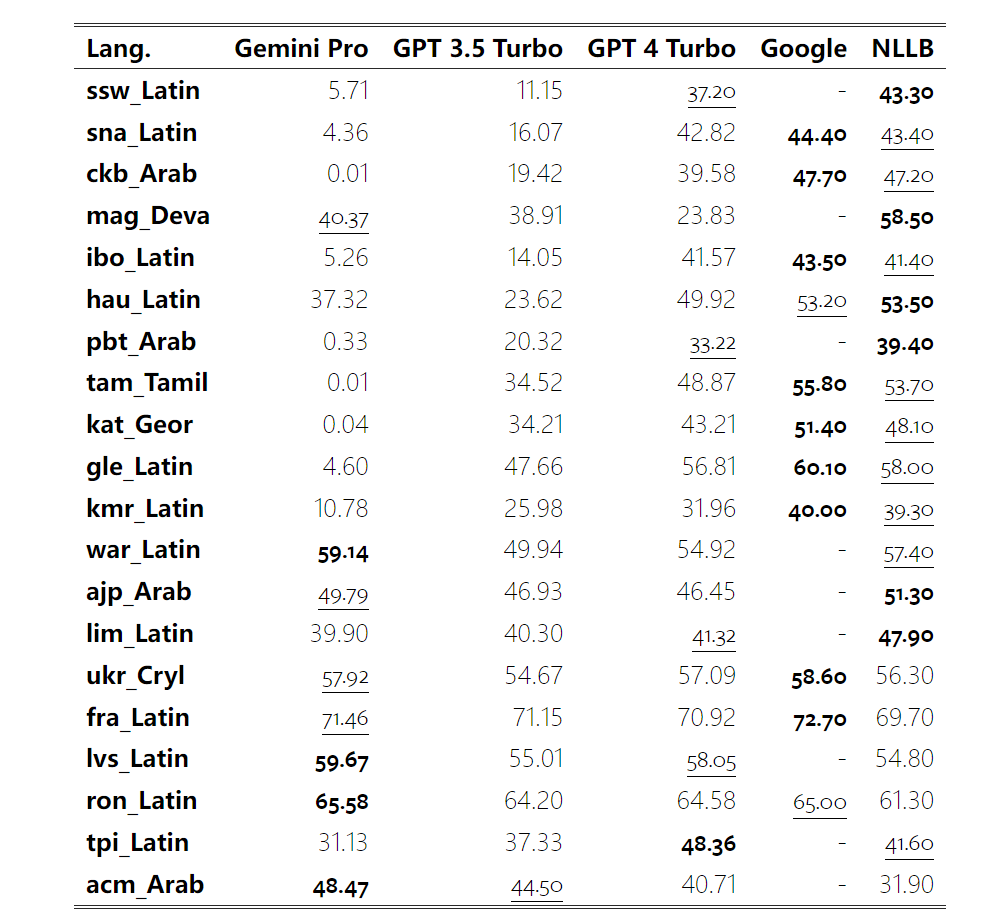
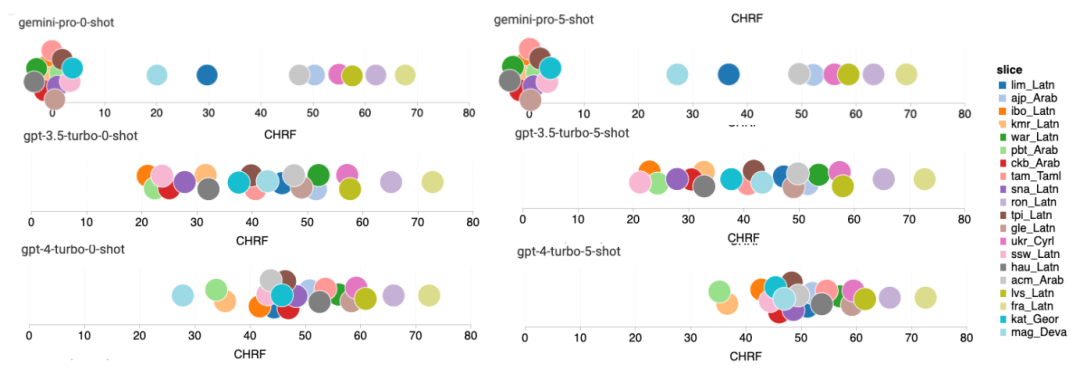
요컨대, 특정 작업을 주도하는 모델은 없는 것 같습니다. 따라서 범용 추론 작업을 수행할 때는 사용할 모델을 결정하기 전에 Gemini 및 GPT 모델을 모두 사용해 보는 것이 좋습니다. 테스트된 모델의 수학적 추론 능력을 평가하기 위해 저자는 4가지 수학적 문제 벤치마크 세트를 선택했습니다. (1) GSM8K: 초등학교 수학 벤치마크 ; (2) SVAMP: 단어 순서를 변경하여 질문을 생성하여 강력한 추론 능력을 확인합니다. (3) ASDIV: 다양한 언어 모드 및 질문 유형 포함 (4) MAWPS: 산술 및 대수 단어 문제가 포함되어 있습니다. 저자는 4개의 수학적 문제 테스트 세트에서 Gemini Pro, GPT 3.5 Turbo, GPT 4 Turbo 및 Mixtral의 정확도를 비교하여 전반적인 성능, 다양한 문제 복잡성에서의 성능 및 다양한 사고 체인 성능을 심층적으로 확인했습니다. 그림 11은 전반적인 결과를 보여줍니다. Gemini Pro의 정확도는 다양한 언어 모드의 GSM8K, SVAMP 및 ASDIV를 포함한 작업에서 GPT 3.5 Turbo보다 약간 낮고 GPT 4 Turbo보다 훨씬 낮습니다. MAWPS 작업의 경우 Gemini Pro는 테스트된 모든 모델이 90% 이상의 정확도를 달성했지만 여전히 GPT 모델보다 약간 열등합니다. 이 작업에서 GPT 3.5 Turbo는 GPT 4 Turbo보다 간신히 성능이 뛰어납니다. 이에 비해 Mixtral 모델의 정확도는 다른 모델에 비해 훨씬 낮습니다. 그림 11: 네 가지 수학적 추론 테스트 세트 작업에서 테스트된 모델의 전반적인 정확도. 문제 길이에 대한 각 모델의 견고성은 그림 12에 나와 있습니다. BIG-Bench Hard의 추론 작업과 유사하게 테스트 중인 모델은 긴 질문에 답할 때 정확도가 감소하는 것으로 나타났습니다.GPT 3.5 Turbo는 짧은 질문에서 Gemini Pro보다 더 나은 성능을 발휘하지만 회귀 속도가 더 빠르며, Gemini Pro는 긴 질문에서 정확성 측면에서 GPT 3.5 Turbo와 유사하지만 여전히 약간 뒤처져 있습니다. 그림 12: 네 가지 수학적 추론 테스트 세트 작업에서 다양한 질문 길이에 대한 답변을 생성하는 테스트된 모델의 정확도. 또한 저자는 답변에 더 긴 사고 체인이 필요할 때 테스트된 모델의 정확성에 차이가 있음을 관찰했습니다. 그림 13에서 볼 수 있듯이 GPT 4 Turbo는 긴 추론 체인을 사용하는 경우에도 매우 견고하지만 GPT 3.5 Turbo, Gemini Pro 및 Mixtral은 COT 길이가 증가할 때 한계를 나타냅니다. 분석을 통해 저자는 또한 Gemini Pro가 COT 길이가 100이 넘는 복잡한 예에서 GPT 3.5 Turbo보다 성능이 뛰어났지만 더 짧은 예에서는 성능이 좋지 않다는 사실도 발견했습니다. 그림 13: 서로 다른 사고 체인 길이에서 GSM8K의 각 모델의 정확도. 그림 14는 다양한 자릿수에 대한 답을 생성하는 테스트 모델의 정확도를 보여줍니다. 저자는 답변의 자릿수가 1, 2, 3 이상인지 여부에 따라 3개의 "버킷"을 만들었습니다(2자리 이상의 답변이 없는 MAWPS 작업 제외). 그림에서 볼 수 있듯이 GPT 3.5 Turbo는 여러 자리 수학 문제에 더 강력한 것으로 보이지만 Gemini Pro는 더 높은 숫자의 문제에 성능이 저하됩니다. 그림 14: 답변 자릿수가 다를 때 네 가지 수학적 추론 테스트 세트 작업에서 각 모델의 정확도. 이 부분에서 저자는 HumanEval과 ODEX라는 두 가지 코드 생성 데이터 세트를 사용하여 모델의 코딩 능력을 테스트합니다. 전자는 Python 표준 라이브러리의 제한된 기능 세트에 대한 모델의 기본 코드 이해를 테스트하고, 후자는 Python 생태계 전반에 걸쳐 더 광범위한 라이브러리 세트를 사용하는 모델의 능력을 테스트합니다. 두 문제에 대한 입력은 영어로 작성된 작업 지침입니다(일반적으로 테스트 사례 포함). 이러한 질문은 모델의 언어 이해도, 알고리즘 이해도, 초등 수학 능력을 평가하는 데 사용됩니다. 전체적으로 HumanEval에는 164개의 테스트 샘플이 있고 ODEX에는 439개의 테스트 샘플이 있습니다. 우선, 그림 15에 표시된 전체 결과에서 두 작업 모두 Gemini Pro의 Pass@1 점수가 GPT 3.5 Turbo보다 낮고 GPT 4 Turbo보다 훨씬 낮다는 것을 알 수 있습니다. 이러한 결과는 Gemini의 코드 생성 기능에 개선의 여지가 있음을 나타냅니다. 그림 15: 코드 생성 작업에서 각 모델의 전반적인 정확도. 두 번째로 저자는 그림 16(a)에서 금 용액 길이와 모델 성능 간의 관계를 분석합니다. 솔루션의 길이는 어느 정도 해당 코드 생성 작업의 어려움을 나타낼 수 있습니다. 저자는 Gemini Pro가 솔루션 길이가 100 미만일 때(쉬운 경우처럼) GPT 3.5와 비슷한 Pass@1 점수를 달성하지만 솔루션 길이가 길어지면 크게 뒤처진다는 사실을 발견했습니다. 이는 저자가 Gemini Pro가 일반적으로 영어 작업에서 더 긴 입력 및 출력에 강력하다는 것을 발견한 이전 섹션의 결과와 흥미로운 대조를 이룹니다. 저자는 그림 16(b)에서 각 솔루션에 필요한 라이브러리가 모델 성능에 미치는 영향도 분석했습니다. mocks, pandas, numpy 및 datetime과 같은 대부분의 라이브러리 사용 사례에서 Gemini Pro는 GPT 3.5보다 성능이 나쁩니다. 그러나 matplotlib의 사용 사례에서는 GPT 3.5 및 GPT 4보다 성능이 뛰어나 코드를 통해 플롯 시각화를 수행하는 능력이 더 뛰어나다는 것을 나타냅니다. 마지막으로 저자는 Gemini Pro가 코드 생성에서 GPT 3.5보다 성능이 떨어지는 몇 가지 구체적인 실패 사례를 보여줍니다. 첫째, 그들은 Gemini가 Python API에서 함수와 매개변수를 올바르게 선택하는 데 약간 열등하다는 점을 발견했습니다.예를 들어, 다음 프롬프트가 주어지면: Gemini Pro는 다음 코드를 생성하여 유형 불일치 오류가 발생했습니다. 반면, GPT 3.5 Turbo는 다음 코드를 사용하여 원하는 효과를 얻었습니다. 또한 Gemini Pro는 실행된 코드가 구문적으로 정확하지만 더 복잡한 의도와 올바르게 일치하지 않는 오류 비율이 더 높습니다. 예를 들어, 다음 팁과 관련하여: Gemini Pro는 여러 번 나타나는 숫자를 제거하지 않고 고유한 숫자만 추출하는 구현을 만들었습니다. 이 일련의 실험에서는 FLORES-200 기계 번역 벤치마크를 사용하여 모델의 다국어 기능, 특히 다양한 언어 쌍 간의 번역 기능을 평가합니다. 저자는 Robinson et al.(2023)의 분석에 사용된 20개 언어 중 다양한 하위 집합에 초점을 맞춰 다양한 수준의 리소스 가용성과 번역 난이도를 다루고 있습니다. 저자는 선택된 모든 언어 쌍에 대해 테스트 세트에서 1012개의 문장을 평가했습니다. 표 4와 5에서 저자는 Google 번역과 같은 성숙한 시스템을 사용하여 Gemini Pro, GPT 3.5 Turbo 및 GPT 4 Turbo를 비교 분석합니다. 또한 광범위한 언어 범위로 알려진 선도적인 오픈 소스 기계 번역 모델인 NLLB-MoE를 벤치마킹했습니다. 결과는 Google Translate가 9개 언어에서 좋은 성능을 발휘하여 전체적으로 다른 모델보다 성능이 뛰어나고, NLLB가 0/5샷 설정에서 6/8 언어에서 좋은 성능을 발휘하는 것으로 나타났습니다. 범용 언어 모델은 경쟁력 있는 성능을 보여주었지만 아직 영어가 아닌 언어로의 번역에 있어서 특수 기계 번역 시스템을 능가하지 못했습니다. 표 4: 모든 언어에 대해 0샷 힌트를 사용하는 기계 번역에 대한 각 모델의 성능(chRF(%) 점수). 최고 점수는 굵은 글씨로 표시되고 다음 최고 점수는 밑줄로 표시됩니다.
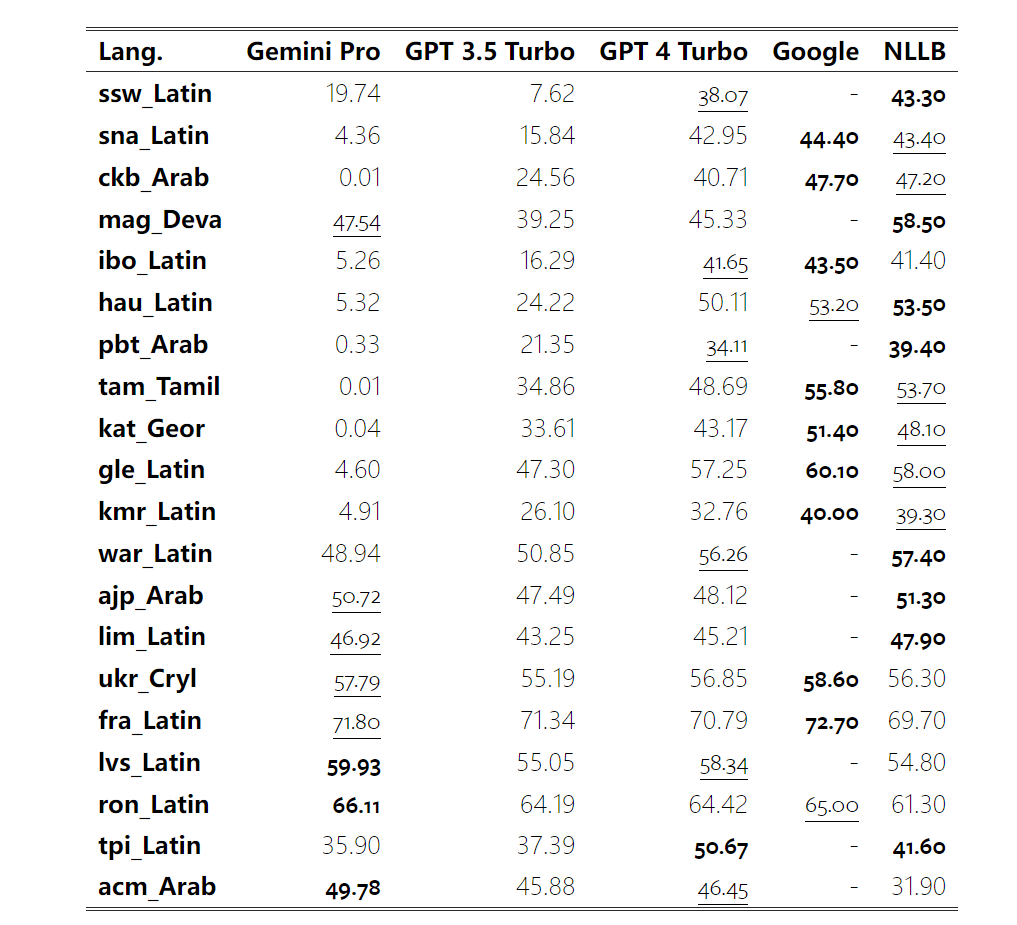
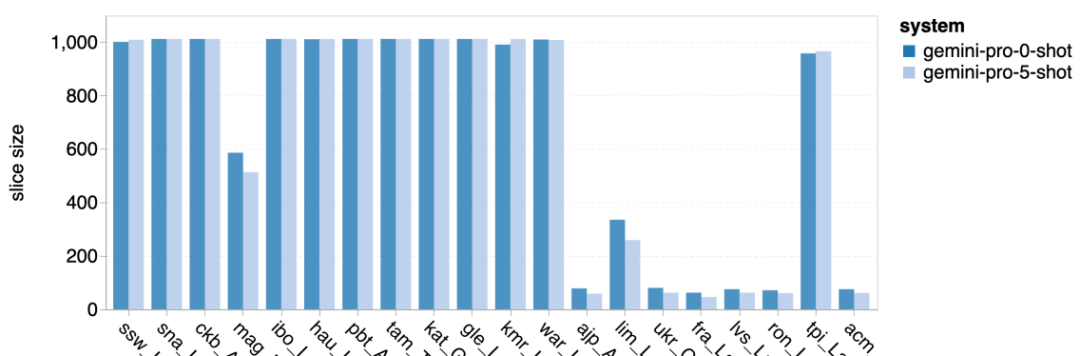
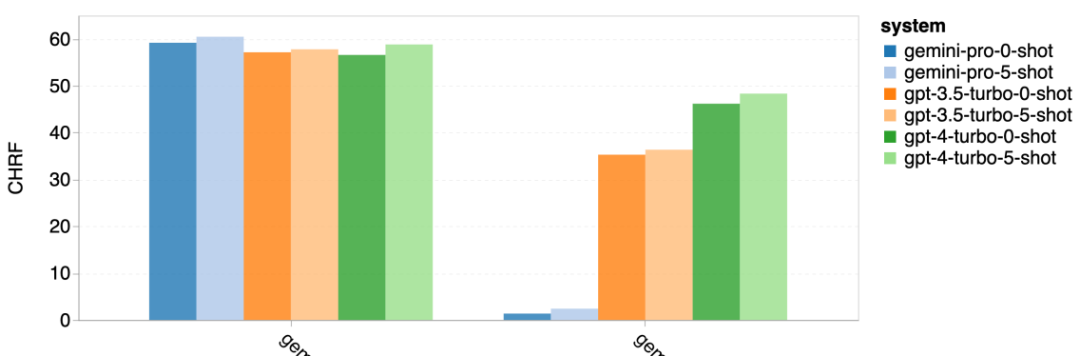
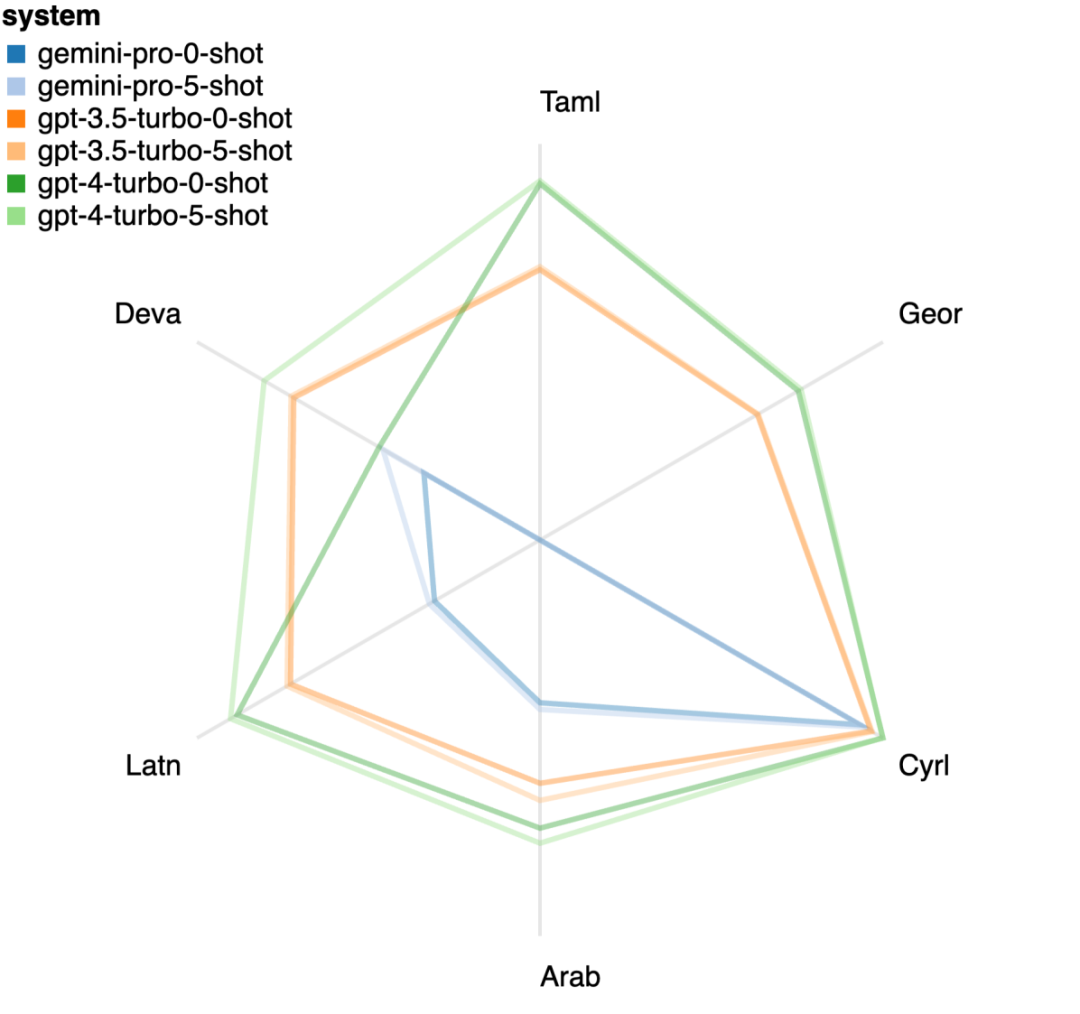
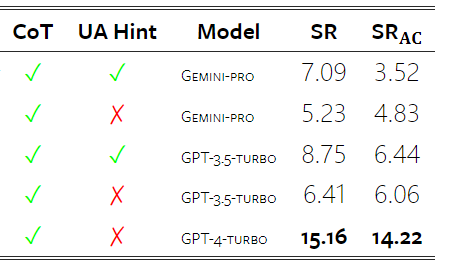
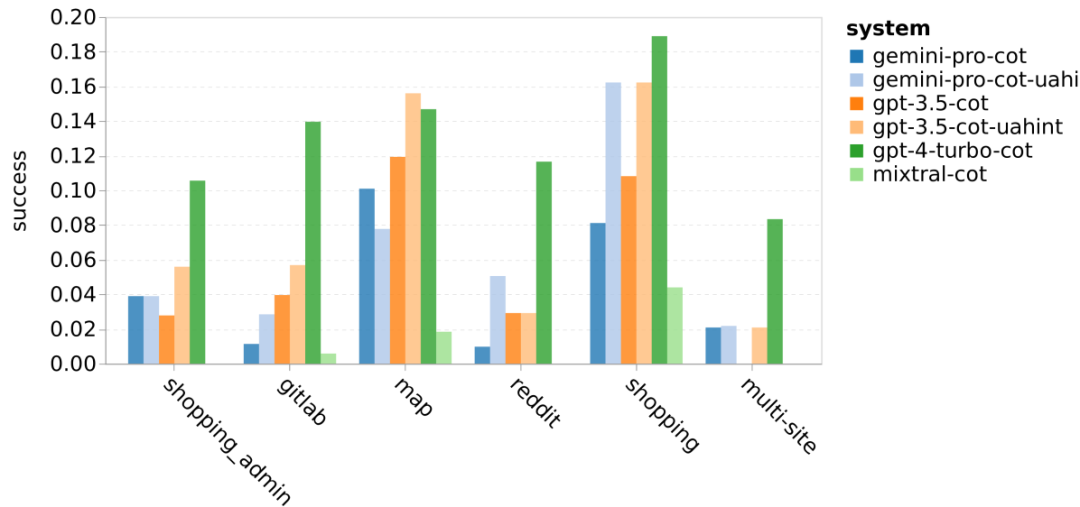
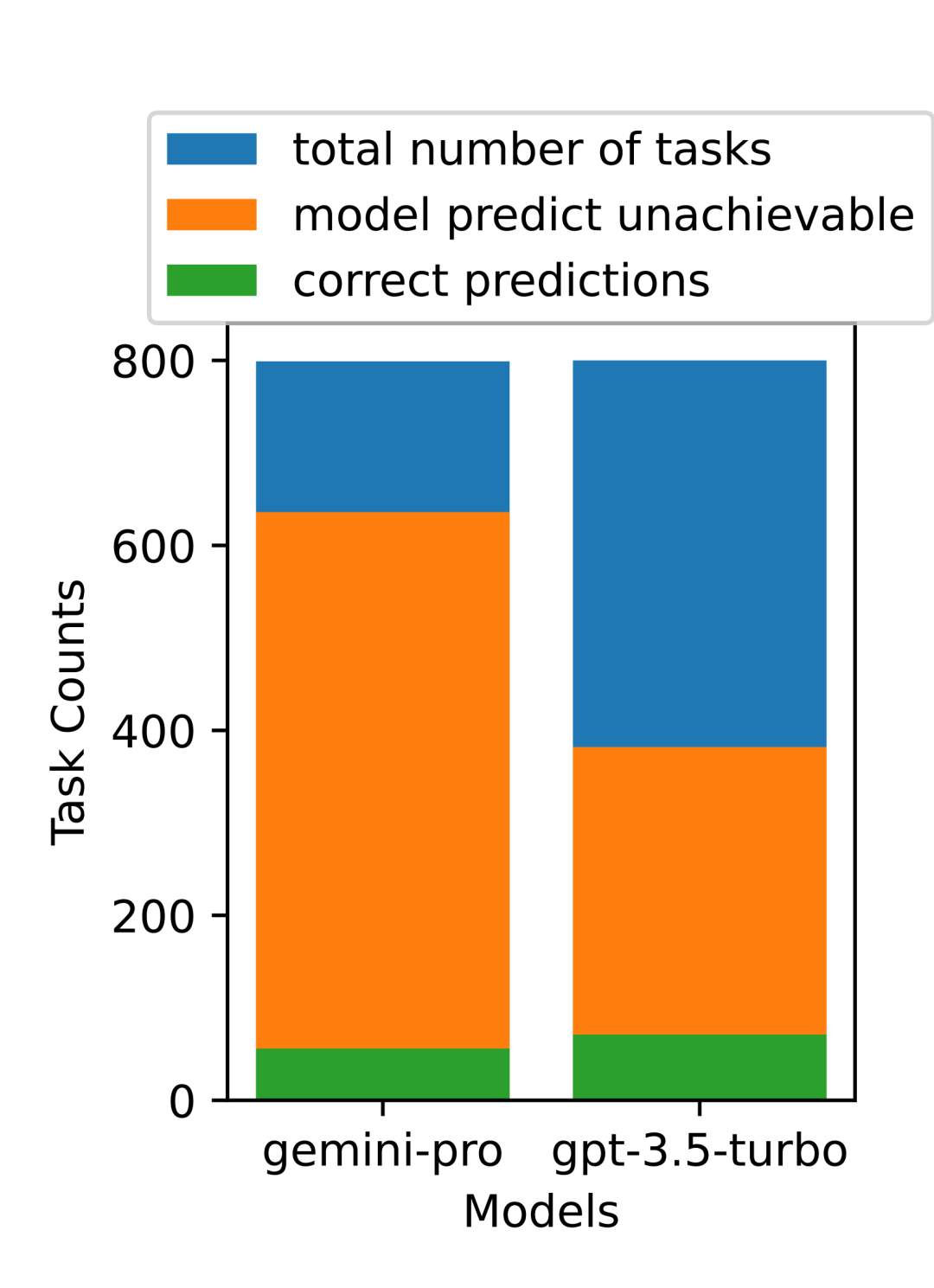
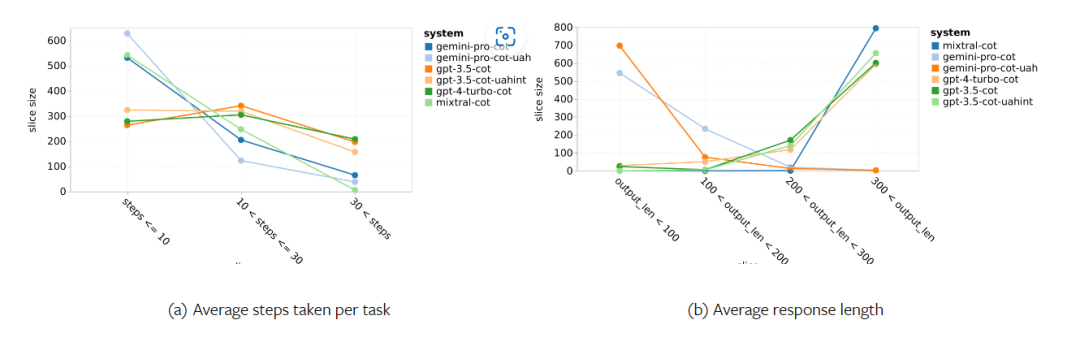
표 5: 모든 언어에 대해 5샷 힌트를 사용하는 기계 번역에 대한 각 모델의 성능(chRF(%) 점수). 최고 점수는 굵은 글씨로 표시되고 다음 최고 점수는 밑줄로 표시됩니다. 그림 17은 다양한 언어 쌍에 대한 일반 언어 모델의 성능 비교를 보여줍니다. GPT 4 Turbo는 GPT 3.5 Turbo 및 Gemini Pro에 비해 NLLB에서 일관된 성능 편차를 나타냅니다. GPT 4 Turbo는 리소스가 적은 언어에서도 크게 개선되었으며, 리소스가 많은 언어에서는 두 LLM의 성능이 비슷합니다. 이에 비해 Gemini Pro는 20개 언어 중 8개 언어에서 GPT 3.5 Turbo 및 GPT 4 Turbo를 능가했으며 4개 언어에서 최고 성능을 달성했습니다. 하지만 Gemini Pro는 약 10개 언어쌍에서 응답을 차단하는 경향이 강한 것으로 나타났습니다. 그림 17: 언어 쌍별 기계 번역 성능(chRF(%) 점수). 그림 18은 Gemini Pro가 신뢰도가 낮은 시나리오에서 응답을 가리는 경향이 있기 때문에 이러한 언어에서 성능이 낮다는 것을 보여줍니다. Gemini Pro가 0샷 또는 5샷 구성에서 "차단된 응답" 오류를 생성하는 경우 해당 응답은 "차단된" 것으로 간주됩니다. 그림 18: Gemini Pro에 의해 차단된 샘플 수. 그림 19를 자세히 살펴보면 Gemini Pro가 비차폐 샘플에서 더 높은 신뢰도로 GPT 3.5 Turbo 및 GPT 4 Turbo보다 약간 뛰어난 성능을 보인다는 것을 알 수 있습니다.구체적으로 GPT 4 Turbo보다 5샷과 0샷 설정에서 각각 1.6chrf, 2.6chrf 성능이 뛰어나고, GPT 3.5 Turbo보다 2.7chrf, 2chrf 성능이 뛰어납니다. 그러나 이러한 샘플에 대한 GPT 4 Turbo 및 GPT 3.5 Turbo의 성능에 대한 저자의 예비 분석은 이러한 샘플의 번역이 일반적으로 더 어렵다는 것을 보여줍니다. Gemini Pro는 이러한 특정 샘플에서 성능이 좋지 않으며 Gemini Pro 0샷 마스크는 반응하는 반면 5샷은 그렇지 않으며 그 반대의 경우도 마찬가지라는 점이 특히 눈에 띕니다. 그림 19: 마스크된 샘플과 마스크되지 않은 샘플의 chrf 성능(%). 모델 분석 전반에 걸쳐 저자는 GPT 4 Turbo 그림 20은 언어군이나 문자에 따른 명확한 추세를 보여줍니다. 중요한 관찰은 Gemini Pro가 키릴 문자의 다른 모델과 경쟁적으로 작동하지만 다른 문자에서는 그렇지 않다는 것입니다. GPT-4는 다양한 스크립트에서 탁월한 성능을 발휘하여 다른 모델보다 뛰어난 성능을 발휘하며, 그중에서도 몇 번의 힌트가 특히 효과적입니다. 이러한 효과는 산스크리트어를 사용하는 언어에서 특히 두드러집니다. 그림 20: 다양한 스크립트에서 각 모델의 성능(chrf(%)). 마지막으로 저자는 장기 계획과 복잡한 데이터 이해가 필요한 작업인 네트워크 탐색 에이전트로서 각 모델의 능력을 검사합니다. 그들은 실행 결과로 성공 여부를 측정하는 시뮬레이션 환경인 WebArena를 사용했습니다. 에이전트에 할당된 작업에는 정보 검색, 웹 사이트 탐색, 콘텐츠 및 구성 조작이 포함됩니다. 작업은 전자 상거래 플랫폼, 소셜 포럼, 협업 소프트웨어 개발 플랫폼(예: gitlab), 콘텐츠 관리 시스템, 온라인 지도 등 다양한 웹사이트에 걸쳐 있습니다. 저자는 Gemini-Pro의 전반적인 성공률, 다양한 작업의 성공률, 응답 길이, 궤적 단계 및 작업 실패를 예측하는 경향을 테스트했습니다. 표 6에는 전반적인 성능이 나열되어 있습니다. Gemini-Pro의 성능은 GPT-3.5-Turbo에 가깝지만 약간 열등합니다. GPT-3.5-Turbo와 유사하게 Gemini-Pro는 작업이 완료되지 않을 수 있다는 힌트(UA 힌트)가 언급될 때 더 나은 성능을 발휘합니다. UA 힌트를 사용하면 Gemini-Pro의 전체 성공률은 7.09%입니다. 웹사이트 유형별로 분류하면 그림 21과 같이 Gemini-Pro가 gitlab과 지도, 쇼핑 관리, Reddit, 쇼핑에서는 GPT-3.5-Turbo보다 성능이 떨어지는 것을 확인할 수 있습니다. 웹사이트 성능은 GPT-3.5-Turbo에 가깝습니다. 다중 사이트 작업에서 Gemini-Pro는 GPT-3.5-Turbo보다 성능이 뛰어납니다. 이는 Gemini가 다양한 벤치마크에서 더 복잡한 하위 작업에서 약간 더 나은 성능을 발휘한다는 것을 보여주는 이전 결과와 일치합니다. 그림 21: 다양한 유형의 웹 사이트에서 모델의 웹 에이전트 성공률. 그림 22에서 볼 수 있듯이 일반적으로 Gemini-Pro는 특히 UA 힌트가 제공될 때 완료가 불가능한 작업을 더 많이 예측합니다. Gemini-Pro는 UA 힌트를 고려할 때 작업의 80.6% 이상을 완료할 수 없을 것으로 예측한 반면, GPT-3.5-Turbo는 47.7%만 예측했습니다. 데이터세트에 있는 작업 중 실제로 달성할 수 없는 작업은 4.4%에 불과하므로 둘 다 실제 달성할 수 없는 작업 수를 크게 과대평가한다는 점에 유의하는 것이 중요합니다. 동시에 저자는 Gemini Pro가 결론에 도달하기 전에 더 적은 단계를 거쳐 더 짧은 문구로 응답할 가능성이 더 높다는 것을 관찰했습니다. 그림 23(a)에서 볼 수 있듯이 Gemini Pro의 궤적은 절반 이상이 10스텝 미만인 반면, GPT 3.5 Turbo 및 GPT 4 Turbo의 궤적은 대부분 10~30스텝입니다.마찬가지로 Gemini의 답변도 대부분 100자 미만인 반면, GPT 3.5 Turbo, GPT 4 Turbo, Mixtral의 답변은 대부분 300자를 넘습니다(그림 23(b)). Gemini는 행동을 직접 예측하는 경향이 있지만 다른 모델은 먼저 추론한 다음 행동 예측을 제공합니다. 위 내용은 Gemini 전체 검토: CMU에서 GPT 3.5 Turbo까지 Gemini Pro는 패배합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!